
java基础面试题
"=="和"equals"的区别
"=="用来判断两个变量之间的值是否相等,变量可以分为基础数据类型、引用类型。基本数据类型直接比较值而引用类型则比较引用内存首地址。
"equals"比较的是两个对象的内容是否一样。
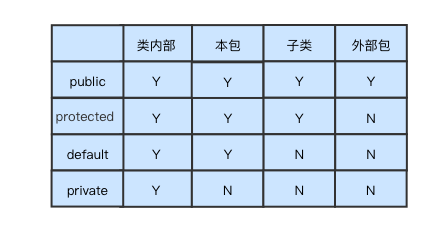
java访问修饰符
<? extends T>和<? super T>
<? extends T>和<? super T>是Java泛型中的“通配符(Wildcards)”和“边界(Bounds)”的概念。
<? extends T>:是指 “上界通配符(Upper Bounds Wildcards)”
<? super T>:是指 “下界通配符(Lower Bounds Wildcards)”
- 频繁往外读取内容的,适合用上界Extends。
- 经常往里插入的,适合用下界Super。
多态
编译时多态:方法的重载
运行时多态:向上造型和方法的重写
事物在运行过程中存在不同的状态,多态存在三前提
1、要有继承关系
2、子类要重写父类的方法
3、父类引用指向子类
为什么有了数组还需要集合
数组不是面向对象的,存在明显的缺陷,集合弥补了数组的缺点,比数组更灵活更实用,而且不同的集合框架类可适用不同场合。如下:
1、数组能存放基本数据类型和对象,而集合类存放的都是对象的引用,而非对象本身!
2、数组容易固定无法动态改变,集合类容量动态改变。
3、数组无法判断其中实际存有多少元素,length只告诉了数组的容量,而集合的size()可以确切知道元素的个数
4、集合有多种实现方式和不同适用场合,不像数组仅采用顺序表方式
5、集合以类的形式存在,具有封装、继承、多态等类的特性,通过简单的方法和属性即可实现各种复杂操作,大大提高了软件的开发效率
集合详解 https://www.cnblogs.com/ysocean/p/6555373.html
讲一下java中的集合
java中的集合分为value(Collection)、key-value(Map)两种
存储值又分为List和Set
1、List是有序的,可以重复的(常用的有ArrayList和LinkedList)
ArrayList底层使用的是数组,LinkedList使用的是链表
(1) 数组查询具有索引查询特定元素较快,而插入和删除较慢(数组在内存中是一块连续的空间,如果插入或删除需要移动内存)
(2) 链表不要求内存是连续的,在当前元素中存放下一个或上一个元素的地址,查询时需要从头部开始,一个一个的找,所以查询效率低,插入、删除时不需要移动内存,只需要改变引用指向即可,所以插入或者删除效率较高。
2、Set是无序的,不可重复的,根据equals和hashcode判断
存储key-value的为Map
---未完待续
如何捕获子线程抛出的异常
方式1(setUncaughtExceptionHandler):
public static void main(String[] args) { Thread t = new Thread(new Runnable() { @Override public void run() { int i = 10/0; } }); t.setUncaughtExceptionHandler(new Thread.UncaughtExceptionHandler() { @Override public void uncaughtException(Thread t, java.lang.Throwable e) { System.out.println("算术异常"); } }); t.start(); }
打印结果:算术异常
方式2:
使用Executors创建线程时,还可以在ThreadFactory中设置:
public static void main(String[] args) { ExecutorService es = Executors.newCachedThreadPool(new MyThreadFactory()); es.execute(new Runnable() { @Override public void run() { int i = 10/0; } }); } static class MyThreadFactory implements ThreadFactory { @Override public Thread newThread(Runnable r) { Thread t = new Thread(r); t.setUncaughtExceptionHandler(new MyUnchecckedExceptionhandler()); return t; } } @SuppressWarnings("all") static class MyUnchecckedExceptionhandler implements Thread.UncaughtExceptionHandler { @Override public void uncaughtException(Thread t, Throwable e) { System.out.println("算术异常"); } }
