Flink入门
Flink是什么?
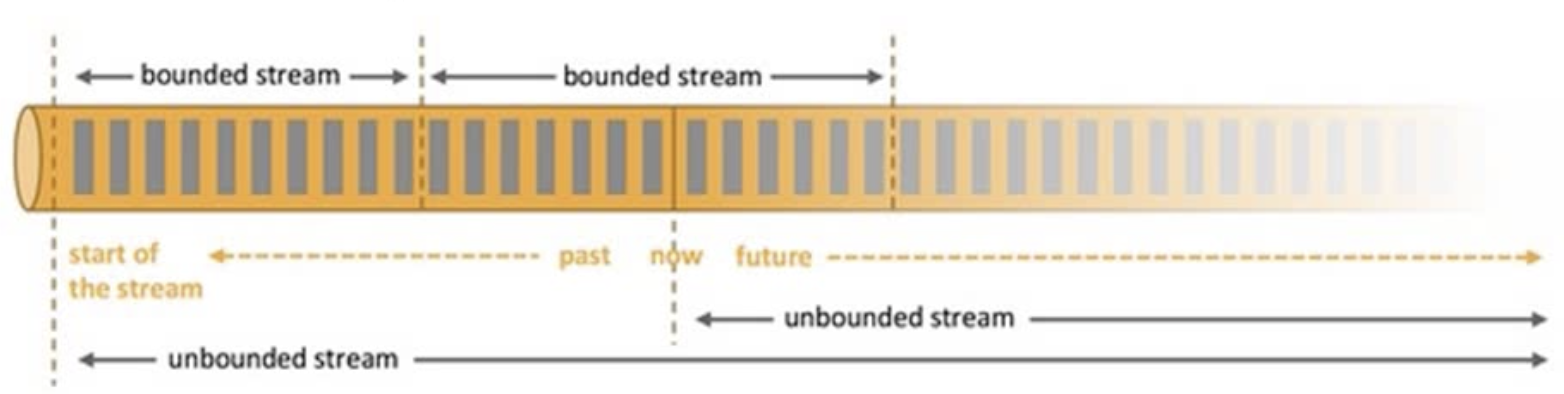
Apache Flink 是一个框架和分布式处理引擎,用于处理无界和有界的数据流进行状态计算。
为什么选择Flink
- 流数据更真实地反应我们的生活方式(聊天、导航、转账)
- 传统的数据架构是基于有限数据集的
- 我们的目标
- 低延迟
- 高吞吐
- 结果的准确性和良好的容错性
哪些行业需要处理流数据
- 电商和市场营销
数据报表、广告投放、业务流程需要
- 物联网
传感器实时数据采集和显示、实时报警、交通运输业
- 电信业
基站流量调配
- 银行和金融业
实时结算和通知推送,实时监测异常行为
Flink下载安装
https://www.apache.org/dyn/closer.lua/flink/flink-1.10.1/flink-1.10.1-bin-scala_2.11.tgz
Flink word count 案例
maven依赖
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_2.11</artifactId>
<version>1.7.2</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.11</artifactId>
<version>1.7.2</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.4.6</version>
<executions>
<execution>
<goals>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
批处理 word count 程序
在resource目录下创建一个hello.txt文件
hello word
hello scala
hello fink
hello spark
/** * 批处理 word count 程序 */ object WordCount { def main(args: Array[String]): Unit = { // 创建一个执行环境 val env = ExecutionEnvironment.getExecutionEnvironment // 从文件中读取数据 val inputPath = "/Users/qiunan/IdeaProjects/FlinkTutorial/src/main/resources/hello.txt" val inputDataSet = env.readTextFile(inputPath) // 切分数据得到word 然后再按word做分组聚合 val wordCountDataSet = inputDataSet.flatMap(_.split(" ")) .map((_,1)) .groupBy(0) .sum(1) wordCountDataSet.print() } }
打印结果
(scala,1) (spark,1) (word,1) (fink,1) (hello,4)
流处理word count 程序
/** * 流处理word count 程序 */ object StreamWordCount { def main(args: Array[String]): Unit = { // 创建流处理的执行环境 val env = StreamExecutionEnvironment.getExecutionEnvironment // 接受一个socket文本流 val dataStream = env.socketTextStream("localhost", 777); // 对每条数据进行处理 val wordCountDataStream = dataStream.flatMap(_.split(" ")) .filter(_.nonEmpty) .map((_, 1)) .keyBy(0) .sum(1) wordCountDataStream.print() // 启动executor env.execute(); } }
启动程序 在终端窗口输入 nc -lk 777
qiunan@qiunandeiMac ~ % nc -lk 777
hello word
hello flink
hello spark
打印结果
5> (word,1) 2> (hello,1) 5> (flink,1) 2> (hello,2) 2> (hello,3) 1> (spark,1)
Flink是什么?
