【Hadoop】第一天 Hadoop基本概念跟原理以及安装

大数据概念
大数据概念
大数据(big data):一般值 无法再一定范围时间内用常规软件进行捕捉处理和优化的数据集和,需要新处理模式下才能具有更强的决策力,主要就是海量,高增长和多样化的信息资产。
解决:海量数据的存储跟海量数据的分析计算问题。
按照顺序给出数据存储单位:
bit,Byte,KB,MB,GB,TB,PB,EB,ZB,YB,BB,NB,DB
其中每一个数据之间的进制都是1024。目前大型公司数据量一般在TB跟PB之间。
大数据特点
- Volume(大量)
截止目前人类所有印刷彩铃数据量是200PB,而历史上任说话总量大约到5EB,海量数据。
- Velocity(高速)
大数据区别于传统数据挖掘的显著特种就是
大,目前支付宝 阿里巴巴的经营模式,也是数字化服务。数据量在高速增长。
- Variety(多样)
这种类型的多样性也让数据被分为结构化数据跟非结构化数据,相对于以往便于存储的MySQL类型数据库,真实的世界中非关系型数据库占据90%以上其实,如何处理多种类型数据也是关键。
- Value(低价值密度)
价值密度的高度跟数据总量的大小成反比的哦,数据量约大我们越要从中筛查出对我们有用的价值数据。
大数据应用场景
都是一些面上的理论知识,主要是知道大数据的应用范围广泛即可,具体自行百度。 目前所有的应用跟服务其实都是在数据的基础上来进行工作的。并且国家跟高校也都在大力发展大数据课程。
大数据部分分类
一般大中型企业大数据部门组织结构如下:

Hadoop 框架
Hadoop 是什么
- Hadoop目前是一个由Apache基金会开发的分布式系统基础架构
- 主要解决海量数据的存储跟海量数据的分析计算问题。
- 通常来说我们说的的hadoop都是广义的一个概念,Hadoop 生态圈。
![在这里插入图片描述]()

Hadoop发展史
hadoop创始人Doug Cutting,主要的思想源头是Google 三辆马车
- GFS ===》 HDFS
- MapReduce===》 MR
- BigTable===》HBase
hadoop 三大版本
Hadoop三大发行版本:Apache、Cloudera、Hortonworks。
- Apache版本最原始(最基础)的版本,对于入门学习最好。
- Cloudera在大型互联网企业中用的较多。
- Hortonworks文档较好。
Apache Hadoop
Apache版本最原始(最基础)的版本,对于入门学习最好。官网地址,下载地址,缺陷就是我们在组成大数据软件体系的时候版本之间记得要搭配好哦!
Cloudera Hadoop
Cloudera在大型互联网企业中用的较多。官网地址,下载地址.
(1) 2008年成立的Cloudera是最早将Hadoop商用的公司,为合作伙伴提供Hadoop的商用解决方案,主要是包括支持、咨询服务、培训。
(2)2009年Hadoop的创始人Doug Cutting也加盟Cloudera公司。Cloudera产品主要为CDH,Cloudera Manager,Cloudera Support
(3)CDH是Cloudera的Hadoop发行版,完全开源,比Apache Hadoop在兼容性,安全性,稳定性上有所增强。
(4)Cloudera Manager是集群的软件分发及管理监控平台,可以在几个小时内部署好一个Hadoop集群,并对集群的节点及服务进行实时监控。Cloudera Support即是对Hadoop的技术支持。
(5)Cloudera的标价为每年每个节点4000美元。Cloudera开发并贡献了可实时处理大数据的Impala项目。
Hortonworks Hadoop
(1)2011年成立的Hortonworks是雅虎与硅谷风投公司Benchmark Capital合资组建。
(2)公司成立之初就吸纳了大约25名至30名专门研究Hadoop的雅虎工程师,上述工程师均在2005年开始协助雅虎开发Hadoop,贡献了Hadoop80%的代码。
(3)雅虎工程副总裁、雅虎Hadoop开发团队负责人Eric Baldeschwieler出任Hortonworks的首席执行官。
(4)Hortonworks的主打产品是Hortonworks Data Platform(HDP),也同样是100%开源的产品,HDP除常见的项目外还包括了Ambari,一款开源的安装和管理系统。
(5)HCatalog,一个元数据管理系统,HCatalog现已集成到Facebook开源的Hive中。Hortonworks的Stinger开创性的极大的优化了Hive项目。Hortonworks为入门提供了一个非常好的,易于使用的沙盒。
(6)Hortonworks开发了很多增强特性并提交至核心主干,这使得Apache Hadoop能够在包括Window Server和Windows Azure在内的Microsoft Windows平台上本地运行。定价以集群为基础,每10个节点每年为12500美元。
Hadoop优势
- 高可用
Hadoop 底层对同一个数据维护这多个复本,即使Hadoop某个计算元素或者存储出现问题,也不会导致数据的丢失。
- 高扩展
在集群之间分配任务数据,可以方便的扩展跟删除多个节点,比如美团节点就在3K~5k 个节点
- 高效性
在MapReduce的思想下 Hadoop是并行工作的,以加快任务的处理速度
- 高容错性
如果一个子任务速度过慢或者任务失败 Hadoop会有响应策略会自动重试跟任务分配。
Hadoop 组成(重点)

HDFS架构概述
HDFS(Hadoop Distributed File System) 架构主要是三个Namenode,DataNode,Secondary NameNode。

YARN 架构概述
YARN主要进行资源分配的。ResourceMananger,NodeManager,ApplicationMaster,Container。