打印结果:算术异常
Linux Shell 内部命令和外部命令的区别
Linux命令通常被分为两类:
内部命令: 内部命令被构建载shell中。当执行shell命令时,内部命令的执行速度非常快。
这是因为没有其他进程因为执行这条命令而被创建。
比如,当执行"cd"命令时,没有进程被创建。在执行过程中只是简单的改变当前的目录。
如果使用的bash shell,可以通过"help"命令得到所有内部命领列表
内部命令有: exit、history、cd、source、fg、echo等
外部命令: 外部命令并没有被构建在shell中。这些可执行的外部命令保存载一个独立的文件中。
当一个外部命令被执行时,一个新的进程即被创建同时命令被执行。
比如,当执行"cat"命令时,/usr/bin/cat就会被执行。
外部命令有: ls、 cat等
判断一个指定的命令是不是内部命令可以使用type命令
[root@bogon ~]# type cat cat 是 /usr/bin/cat [root@bogon ~]# type cd cd 是 shell 内嵌 [root@bogon ~]#
MySQL事务
MySQL 事务主要用于处理操作量大,复杂度高的数据。比如说,在人员管理系统中,你删除一个人员,你既需要删除人员的基本资料,也要删除和该人员相关的信息,如信箱,文章等等,这样,这些数据库操作语句就构成一个事务!
- 在 MySQL 中只有使用了 Innodb 数据库引擎的数据库或表才支持事务。
- 事务处理可以用来维护数据库的完整性,保证成批的 SQL 语句要么全部执行,要么全部不执行。
- 事务用来管理 insert,update,delete 语句
一般来说,事务是必须满足4个条件(ACID)::原子性(Atomicity,或称不可分割性)、一致性(Consistency)、隔离性(Isolation,又称独立性)、持久性(Durability)。
-
原子性:一个事务(transaction)中的所有操作,要么全部完成,要么全部不完成,不会结束在中间某个环节。事务在执行过程中发生错误,会被回滚(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。
-
一致性:在事务开始之前和事务结束以后,数据库的完整性没有被破坏。这表示写入的资料必须完全符合所有的预设规则,这包含资料的精确度、串联性以及后续数据库可以自发性地完成预定的工作。
-
隔离性:数据库允许多个并发事务同时对其数据进行读写和修改的能力,隔离性可以防止多个事务并发执行时由于交叉执行而导致数据的不一致。事务隔离分为不同级别,包括读未提交(Read uncommitted)、读提交(read committed)---oracle默认隔离级别、可重复读(repeatable read)---mysql默认隔离级别 、串行化(Serializable)。
-
持久性:事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失。
TCP四次握手断开连接
[Shake 1] 套接字A:“任务处理完毕,我希望断开连接。” [Shake 2] 套接字B:“哦,是吗?请稍等,我准备一下。” 等待片刻后…… [Shake 3] 套接字B:“我准备好了,可以断开连接了。” [Shake 4] 套接字A:“好的,谢谢合作。”
为什么HashMap链表长度超过8会转成红黑树结构
HashMap在JDK1.8及以后的版本中引入了红黑树结构,若桶中链表元素个数大于等于8时,链表转换成树结构;若桶中链表元素个数小于等于6时,树结构还原成链表。因为红黑树的平均查找长度是log(n),长度为8的时候,平均查找长度为3,如果继续使用链表,平均查找长度为8/2=4,这才有转换为树的必要。链表长度如果是小于等于6,6/2=3,虽然速度也很快的,但是转化为树结构和生成树的时间并不会太短。还有选择6和8,中间有个差值7可以有效防止链表和树频繁转换。假设一下,如果设计成链表个数超过8则链表转换成树结构,链表个数小于8则树结构转换成链表,如果一个HashMap不停的插入、删除元素,链表个数在8左右徘徊,就会频繁的发生树转链表、链表转树,效率会很低。
Springboot的优缺点
1)优点
- 快速构建项目。
- 对主流开发框架的无配置集成。
- 项目可独立运行,无须外部依赖Servlet容器。
- 提供运行时的应用监控。
- 极大地提高了开发、部署效率。
- 与云计算的天然集成。
2)缺点
- 版本迭代速度很快,一些模块改动很大。
- 由于不用自己做配置,报错时很难定位。
- 网上现成的解决方案比较少。
get请求和post请求有什么区别?