Apache Flink 是一个框架和分布式处理引擎,用于处理无界和有界的数据流进行状态计算。
为什么选择Flink
- 流数据更真实地反应我们的生活方式(聊天、导航、转账)
- 传统的数据架构是基于有限数据集的
- 我们的目标
- 低延迟
- 高吞吐
- 结果的准确性和良好的容错性
哪些行业需要处理流数据
- 电商和市场营销
数据报表、广告投放、业务流程需要
- 物联网
传感器实时数据采集和显示、实时报警、交通运输业
- 电信业
基站流量调配
- 银行和金融业
实时结算和通知推送,实时监测异常行为
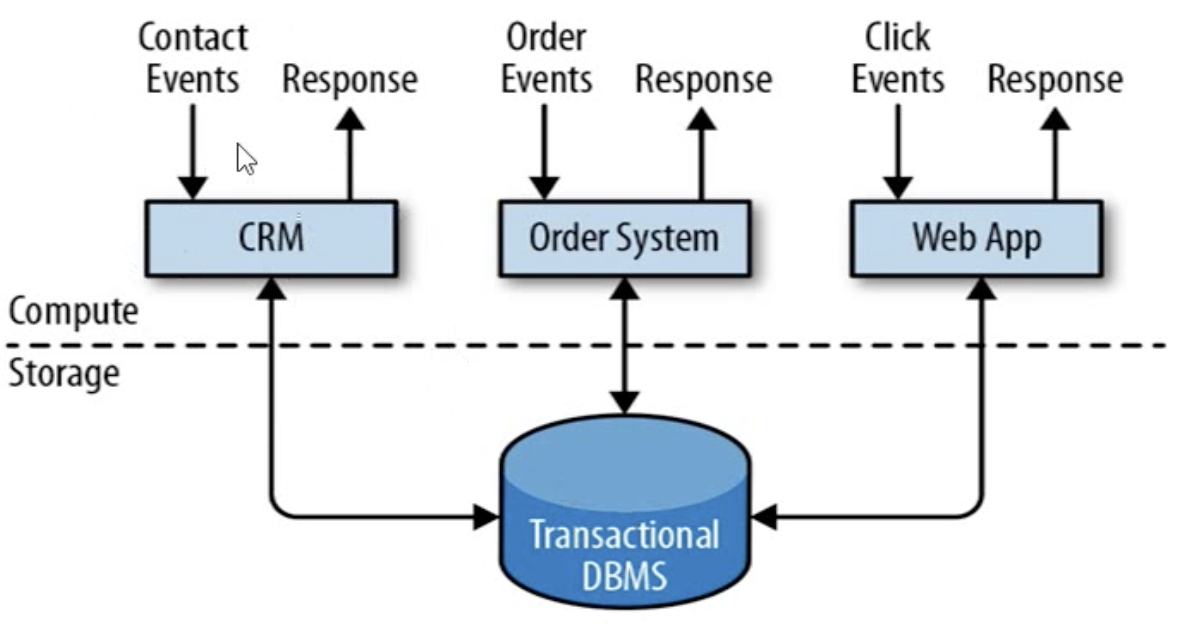
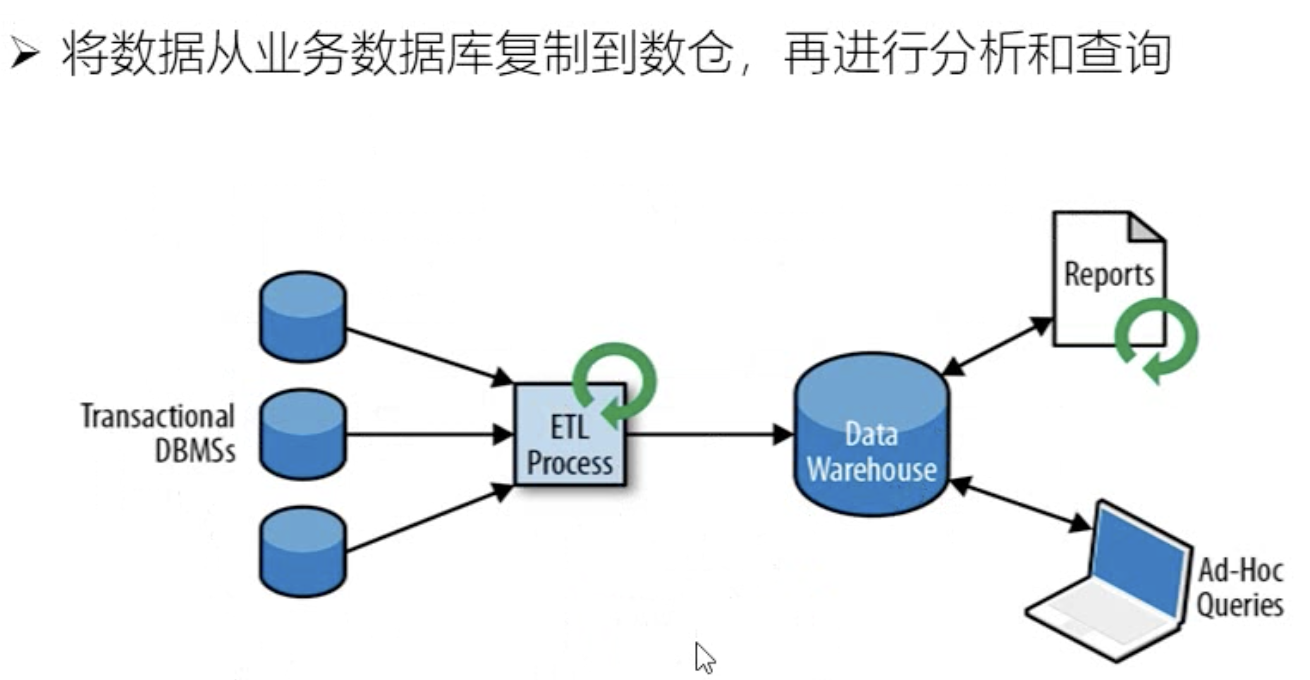
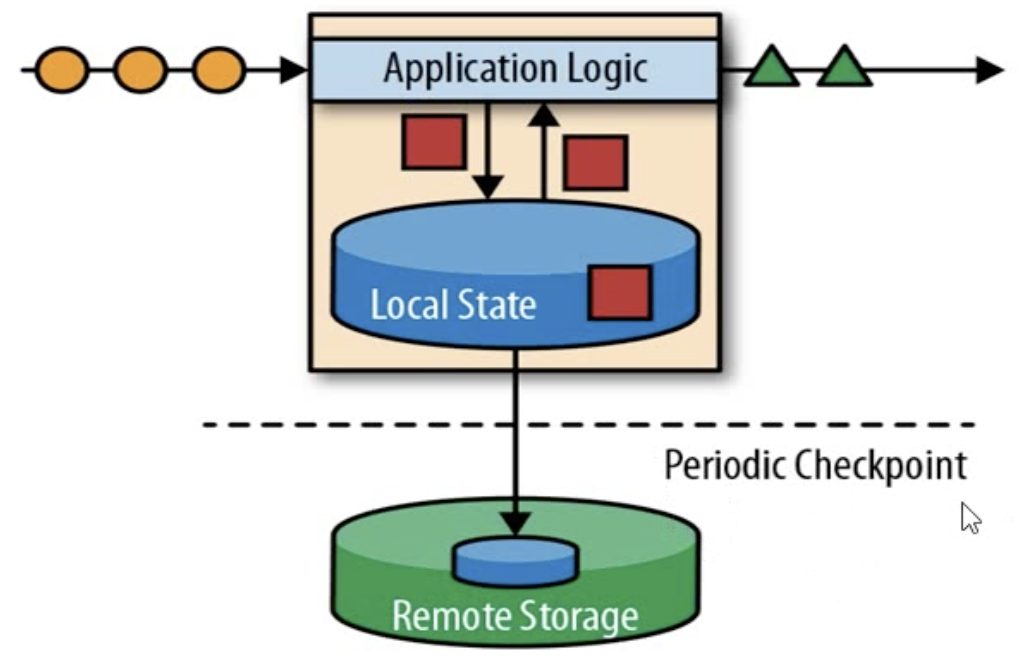
传统数据处理架构
- 事务处理
- 分析处理
- 有状态的的流式处理
流处理的演变
- lambda架构
用两套系统,同时保证低延迟和结果准确

