16、图论 Graph theory
学习资源:慕课网liuyubobobo老师的《算法与数据结构精解》
1、图论简介
图论(Graph theory),是组合数学的一个分支,和其他数学分支,如群论、矩阵论、拓扑学有着密切关系。
图是图论的主要研究对象。图是由若干给定的顶点及连接两顶点的边所构成的图形,这种图形通常用来描述某些事物之间的某种特定关系。顶点用于代表事物,连接两顶点的边则用于表示两个事物间具有这种关系。
图论的研究对象相当于一维的单纯复形。
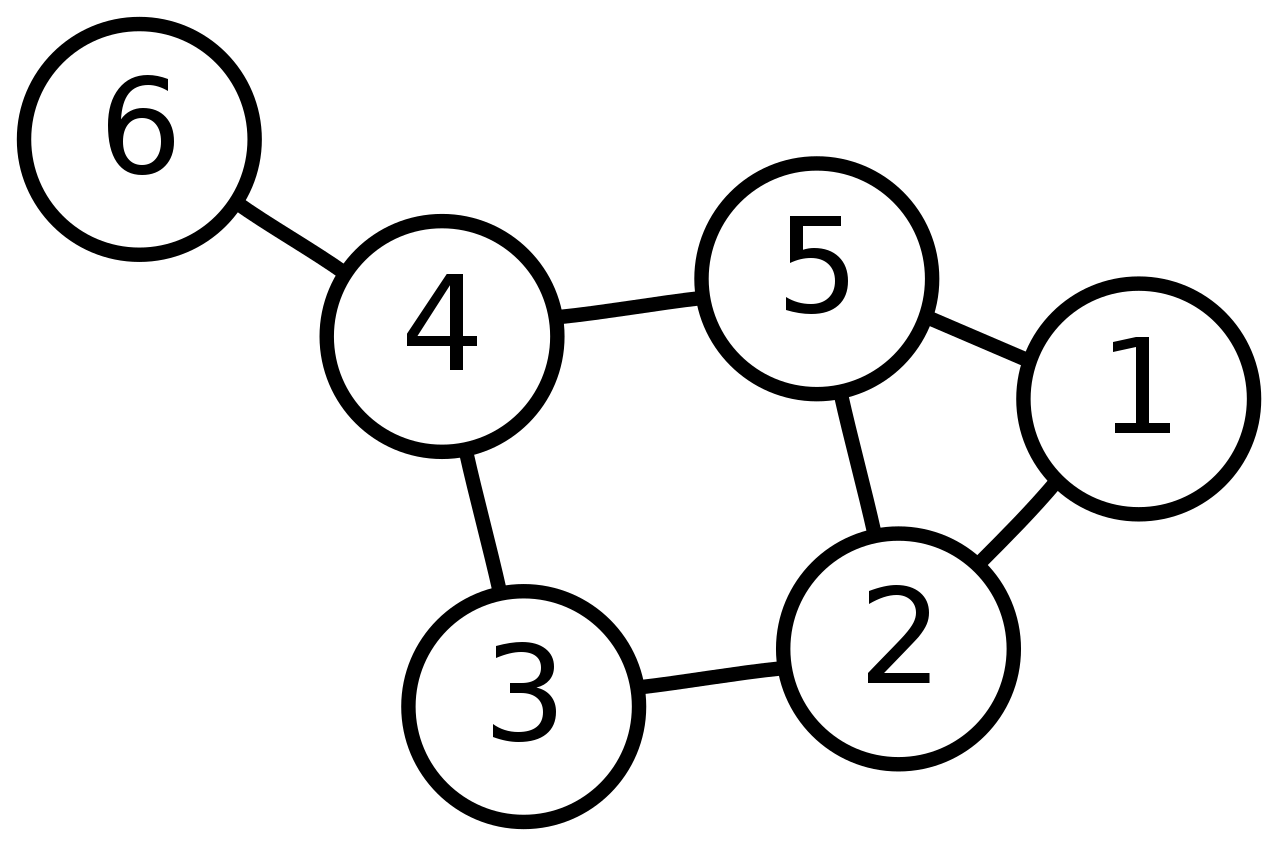
由User:AzaToth - Image:6n-graf.png simlar input data,公有领域,链接由User:AzaToth - Image:6n-graf.png simlar input data,公有领域,链接
1.1、图的分类
无向图
有向图
无权图
有权图
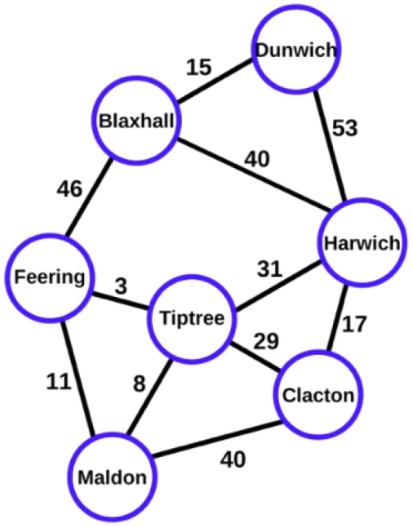
1.2、图的连通性
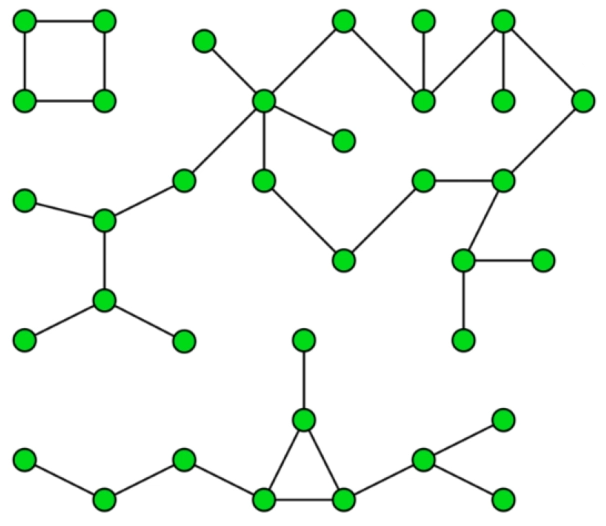
1.3、简单图
没有自环边和平行边的图
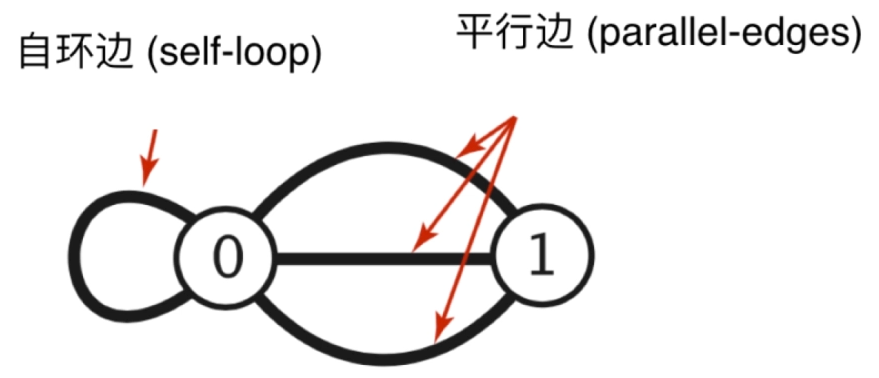
2、无权图的表示
既然图是由点和边组成的,那么在计算机中用怎样的数据结构来表示一个图?
2.1、无权图的接口
public interface Graph {
public int V();
public int E();
public void addEdge(int v, int w);
boolean hasEdge(int v, int w);
void show();
public Iterable<Integer> adj(int v);
}
2.2、邻接矩阵(Adjacency matrix)
在图论中,邻接矩阵(adjacency matrix)是表示一种图结构的常用表示方法。它用数字方阵记录各点之间是否有边相连,数字的大小可以表示边的权值大小。
例如,阶为 n 的图 G 的邻接矩阵 A 是 n*n 的二维矩阵。将 G 的顶点记为 v1 ,v2 ,...,vn,二维矩阵的横纵方向分别记为 i 、j ,那么 Aij 则表示 vi 与 vj 的连接关系, Aij = 1 表示连接, Aij = 0 表示不连接。无向图的邻接矩阵是对称矩阵
- 无向图
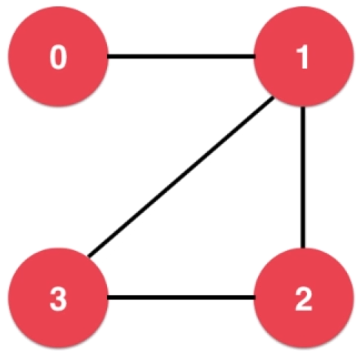
可用邻接矩阵表示为:
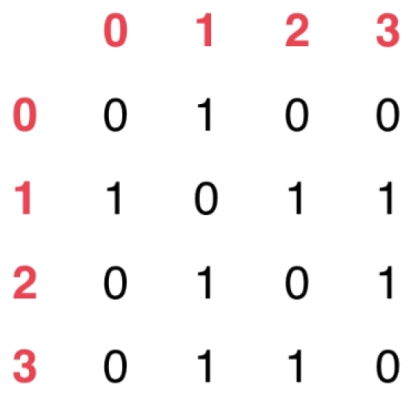
// 稠密图 - 邻接矩阵
// 初始的时候,图中没有边
// 优点:没有平行边的问题,算法复杂度低
public class DenseGraph {
private int n; // 顶点数
private int m; // 边数
private boolean directed; // 是否为有向图
private boolean[][] g; // 图的具体数据,g为n*n的布尔矩阵
// 构造函数
public DenseGraph( int n , boolean directed ){
assert n >= 0;
this.n = n;
this.m = 0; // 初始化没有任何边
this.directed = directed;
// 初始化每一个g[i][j]均为false, 表示没有任何边
g = new boolean[n][n];
}
public int V(){ return n;} // 返回顶点个数
public int E(){ return m;} // 返回边的个数
// 向图中添加一个边,参数为两个顶点
public void addEdge( int v , int w ){
assert v >= 0 && v < n ;
assert w >= 0 && w < n ;
// 如果已经存在v-->w,则退出
if( hasEdge( v , w ) )
return;
// 如果是有向图,则只需 v-->w
g[v][w] = true;
// 如果是无向图,则需要 v-->w,还需要 w-->v
if( !directed )
g[w][v] = true;
m ++;
}
// 验证图中是否有从v到w的边
boolean hasEdge( int v , int w ){
assert v >= 0 && v < n ;
assert w >= 0 && w < n ;
return g[v][w];
}
// 显示图的信息
public void show(){
for( int i = 0 ; i < n ; i ++ ){
for( int j = 0 ; j < n ; j ++ )
System.out.print(g[i][j]+"\t");
System.out.println();
}
}
// 返回图中一个顶点的所有邻边
// 由于java使用引用机制,返回一个Vector不会带来额外开销,
public Iterable<Integer> adj(int v) {
assert v >= 0 && v < n;
Vector<Integer> adjV = new Vector<Integer>();
for(int i = 0 ; i < n ; i ++ )
if( g[v][i] )
adjV.add(i);
return adjV;
}
}
- 有向图
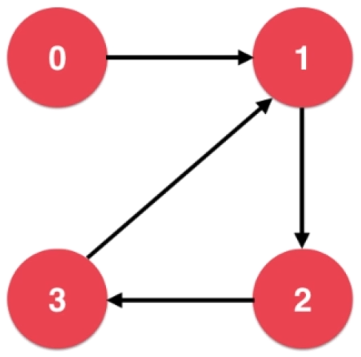
可用邻接矩阵表示为:
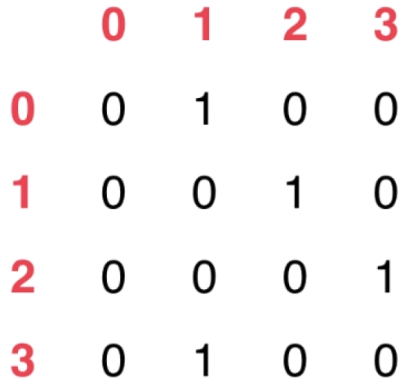
// 稠密图 - 邻接矩阵
public class DenseGraph {
private int n; // 节点数
private int m; // 边数
private boolean directed; // 是否为有向图
private boolean[][] g; // 图的具体数据
// 构造函数
public DenseGraph( int n , boolean directed ){
assert n >= 0;
this.n = n;
this.m = 0; // 初始化没有任何边
this.directed = directed;
// g初始化为n*n的布尔矩阵, 每一个g[i][j]均为false, 表示没有任和边
// false为boolean型变量的默认值
g = new boolean[n][n];
}
public int V(){ return n;} // 返回节点个数
public int E(){ return m;} // 返回边的个数
// 向图中添加一个边
public void addEdge( int v , int w ){
assert v >= 0 && v < n ;
assert w >= 0 && w < n ;
if( hasEdge( v , w ) )
return;
g[v][w] = true;
if( !directed )
g[w][v] = true;
m ++;
}
// 验证图中是否有从v到w的边
boolean hasEdge( int v , int w ){
assert v >= 0 && v < n ;
assert w >= 0 && w < n ;
return g[v][w];
}
// 显示图的信息
public void show(){
for( int i = 0 ; i < n ; i ++ ){
for( int j = 0 ; j < n ; j ++ )
System.out.print(g[i][j]+"\t");
System.out.println();
}
}
// 返回图中一个顶点的所有邻边
// 由于java使用引用机制,返回一个Vector不会带来额外开销,
public Iterable<Integer> adj(int v) {
assert v >= 0 && v < n;
Vector<Integer> adjV = new Vector<Integer>();
for(int i = 0 ; i < n ; i ++ )
if( g[v][i] )
adjV.add(i);
return adjV;
}
}
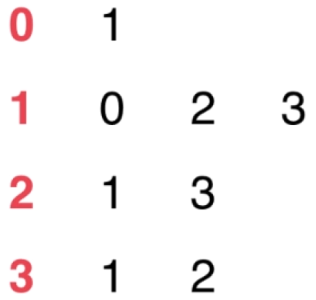
2.3、邻接表(Adjacency list)
不同与邻接矩阵,邻接表每一行保存的是和当前顶点相连接的其他顶点的信息
- 无向图
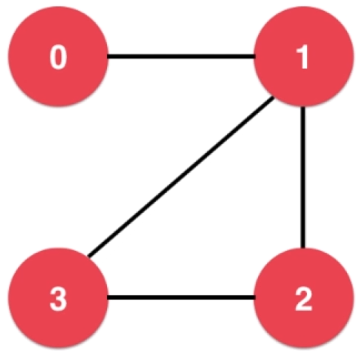
可用邻接表表示为:
- 有向图
可用邻接表表示为:

import java.util.Vector;
// 稀疏图 - 邻接表
// 缺点:存在平行边,如果要取消平行边,算法复杂度将大大增加
public class SparseGraph {