MapReduce 架构概述
MapReduce 主要是思想的引入,将任务计算过程分为两个阶段,有种分治的思想。
- Map阶段
对任务进行并行的处理输入数据。
- Reduce阶段
对Map阶段的结果进行汇总。
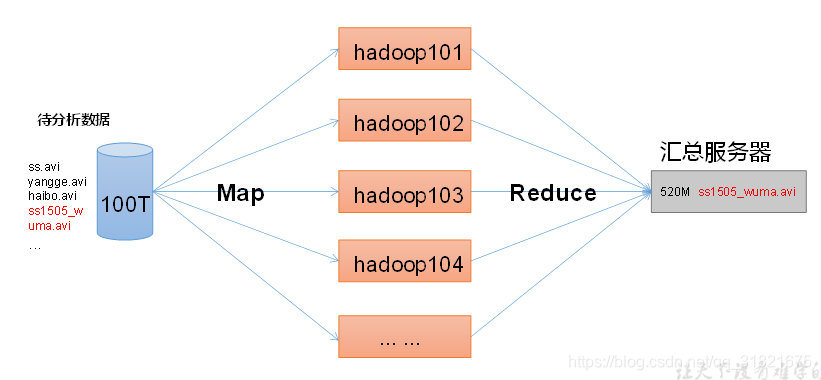
大数据体系
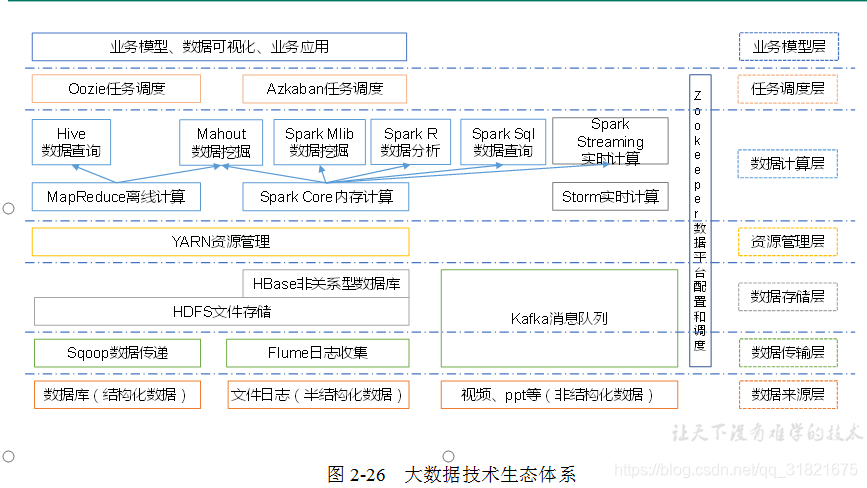
图中涉及的技术名词解释如下:
Sqoop:Sqoop是一款开源的工具,主要用于在Hadoop、Hive与传统的数据库(MySql)间进行数据的传递,可以将一个关系型数据库(例如 :MySQL,Oracle 等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。Flume:Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。Kafka:Kafka是一种高吞吐量的分布式发布订阅消息系统,有如下特性:
- 通过O(1)的磁盘数据结构提供消息的持久化,这种结构对于即使数以TB的消息存储也能够保持长时间的稳定性能。
- 高吞吐量:即使是非常普通的硬件Kafka也可以支持每秒数百万的消息。
- 支持通过Kafka服务器和消费机集群来分区消息。
- 支持Hadoop并行数据加载。
Storm:Storm用于连续计算,对数据流做连续查询,在计算时就将结果以流的形式输出给用户。Spark:Spark是当前最流行的开源大数据内存计算框架。可以基于Hadoop上存储的大数据进行计算。Oozie:Oozie是一个管理Hdoop作业(job)的工作流程调度管理系统。
7.Hbase:HBase是一个分布式的、面向列的开源数据库。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。Hive:Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的SQL查询功能,可以将SQL语句转换为MapReduce任务进行运行。 其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。R语言:R是用于统计分析、绘图的语言和操作环境。R是属于GNU系统的一个自由、免费、源代码开放的软件,它是一个用于统计计算和统计制图的优秀工具。Mahout:Apache Mahout是个可扩展的机器学习和数据挖掘库。ZooKeeper:Zookeeper是Google的Chubby一个开源的实现。它是一个针对大型分布式系统的可靠协调系统,提供的功能包括:配置维护、名字服务、 分布式同步、组服务等。ZooKeeper的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效、功能稳定的系统提供给用户。简而言之就是大数据的生态动物园的管理员
一个简单的推荐项目框架:

Hadoop 部署方式
一般有三种方式用来安装哦
- 本地模式
- 伪分布模式
- 集群模式
环境搭建
一般情况下无非就是要注意以下几点:
参考 Hadoop-HA分布式搭建,本次视频教程是Windows下按照VMware 然后安装centos7 来安装的。所以开搞前要注意一下几点
- 网络设置
1.1 知道网卡、网关、交换机、路由器简单作用。
1.2 VMware网络配置
1.2 首先设定VMware的网络为NAT,设置好固定网关
1.3 VMware 会在Windows电脑上创建虚拟网卡
1.4 创建好的centos系统设置好 固定IP地址跟网关,
形象图如下