- flink
Flink的主要特点
- 事件驱动

- 基于流的世界观
Flink的其他特点
- 支持事件事件(event-time)和处理事件(processing-time)语义
- 精确一次(exactly-once)的状态一致性保证
- 低延迟,每秒处理数百万个事件,毫秒级延迟
- 与众多常用存储系统的连接
- 高可用,动态扩展,实现7*24小时全天候运行
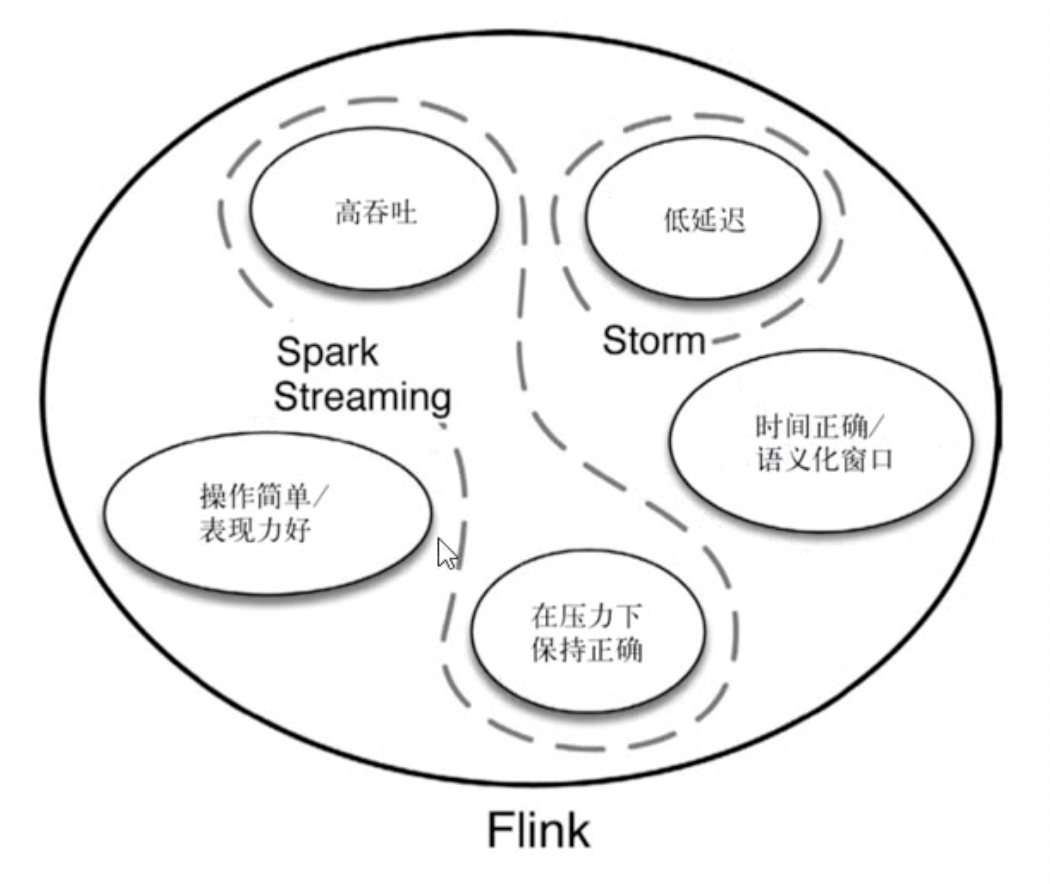
Flink vs Spark Streaming
- 数据模型
spark采用RDD模型,spark streaming 的DStream实际上也就是一组组小批数据RDD的集合
flink基于数据模型时数据流,以及事件(Event)序列
- 运行时架构
spark是批计算,将DAG划分为不同的stage,一个完成后才可以算下一个
flink是标准的流执行模式,一个事件在一个节点处理完成后就可以直接发往下一个节点进行处理