private int n; // 节点数
private int m; // 边数
private boolean directed; // 是否为有向图
private Vector<Integer>[] g; // 图的具体数据,用一个矢量队列记录和第i个顶点连接的其他顶点
// 构造函数
public SparseGraph( int n , boolean directed ){
assert n >= 0;
this.n = n;
this.m = 0; // 初始化没有任何边
this.directed = directed;
// g初始化为n个空的vector, 表示每一个g[i]都为空, 即没有任和边
g = (Vector<Integer>[])new Vector[n];
for(int i = 0 ; i < n ; i ++)
g[i] = new Vector<Integer>();
}
public int V(){ return n;} // 返回节点个数
public int E(){ return m;} // 返回边的个数
// 向图中添加一个边
public void addEdge( int v, int w ){
assert v >= 0 && v < n ;
assert w >= 0 && w < n ;
// 此处没有判断 hasEdge,则稀疏图中会存在平行边
// 如果是有向图,则只需 v-->w
g[v].add(w);
// 如果是无向图,且不是自环边(自环边只需要运行上面的一行代码即可),则需要 v-->w,还需要w-->v
if( v != w && !directed )
g[w].add(v);
m ++;
}
// 验证图中是否有从v到w的边
boolean hasEdge( int v , int w ){
assert v >= 0 && v < n ;
assert w >= 0 && w < n ;
for( int i = 0 ; i < g[v].size() ; i ++ )
if( g[v].elementAt(i) == w )
return true;
return false;
}
// 显示图的信息
public void show(){
for( int i = 0 ; i < n ; i ++ ){
System.out.print("vertex " + i + ":\t");
for( int j = 0 ; j < g[i].size() ; j ++ )
System.out.print(g[i].elementAt(j) + "\t");
System.out.println();
}
}
// 返回图中一个顶点的所有邻边
// 由于java使用引用机制,返回一个Vector不会带来额外开销,
public Iterable<Integer> adj(int v) {
assert v >= 0 && v < n;
return g[v];
}
}
2.3、邻接矩阵 vs 邻接表
- 邻接表的存储空间要小于邻接矩阵
- 邻接矩阵适合表示稠密图(Dense Graph)。最典型的稠密图即是完全图:每对顶点之间都恰连有一条边的简单图

- 邻接表适合表示稀疏图(Sparse Graph)。稀疏图简单理解:图中每个顶点的边的数目远远小于它所能拥有的边的上限,例如,n 个顶点的图,一个顶点最多可以有 n - 1 条边。
3、无权图的遍历
借助之前代码中实现的迭代器,我们可以快速地遍历一个顶点的所有相邻顶点,这对之后遍历图的所有顶点很有帮助。
public Iterable<Integer> adj(int v);
3.1、深度优先遍历
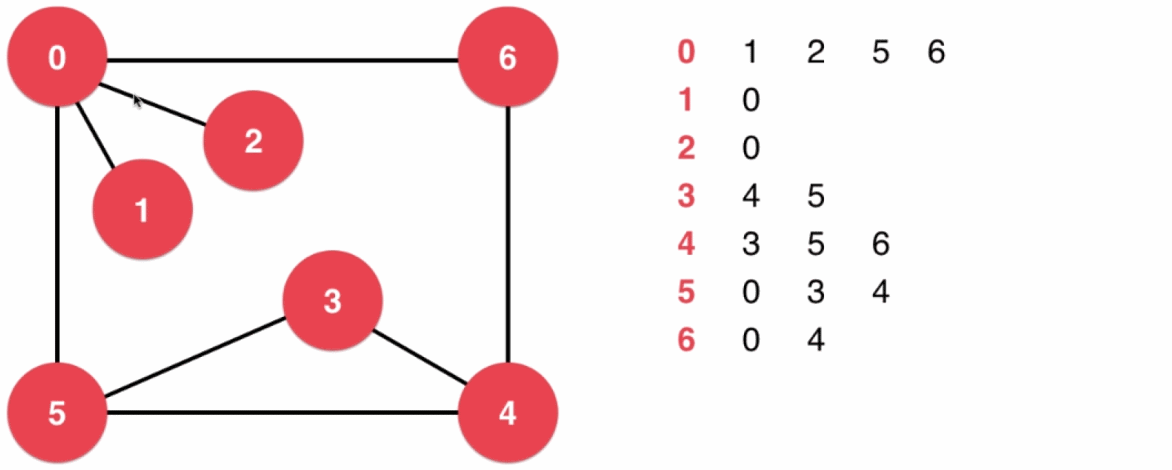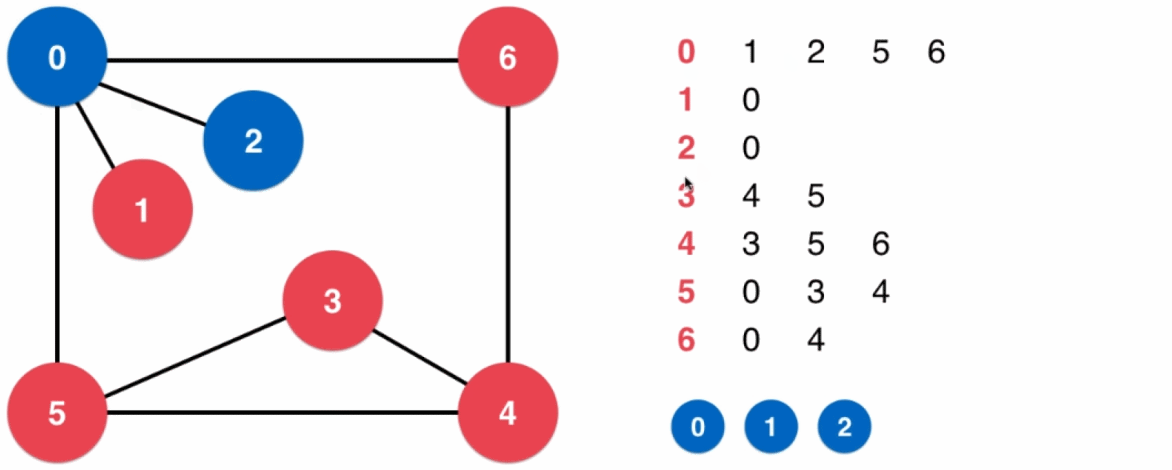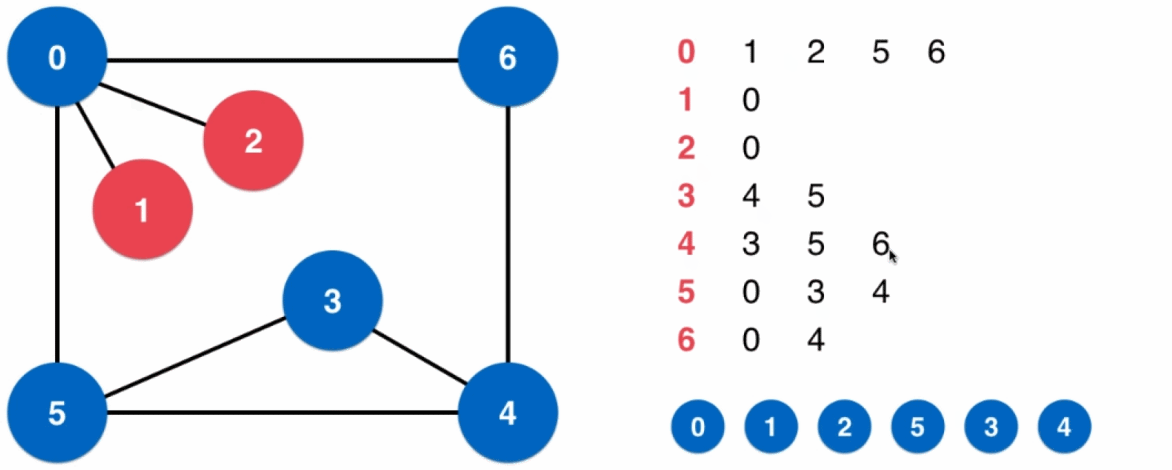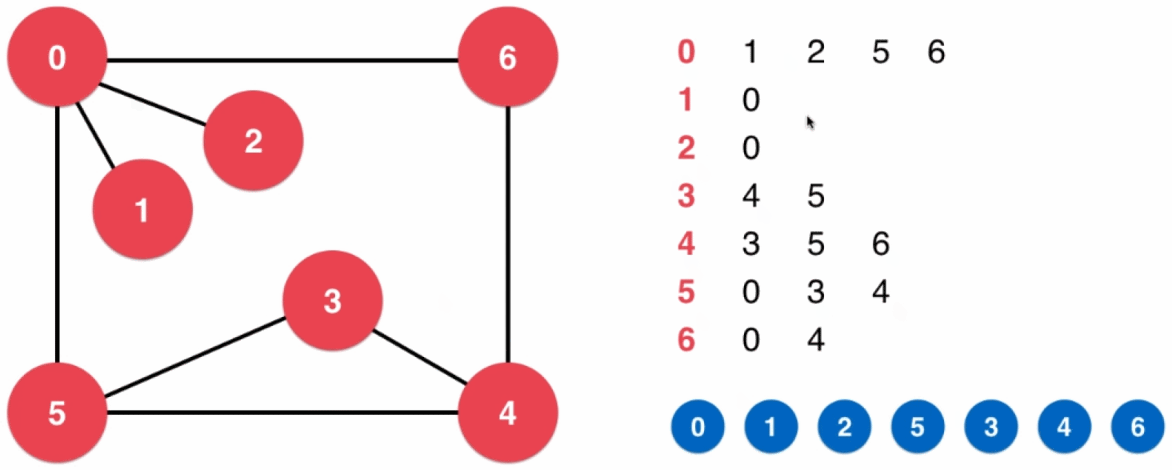
- 创建一个大小等于图中顶点数的一维数组
visit[],用于记录每一个顶点是否被访问过,数组初始为全部未访问 - 然后从一个顶点 v 开始进行深度优先遍历,并将当前访问的顶点 v 标记为已遍历;之后遍历 v 的相邻顶点,记为 v[ i ] ,如果 v[ i ] 没有被访问过,则对 v[ i ] 进行一次深度优先遍历(深度优先遍历使用递归的思想实现)
应用1:求无权图连通分量
// 求无权图的连通分量
public class Components {
Graph G; // 图的引用
private boolean[] visited; // 记录dfs的过程中顶点是否被访问,数组大小为图的顶点数目
private int cCount; // 记录连通分量个数
private int[] id; // 每个顶点所对应的连通分量标记,如果id[i] = id[j],表名i,j存在一条路径连接
// 构造函数, 求出无权图的连通分量
public Components(Graph graph){
// 算法初始化
G = graph;
visited = new boolean[G.V()];
id = new int[G.V()];
cCount = 0;
for( int i = 0 ; i < G.V() ; i ++ ){
visited[i] = false;
id[i] = -1;
}
// 求图的连通分量
// 遍历图的每一个顶点
for( int i = 0 ; i < G.V() ; i ++ )
// 如果当前顶点没有遍历过,就进行深度优先遍历
if( !visited[i] ){
dfs(i);
// 深度遍历完成,连通分量++
cCount++;
}
}
// 图的深度优先遍历,参数:图中的一个顶点
void dfs( int v ){
// 将当前访问的顶点 v 标记为已遍历
visited[v] = true;
id[v] = cCount;
// 遍历与 v 相邻的每一个顶点
for( int i: G.adj(v) ){
// 如果当前的顶点没有被访问过,则递归遍历 顶点i
if( !visited[i] )
dfs(i);
}
}
// 返回图的连通分量个数
public int count(){
return cCount;
}
// 查询点v和点w是否连通
boolean isConnected( int v , int w ){
assert v >= 0 && v < G.V();
assert w >= 0 && w < G.V();
return id[v] == id[w];
}
}
应用2:获得两点间的一条路径
3.2、广度优先遍历
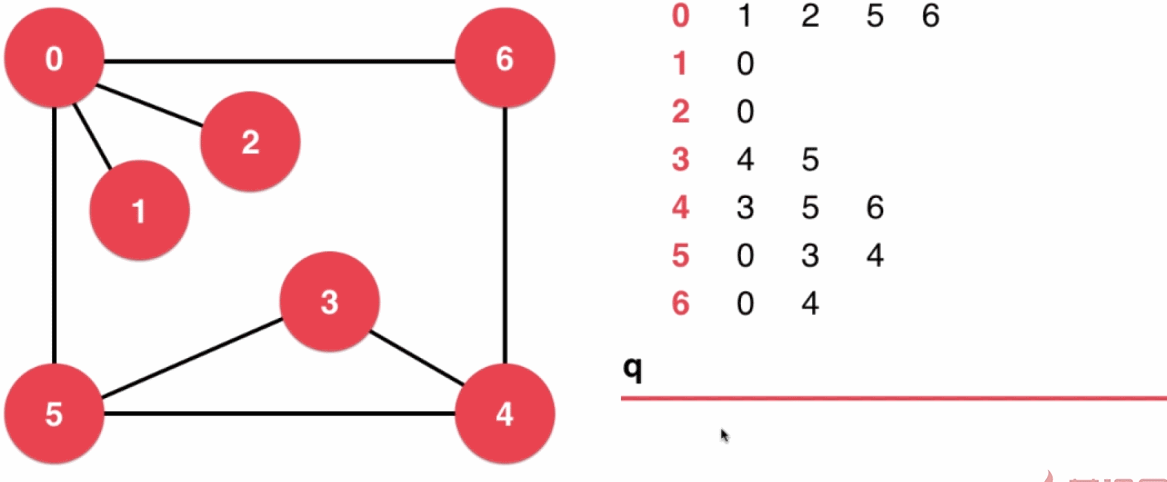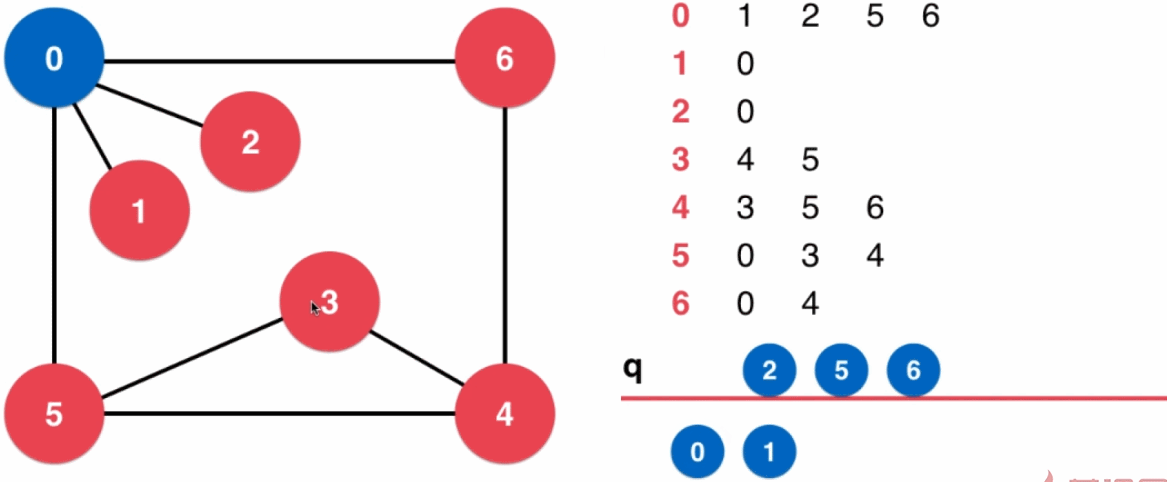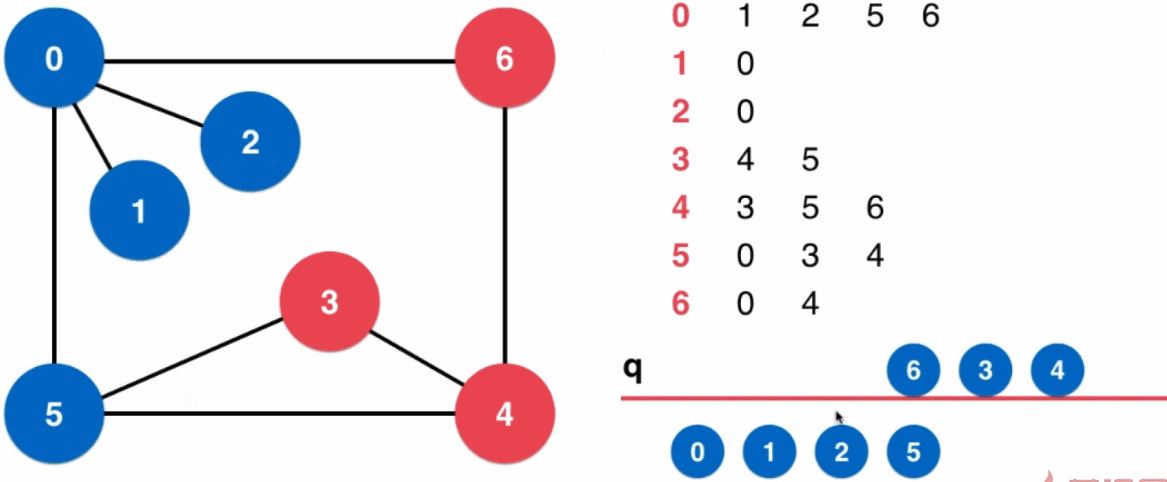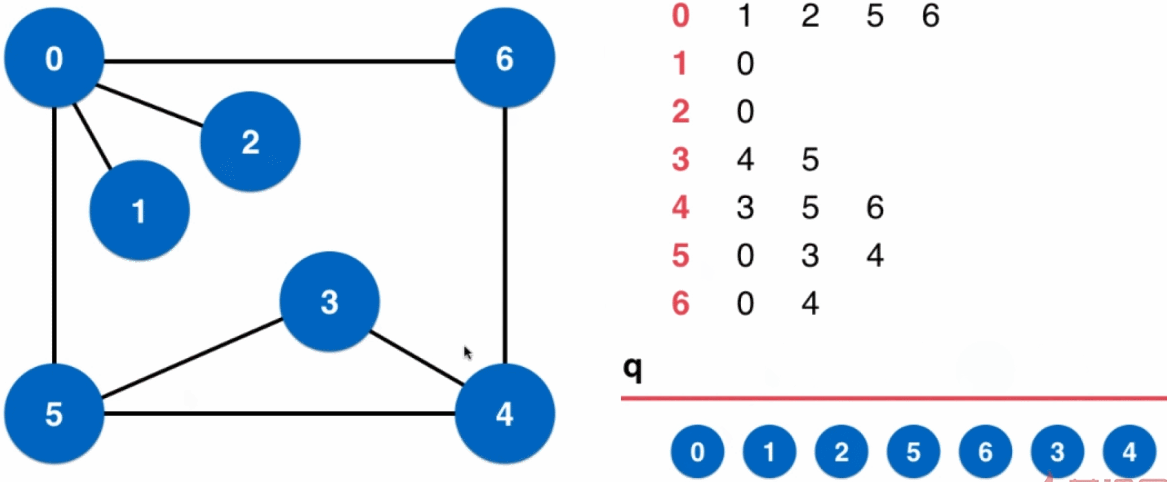
应用:求无权图最短路径
public class ShortestPath {
private Graph G; // 图的引用
private int s; // 起始点
private boolean[] visited; // 记录dfs的过程中节点是否被访问
private int[] from; // 记录路径, from[i]表示查找的路径上i的上一个节点
private int[] ord; // 记录路径中节点的次序。ord[i]表示i节点在路径中的次序,即 s 到 i 的距离。
// 构造函数, 寻路算法, 寻找图graph从s点到其他点的路径
public ShortestPath(Graph graph, int s){
// 算法初始化
G = graph;
assert s >= 0 && s < G.V();
visited = new boolean[G.V()];
from = new int[G.V()];
ord = new int[G.V()];
for( int i = 0 ; i < G.V() ; i ++ ){
visited[i] = false;
from[i] = -1;
ord[i] = -1;
}
this.s = s;
// 无向图最短路径算法, 从s开始广度优先遍历整张图
// 广度优先遍历需要借助一个队列
Queue<Integer> q = new LinkedList<Integer>();
// 将原点 s 添加进队列
q.add(s);
// 状态标记为 已访问
visited[s] = true;
// s 到 s 的距离为 0
ord[s] = 0;
// 循环地将图中的所有顶点添加到队列中,并在队首元素出队后,遍历队首元素的相邻元素,直到队列为空结束循环
while( !q.isEmpty() ){
// 移除队首元素 v