- centos设置
2.1 centos 修改主机名
2.2 centos 设置固定IP
2.2 centos 主机名跟IP映射
2.3 centos 防火墙设置
2.4 Ubuntu 防火墙设置
- 安装JDK
- 安装Hadoop 2.7.2
Hadoop 重要目录介绍
(1)bin目录:存放对Hadoop相关服务(HDFS,YARN)进行操作的脚本
(2)etc目录:Hadoop的配置文件目录,存放Hadoop的配置文件
(3)lib目录:存放Hadoop的本地库(对数据进行压缩解压缩功能)
(4)sbin目录:存放启动或停止Hadoop相关服务的脚本
(5)share目录:存放Hadoop的依赖jar包、文档、和官方案例
Hadoop运行模式
Hadoop运行模式包括:本地模式、伪分布式模式以及完全分布式模式。
Hadoop官方网站:http://hadoop.apache.org/
官方文档:https://hadoop.apache.org/docs/r2.7.2/
Hadoop本地版
本地版操作指南官方:Setting up a Single Node Cluster.
官方Grep案例
Grep案例
PS:切记输出目录要不存在哦,Hadoop会自动创建。
官方WordCount案例
伪分布式
Pseudo-Distributed Operation 参考 官方手册。其中hdfs://*** 是Hadoop文件系统存储文件的一种方式哦,参考 https://www.baidu.com这样的。
PS: 格式化Hadoop的时候记得要两部哦,先停止 namenode,datanode,然后将data跟logs 删除,最终再格式化Hadoop。
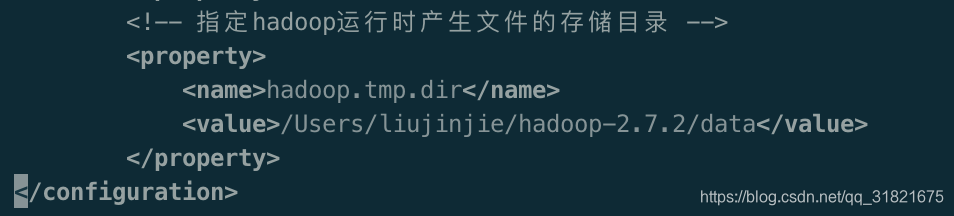
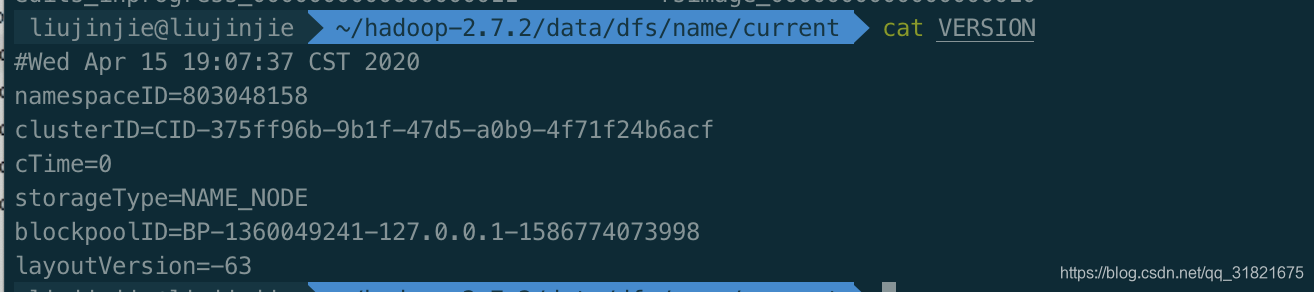
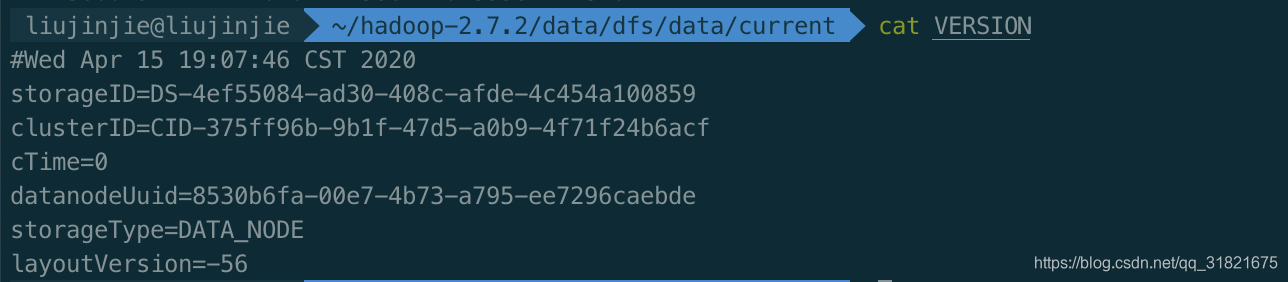
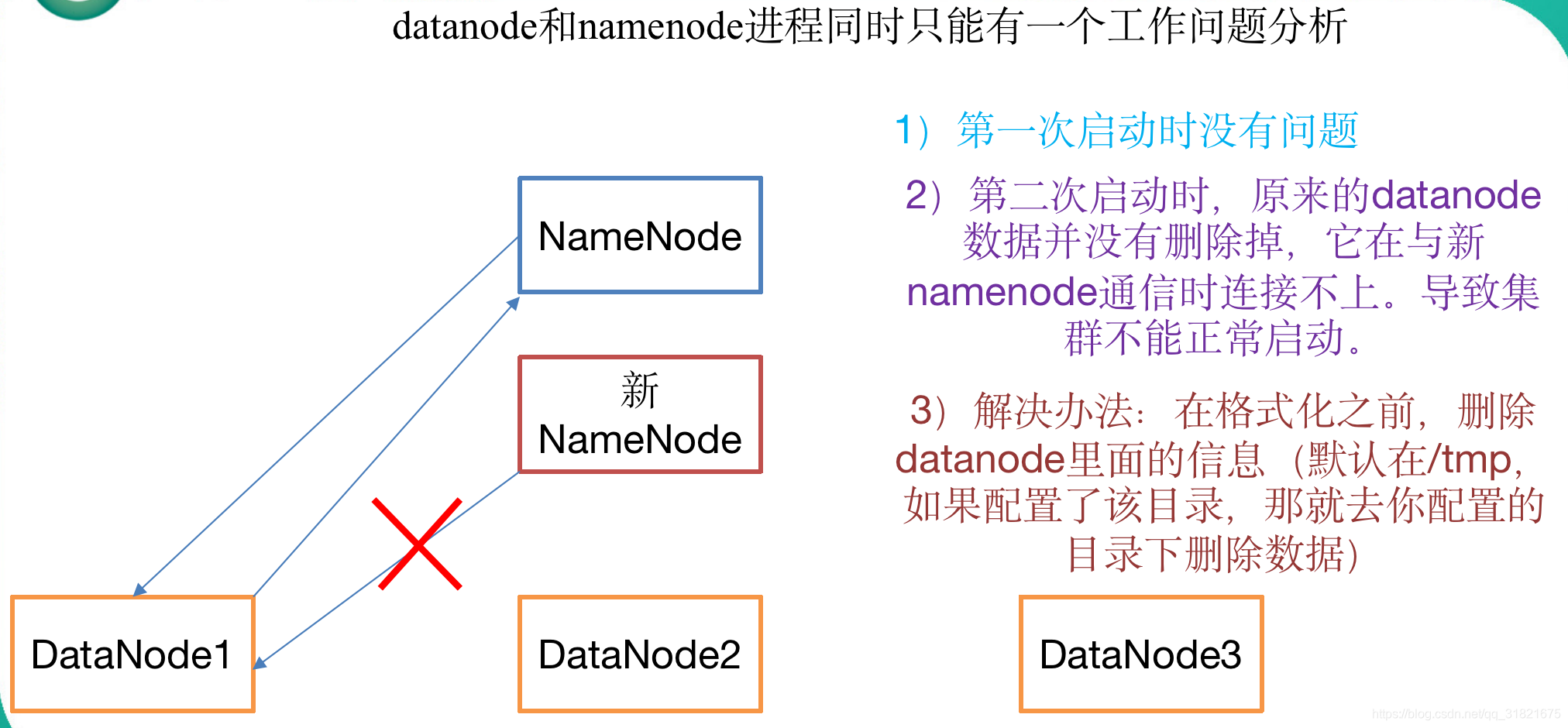
注意:格式化NameNode,会产生新的集群id,导致NameNode和DataNode的集群id不一致,集群找不到已往数据。所以,格式NameNode时,一定要先删除data数据和log日志,然后再格式化NameNode。
Hadoop 伪分布式搭建
无非就是 core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml、配置历史服务器、配置日志的聚集跟 jps 等软件的集和使用。可参考 安装入门
4.8 验证是否启动成功
使用 jps 命令验证
27408 NameNode
28218 Jps
27643 SecondaryNameNode
28066 NodeManager
27803 ResourceManager
27512 DataNode
4.9 成功验证
http://主机名:50070 (HDFS管理界面)
http://主机名:8088 (MR管理界面)
5.0 大数据服务端口汇总
1、HDFS页面:50070
2、YARN的管理界面:8088
3、HistoryServer的管理界面:19888
4、Zookeeper的服务端口号:2181
5、Mysql的服务端口号:3306
6、Hive.server1=10000
7、Kafka的服务端口号:9092
8、azkaban界面:8443
9、Hbase界面:16010,60010
10、Spark的界面:8080
11、Spark的URL:7077
PS:HDFS是 应用级的分布式文件存储服务,根据这个思想可以联想到网盘,我们看到的HDFS提供的什么 hdfs://cluster:9000/ljj/sowhat/file 这些都是虚拟的,由namenode来提供的,实际数据跟最终切片后数据的映射关系就由namenode来实现,延伸到如何实现控制别人存储文件的网盘大小等都是可以简单实现的。
当很多人传输跟存储相同一份文件的时候,系统会将最早的一份文件快捷方式存储到你的文件系统中,然后告知我们上传成功,这样不仅减少了公司的网盘空间,还速度极快。
同时再次记住一点 HDFS是一次写入多次读出,不支持随机性读取跟修改,并且Hadoop-shell 权限检查不严格。
完全分布式运行模式
主要点:
- 准备3台客户机(关闭防火墙、静态ip、主机名称),大致步骤跟上面类似,
- 安装JDK
- 配置环境变量
- 安装Hadoop
- 配置环境变量
- 配置集群
- 单点启动
- 配置ssh
- 群起并测试集群
其中1~5 都是很简单的操作哦,跟以前类似。
PS:scp可以实现两个服务器之间来回cp文件,
scp -r /opt/module root@hadoop102:/opt/module
scp -r atguigu@hadoop101:/opt/module/opt/module
scp -r atguigu@hadoop101:/opt/module root@hadoop104:/opt/module
注意:拷贝过来的/opt/module目录,别忘了在hadoop102、hadoop103、hadoop104上修改所有文件的,所有者和所有者组
对Java跟Hadoop软件的 环境变量移动 scp /etc/profile root@hadoop102:/etc/profile
拷贝过来的配置文件别忘了source一下/etc/profile
rsync 远程同步工具
rsync主要用于备份和镜像。具有速度快、避免复制相同内容和支持符号链接的优点。
rsync和scp区别:用rsync做文件的复制要比scp的速度快,rsync只对差异文件做更新。scp是把所有文件都复制过去。
rsync -rvl $pdir/$fname $user@hadoop$host:$pdir/$fname
命令 选项参数 要拷贝的文件路径/名称 目的用户@主机:目的路径/名称