Flink下载安装
https://www.apache.org/dyn/closer.lua/flink/flink-1.10.1/flink-1.10.1-bin-scala_2.11.tgz
Flink word count 案例
maven依赖
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_2.11</artifactId>
<version>1.7.2</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.11</artifactId>
<version>1.7.2</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.4.6</version>
<executions>
<execution>
<goals>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
批处理 word count 程序
在resource目录下创建一个hello.txt文件
hello word
hello scala
hello fink
hello spark
/** * 批处理 word count 程序 */ object WordCount { def main(args: Array[String]): Unit = { // 创建一个执行环境 val env = ExecutionEnvironment.getExecutionEnvironment // 从文件中读取数据 val inputPath = "/Users/qiunan/IdeaProjects/FlinkTutorial/src/main/resources/hello.txt" val inputDataSet = env.readTextFile(inputPath) // 切分数据得到word 然后再按word做分组聚合 val wordCountDataSet = inputDataSet.flatMap(_.split(" ")) .map((_,1)) .groupBy(0) .sum(1) wordCountDataSet.print() } }
打印结果
(scala,1) (spark,1) (word,1) (fink,1) (hello,4)
流处理word count 程序
/** * 流处理word count 程序 */ object StreamWordCount { def main(args: Array[String]): Unit = { // 创建流处理的执行环境 val env = StreamExecutionEnvironment.getExecutionEnvironment // 接受一个socket文本流 val dataStream = env.socketTextStream("localhost", 777); // 对每条数据进行处理 val