int v = q.remove();
// 然后遍历 v 的相邻顶点
for( int i : G.adj(v) ) {
// 如果顶点 i 没有访问过,就添加到队列中
if (!visited[i]) {
q.add(i);
visited[i] = true;
from[i] = v;
ord[i] = ord[v] + 1;
}
}
}
}
// 查询从s点到w点是否有路径
public boolean hasPath(int w){
assert w >= 0 && w < G.V();
return visited[w];
}
// 查询从s点到w点的路径, 存放在vec中
public Vector<Integer> path(int w){
assert hasPath(w) ;
Stack<Integer> s = new Stack<Integer>();
// 通过from数组逆向查找到从s到w的路径, 存放到栈中
int p = w;
while( p != -1 ){
s.push(p);
p = from[p];
}
// 从栈中依次取出元素, 获得顺序的从s到w的路径
Vector<Integer> res = new Vector<Integer>();
while( !s.empty() )
res.add( s.pop() );
return res;
}
// 打印出从s点到w点的路径
public void showPath(int w){
assert hasPath(w) ;
Vector<Integer> vec = path(w);
for( int i = 0 ; i < vec.size() ; i ++ ){
System.out.print(vec.elementAt(i));
if( i == vec.size() - 1 )
System.out.println();
else
System.out.print(" -> ");
}
}
// 查看从s点到w点的最短路径长度
// 若从s到w不可达,返回-1
public int length(int w){
assert w >= 0 && w < G.V();
return ord[w];
}
}
4、有权图的表示
4.1、有权图的接口
interface WeightedGraph<Weight extends Number & Comparable> {
public int V();
public int E();
public void addEdge(Edge<Weight> e);
boolean hasEdge(int v, int w);
void show();
public Iterable<Edge<Weight>> adj(int v);
}
4.2、Edge类
// 边类
// 泛型Weight
public class Edge<Weight extends Number & Comparable> implements Comparable<Edge>{
private int a, b; // 边的两个端点
private Weight weight; // 边的权值
public Edge(){};
public Edge(int a, int b, Weight weight) {
this.a = a;
this.b = b;
this.weight = weight;
}
public Edge(Edge<Weight> e) {
this.a = e.a;
this.b = e.b;
this.weight = e.weight;
}
public int v(){ return a;} // 返回第一个顶点
public int w(){ return b;} // 返回第二个顶点
public Weight wt(){ return weight;} // 返回权值
// 给定一个顶点, 返回这条边上的另一个顶点
public int other(int x){
assert x == a || x == b;
return x == a ? b : a;
}
// 输出边的信息
public String toString(){
return "" + a + "-" + b + ": " + weight;
}
// 边之间的比较
public int compareTo(Edge that) {
if( weight.compareTo(that.wt()) < 0 )
return -1;
else if ( weight.compareTo(that.wt()) > 0 )
return +1;
else
return 0;
}
}
4.2、邻接表
原来的无权图的邻接表中,每一个顶点与其他顶点的连接关系可以由一个整型的矢量队列表示,但是由于有权图的边还附有权值,所以需要将有权图的边封装成一个类 Edge ,该类存储和当前顶点连接的另一顶点及这条边的权值。

// 稀疏图 - 邻接表
public class SparseWeightedGraph<Weight extends Number & Comparable>
implements WeightedGraph {
private int n; // 节点数
private int m; // 边数
private boolean directed; // 是否为有向图
private Vector<Edge<Weight>>[] g; // 图的具体数据
// 构造函数
public SparseWeightedGraph( int n , boolean directed ){
assert n >= 0;
this.n = n;
this.m = 0; // 初始化没有任何边
this.directed = directed;
// g初始化为n个空的vector, 表示每一个g[i]都为空, 即没有任和边
g = (Vector<Edge<Weight>>[])new Vector[n];
for(int i = 0 ; i < n ; i ++)
g[i] = new Vector<Edge<Weight>>();
}
public int V(){ return n;} // 返回节点个数
public int E(){ return m;} // 返回边的个数
// 向图中添加一个边, 权值为weight
public void addEdge(Edge e){
assert e.v() >= 0 && e.v() < n ;
assert e.w() >= 0 && e.w() < n ;
// 注意, 由于在邻接表的情况, 查找是否有重边需要遍历整个链表
// 我们的程序允许重边的出现
g[e.v()].add(new Edge(e));
if( e.v() != e.w() && !directed )
g[e.w()].add(new Edge(e.w(), e.v(), e.wt()));
m ++;
}
public void addEdge(int v, int w, Weight weight){
assert v >= 0 && v < n ;
assert w >= 0 && w < n ;
// 注意, 由于在邻接表的情况, 查找是否有重边需要遍历整个链表
// 我们的程序允许重边的出现
g[v].add(new Edge(v, w, weight));
if( v != w && !directed )
g[w].add(new Edge(w, v, weight));
m ++;
}
// 验证图中是否有从v到w的边
public boolean hasEdge( int v , int w ){
assert v >= 0 && v < n ;
assert w >= 0 && w < n ;
for( int i = 0 ; i < g[v].size() ; i ++ )
if( g[v].elementAt(i).other(v) == w )
return true;
return false;
}
// 显示图的信息
public void show(){
for( int i = 0 ; i < n ; i ++ ){
System.out.print("vertex " + i + ":\t");
for( int j = 0 ; j < g[i].size() ; j ++ ){
Edge e = g[i].elementAt(j);
System.out.print( "( to:" + e.other(i) + ",wt:" + e.wt() + ")\t");
}
System.out.println();
}
}
// 返回图中一个顶点的所有邻边
// 由于java使用引用机制,返回一个Vector不会带来额外开销,
public Iterable<Edge<Weight>> adj(int v) {
assert v >= 0 && v < n;