重点:
(1)需求:循环复制文件到所有节点的相同目录下
(2)需求分析:
(a)rsync命令原始拷贝:rsync -rvl /opt/module root@hadoop103:/opt/
(b)期望脚本: xsync 要同步的文件名称
(c)说明:在/home/sowhat/bin这个目录下存放的脚本,sowhat用户可以在系统任何地方直接执行。
同步脚本
#!/bin/bash
#1 获取输入参数个数,如果没有参数,直接退出
pcount=$#
if((pcount==0)); then
echo no args;
exit;
fi
#2 获取文件名称
p1=$1
fname=`basename $p1` # 获得文件名
echo fname=$fname
#3 获取上级目录到绝对路径
pdir=`cd -P $(dirname $p1); pwd` # -P 是进入到软链接 实际路径
echo pdir=$pdir
#4 获取当前用户名称
user=`whoami`
#5 循环 一般就是在102上进行修改 然后运行这个脚本实现 103 跟104的同步
for((host=103; host<105; host++)); do
echo ------------------- hadoop$host --------------
rsync -rvl $pdir/$fname $user@hadoop$host:$pdir
done
分布式部署图:
一般 NameNode跟SecondaryNameNode不要放在一个机器上哦,
ResourceManager一般要 避开 NameNode跟SecondaryNameNode哦。
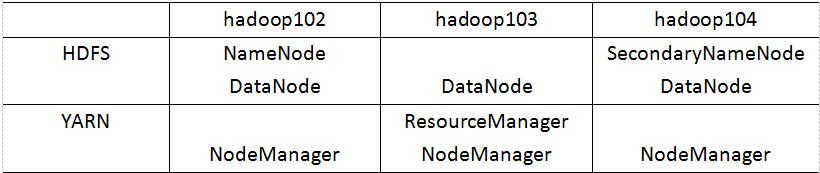
一般就是在102 上将 HDFS,YARN,MapReduce等配置文件配置好,然后直接用 ==同步脚本 ==分发到别的节点上。
- 先删除
所有节点上的 data , logs 文件- hadoop namenode -format 格式化 (102)
- hadoop-daemon.sh start namenode (102)
- hadoop-daemon.sh start datanode (102,103,104)
上面的不足之处在于 还要登陆 103 跟104 启动datanode,
SSH

