

[PocketFlow]更改网络结构之后,输出维度正确,AP还是低?
1. 问题
继上上次TensorFlow挂起无输出后,又遇到一令人发指的bug。在原始的PeleeNet基础上,更改了Stemblock、DenseBlock,替换卷积,增加cbam、FPN模块之后,虽然网络最后输出tensor的shape正确,但AP仍然直逼上次的bug,仅为Pelee的1/10。
2. 解决
这算是师兄出去实习后的一个历史遗留问题。走之前就提到改了网络结构之后训练的效果不好,要我看看问题在哪,但我在前两次惨痛的经历之后才算走上正轨。开始是因为坑爹的TensorFlow没有上采样操作,带sample字眼的就只有tf.keras.layers.convolutional.UpSampling2D,而这玩意还只能进行整数倍的放大(最后的feature maps 大小为[2,3,5,10...],故放弃)。只好用tf.image.resize做,但是这函数也是一脸的不靠谱像。师兄觉得可能是这个操作的问题,走之前提了一嘴。所以我的前期工作都是围绕着上采样展开。
2.1 上采样
依次使用了:
tf.image.resize_bilinear: 功能貌似和不带bilinear的差不多,但点开函数定义,看见带grad啥的,看着安心一点。tf.nn.conv2d_transpose: 不用tf.layers.conv2d_transpose好像是因为不能指定output_shape大小,中途尺寸还匹配错误,具体的忘了。最后只好用nn的,这玩意还需要自己用get_variable初始化卷积核再当参数传进来...
试过不同学习率,训练地也比较彻底,但是都失败了(转置卷积能高1个点左右)
2.2 tf.keras.layers 和 tf.layers
后来看实现Pelee时全部用的是tf.layers和tf.nn,而在更改的网络结构中使用了tf.keras.layers,会不会是两者不兼容导致的?随意在Pelee网络中把一个tf.layers.Conv2D改为tf.keras.layers.Conv2D,md居然还报错了:
InvalidArgumentError (see above for traceback): Inputs to operation model/gradients/AddN_449 of type AddN must have the same size and shape. Input 0: [3,3,16,16] != input 1: [1,1,32,16]
[[node model/gradients/AddN_449 (defined at /home/xxx/xxxxx/PocketFlow/learners/full_precision/learner.py:181) = AddN[N=2, T=DT_FLOAT, _device="/job:localhost/replica:0/task:0/device:GPU:0"](model/gradients/model/L2Loss_12_grad/mul, model/gradients/model/peleenet-ssd/stage_1/dense_block_0/conv2d_4/Conv2D_grad/Conv2DBackpropFilter, ^model/gradients/model/peleenet-ssd/stage_1/dense_block_0/conv2d_4/Conv2D_grad/Conv2DBackpropInput)]]
说什么反向传播时卷积核维度不匹配???但是在另一个地方改了之后又鬼事没有,我是真的佛了。StackOverflow上面提问,但是没人鸟我。
虽然tf.layers就是在tf.keras.layers上封装了一层,但本着严谨的态度,我还是用原生API又写了一遍网络,然而没卵用。(就算是这个的问题,我也不看了)
2.3 attention
2.3.1 softmax
再后来读了cbam的论文,发现spacial_attention模块的实现有点问题:
def spatial_attention(self, inputs):
max = tf.reduce_max(inputs, axis=-1, keep_dims=True)
avg = tf.reduce_mean(inputs, axis=-1, keep_dims=True)
x = tf.concat([avg, max], -1)
conv = tf.layers.Conv2D(1, 3, 1, "same", use_bias=False)(x)
return tf.nn.softmax(conv_)