wordCountDataStream = dataStream.flatMap(_.split(" ")) .filter(_.nonEmpty) .map((_, 1)) .keyBy(0) .sum(1) wordCountDataStream.print() // 启动executor env.execute(); } }
启动程序 在终端窗口输入 nc -lk 777
qiunan@qiunandeiMac ~ % nc -lk 777
hello word
hello flink
hello spark
打印结果
5> (word,1) 2> (hello,1) 5> (flink,1) 2> (hello,2) 2> (hello,3) 1> (spark,1)
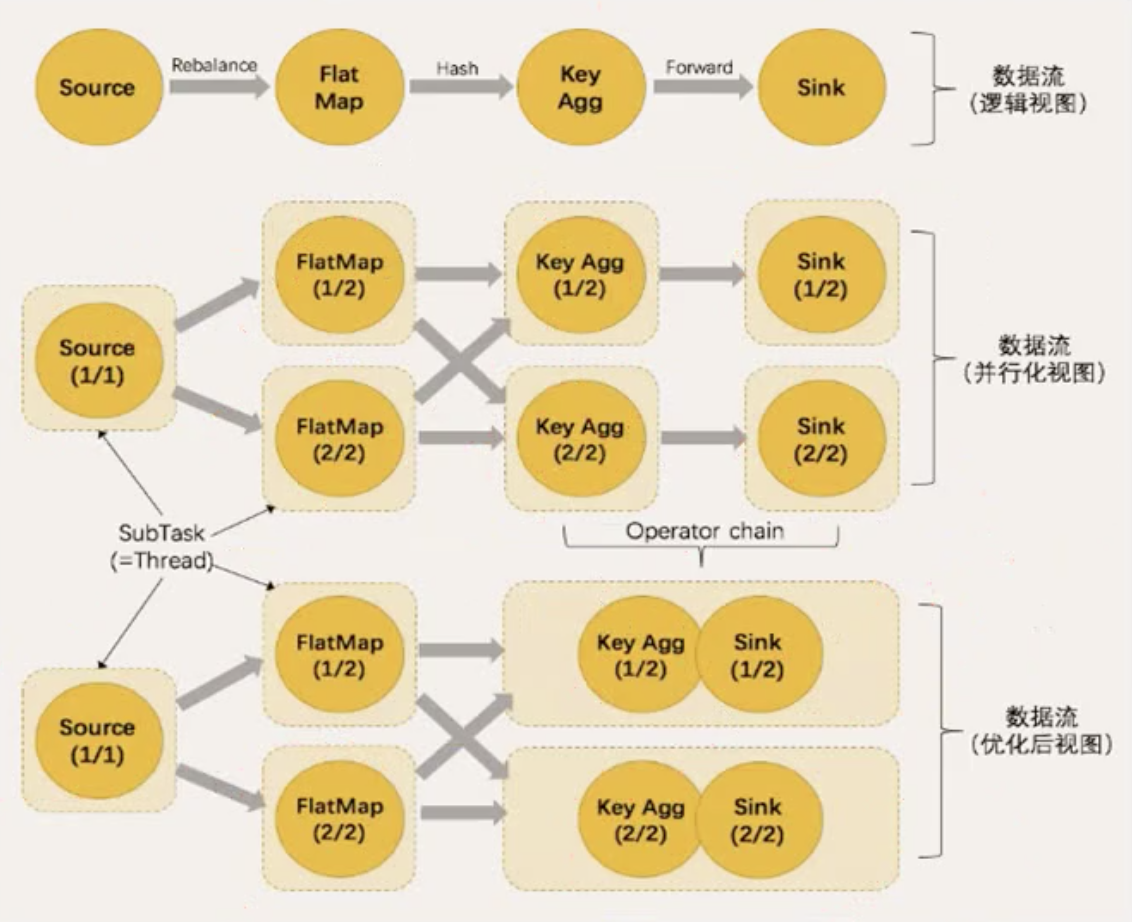
任务提交流程
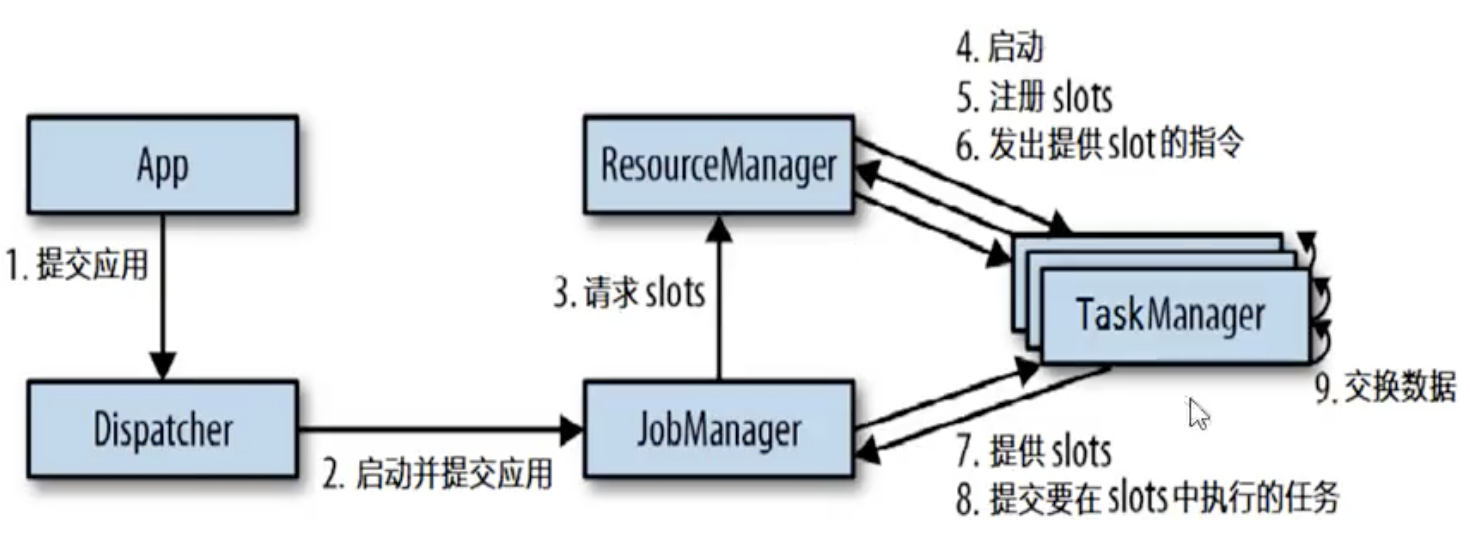
任务提交流程(YARN)