配置集群之间 SSH无密登陆, 配置ssh免登陆 教程 。
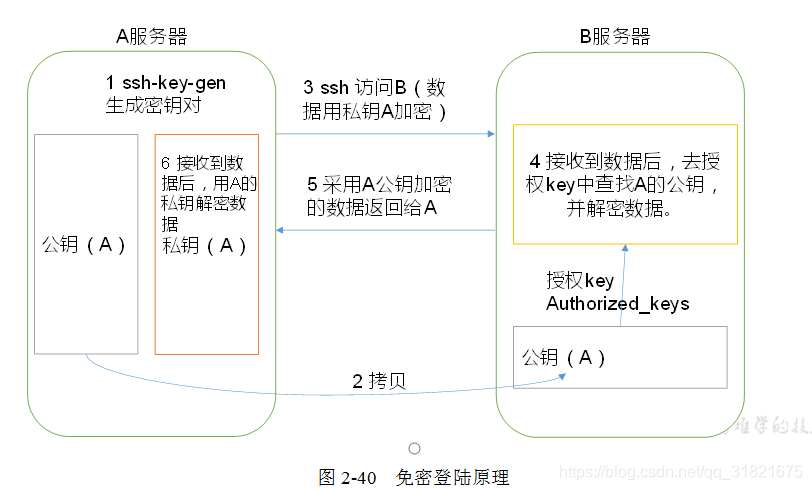
NameNode 要可以免密登陆其他节点,ResourceManager要可以免密登陆其他节点 切记。
(2)生成公钥和私钥:
[atguigu@hadoop102 .ssh]$ ssh-keygen -t rsa
然后敲(三个回车),就会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)
(3)将公钥拷贝到要免密登录的目标机器上
[atguigu@hadoop102 .ssh]$ ssh-copy-id hadoop102
[atguigu@hadoop102 .ssh]$ ssh-copy-id hadoop103
[atguigu@hadoop102 .ssh]$ ssh-copy-id hadoop104
注意:
还需要在hadoop102上采用root账号,配置一下无密登录到hadoop102、hadoop103、hadoop104;
还需要在hadoop103上采用atguigu账号配置一下无密登录到hadoop102、hadoop103、hadoop104服务器上。
3. .ssh文件夹下(~/.ssh)的文件功能解释

集群群起
配置slaves ;/opt/module/hadoop-2.7.2/etc/hadoop/slaves
在该文件中增加如下内容
hadoop102
hadoop103
hadoop104
注意:该文件中添加的内容结尾不允许有空格,文件中不允许有空行。
同步所有节点配置文件
[atguigu@hadoop102 hadoop]$ xsync slaves
启动集群
(1)如果集群是第一次启动,需要格式化NameNode(注意格式化之前,一定要先停止上次启动的所有namenode和datanode进程,然后再删除data和log数据)
[atguigu@hadoop102 hadoop-2.7.2]$ bin/hdfs namenode -format
(2)启动HDFS
[atguigu@hadoop102hadoop-2.7.2]$ sbin/start-dfs.sh
[atguigu@hadoop102hadoop-2.7.2]$ jps
4166 NameNode
4482 Jps
4263 DataNode
[atguigu@hadoop103hadoop-2.7.2]$ jps
3218 DataNode
3288 Jps
[atguigu@hadoop104hadoop-2.7.2]$ jps
3221 DataNode
3283 SecondaryNameNode
3364 Jps
(3)启动YARN
[atguigu@hadoop103 hadoop-2.7.2]$ sbin/start-yarn.sh
注意:NameNode和ResourceManger如果不是同一台机器,不能在NameNode上启动 YARN,应该在ResouceManager所在的机器上启动YARN。
(4)Web端查看SecondaryNameNode
(a)浏览器中输入:http://hadoop104:50090/status.html
(b)查看SecondaryNameNode信息,如图2-41所示。

