

近期阅读论文总结
0. 论文关系图
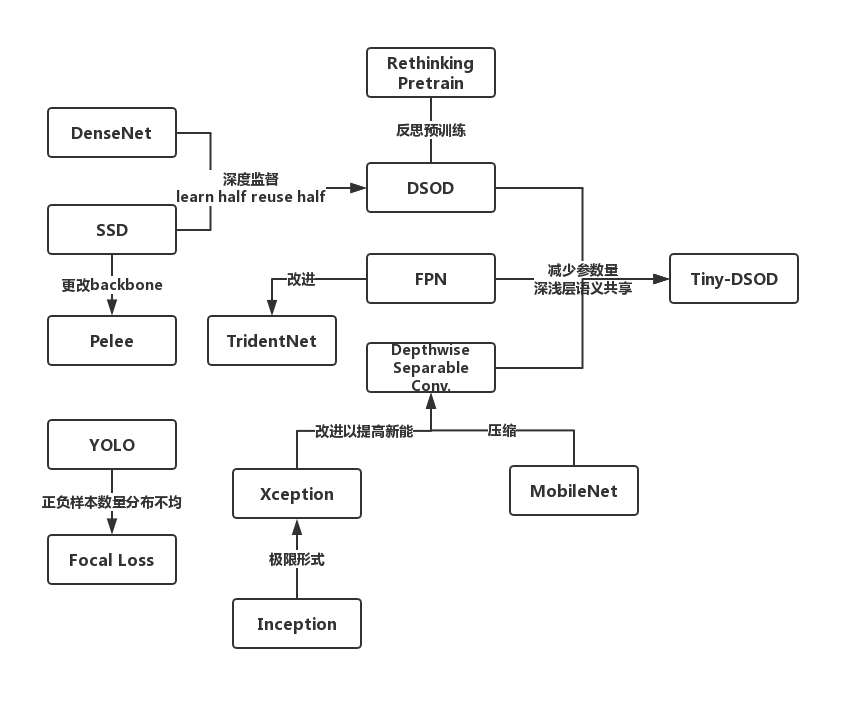
近期做的目标检测项目,写代码的时候为了理解地更透彻,看了一些相关的论文。现在写一些自己的总结,我一直觉得心里想的和写出来的是不同的,用文字记录的时候也在思考,所以更像是对自己思考的一个refine的过程。(明天汇报,怕忘了而已)
1. YOLO、SSD、Focal Loss
首先是两篇one-stage检测的论文:SSD和YOLO,SSD的backbone更改(加上了一些stem block、dense block等)之后得到了Pelee,是一个相对轻量级的检测器。后续网络结构的改动都是在这个上面进行。one-stage检测方法相比two-stage其中一个缺点就是正负样本数量不均,在SSD中采用难例挖掘(HNM, hard negative mining)使正负样本比例控制在1:3;而YOLO中则通过降低置信度低的物体的loss加权来避免过多的负样本影响模型的训练。Focal Loss是对这个问题的一种改进,它在交叉熵的基础上乘上了一个\((1-p_{t})^\gamma\),\(p_{t}\)是分类概率,因此当\(\gamma \gt 0\)时会降低容易分类的样本的权重,而难例则受影响比较小,因此让训练focus到难例上面来。相比HNM的直接截断,Focal Loss的处理方式比较温和,但其实我觉得Focal Loss和YOLO中的处理方式就有点像,YOLO中提到:
Also, in every image many grid cells do not contain any object. This pushes the “confidence” scores of those cells towards zero, often overpowering the gradient from cells that do contain objects.