return g[v];
}
}
4.3、邻接矩阵
参照无权图,原先的表示顶点 i 、j 之间有边的 Aij = 1 改为 Aij = Edge ,而Aij = null 表示顶点 i 、j 之间没有边(权值为 0 == 没有边)。
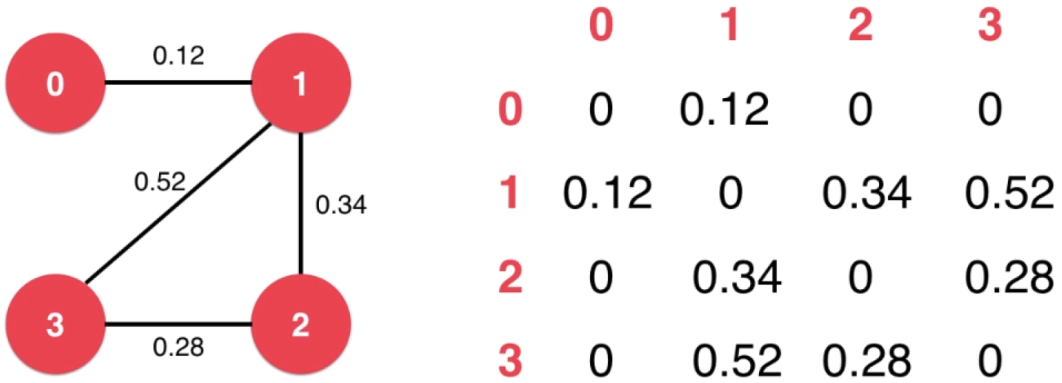
// 稠密图 - 邻接矩阵
public class DenseWeightedGraph<Weight extends Number & Comparable>
implements WeightedGraph{
private int n; // 节点数
private int m; // 边数
private boolean directed; // 是否为有向图
private Edge<Weight>[][] g; // 图的具体数据
// 构造函数
public DenseWeightedGraph( int n , boolean directed ){
assert n >= 0;
this.n = n;
this.m = 0; // 初始化没有任何边
this.directed = directed;
// g初始化为n*n的布尔矩阵, 每一个g[i][j]均为null, 表示没有任和边
// false为boolean型变量的默认值
g = new Edge[n][n];
for(int i = 0 ; i < n ; i ++)
for(int j = 0 ; j < n ; j ++)
g[i][j] = null;
}
public int V(){ return n;} // 返回节点个数
public int E(){ return m;} // 返回边的个数
// 向图中添加一个边
public void addEdge(Edge e){
assert e.v() >= 0 && e.v() < n ;
assert e.w() >= 0 && e.w() < n ;
if( hasEdge( e.v() , e.w() ) )
return;
g[e.v()][e.w()] = new Edge(e);
if( e.v() != e.w() && !directed )
g[e.w()][e.v()] = new Edge(e.w(), e.v(), e.wt());
m ++;
}
public void addEdge(int v, int w, Weight weight){
assert v >= 0 && v < n ;
assert w >= 0 && w < n ;
// 不添加平行边
if( hasEdge(v, w))
return;
g[v][w] = new Edge(v, w, weight);
if( v != w && !directed )
g[w][v] = new Edge(w, v, weight);
m ++;
}
// 验证图中是否有从v到w的边
public boolean hasEdge( int v , int w ){
assert v >= 0 && v < n ;
assert w >= 0 && w < n ;
return g[v][w] != null;
}
// 显示图的信息
public void show(){
for( int i = 0 ; i < n ; i ++ ){
for( int j = 0 ; j < n ; j ++ )
if( g[i][j] != null )
System.out.print(g[i][j].wt()+"\t");
else
System.out.print("NULL\t");
System.out.println();
}
}
// 返回图中一个顶点的所有邻边
// 由于java使用引用机制,返回一个Vector不会带来额外开销,
public Iterable<Edge<Weight>> adj(int v) {
assert v >= 0 && v < n;
Vector<Edge<Weight>> adjV = new Vector<>();
for(int i = 0 ; i < n ; i ++ )
if( g[v][i] != null )
adjV.add( g[v][i] );
return adjV;
}
}
5、有权图的最小生成树
最小生成树是一副连通有权无向图中一棵权值最小的生成树。最小生成树其实是最小权重生成树的简称。
在一给定的无向图 G = (V, E) 中,(u, v) 代表连接顶点 u 与顶点 v 的边(即 (u,v)$\in E$ ),而 w(u, v) 代表此边的权重,若存在 T 为 E 的子集(即 T$\subseteq E$) 且 (V, T) 为树,使得的 w(T) 最小,则此 T 为 G 的最小生成树.
$$
w(T)=\sum _{(u,v)\in T}w(u,v)
$$
一个连通图可能有多个生成树。当图中的边具有权值时,总会有一个生成树的边的权值之和小于或者等于其它生成树的边的权值之和。广义上而言,对于非连通无向图来说,它的每一连通分量同样有最小生成树,它们的并被称为最小生成森林。
以有线电视电缆的架设为例,若只能沿着街道布线,则以街道为边,而路口为顶点,其中必然有一最小生成树能使布线成本最低。
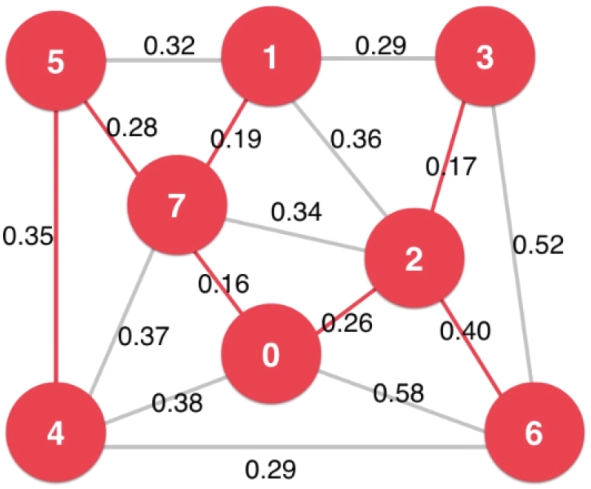
5.1、切分定理
切分:把图中的结点分为两部分,成为一个切分(Cut)。
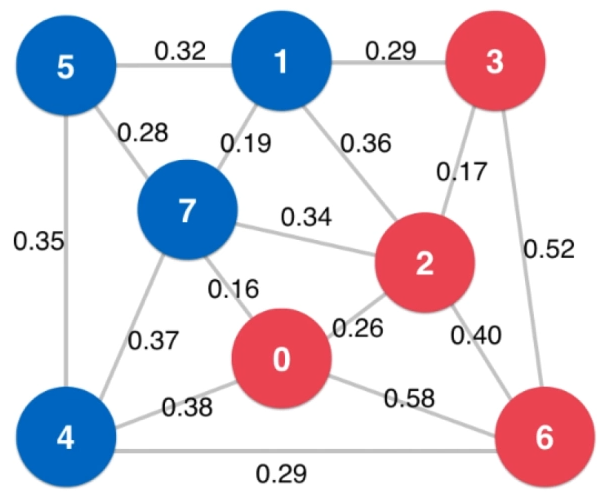
横切边:如果一个边的两个端点,属于切分(Cut)不同部分的的一条边,这个边称为横切边(Crossing Edge)。
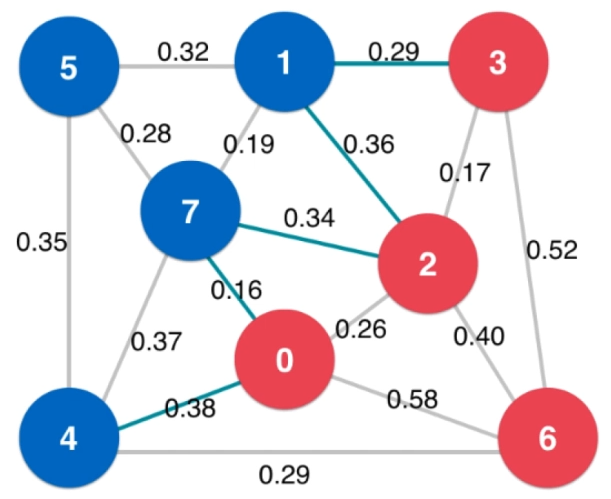
切分定理:在一幅连通加权无向图中,给定任意的切分,如有一条横切边的权值严格小于所有其他横切边,则这条边必然属于图的最小生成树。
证明:令 e 为权重最小的横切边,假设 T 为图的最小生成树,且 T 不包含 e 。那么如果将 e 加入 T ,得到的图必然含有提议奥经过 e 的环,且这个环也含有另一条横切边——设为 e' ,e' 的权重必然大于 e ,那么用 e 替换 e' 可以形成一个权值小于 T 的生成树,与 T 为最小生成树矛盾,所以假设不成立。
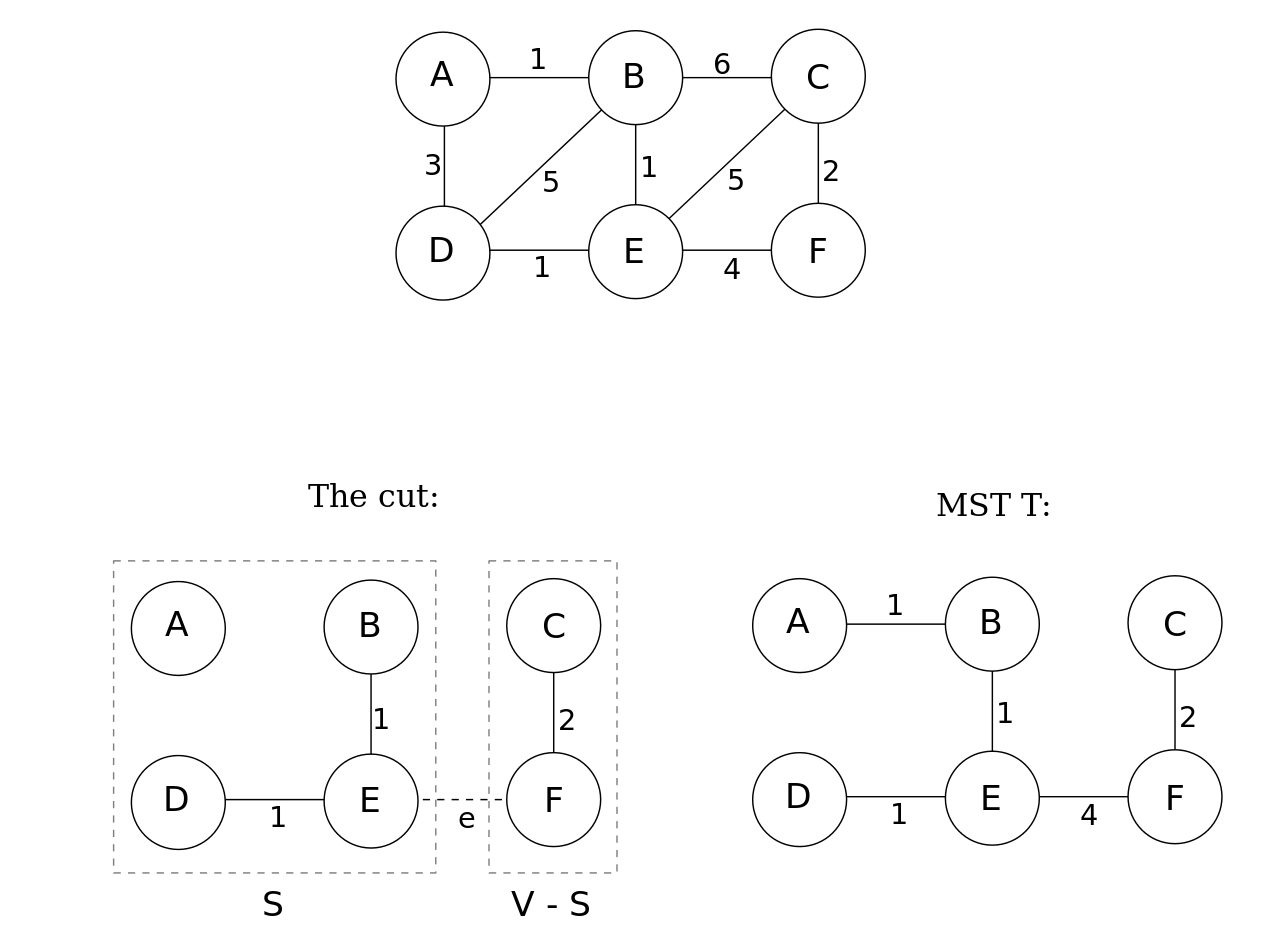
由King rhoton - 自己的作品,CC BY-SA 3.0,链接
此图展示了最小生成树的切分定理。T 是该图唯一的最小生成树,如果 S = { A, B, D, E },那么 V - S = { C, F },然后有3条横切边BC,EC,EF 可以将这两个切分相连。其中边 e 是其中权值最小的边,所以 S $\bigcup$ { e } 是最小生成树的一部分。
5.2、Prim 算法
图论中的一种算法,可在加权连通图里搜索最小生成树。意即由此算法搜索到的边子集所构成的树中,不但包括了连通图里的所有顶点,且其所有边的权值之和亦为最小。
算法描述:
- 输入:一个加权连通图,其中顶点集合为 $\displaystyle V$ ,边集合为 $\displaystyle E $ ;
- 初始化:$\displaystyle V_{\text{new}}={x}$,其中 x 为集合 V 中任一节点(作为算法的起始点),$\displaystyle E_{\text{new}}={}$;
- 重复下列操作,直到 $\displaystyle V_{\text{new}}=V$:
- 在集合 $\displaystyle E$ 中选取权值最小的边 $\displaystyle (u,v)$ ,其中 $\displaystyle u$ 为集合 ${\displaystyle V_{\text{new}}}$ 中的元素,而 ${\displaystyle v}$ 则是 ${\displaystyle V}$ 中没有加入 ${\displaystyle V_{\text{new}}}$ 的顶点(如果存在有多条满足前述条件即具有相同权值的边,则可任意选取其中之一);
- 将 ${\displaystyle v}$ 加入集合 ${\displaystyle V_{\text{new}}}$ ,将 $\displaystyle (u,v)$ 加入集合 ${\displaystyle E_{\text{new}}}$ 中;
- 加入集合 ${\displaystyle V_{\text{new}}}$ 和 ${\displaystyle E_{\text{new}}}$ 来描述所得到的最小生成树。
5.2.1、Lazy Prim
算法描述:
- 首先需要借助一个最小堆,用于筛选当前权值最小的边
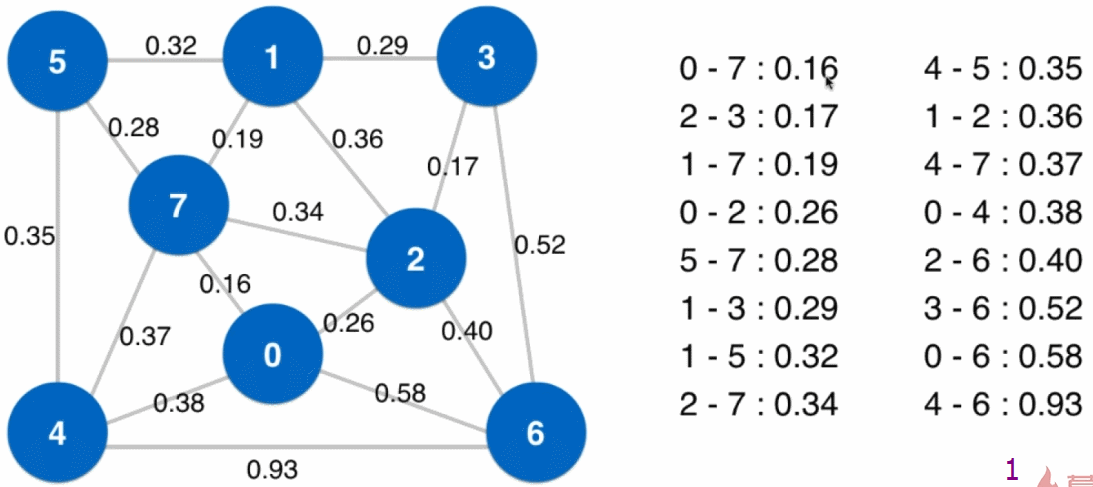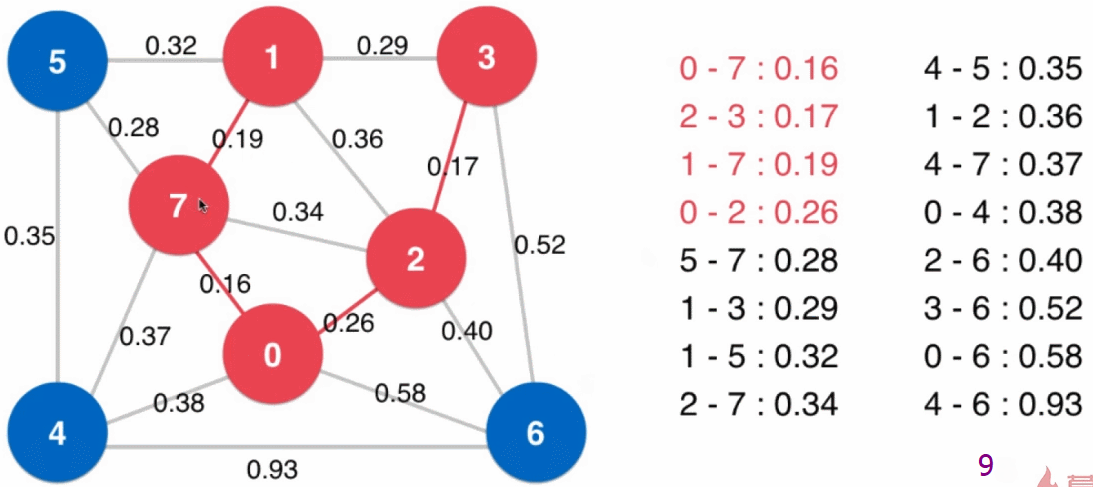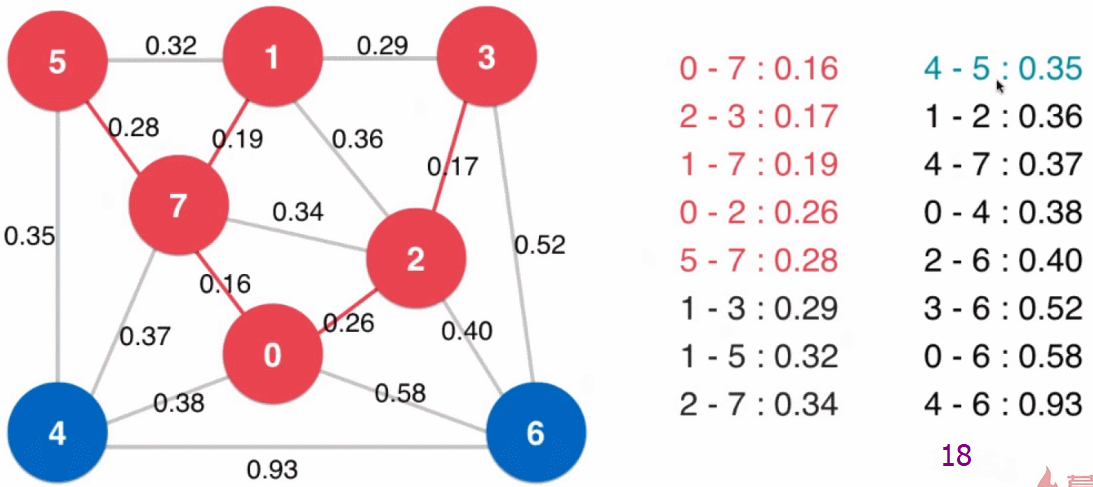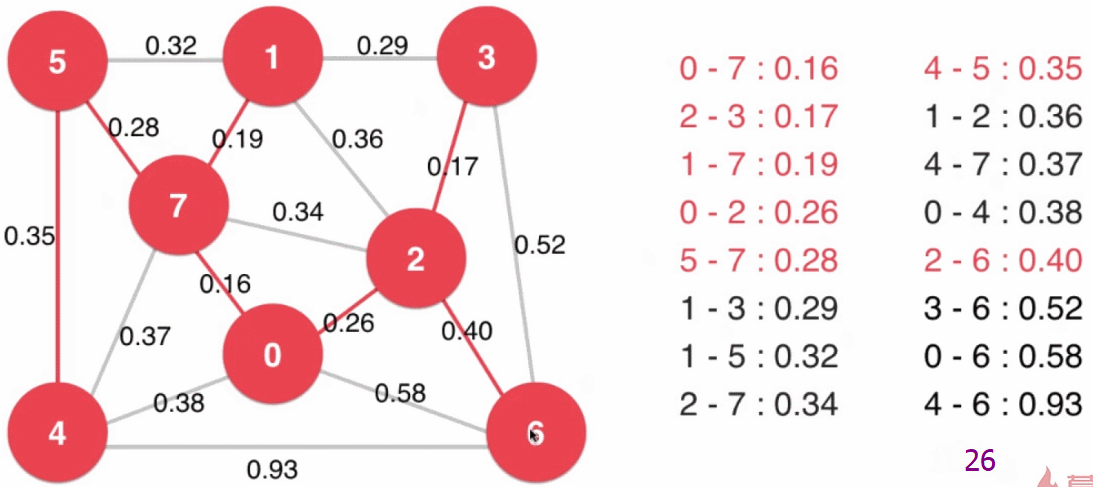
