

Mysql InnoDB数据结构
InnoDB 是按照索引来存储数据的;用户数据都存储在聚簇索引中;
每个索引有自己的数据空间,一个索引会有两个独立的空间(段 segment),一个段用来存储非叶子节点索引数据,一个段用来存储叶子节点数据;
段又会细分为64个块(extend - 1MB),每个块是由256个页(page - 16KB)组成,页编号在表空间中独立存储的,4个字节(32位),所以一个表空间大致可以存储64TB;
理论上来说每个段是一块独立连续的物理空间,主要是为了加载数据,方便进行顺序遍历数据,随机IO代价比较高,虽然底层页支持存储空间不是连续的;
为了方便段中数据管理,又将区分为3类:空闲、满和非满,组成3个链表,来实现数据的更改的管理;
数据插入都是先进入空闲和非满的碎片区,这些区暂时不属于某个段,(效率比较高);
当碎片区达到32个页,会对区进行迁移,将碎片区区分配到某个段下面;
页是最小的数据单元,读取数据时,都是一整页读入内存;
为了提高查询速度,又会将页中的记录数据进行分组,每4-8条分为一组,每组的最小值(索引列的值)形成一个链表;
索引形成的B+树,聚簇索引会按照 (主键、所在页最小值、其他列数据(叶子节点))为单元,主键大小排序形成一颗树,每一层数据都是以页为单位存储;
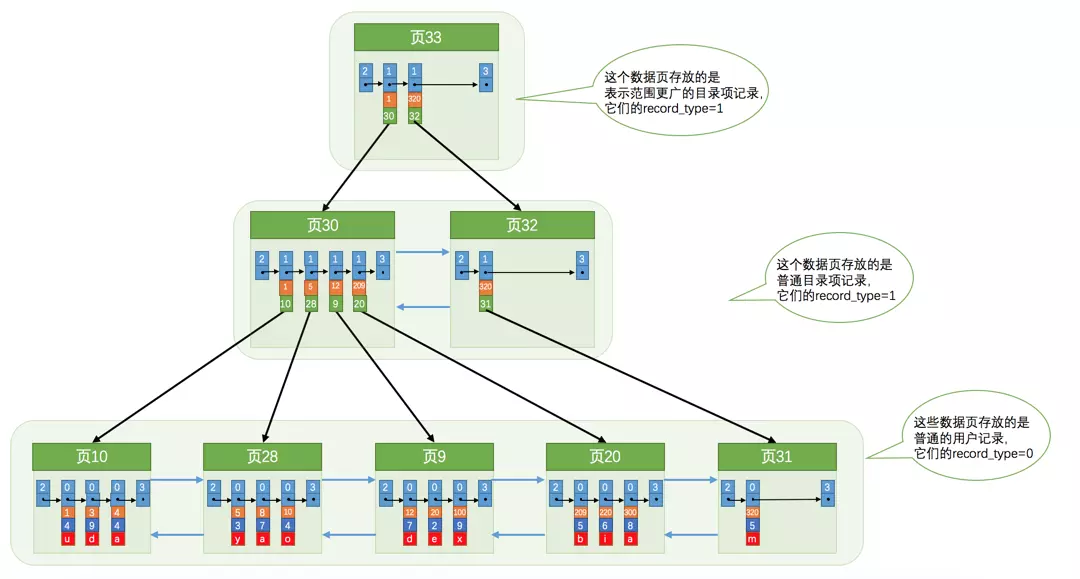
普通二级索引,叶子节点就不会存储每条记录的详细信息了,只会存储记录的主键信息,类似:
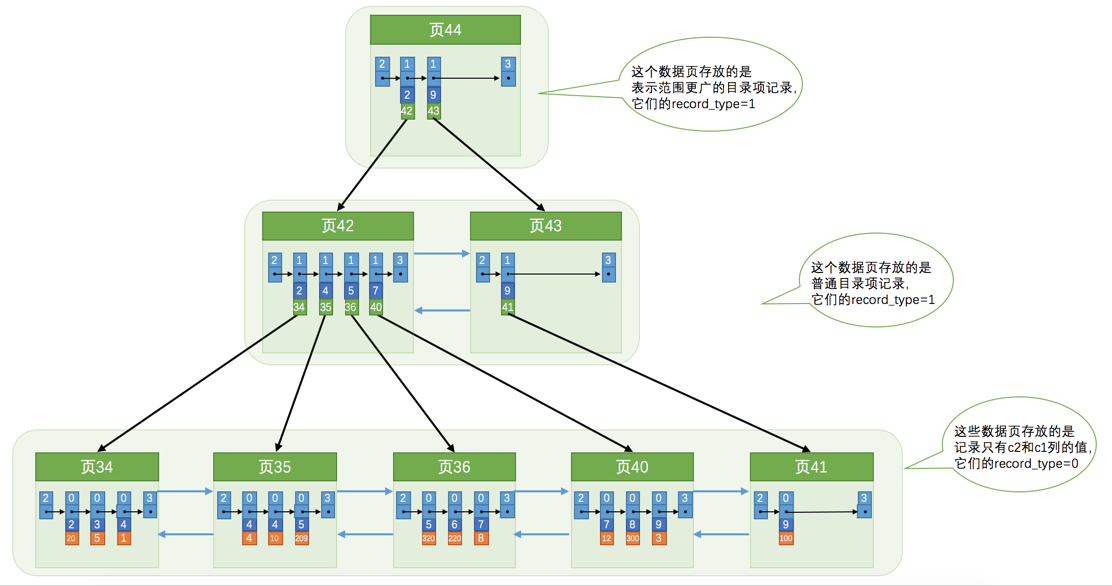
所以二级索引如果不能查询的数据不能覆盖索引,那么就需要通过二级索引查询聚簇索引,在通过聚簇索引查询数据记录;简称回表;
总结:
索引主要思想是:将数据排序分组,然后将边界值再重新组成一个新的组,组中的数据以链表的方式连接;
通过二分查找的方式来快速定位数据所在的页;
本文参考 掘金小册:MySQL是怎样运行的