我理解的是图像中不含obj的cell占多数,这样会导致网络一直在试图降低noobj那一项,从而影响含obj的cell的梯度下降。而YOLO就加了一个\(\lambda_{noobj} = 0.5\)来降低这部分的权重。让训练重点转移到含有obj的项。
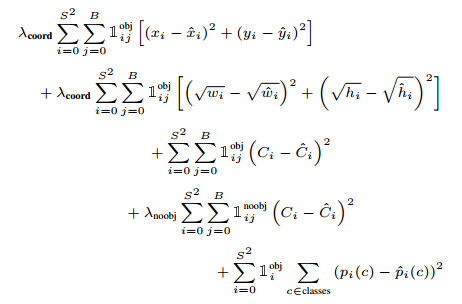
2. DSOD、Pretraining
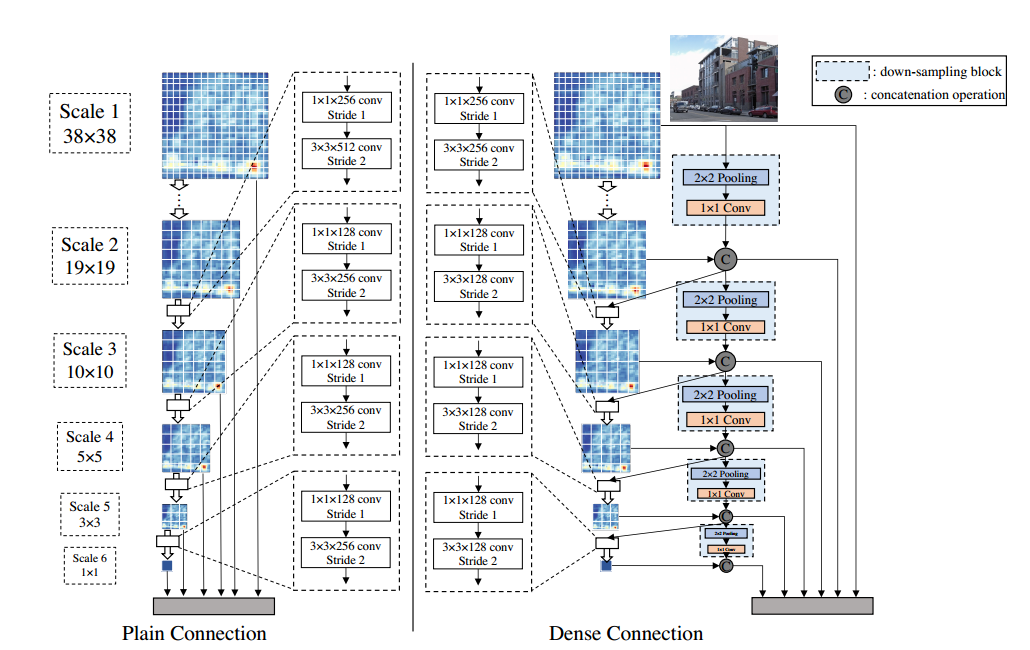
SSD结合DenseNet的思想得到DSOD,DSOD除了backbone,预测层也改为了dense连接的结构,希望不仅仅是对output layer,对之前的层也进行一些隐式的deep supervision。DSOD中一个比较值得注意的改动是:特征图A,经过卷积之后size变为1/4,得到B,同时A经过下采样和1x1卷积得到shape和B相同的C,将B和C进行特征融合得到下一层的输入。文中说到这样“learn half, reuse half”的策略相比plain structure能以更少的参数得到更高的准确率。DSOD是第一个train from stratch的目标检测网络,实验证明两阶段模型不经过预训练的话很难收敛,基本都失败了。
We observe that only the proposal-free method (the 3rd category) can converge successfully without the pre-trained models. We conjecture this is due to the RoI (Regions of Interest) pooling in the other two categories of methods — RoI pooling generates features for each region proposals, which hinders the gradients being smoothly back-propagated from region-level to convolutional feature maps. The proposal-based methods work well with pretrained network models because the parameter initialization is good for those layers before RoI pooling, while this is not true for training from scratch.
作者认为是ROI Pooling使梯度不能平稳地从region-level传递到 feature map。然而对预训练模型fine-tuning可以收到比较好的结果是因为ROI Pooling之前的层拥有一个比较好的初值,而from scratch就没有。后来Rethinking ImageNet Pre-training也对预训练进行了一些思考,使用了Group Norm和Sync Norm好像就可以从头训练两阶段了,不是很了解这俩...