- 设定一个最下生成树的起始点(下图中为 0),从起始点开始逐个顶点地生成切分,同时扩展最小生成树(起始点就是最小生成树的根结点)
- 以已经归入最小生成树的顶点和其他顶点做一个切分
然后将现在这个切分的横切边全部添加到最小堆中,之后从最小堆中取出最小的横切边(注意:当最小生成树新加入结点后,可能此时最小堆中的横切边就不再是横切边了,例如下图中最小生成树扩展到四个结点时,$2 - 7$ 这条边),这条横切边的另一端的顶点即是最小生成树的下一个结点,将这个顶点归入到最小生成树中 - 重复步骤3,直到最小堆为空(或最小生成树有 $V$ 个结点),所有顶点都归入了最小生成树
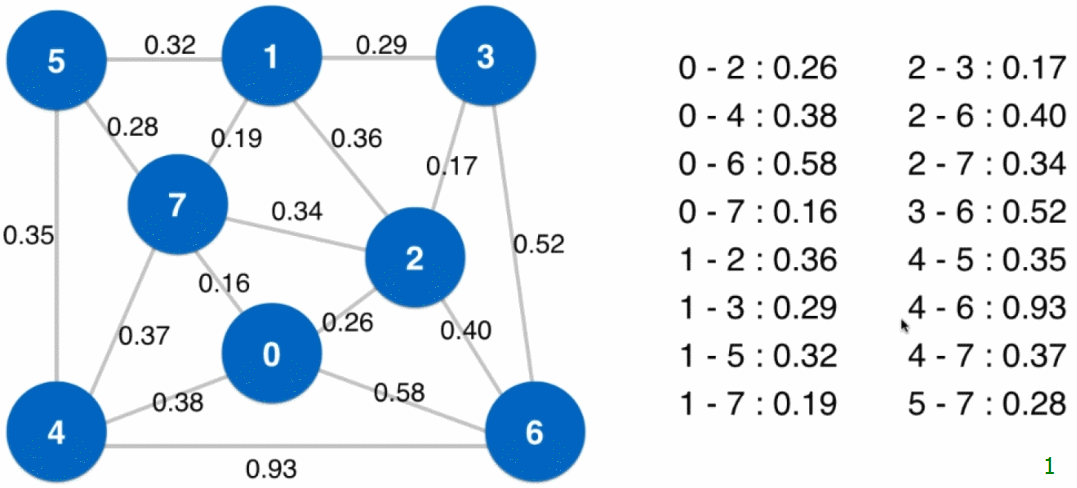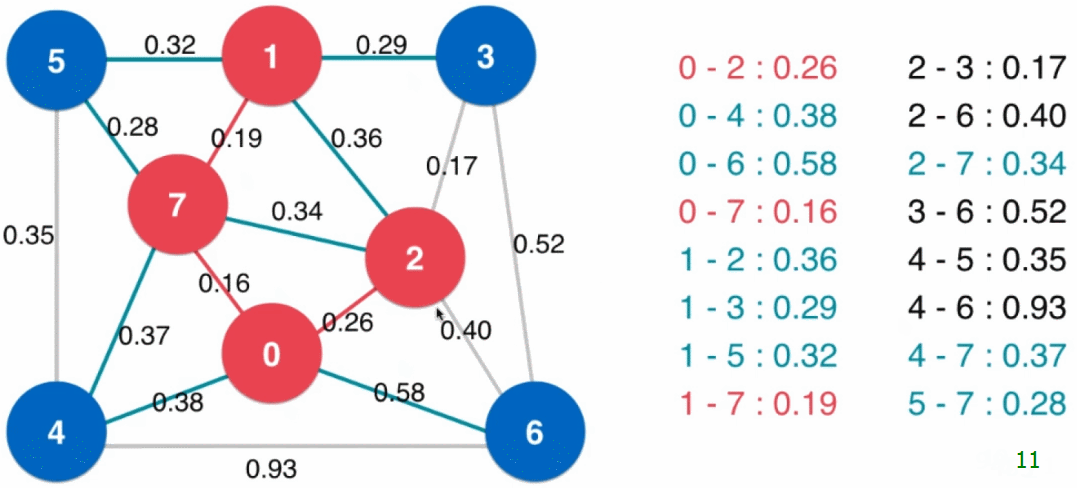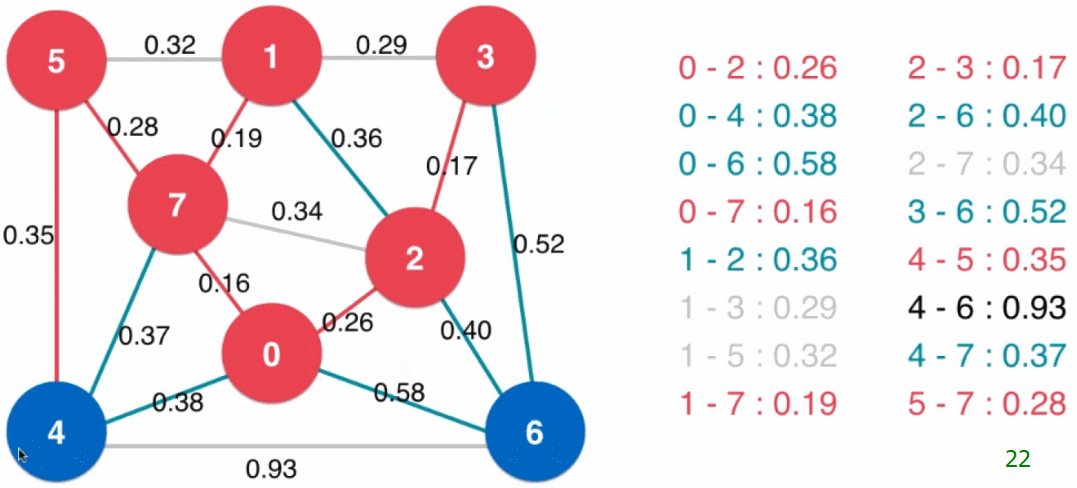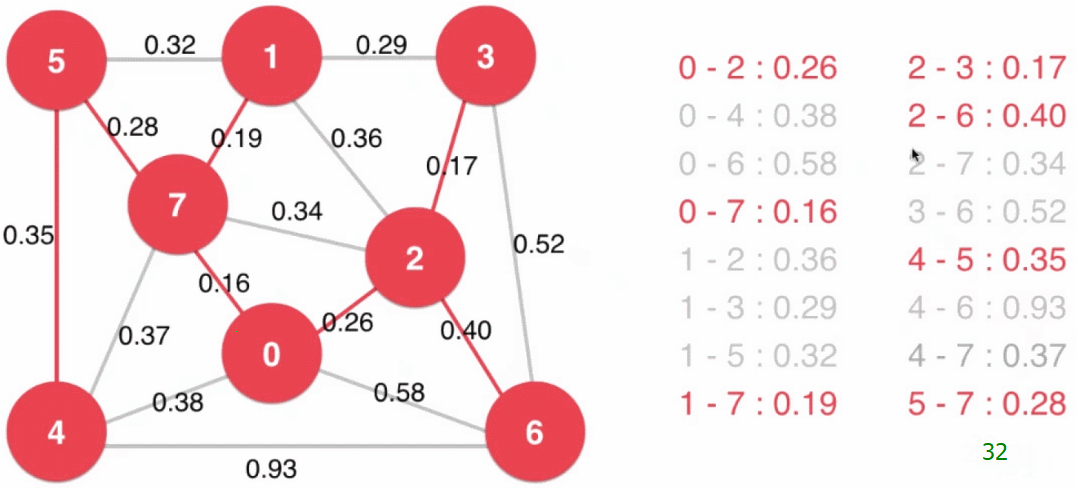
// 使用Prim算法求图的最小生成树
public class LazyPrimMST<Weight extends Number & Comparable> {
private WeightedGraph<Weight> G; // 图的引用
private MinHeap<Edge<Weight>> pq; // 最小堆, 算法辅助数据结构
private boolean[] marked; // 标记数组, 在算法运行过程中标记节点i是否成为最小生成树的一个结点
private Vector<Edge<Weight>> mst; // 最小生成树所包含的所有边
private Number mstWeight; // 最小生成树的权值
// 构造函数, 使用Prim算法求图的最小生成树
public LazyPrimMST(WeightedGraph<Weight> graph){
// 算法初始化
G = graph;
// 最小堆大小为 图的边数
pq = new MinHeap<Edge<Weight>>(G.E());
// 标记数组大小为 图的顶点数
marked = new boolean[G.V()];
mst = new Vector<Edge<Weight>>();
// Lazy Prim
// 选择 0 作为最小生成树的起始点
visit(0);
// 从起始点开始扩展生成最小生成树
while( !pq.isEmpty() ){
// 使用最小堆找出已经访问的边中权值最小的边
Edge<Weight> e = pq.extractMin();
// 如果这条边的两端都已经访问过了, 则扔掉这条边
if( marked[e.v()] == marked[e.w()] )
continue;
// 否则, 这条边则应该存在在最小生成树中
mst.add( e );
// 上一行代码只是将权值最小的边加入了到最小生成树中,还不能得到当前最小生成树的最新的顶点是哪个
// 访问和这条边连接的还没有被访问过的节点
if( !marked[e.v()] )
visit( e.v() );
else
visit( e.w() );
}
// 计算最小生成树的权值
mstWeight = mst.elementAt(0).wt();
for( int i = 1 ; i < mst.size() ; i ++ )
mstWeight = mstWeight.doubleValue() + mst.elementAt(i).wt().doubleValue();
}
// 访问节点v
private void visit(int v){
assert !marked[v];
marked[v] = true;
// 将和结点 v 相连接的所有未访问的边放入最小堆中,未访问的边即是横切边
for( Edge<Weight> e : G.adj(v) )
// 如果 v 的相邻边连接的另一个顶点没有访问过,则视为横切边,将这条边添加到最小堆中
if( !marked[e.other(v)] )
pq.insert(e);
}
// 返回最小生成树的所有边
Vector<Edge<Weight>> mstEdges(){
return mst;
}
// 返回最小生成树的权值
Number result(){
return mstWeight;
}
}
算法复杂度:$O(E log E)$
5.2.2、Lazy Prim 优化
优化方向:
- Lazy 算法在向最小堆中添加边时,没有判断当前添加的边还是不是横切边,所以在 while 循环中就会多进行几次无用的取出对顶元素的操作
- 再者从最小生成树的扩展情况来看,对每一个结点来说,只需要找到它可选的最短边即可
所以综上所述,改进后算法为:
- 借助一个最小索引堆来进行辅助,最小索引堆的每一个位置保存可选的最短横切边
- 同 Lazy 添加向最小堆中添加横切边相同,我们将起始点添加到最小索引堆中,并添加现在这个切分横切边,只是在添加前判断一下待添加的边是否真的是横切边
- 接着取出堆中的最小元素(堆存储的是图顶点的索引),标记该元素对应的顶点,保存有关信息,并将该元素指向的新的属于最小生成树的顶点添加到最小索引堆中,继续执行步骤 2
- 重复步骤 3 ,直到最小索引堆为空

import java.util.Vector;
// 使用优化的Prim算法求图的最小生成树
public class PrimMST<Weight extends Number & Comparable> {
private WeightedGraph G; // 图的引用
private IndexMinHeap<Weight> ipq; // 最小索引堆, 算法辅助数据结构
private Edge<Weight>[] edgeTo; // 访问的点所对应的边, 算法辅助数据结构
private boolean[] marked; // 标记数组, 在算法运行过程中标记节点i是否被访问
private Vector<Edge<Weight>> mst; // 最小生成树所包含的所有边
private Number mstWeight; // 最小生成树的权值
// 构造函数, 使用Prim算法求图的最小生成树
public PrimMST(WeightedGraph graph){
G = graph;
assert( graph.E() >= 1 );
ipq = new IndexMinHeap<Weight>(graph.V());
// 算法初始化
marked = new boolean[G.V()];
edgeTo = new Edge[G.V()];
for( int i = 0 ; i < G.V() ; i ++ ){
marked[i] = false;
edgeTo[i] = null;
}
mst = new Vector<Edge<Weight>>();
// Prim
visit(0);
while( !ipq.isEmpty() ){
// 使用最小索引堆找出已经访问的边中权值最小的边
// 最小索引堆中存储的是点的索引, 通过点的索引找到相对应的边
int v = ipq.extractMinIndex();
assert( edgeTo[v] != null );
mst.add( edgeTo[v] );
visit( v );
}
// 计算最小生成树的权值
mstWeight = mst.elementAt(0).wt();
for( int i = 1 ; i < mst.size() ; i ++ )
mstWeight = mstWeight.doubleValue() + mst.elementAt(i).wt().doubleValue();
}
// 访问节点v
void visit(int v){
assert !marked[v];
marked[v] = true;
// 将和节点v相连接的未访问的另一端点, 和与之相连接的边, 放入最小堆中
for( Object item : G.adj(v) ){
Edge<Weight> e = (Edge<Weight>)item;
int w = e.other(v);
// 如果边的另一端点未被访问
if( !marked[w] ){
// 如果从没有考虑过这个端点, 直接将这个端点和与之相连接的边加入索引堆
if( edgeTo[w] == null ){
edgeTo[w] = e;
ipq.insert(w, e.wt());
}
// 如果曾经考虑这个端点, 但现在的边比之前考虑的边更短, 则进行替换
else if( e.wt().compareTo(edgeTo[w].wt()) < 0 ){
edgeTo[w] = e;
ipq.change(w, e.wt());
}
}
}
}
// 返回最小生成树的所有边