可以做一些基本的上传指令检测 Hadoop集群是否ok了。
(2)上传文件后查看文件存放在什么位置
(a)查看HDFS文件
存储路径
[atguigu@hadoop102 subdir0]$ pwd
/opt/module/hadoop-2.7.2/data/tmp/dfs/data/current/BP-938951106-192.168.10.107-1495462844069/current/finalized/subdir0/subdir0
(b)查看HDFS在磁盘存储文件内容
[atguigu@hadoop102 subdir0]$ cat blk_1073741825
hadoop yarn
hadoop mapreduce
atguigu
atguigu
© 拼接,将存储的文件可以拼接起来 跟从hadoop102:50070 浏览器下载一样。
-rw-rw-r--. 1 atguigu atguigu 134217728 5月 23 16:01 blk_1073741836
-rw-rw-r--. 1 atguigu atguigu 1048583 5月 23 16:01 blk_1073741836_1012.meta
-rw-rw-r--. 1 atguigu atguigu 63439959 5月 23 16:01 blk_1073741837
-rw-rw-r--. 1 atguigu atguigu 495635 5月 23 16:01 blk_1073741837_1013.meta
[atguigu@hadoop102 subdir0]$ cat blk_1073741836>>tmp.file
[atguigu@hadoop102 subdir0]$ cat blk_1073741837>>tmp.file
[atguigu@hadoop102 subdir0]$ tar -zxvf tmp.file
集群启动/停止方式总结
- 各个服务组件逐一启动/停止
(1)分别启动/停止HDFS组件
hadoop-daemon.sh start / stop namenode / datanode / secondarynamenode
(2)启动/停止YARN
yarn-daemon.sh start / stop resourcemanager / nodemanager
- 各个模块分开启动/停止(配置ssh是前提)常用
(1)整体启动/停止HDFS
start-dfs.sh / stop-dfs.sh
(2)整体启动/停止YARN
start-yarn.sh / stop-yarn.sh
PS: 一般都是先启动HDFS 再启动YARN,不建议直接启动ALL。
crontab
crontab 定时任务启动或循环任务启动工具,可以直接用在线工具哦
crontab -e [-r] [-l ] ( e是编辑,r是删除,l 是查看的意思)

集群时间同步
时间同步的方式:
找一个机器,作为时间服务器,所有的机器与这台集群时间进行定时的同步,比如,每隔十分钟,同步一次时间。
我们将hadoop102认为时间服务器

- 时间服务器配置(必须root用户)
(1)检查ntp是否安装
[root@hadoop102 桌面]# rpm -qa|grep ntp
ntp-4.2.6p5-10.el6.centos.x86_64
fontpackages-filesystem-1.41-1.1.el6.noarch
ntpdate-4.2.6p5-10.el6.centos.x86_64
(2)修改ntp配置文件
[root@hadoop102 桌面]# vi /etc/ntp.conf
修改内容如下
a)修改1(授权192.168.1.0-192.168.1.255网段上的所有机器可以从这台机器上查询和同步时间)
#restrict 192.168.1.0 mask 255.255.255.0 nomodify notrap为
restrict 192.168.1.0 mask 255.255.255.0 nomodify notrap
b)修改2(集群在局域网中,不使用其他互联网上的时间)
server 0.centos.pool.ntp.org iburst
server 1.centos.pool.ntp.org iburst
server 2.centos.pool.ntp.org iburst
server 3.centos.pool.ntp.org iburst为
#server 0.centos.pool.ntp.org iburst
#server 1.centos.pool.ntp.org iburst
#server 2.centos.pool.ntp.org iburst
#server 3.centos.pool.ntp.org iburst
c)添加3(当该节点丢失网络连接,依然可以采用本地时间作为时间服务器为集群中的其他节点提供时间同步)
server 127.127.1.0
fudge 127.127.1.0 stratum 10
(3)修改/etc/sysconfig/ntpd 文件
[root@hadoop102 桌面]# vim /etc/sysconfig/ntpd
增加内容如下(让硬件时间与系统时间一起同步)
SYNC_HWCLOCK=yes
(4)重新启动ntpd服务
[root@hadoop102 桌面]# service ntpd status
ntpd 已停
[root@hadoop102 桌面]# service ntpd start
正在启动 ntpd: [确定]
(5)设置ntpd服务开机启动
[root@hadoop102 桌面]# chkconfig ntpd on
- 其他机器配置(必须root用户)
(1)在其他机器配置10分钟与时间服务器同步一次
[root@hadoop103桌面]# crontab -e
编写定时任务如下:
*/10 * * * * /usr/sbin/ntpdate hadoop102
(2)修改任意机器时间
[root@hadoop103桌面]# date -s "2017-9-11 11:11:11"
(3)十分钟后查看机器是否与时间服务器同步
[root@hadoop103桌面]# date
PS:测试的时候可以将10分钟调整为1分钟,节省时间。
Hadoop编译
编译的原因 :
一般hadoop需要在自己的linux环境下重新将源代码编译一下,为什么hadoop要自己再次编译一下,网上很多都是说:官网提供编译好的只有32位的,没有提供64位的,其实这种解释是错的。官网可下载的也有编译好的64位。
那为什么要大费周折的重新编译?主要是要重新编译本地库(Native Libraries) 代码(Linux下对应[.so]文件,window下对应[.dlI]文件),也就是编译生成linux下的[.so] 文件。
判别Hadoop32or64