3. Tiny-DSOD、FPN、Depthwise Separable Conv.
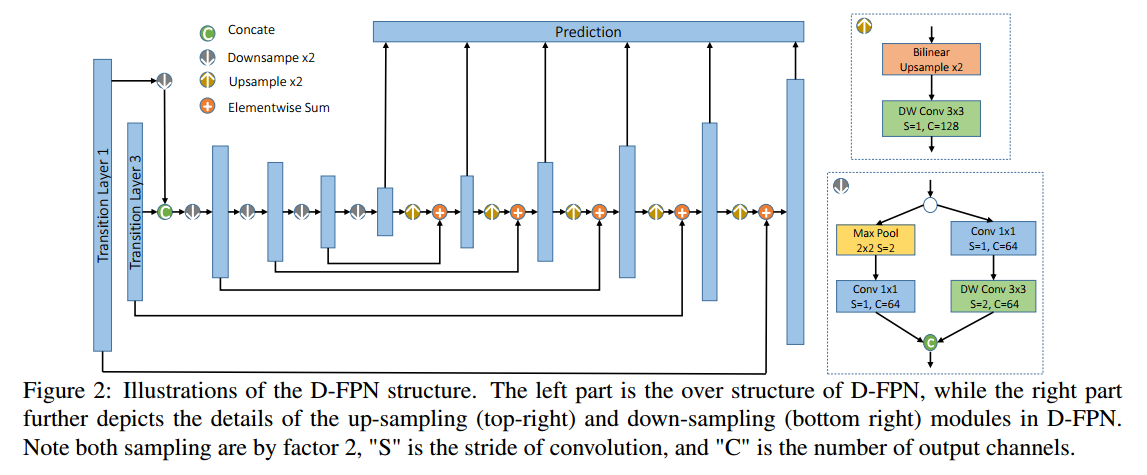
结合DSOD、FPN以及深度可分卷积得到了Tiny-DSOD,tiny主要是因为深度可分卷积减少了参数量。它认为SSD和DSOD最后的预测层因为浅层和深层的特征图不相通,导致浅层的特征图缺乏语义信息,而FPN这种结构就是既利用了深层较强的语义特征(利于分类),又利用了深层的高分辨率信息(利于定位),使深层和浅层的信息得到了共享。深度可分卷积在MobileNet和Xception中都有提到,但是两者的动机不同,结构顺序也稍有不同。以Xception为例,它的目的是尽可能的让卷积核分开来学习空间和通道间的相关性。首先仅保留Inception中的3x3卷积分支,之后将不同分支的1x1卷积拼接在一起,最后进一步增多3x3卷积分支的数量,使它与1x1卷积的输出通道数相等,这样就得到了Inception的极限模式。
4. TridentNet
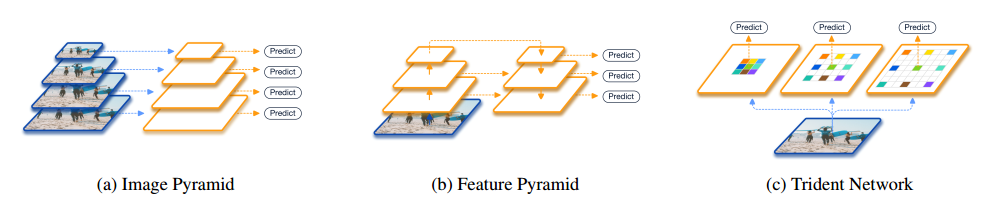
最后是TridentNet,它认为FPN对不同尺寸的物体的表达能力还是有差异,因为不同尺寸物体的特征是由FPN的不同层提取的。
To compensate the absence of semantics in low-level features, FPN [26] (Figure 1(b)) further augments a top-down pathway and lateral connections to incorporate strong semantic information in high-level features. However, the representational power for objects of different scales still differ, since their features are extracted on different layers in FPN. This makes feature pyramids an unsatisfactory alternative for image pyramids.
它希望网络能同等对待不同大小的目标,因此不同尺寸的目标经历的一系列图像操作都应该相同,从而使模型最后对不同尺寸目标都有一个统一的表达能力。因为卷积核大小不变的情况下,FPN中特征图变小实际上等价于感受野变大,所以TridentNet提出了一种不同分支参数共享,但卷积核的dilate rate不同的结构。而因为不同分支卷积核的感受野不同,实际上每个卷积核在不同尺寸上得到了充分训练。在推导时可以只取一条支线进行近似,以提高运行速度。
5. Reference
主要是自己的思考和平时到处的摘抄(没记录出处...)
You Only Look Once: Unified, Real-Time Object Detection
SSD: Single Shot MultiBox Detector
Pelee: A Real-Time Object Detection System on Mobile Devices
Focal Loss for Dense Object Detection
Densely Connected Convolutional Networks
DSOD: Learning Deeply Supervised Object Detectors from Scratch
Feature Pyramid Networks for Object Detection
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
Going deeper with convolutions
Xception: Deep Learning with Depthwise Separable Convolutions
Tiny-DSOD: Lightweight Object Detection for Resource-Restricted Usages
Rethinking ImageNet Pre-training
Scale-Aware Trident Networks for Object Detection