Vector<Edge<Weight>> mstEdges(){
return mst;
}
// 返回最小生成树的权值
Number result(){
return mstWeight;
}
// 测试 Prim
public static void main(String[] args) {
String filename = "testG1.txt";
int V = 8;
SparseWeightedGraph<Double> g = new SparseWeightedGraph<Double>(V, false);
ReadWeightedGraph readGraph = new ReadWeightedGraph(g, filename);
// Test Prim MST
System.out.println("Test Prim MST:");
PrimMST<Double> primMST = new PrimMST<Double>(g);
Vector<Edge<Double>> mst = primMST.mstEdges();
for( int i = 0 ; i < mst.size() ; i ++ )
System.out.println(mst.elementAt(i));
System.out.println("The MST weight is: " + primMST.result());
System.out.println();
}
}
算法复杂度:$O(E log V)$
5.3、Kruskal 算法
Kruskal算法是一种用来查找最小生成树的算法,由Joseph Kruskal在1956年发表。用来解决同样问题的还有Prim算法和Boruvka算法等。三种算法都是贪心算法的应用。
算法描述:
- 新建图 ${\displaystyle G}$ ,${\displaystyle G}$ 中拥有原图中相同的节点,但没有边
- 将原图中所有的边按权值从小到大排序
- 从权值最小的边开始,如果这条边连接的两个节点于图 ${\displaystyle G}$ 中不在同一个连通分量(也可以理解为:不在同一个切分,或连接后不形成一个环)中,则添加这条边到图 ${\displaystyle G}$ 中
- 重复3,直至图 ${\displaystyle G}$ 中所有的节点都在同一个连通分量中
证明:
- 这样的步骤保证了选取的每条边都是桥,因此图 ${\displaystyle G}$ 构成一个树。
- 为什么这一定是最小生成树呢?关键还是步骤3中对边的选取。算法中总共选取了 ${\displaystyle n-1}$ 条边,每条边在选取的当时,都是连接两个不同的连通分量的权值最小的边
- 要证明这条边一定属于最小生成树,可以用反证法:如果这条边不在最小生成树中,它连接的两个连通分量最终还是要连起来的,通过其他的连法,那么另一种连法与这条边一定构成了环,而环中一定有一条权值大于这条边的边,用这条边将其替换掉,图仍旧保持连通,但总权值减小了。也就是说,如果不选取这条边,最后构成的生成树的总权值一定不会是最小的。
示例:
| 图例 | 说明 |
|---|---|
 |
AD和CE是最短的两条边,长度为5,其中AD被任意选出,以高亮表示。 |
 |
现在CE是不属于环的最短边,长度为5,因此第二个以高亮表示。 |
 |
下一条边是长度为6的DF,同样地以高亮表示。 |
 |
接下来的最短边是AB和BE,长度均为7。AB被任意选中,并以高亮表示。边BD用红色高亮表示,因为B和D之间已经存在一条(标为绿色的)路径,如果选择它将会构成一个环(ABD)。 |
 |
以高亮表示下一条最短边BE,长度为7。这时更多的边用红色高亮标出:会构成环BCE的BC、会构成环DBEA的DE以及会构成环FEBAD的FE。 |
 |
最终,标记长度为9的边EG,得到最小生成树,结束算法过程。 |
import java.util.Vector;
// Kruskal算法求最小生成树
public class KruskalMST<Weight extends Number & Comparable> {
private Vector<Edge<Weight>> mst; // 最小生成树所包含的所有边
private Number mstWeight; // 最小生成树的权值
// 构造函数, 使用Kruskal算法计算graph的最小生成树
public KruskalMST(WeightedGraph graph){
mst = new Vector<Edge<Weight>>();
// 将图中的所有边存放到一个最小堆中
MinHeap<Edge<Weight>> pq = new MinHeap<Edge<Weight>>( graph.E() );
// 遍历图的所有顶点
for( int i = 0 ; i < graph.V() ; i ++ ) {
// 遍历顶点的所有邻边
for (Object item : graph.adj(i)) {
Edge<Weight> e = (Edge<Weight>) item;
// 不进行if判断,一条边会重复两次加入到最小堆中
if (e.v() <= e.w())
pq.insert(e);
}
}
// 创建一个并查集, 来查看已经访问的节点的连通情况
UnionFind uf = new UnionFind(graph.V());
// 循环终止条件:向量队列的大小 == 图顶点数 - 1
while( !pq.isEmpty() && mst.size() < graph.V() - 1 ){
// 从最小堆中依次从小到大取出所有的边
Edge<Weight> e = pq.extractMin();
// 初始,并查集为空
// 如果该边的两个端点是连通的, 说明加入这条边将产生环, 扔掉这条边
if( uf.isConnected( e.v() , e.w() ) )
continue;
// 否则, 将这条边添加进最小生成树, 同时标记边的两个端点连通
mst.add( e );
// 元素个数少的集合合并到元素个数多的集合上
uf.unionElements( e.v() , e.w() );
}
// 计算最小生成树的权值
mstWeight = mst.elementAt(0).wt();
for( int i = 1 ; i < mst.size() ; i ++ )
mstWeight = mstWeight.doubleValue() + mst.elementAt(i).wt().doubleValue();
}
// 返回最小生成树的所有边
Vector<Edge<Weight>> mstEdges(){
return mst;
}
// 返回最小生成树的权值
Number result(){
return mstWeight;
}
// 测试 Kruskal
public static void main(String[] args) {
String filename = "testG1.txt";
int V = 8;
SparseWeightedGraph<Double> g = new SparseWeightedGraph<Double>(V, false);
ReadWeightedGraph readGraph = new ReadWeightedGraph(g, filename);
// Test Kruskal
System.out.println("Test Kruskal:");
KruskalMST<Double> kruskalMST = new KruskalMST<Double>(g);
Vector<Edge<Double>> mst = kruskalMST.mstEdges();
for( int i = 0 ; i < mst.size() ; i ++ )
System.out.println(mst.elementAt(i));
System.out.println("The MST weight is: " + kruskalMST.result());
System.out.println();
}
}
算法复杂度:$O( E log E )$。
同 Prim 算法相比,Kruskal 算法实现思路更简单,因此对于较小的图,可以优先使用 Kruskal 处理。
6、有权图的最短路径
6.1、Dijkstra 算法
戴克斯特拉算法,是由荷兰计算机科学家艾兹赫尔·戴克斯特拉在1956年发现的算法,并于3年后在期刊上发表。戴克斯特拉算法使用类似广度优先搜索的方法解决赋权图的单源最短路径问题。
该算法存在很多变体:戴克斯特拉的原始版本仅适用于找到两个顶点之间的最短路径,后来更常见的变体固定了一个顶点作为源结点然后找到该顶点到图中所有其它结点的最短路径,产生一个最短路径树。
应当注意,绝大多数的戴克斯特拉算法不能有效处理带有负权边的图。