这里的Softmax默认是在 axis=-1 进行,也就是channel维度。 但是经过reduce之后feature maps的channel数已经是1了,再用softmax的话就全变为1了。应该改为如下:
def spatial_attention(self, inputs):
max = tf.reduce_max(inputs, axis=-1, keep_dims=True)
avg = tf.reduce_mean(inputs, axis=-1, keep_dims=True)
x = tf.concat([avg, max], -1)
conv = tf.layers.Conv2D(1, 3, 1, "same", use_bias=False)(x)
# fix bug of softmax
shape = tf.shape(conv)
conv_ = tf.reshape(conv, [shape[0], -1])
conv_ = tf.nn.softmax(conv_)
return tf.reshape(conv_, shape)
我差点以为找到bug了,结果一想最后的输出结果是 channel_attention(feature)\*spacial_attention(feature)\*feature,这样就算space全为1,对结果应该也没有什么影响。实验验证改了之后AP还是原样。
这时候差不多心凉了,只能在原来Pelee的基础上一个一个更改模块,排查错误了。结果加上attention模块之后AP就掉到1/10了!这就说明attention模块肯定是有问题了,带着这个想法,在更改过后的网络中去掉了attention模块,意外的是AP并没有恢复到正常水平。虽然不愿承认,但网络中除了attention模块,还有其他的问题(又回到心凉的状态)。
不过我就纳闷了,我就加了这三行attention的代码,就能把整个网络的结构破坏了?CVPR19还有篇randwire(大概是这个名字?)说随机设计的网络结构效果比手工的好呢!就算还有其他问题,也先把这个解决了!在github上找了cbam的实现,和我的大体一致,将attention模块替换成github上的,依旧凉。
2.3.2 l2_normalize
仔细看了下增加的attention模块的代码:
with tf.variable_scope("attention"):
for i, feature in enumerate(feature_layers):
feature_layers[i] = self.spatial_attention(feature) * self.channel_attention(feature) * feature
with tf.variable_scope("normalize"):
for i, feature in enumerate(feature_layers):
feature_layers[i] = tf.nn.l2_normalize(feature)
这我只能怀疑是normalize的问题了吧?接着看了PyTorch实现的网络结构,坑爹的来了:PyTorch的normalize默认dim=1,即在channel维度上操作,按前面softmax函数axis=None代表-1,讲道理l2_normalize默认axis=None也该是-1吧?但别人调的是reduce_sum,是all dimension!抱着最后一丝希望将axis指定为-1,AP终于正常了:
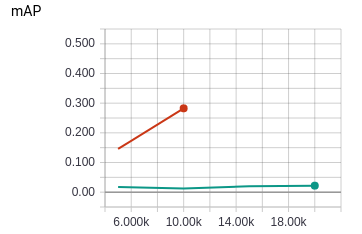
最后在改过的网络上验证,第5k次迭代mAP为5左右,虽然高了点,心里还是有点慌,结果到10k时已经达到22了!(留下了辛酸的泪水)
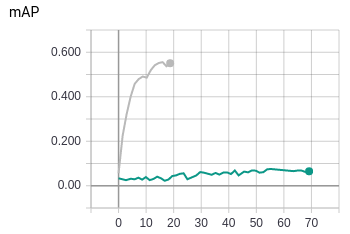
我试着分析了一下原因,感觉还是不是很理解,下次组会上问一下看看。看来normalization这一块值得研究。
3. 后记
这次历时1个月的debug中,看了Stanford的cs20si: TensorFlow for deep learning research的课程slides,TF入门教程,属实良心。debug中很多小实验都是看懂了这个才能轻松按自己的想法实现的(之后有时间会回顾整理成博客)。如果TensorFlow的官方tutorial也能像这个课一样说人话、API不要改的比学的还快,应该就不会劝退这么多人了吧(不过tfrecord和data API结合用起来GPU利用率确实比PyTorch高多了)!
PocketFlow的程序结构确实很不错,训练和评估都封装的很完善,对扩展也比较友好,作者还是CVPR大佬,膜拜。
等把这个网络的TF版本在COCO上训练成功再量化之后我就可以出坑了!
另外,看来PyTorch和TensorFlow都得学啊!