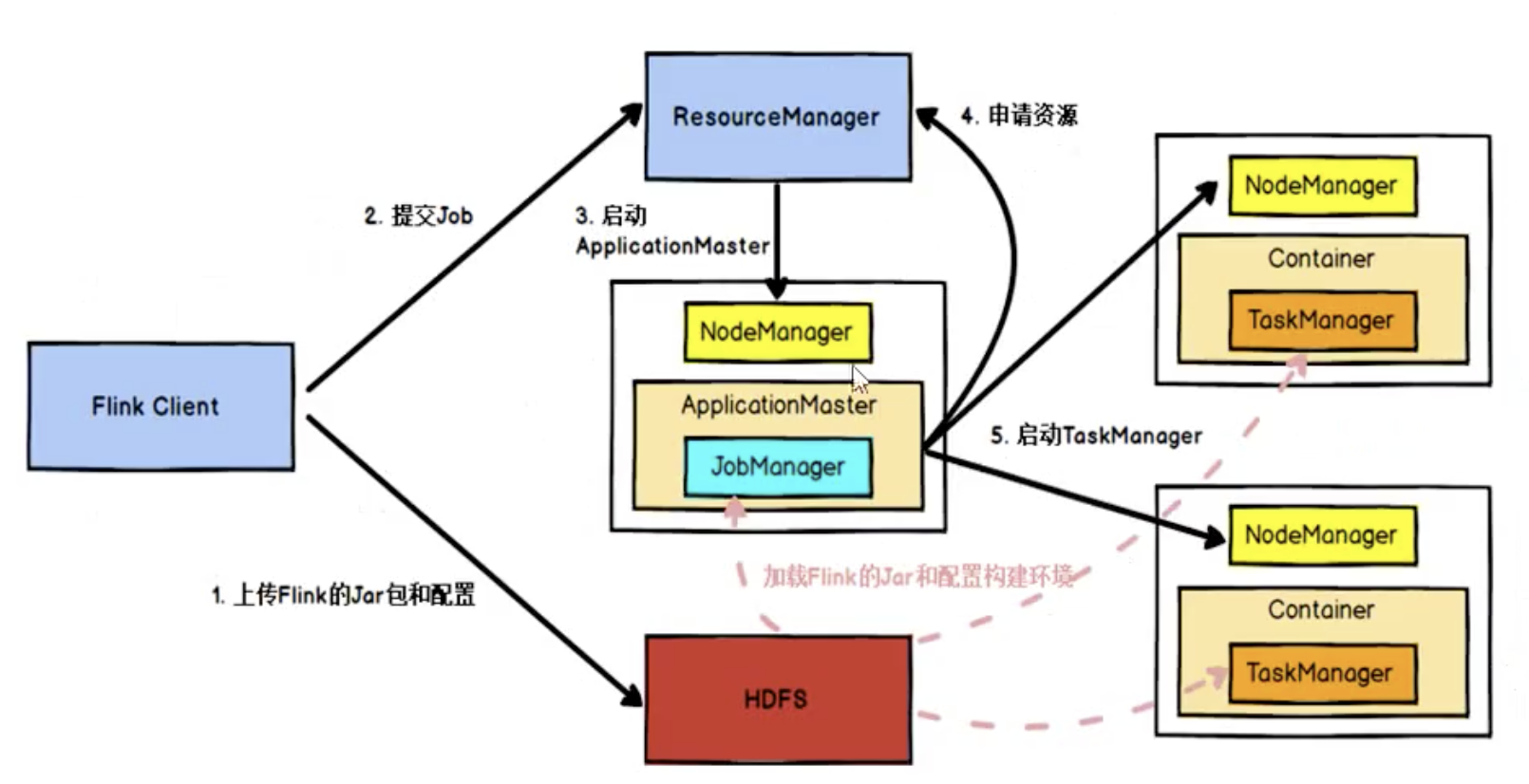
TaskManager 和 Slots
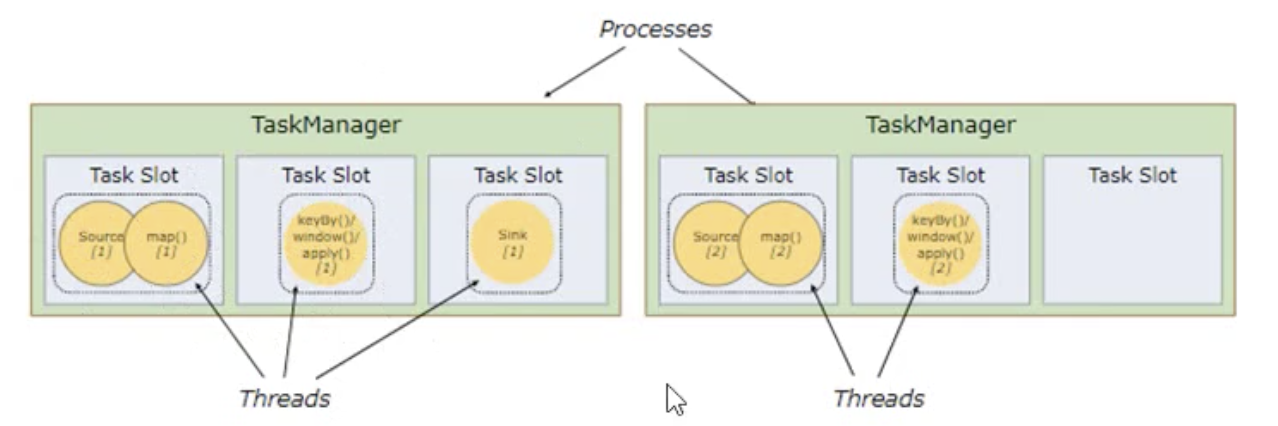
TM --- process进程
Task on slot --- thread 线程
每个线程执行在固定的计算资源上,这个资源就是slot
solt之间内存时独享的,cpu不时独享的
所以slot数量最好配成cpu核心数
并行的概念:
数据并行 --- 同一任务,不同的并行子任务,同时处理不同的数据
任务并行 --- 同一时间,不同的slot在执行不同的任务
一个流处理程序需要的slot数量,其实就是所有任务中最大的那个并行度
如果并行度相同、one to one 数据传输,那么可以把多个算子合并成一个任务
TM数量和slot数量,决定了并行处理的最大能力
但是不一定程序执行时一定都用到。程序执行时的并行度才是用到的能力(动态)
任务链(Operator Chains)