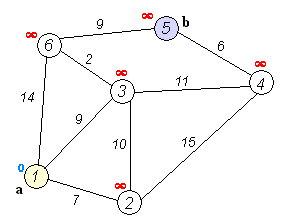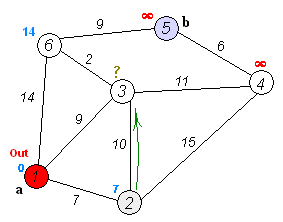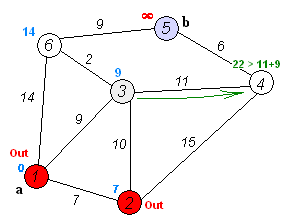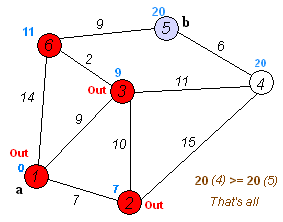
相关变量的定义:源点 $\displaystyle s$ 、$\displaystyle s$ 到顶点 $\displaystyle v$ 的最短路径权值 $\displaystyle d[v]$ 、顶点 $\displaystyle u$ 到顶点 $\displaystyle v$ 的权值 $\displaystyle w[u,v]$
松弛操作:它是戴克斯特拉算法的基础操作,如果存在一条从 $\displaystyle u$ 到 $\displaystyle v$ 的边 $\displaystyle u->v$,那么从 $\displaystyle s$ 到 $\displaystyle v$ 的一条新路径则是通过将边 $\displaystyle u->v$ 添加到边 $\displaystyle s->u$ 尾部来扩展一条从 $\displaystyle s$ 到 $\displaystyle v$ 的路径: $\displaystyle s->u->v$。新路径的长度是 $\displaystyle d[u]+w(u,v)$ ,如果这个值比目前已知的 $\displaystyle d[v]$ 要小,那么可以用这个值来替代当前 $\displaystyle d[v]$ 中的值。松弛边的操作一直运行到所有的 ${\displaystyle d[v]}$ 都代表从 $\displaystyle s$ 到 $\displaystyle v$ 的最短路径的长度值。
算法描述:
- 从源点 S 开始,访问 S 的邻边,并将它的邻边添加到到一个最小优先级队列中,之后取出最小边,那么这条最小边就是一个最短路径,设相应顶点设为 A
- 接着访问 A 的邻边,并将这些邻边(除去那些已经找到最短路径的顶点对应的邻边,这里除去边 A--S)存入到当前的最小优先级队列中,之后取出最小边,又是一个最短路径,相应顶点设为 B
- 重复 步骤2 直到最小优先级队列为空
我理解:
- 该算法从起始点开始寻找第一个最短路径,这个操作是特别容易实现的,只需要找到起始点的最短邻边即可。对于起始点的相邻顶点,松弛操作也无法找到另一条通向这个顶点的更短路径
- 对于起始点和已经找到最短路径的顶点,可以将它们视为一个整体,视为一个新的起始点
因为那些未找到最短路径的剩余顶点也只可能从这个整体扩展出最短路径 - 这样的话该算法就是:每次只从"起始点"开始找到一个其他顶点的最短路径
例如在上图中:
初始起始点为 2 ,显然 $2 -> 1$ 这条边是最短的,则树的第一个结点是顶点 1 ,起始点更新为 "2+1"
"2+1",显然 $2+1->4$ 这条边是最短的,则树的第一个结点是顶点 4,起始点更新为 "2+1+4"
"2+1+4",显然 $2+1+4->5$ 是最短的,则树的第一个结点是顶点 5,起始点更新为 "2+1+4+5"
······ - hhh,这样只是方便理解
import java.util.Vector;
import java.util.Stack;
// Dijkstra算法求最短路径
public class Dijkstra<Weight extends Number & Comparable> {
private WeightedGraph G; // 图的引用
private int s; // 起始点
private Number[] distTo; // distTo[i]存储从起始点s到i的最短路径长度
private boolean[] marked; // 标记数组, 在算法运行过程中标记节点i是否被访问
private Edge<Weight>[] from; // from[i]记录最短路径中, 到达i点的边是哪一条
// 可以用来恢复整个最短路径
// 构造函数, 使用Dijkstra算法求最短路径
public Dijkstra(WeightedGraph graph, int s){
// 算法初始化
G = graph;
assert s >= 0 && s < G.V();
this.s = s;
distTo = new Number[G.V()];
marked = new boolean[G.V()];
from = new Edge[G.V()];
for( int i = 0 ; i < G.V() ; i ++ ){
distTo[i] = 0.0;
marked[i] = false;
from[i] = null;
}
// 使用索引堆记录当前找到的到达每个顶点的最短距离
IndexMinHeap<Weight> ipq = new IndexMinHeap<Weight>(G.V());
// 对于起始点s进行初始化
distTo[s] = 0.0;
marked[s] = true;
from[s] = new Edge<Weight>(s, s, (Weight)(Number)(0.0));
ipq.insert(s, (Weight)distTo[s] );
while( !ipq.isEmpty() ){
int v = ipq.extractMinIndex();
// distTo[v]就是s到v的最短距离
marked[v] = true;
// 对v的所有相邻节点进行更新,v --> e
for( Object item : G.adj(v) ){
// w 是邻边e另一端的顶点
Edge<Weight> e = (Edge<Weight>)item;
int w = e.other(v);
// 如果从s点到w点的最短路径还没有找到
if( !marked[w] ){
// 如果w点以前没有访问过,还没有到达 w 的边
// 或者访问过, 但是通过当前的v点到w点距离更短,
// 则进行更新
if( from[w] == null
|| distTo[v].doubleValue() + e.wt().doubleValue() < distTo[w].doubleValue() ){
distTo[w] = distTo[v].doubleValue() + e.wt().doubleValue();
from[w] = e;
if( ipq.contain(w) )
ipq.change(w, (Weight)distTo[w] );
else
ipq.insert(w, (Weight)distTo[w] );
}
}
}
}
}
// 返回从s点到w点的最短路径长度
Number shortestPathTo( int w ){
assert w >= 0 && w < G.V();
assert hasPathTo(w);
return distTo[w];
}
// 判断从s点到w点是否连通
boolean hasPathTo( int w ){
assert w >= 0 && w < G.V() ;
return marked[w];
}
// 寻找从s到w的最短路径, 将整个路径经过的边存放在vec中
Vector<Edge<Weight>> shortestPath( int w){
assert w >= 0 && w < G.V();
assert hasPathTo(w);
// 通过from数组逆向查找到从s到w的路径, 存放到栈中
Stack<Edge<Weight>> edgeStack = new Stack<Edge<Weight>>();
Edge<Weight> e = from[w];
while( e.v() != this.s ){
edgeStack.push(e);
e = from[e.v()];
}
edgeStack.push(e);
// 从栈中依次取出元素, 获得顺序的从s到w的路径
Vector<Edge<Weight>> res = new Vector<Edge<Weight>>();
while( !edgeStack.empty() ){
e = edgeStack.pop();
res.add( e );
}
return res;
}
// 打印出从s点到w点的路径
void showPath(int w){
assert w >= 0 && w < G.V();
assert hasPathTo(w);
Vector<Edge<Weight>> path = shortestPath(w);
for( int i = 0 ; i < path.size() ; i ++ ){
System.out.print( path.elementAt(i).v() + " -> ");
if( i == path.size()-1 )
System.out.println(path.elementAt(i).w());
}
}
}
6.2、Bellman-Ford 算法
