

pandas自定义行数apply
python pandas自定义函数
pandas是数据分析的利器,它内置许多的函数,我之前的一篇博客对pandas的一些常用函数都做了介绍,但是很多时候光是他本身自带的函数可能还不够用,所以这里介绍一下pandas数据类型DataFrame的一个方法,可以让我们的自定义函数运用在上面。
下面看一段代码
import pandas as pd
import os
def f(column):
print(type(column))
df=pd.DataFrame({'column1':[1,2,5,8,63],'column2':[5,6,85,3,5],'column3':[54,36,45,85,69]},index=['fs','fd','f','fa','df'])
print(df)
df.apply(f)
这段代码的输出结果如下:
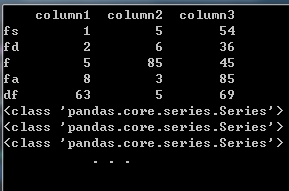
上述代码我们定义了一个函数f,通过apply运用在我们创建的dataframe数据类型上,这里你其实可以发现,f中需要传递一个参数,其实这里你可以发现,dataframe为f传递了三个参数,分别是三个Series对象,其实啊!这里默认传递列参数,然后我们就可以通过这个方法使用自定义函数对列进行操作。
下面再看一段有趣的事例代码:
import pandas as pd
import os
import numpy as np
df=pd.DataFrame({'column1':[1,2,5,8,63],'column2':[5,6,85,3,5],'column3':[54,36,45,85,69]},index=['fs','fd','f','fa','df'],dtype=np.object)
print(df)
def f2(x):
x[3]="hello ,good boy"
x[2]='hello ,good girl'
df.apply(f2)
print(df)
os.system("pause")
结果如下: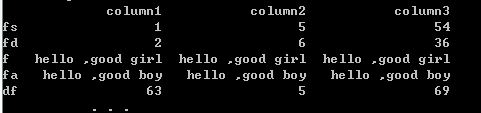
你会发现这样的修改结果,通过这个案例,或许你可以意识到自定义函数的好处。
同时,apply不仅可以对列进行操作还可以对行进行操作,只需要对apply传递一个参数axis=0
下面我再给出一段示例代码:
def f3(x):
print(type(x))
print(x)
df.apply(f3,axis=1)
输出结果如下: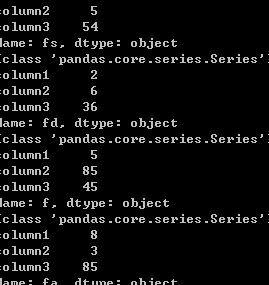
这里有一个要注意的地方,apply对行进行操作时,是不能对元素进行赋值的,但可以进行数据类型转换,也就是不能对行的值进行更改。
实例
def del_unit(sel): sel[7] = sel[7][:-2] return sel def add_unit(sel2): sel2[7] = sel2[7] + 'MB' return sel2 talk_data = total[['主机名称','主机IP','协议','主机帐户','用户名','来源IP','会话时长','会话大小']] talk_data = talk_data[~talk_data['会话大小'].str.contains('KB')] talk_data_mb = talk_data[talk_data['会话大小'].str.contains('MB')] talk_data_mb= talk_data_mb.apply(del_unit,axis=1) talk_data_mb = talk_data_mb.sort_values(by='会话大小',ascending=False) talk_data_mb= talk_data_mb.apply(add_unit,axis=1)
参考文章:https://www.cnblogs.com/gaoxing2580/p/13193459.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号