- 在浏览器进行回退操作时,get请求是无害的,而post请求则会重新请求一次
- get请求参数是连接在url后面的,而post请求参数是存放在requestbody内的
- get请求因为浏览器对url长度有限制(不同浏览器长度限制不一样)对传参数量有限制,而post请求因为参数存放在requestbody内所以参数数量没有限制(事实上get请求也能在requestbody内携带参数,只不过不符合规定,有的浏览器能够获取到数据,而有的不能)
- 因为get请求参数暴露在url上,所以安全方面post比get更加安全
- get请求浏览器会主动cache,post并不会,除非主动设置
- get请求参数会保存在浏览器历史记录内,post请求并不会
- get请求只能进行url编码,而post请求可以支持多种编码方式
- get请求产生1个tcp数据包,post请求产生2个tcp数据包
- 浏览器在发送get请求时会将header和data一起发送给服务器,服务器返回200状态码,而在发送post请求时,会先将header发送给服务器,服务器返回100,之后再将data发送给服务器,服务器返回200 OK
Spring事务的传播特性
所谓事务传播行为就是多个事务方法相互调用时,事务如何在这些方法间传播。Spring 支持 7 种事务传播行为(Transaction Propagation Behavior):
| 传播行为 | 描述 |
|---|---|
| PROPAGATION_REQUIRED | 如果没有,就开启一个事务;如果有,就加入当前事务(方法B看到自己已经运行在 方法A的事务内部,就不再起新的事务,直接加入方法A) |
| RROPAGATION_REQUIRES_NEW | 如果没有,就开启一个事务;如果有,就将当前事务挂起。(方法A所在的事务就会挂起,方法B会起一个新的事务,等待方法B的事务完成以后,方法A才继续执行) |
| PROPAGATION_NESTED | 如果没有,就开启一个事务;如果有,就在当前事务中嵌套其他事务 |
| PROPAGATION_SUPPORTS | 如果没有,就以非事务方式执行;如果有,就加入当前事务(方法B看到自己已经运行在 方法A的事务内部,就不再起新的事务,直接加入方法A) |
| PROPAGATION_NOT_SUPPORTED | 如果没有,就以非事务方式执行;如果有,就将当前事务挂起,(方法A所在的事务就会挂起,而方法B以非事务的状态运行完,再继续方法A的事务) |
| PROPAGATION_NEVER | 如果没有,就以非事务方式执行;如果有,就抛出异常。 |
| PROPAGATION_MANDATORY | 如果没有,就抛出异常;如果有,就使用当前事务 |
乐观锁与悲观锁
悲观锁:总是假设最坏的情况,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会阻塞直到它拿到锁。传统的关系型数据库里边就用到了很多这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁。再比如Java里面的同步原语synchronized关键字的实现也是悲观锁。
乐观锁:顾名思义,就是很乐观,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号等机制。乐观锁适用于多读的应用类型,这样可以提高吞吐量,像数据库提供的类似于write_condition机制,其实都是提供的乐观锁。在Java中java.util.concurrent.atomic包下面的原子变量类就是使用了乐观锁的一种实现方式CAS实现的。
redis一致性hash算法
https://www.zhihu.com/tardis/sogou/art/34985026
Servlet 生命周期
Servlet 生命周期可被定义为从创建直到毁灭的整个过程。以下是 Servlet 遵循的过程:
- Servlet 通过调用 init () 方法进行初始化。
- Servlet 调用 service() 方法来处理客户端的请求。
- Servlet 通过调用 destroy() 方法终止(结束)。
- 最后,Servlet 是由 JVM 的垃圾回收器进行垃圾回收的。