贝尔曼-福特算法,求解单源最短路径问题的一种算法,由 理查德·贝尔曼 和 莱斯特·福特 创立的。它的原理是对图进行 ${\displaystyle |V|-1}$ 次松弛操作,得到所有可能的最短路径。其优于迪科斯彻算法的方面是边的权值可以为负数、可以判断图中是否有负权环、实现简单,缺点是时间复杂度过高,高达 ${\displaystyle O(VE)}$ ,$\displaystyle V$ 和 $\displaystyle E$ 分别是顶点和边的数量。但算法可以进行若干种优化,提高了效率。
和 Dijkstra 算法相同,松弛操作同样是 Bellman-Ford 算法的基础操作。
注意,拥有负权环的图,没有最短路径。
如果一个图没有负权环,那么从一点到另外一点的最短路径,最多经过所有的 $\displaystyle V$ 个顶点,这条路径有 $\displaystyle V-1$条边;否则,一定是有的顶点经过了两次,即存在负权环。
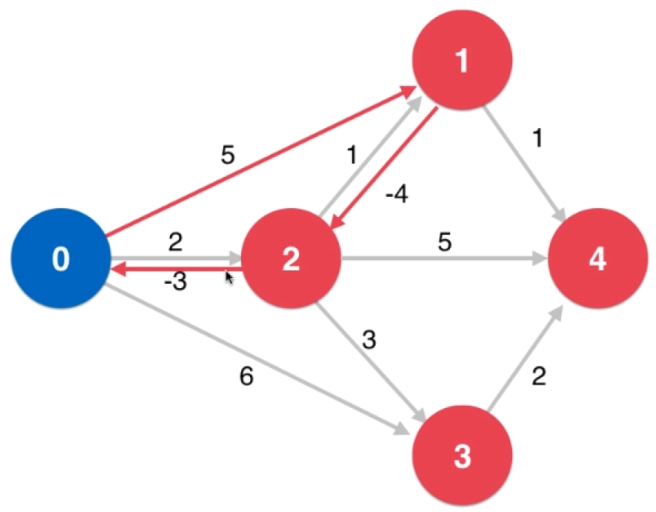
我们先来个例子简单地理解一下该算法的思想(我刚开始有点看不懂,hhh),以求源点相邻结点的最短路径为例:
- 对源点的所有相邻结点进行第一次松弛操作,该操作理解为:找到从源点开始经过 1 条边到达其相邻结点的路径 $\displaystyle s->v$
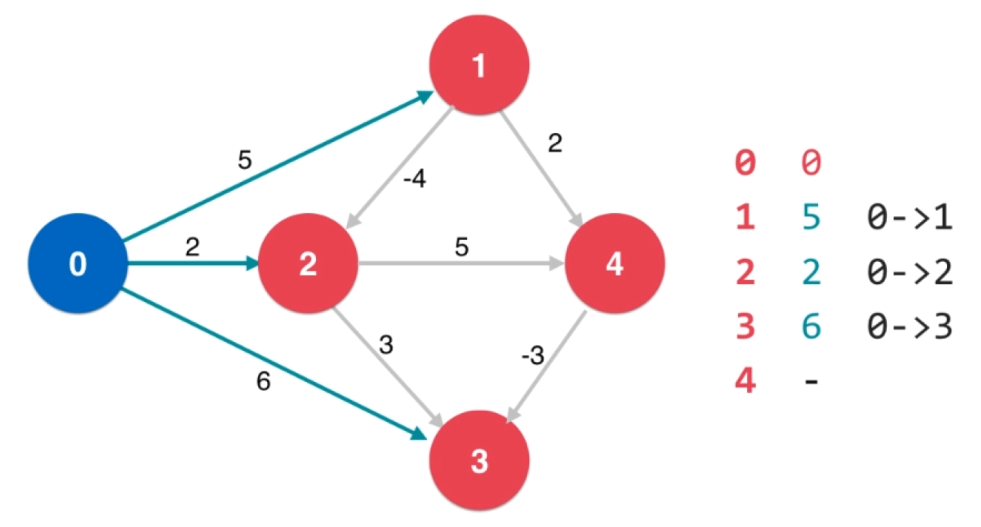
- 对源点所有相邻结点进行第二次松弛操作,找到从源点开始经过 2 条边到达其相邻结点的路径 $\displaystyle s->u->v$ ,这时就需要比较 $\displaystyle s->v$ 和 $\displaystyle s->u->v$ ,得出当前的"最短路径"
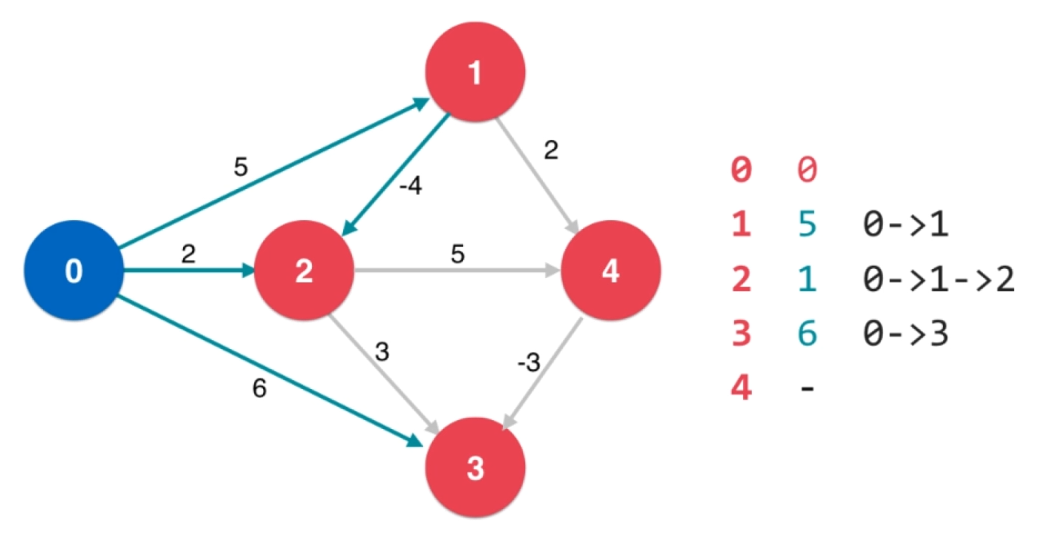
- 重复松弛操作的次数至 $\displaystyle V - 1$ 次,找到从源点开始经过 $V - 1$ 条边到达其相邻结点的路径,最终就可得出最短路径
- 如果对一个结点进行 $V - 1$ 次松弛后还可以继续松弛,则说明图中有负权环
算法描述:对图中每一个结点都进行 $V - 1$ 次松弛操作, 即可得出单源最短路径。
import java.util.Vector;
import java.util.Stack;
// 使用BellmanFord算法求最短路径
public class BellmanFord<Weight extends Number & Comparable> {
private WeightedGraph G; // 图的引用
private int s; // 起始点
private Number[] distTo; // distTo[i]存储从起始点s到i的最短路径长度
Edge<Weight>[] from; // from[i]记录最短路径中, 到达i点的边是哪一条,可以用来恢复整个最短路径
boolean hasNegativeCycle; // 标记图中是否有负权环
// 构造函数, 使用BellmanFord算法求最短路径
public BellmanFord(WeightedGraph graph, int s){
G = graph;
this.s = s;
distTo = new Number[G.V()];
from = new Edge[G.V()];
// 初始化所有的节点s都不可达, 由from数组来表示
for( int i = 0 ; i < G.V() ; i ++ )
from[i] = null;
// 设置distTo[s] = 0, 并且让from[s]不为NULL, 表示初始s节点可达且距离为0
distTo[s] = 0.0;
// 这里我们from[s]的内容是new出来的, 注意要在析构函数里delete掉
from[s] = new Edge<Weight>(s, s, (Weight)(Number)(0.0));
// Bellman-Ford的过程
// 进行V-1次循环, 每一次循环求出从起点到其余所有点, 最多使用pass步可到达的最短距离
for( int pass = 1 ; pass < G.V() ; pass ++ ){
// 每次循环中对所有的边进行一遍松弛操作
// 遍历所有边的方式是先遍历所有的顶点, 然后遍历和所有顶点相邻的所有边
for( int i = 0 ; i < G.V() ; i ++ ){
// 使用我们实现的邻边迭代器遍历和所有顶点相邻的所有边
for( Object item : G.adj(i) ){
Edge<Weight> e = (Edge<Weight>)item;
// 对于每一个边首先判断e->v()可达
// 之后看如果e->w()以前没有到达过, 显然我们可以更新distTo[e->w()]
// 或者e->w()以前虽然到达过, 但是通过这个e我们可以获得一个更短的距离, 即可以进行一次松弛操作, 我们也 // 可以更新distTo[e->w()]
if( from[e.v()] != null && (from[e.w()] == null || distTo[e.v()].doubleValue() + e.wt().doubleValue() < distTo[e.w()].doubleValue()) ){
distTo[e.w()] = distTo[e.v()].doubleValue() + e.wt().doubleValue();
from[e.w()] = e;
}
}
}
}
hasNegativeCycle = detectNegativeCycle();
}
// 判断图中是否有负权环
boolean detectNegativeCycle(){
for( int i = 0 ; i < G.V() ; i ++ ){
for( Object item : G.adj(i) ){
Edge<Weight> e = (Edge<Weight>)item;
// 还能进行松弛操作,则说明有负权环
if( from[e.v()] != null
&& distTo[e.v()].doubleValue() + e.wt().doubleValue() < distTo[e.w()].doubleValue() ){
return true;
}
}
}
return false;
}
// 返回图中是否有负权环
boolean negativeCycle(){
return hasNegativeCycle;
}
// 返回从s点到w点的最短路径长度
Number shortestPathTo( int w ){
assert w >= 0 && w < G.V();
assert !hasNegativeCycle;
assert hasPathTo(w);
return distTo[w];
}
// 判断从s点到w点是否连通
boolean hasPathTo( int w ){
assert( w >= 0 && w < G.V() );
return from[w] != null;
}
// 寻找从s到w的最短路径, 将整个路径经过的边存放在vec中
Vector<Edge<Weight>> shortestPath(int w){
assert w >= 0 && w < G.V() ;
assert !hasNegativeCycle ;
assert hasPathTo(w) ;
// 通过from数组逆向查找到从s到w的路径, 存放到栈中
Stack<Edge<Weight>> s = new Stack<Edge<Weight>>();
Edge<Weight> e = from[w];
while( e.v() != this.s ){
s.push(e);
e = from[e.v()];
}
s.push(e);
// 从栈中依次取出元素, 获得顺序的从s到w的路径
Vector<Edge<Weight>> res = new Vector<Edge<Weight>>();
while( !s.empty() ){
e = s.pop();
res.add(e);
}
return res;
}
// 打印出从s点到w点的路径
void showPath(int w){
assert( w >= 0 && w < G.V() );
assert( !hasNegativeCycle );
assert( hasPathTo(w) );
Vector<Edge<Weight>> res = shortestPath(w);
for( int i = 0 ; i < res.size() ; i ++ ){
System.out.print(res.elementAt(i).v() + " -> ");
if( i == res.size()-1 )
System.out.println(res.elementAt(i).w());
}
}
}

{kind=link}