Hadoop 源码编译
前期准备工作
- CentOS联网 配置CentOS能连接外网。Linux虚拟机ping www.baidu.com 是畅通的
注意:采用root角色编译,减少文件夹权限出现问题 - jar包准备(hadoop源码、JDK8、maven、ant 、protobuf)
(1)hadoop-2.7.2-src.tar.gz
(2)jdk-8u144-linux-x64.tar.gz
(3)apache-ant-1.9.9-bin.tar.gz(build工具,打包用的)
(4)apache-maven-3.0.5-bin.tar.gz
(5)protobuf-2.5.0.tar.gz(序列化的框架)
5.2 jar包安装
注意:所有操作必须在root用户下完成
1.JDK解压、配置环境变量 JAVA_HOME和PATH,验证java-version(如下都需要验证是否配置成功)
[root@hadoop101 software] # tar -zxf jdk-8u144-linux-x64.tar.gz -C /opt/module/
[root@hadoop101 software]# vi /etc/profile
#JAVA_HOME:
export JAVA_HOME=/opt/module/jdk1.8.0_144
export PATH=$PATH:$JAVA_HOME/bin
[root@hadoop101 software]#source /etc/profile
验证命令:java -version
2.Maven解压、配置 MAVEN_HOME和PATH
[root@hadoop101 software]# tar -zxvf apache-maven-3.0.5-bin.tar.gz -C /opt/module/
[root@hadoop101 apache-maven-3.0.5]# vi conf/settings.xml
<mirrors>
<mirror>
<id>nexus-aliyun</id>
<mirrorOf>central</mirrorOf>
<name>Nexus aliyun</name>
<url>http://maven.aliyun.com/nexus/content/groups/public</url>
</mirror>
</mirrors>
[root@hadoop101 apache-maven-3.0.5]# vi /etc/profile
#MAVEN_HOME
export MAVEN_HOME=/opt/module/apache-maven-3.0.5
export PATH=$PATH:$MAVEN_HOME/bin
[root@hadoop101 software]#source /etc/profile
验证命令:mvn -version
3.ant解压、配置 ANT _HOME和PATH
[root@hadoop101 software]# tar -zxvf apache-ant-1.9.9-bin.tar.gz -C /opt/module/
[root@hadoop101 apache-ant-1.9.9]# vi /etc/profile
#ANT_HOME
export ANT_HOME=/opt/module/apache-ant-1.9.9
export PATH=$PATH:$ANT_HOME/bin
[root@hadoop101 software]#source /etc/profile
验证命令:ant -version
4.安装 glibc-headers 和 g++ 命令如下
[root@hadoop101 apache-ant-1.9.9]# yum install glibc-headers
[root@hadoop101 apache-ant-1.9.9]# yum install gcc-c++
5.安装make和cmake
[root@hadoop101 apache-ant-1.9.9]# yum install make
[root@hadoop101 apache-ant-1.9.9]# yum install cmake
6.解压protobuf ,进入到解压后protobuf主目录,/opt/module/protobuf-2.5.0,然后相继执行命令
[root@hadoop101 software]# tar -zxvf protobuf-2.5.0.tar.gz -C /opt/module/
[root@hadoop101 opt]# cd /opt/module/protobuf-2.5.0/
[root@hadoop101 protobuf-2.5.0]#./configure
[root@hadoop101 protobuf-2.5.0]# make
[root@hadoop101 protobuf-2.5.0]# make check
[root@hadoop101 protobuf-2.5.0]# make install
[root@hadoop101 protobuf-2.5.0]# ldconfig
[root@hadoop101 hadoop-dist]# vi /etc/profile
#LD_LIBRARY_PATH
export LD_LIBRARY_PATH=/opt/module/protobuf-2.5.0
export PATH=$PATH:$LD_LIBRARY_PATH
[root@hadoop101 software]#source /etc/profile
验证命令:protoc --version
7.安装openssl库
[root@hadoop101 software]#yum install openssl-devel
8.安装 ncurses-devel库
[root@hadoop101 software]#yum install ncurses-devel
到此,编译工具安装基本完成。
5.3 编译源码
- 解压源码到/opt/目录
[root@hadoop101 software]# tar -zxvf hadoop-2.7.2-src.tar.gz -C /opt/ - 进入到hadoop源码主目录
[root@hadoop101 hadoop-2.7.2-src]# pwd
/opt/hadoop-2.7.2-src - 通过maven执行编译命令
[root@hadoop101 hadoop-2.7.2-src]#mvn package -Pdist,native -DskipTests -Dtar
等待时间30分钟左右,最终成功是全部SUCCESS,如图2-42所示。
![在这里插入图片描述]()
图2-42 编译源码 - 成功的64位hadoop包在/opt/hadoop-2.7.2-src/hadoop-dist/target下
[root@hadoop101 target]# pwd
/opt/hadoop-2.7.2-src/hadoop-dist/target - 编译源码过程中常见的问题及解决方案
(1)MAVEN install时候JVM内存溢出
处理方式:在环境配置文件和maven的执行文件均可调整MAVEN_OPT的heap大小。(详情查阅MAVEN 编译 JVM调优问题,如:http://outofmemory.cn/code-snippet/12652/maven-outofmemoryerror-method)
(2)编译期间maven报错。可能网络阻塞问题导致依赖库下载不完整导致,多次执行命令(一次通过比较难):
[root@hadoop101 hadoop-2.7.2-src]#mvn package -Pdist,nativeN -DskipTests -Dtar
(3)报ant、protobuf等错误,插件下载未完整或者插件版本问题,最开始链接有较多特殊情况,同时推荐
2.7.0版本的问题汇总帖子 http://www.tuicool.com/articles/IBn63qf

常见的分布式文件系统
GFS、HDFS、Lustre 、Ceph 、GridFS 、mogileFS、TFS、FastDFS等。各自适用于不同的领域。它们都不是系统级的分布式文件系统,而是应用级的分布式文件存储服务。
Google学术论文,这是众多分布式文件系统的起源
Google File System(大规模分散文件系统)
MapReduce (大规模分散FrameWork)
BigTable(大规模分散数据库)
Chubby(分散锁服务)
一般你搜索Google_三大论文中文版(Bigtable、 GFS、 Google MapReduce)就有了。
做个中文版下载源:http://dl.iteye.com/topics/download/38db9a29-3e17-3dce-bc93-df9286081126
做个原版地址链接:
http://labs.google.com/papers/gfs.html
http://labs.google.com/papers/bigtable.html
http://labs.google.com/papers/mapreduce.html
GFS(Google File System)
Google公司为了满足本公司需求而开发的基于Linux的专有分布式文件系统。。尽管Google公布了该系统的一些技术细节,但Google并没有将该系统的软件部分作为开源软件发布。
下面分布式文件系统都是类 GFS的产品。
HDFS
Hadoop 实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。 Hadoop是Apache Lucene创始人Doug Cutting开发的使用广泛的文本搜索库。它起源于Apache Nutch,后者是一个开源的网络搜索引擎,本身也是Luene项目的一部分。Aapche Hadoop架构是MapReduce算法的一种开源应用,是Google开创其帝国的重要基石。
Ceph
是加州大学圣克鲁兹分校的Sage weil攻读博士时开发的分布式文件系统。并使用Ceph完成了他的论文。
说 ceph 性能最高,C++编写的代码,支持Fuse,并且没有单点故障依赖, 于是下载安装, 由于 ceph 使用 btrfs 文件系统, 而btrfs 文件系统需要 Linux 2.6.34 以上的内核才支持。
可是ceph太不成熟了,它基于的btrfs本身就不成熟,它的官方网站上也明确指出不要把ceph用在生产环境中。
Lustre
Lustre是一个大规模的、安全可靠的,具备高可用性的集群文件系统,它是由SUN公司开发和维护的。
该项目主要的目的就是开发下一代的集群文件系统,可以支持超过10000个节点,数以PB的数据量存储系统。
目前Lustre已经运用在一些领域,例如HP SFS产品等。适合存储小文件、图片的分布文件系统研究
====================================
用于图片等小文件大规模存储的分布式文件系统调研
架构高性能海量图片服务器的技术要素
nginx性能改进一例(图片全部存入google的leveldb)
FastDFS分布文件系统
TFS(Taobao File System)安装方法
动态生成图片 Nginx + GraphicsMagick
MogileFS
由memcahed的开发公司danga一款perl开发的产品,目前国内使用mogielFS的有图片托管网站yupoo等。
MogileFS是一套高效的文件自动备份组件,由Six Apart开发,广泛应用在包括LiveJournal等web2.0站点上。
MogileFS由3个部分组成:
第1个部分是server端,包括mogilefsd和mogstored两个程序。前者即是 mogilefsd的tracker,它将一些全局信息保存在数据库里,例如站点domain,class,host等。后者即是存储节点(store node),它其实是个HTTP Daemon,默认侦听在7500端口,接受客户端的文件备份请求。在安装完后,要运行mogadm工具将所有的store node注册到mogilefsd的数据库里,mogilefsd会对这些节点进行管理和监控。
第2个部分是utils(工具集),主要是MogileFS的一些管理工具,例如mogadm等。
第3个部分是客户端API,目前只有Perl API(MogileFS.pm)、PHP,用这个模块可以编写客户端程序,实现文件的备份管理功能。
mooseFS
持FUSE,相对比较轻量级,对master服务器有单点依赖,用perl编写,性能相对较差,国内用的人比较多
MooseFS与MogileFS的性能测试对比
FastDFS
是一款类似Google FS的开源分布式文件系统,是纯C语言开发的。
FastDFS是一个开源的轻量级分布式文件系统,它对文件进行管理,功能包括:文件存储、文件同步、文件访问(文件上传、文件下载)等,解决了大容量存储和负载均衡的问题。特别适合以文件为载体的在线服务,如相册网站、视频网站等等。
官方论坛 http://bbs.chinaunix.net/forum-240-1.html
FastDfs google Code http://code.google.com/p/fastdfs/
分布式文件系统FastDFS架构剖析 http://www.programmer.com.cn/4380/
TFS
TFS(Taobao !FileSystem)是一个高可扩展、高可用、高性能、面向互联网服务的分布式文件系统,主要针对海量的非结构化数据,它构筑在普通的Linux机器 集群上,可为外部提供高可靠和高并发的存储访问。TFS为淘宝提供海量小文件存储,通常文件大小不超过1M,满足了淘宝对小文件存储的需求,被广泛地应用 在淘宝各项应用中。它采用了HA架构和平滑扩容,保证了整个文件系统的可用性和扩展性。同时扁平化的数据组织结构,可将文件名映射到文件的物理地址,简化 了文件的访问流程,一定程度上为TFS提供了良好的读写性能。
官网 : http://code.taobao.org/p/tfs/wiki/index/
GridFS文件系统
MongoDB是一种知名的NoSql数据库,GridFS是MongoDB的一个内置功能,它提供一组文件操作的API以利用MongoDB存储文件,GridFS的基本原理是将文件保存在两个Collection中,一个保存文件索引,一个保存文件内容,文件内容按一定大小分成若干块,每一块存在一个Document中,这种方法不仅提供了文件存储,还提供了对文件相关的一些附加属性(比如MD5值,文件名等等)的存储。文件在GridFS中会按4MB为单位进行分块存储。
MongoDB GridFS 数据读取效率 benchmark
http://blog.nosqlfan.com/html/730.html
nginx + gridfs 实现图片的分布式存储 安装(一年后出问题了)
http://www.cnblogs.com/zhangmiao-chp/archive/2011/05/05/2038285.html
基于MongoDB GridFS的图片存储
http://liut.cc/blog/2010/12/about-imsto_my-first-open-source-project.html
nginx+mongodb-gridfs+squid
http://1008305.blog.51cto.com/998305/885340

 浙公网安备 33010602011771号
浙公网安备 33010602011771号