15-哈希表 HashTable
学习资源:慕课网liyubobobo老师的《玩儿转数据结构》
1、简介
哈希表(Hash tabl),是根据键(Key)而直接访问在内存储存位置的数据结构。也就是说,它通过计算一个关于键值的函数,将所需查询的数据映射到表中一个位置来访问记录,这加快了查找速度。这个映射函数称做哈希函数,存放记录的数组称做哈希表。
一个通俗的例子是,为了查找电话簿中某人的号码,可以创建一个按照人名首字母顺序排列的表(即建立人名 x 到首字母 F(x) 的一个函数关系),在首字母为 W 的表中查找 "王" 姓的电话号码,显然比直接查找就要快得多。这里使用人名作为关键字,"取首字母"是这个例子中哈希函数的函数法则 F(),存放首字母的表对应哈希表。关键字和函数法则理论上可以任意确定。
- 若关键字为 k,则其值存放在 f(k) 的存储位置上。由此,不需比较便可直接取得所查记录。称这个对应关系 f 为哈希函数,按这个思想建立的表为哈希表。
- 对不同的关键字可能得到同一哈希地址,即 k1≠k2 ,而 f(k1) = f(k2),这种现象称为哈希冲突。具有相同函数值的关键字对该哈希函数来说称做同义词。综上所述,根据哈希函数 f(k) 和处理冲突的方法将一组关键字映射到一个有限的连续的地址集(区间)上,并以关键字在地址集中的 "像" 作为记录在表中的存储位置,这种表便称为哈希表,这一映射过程称为哈希函数,所得的存储位置称哈希地址。
- 若对于关键字集合中的任一个关键字,经哈希函数映象到地址集合中任何一个地址的概率是相等的,则称此类哈希函数为均匀哈希函数,这就使关键字经过哈希函数得到一个"随机的地址",从而减少冲突。
2、如何设计哈希函数
哈希函数:简单理解即是,输入原始数据,输出经哈希函数计算原始数据在哈希表中的存储位置(即数组索引)。
设计原则:
- 一致性:如果a==b,则hash(a) == hash(b)
- 高效性:计算高效简便
- 均匀性:哈希值均匀分布("键"通过哈希函数得到的"索引"分布越均匀越好)
2.1、整型
-
小范围正整数直接使用
-
小范围负整数进行偏移

-
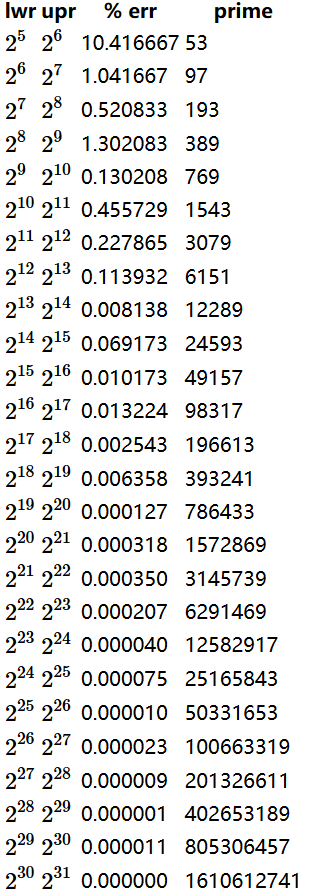
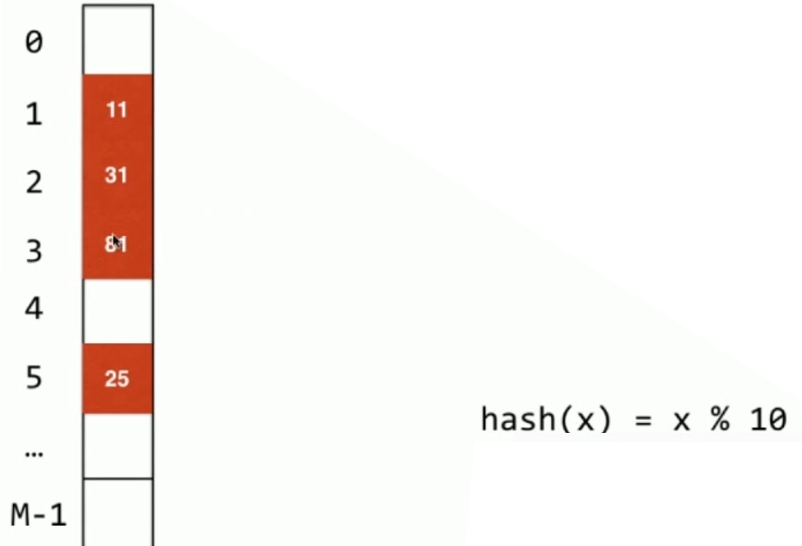
大整数,通常做法:取模,模一个素数 M(素数M可以保证哈希值分布均并利用上大整数的所有信息,这个 M 也将会是哈希表的大小)。

good hash table primes(不同规模的数据所对应的 M):
2.2、浮点型
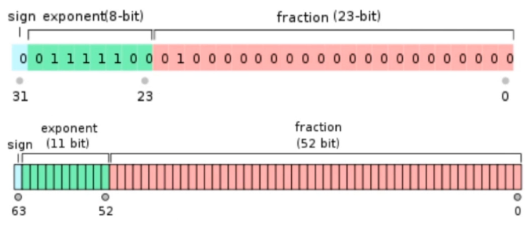
在计算机中都是以32位或者64位的二进制表示,只不过计算机解析成了浮点数。
因此可以将这32位或者64位的0101...数据转换为其二进制所对应的整型
- 将 float 或 double 型数据转换为对应的二进制整型
- 对二进制整型进行取模
2.3、字符串
字符串依然可以转换为整型。
- 十进制整型:

- 只包含小写英文字母的字符串:
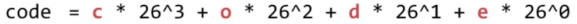
- 一般意义上的字符串:

相应的,哈希函数为:
简化:
int hash = 0;
for(int i=0; i<s.length(); i++)
hash = (hash*B + s.charAt(i)) % M;
2.4、复合类型
复合类型依然也可以转换为整型处理,可以套用字符串的哈希函数,计算出类中的属性的哈希值。
如:Date类,属性:year,month,day
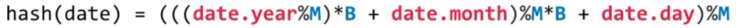
B 需要特殊设计。
// 学生类
public class Student {
private int grade;
private int cls;
private int id;
private String name;
public Student(int grade, int cls, int id, String name) {
this.grade = grade;
this.cls = cls;
this.id = id;
this.name = name;
}
@Override
public int hashCode() {
;
int B = 31;
int hash = 0;
hash = hash*B + grade; // Interger的哈希值就是它本身
hash = hash*B + cls;
hash = hash*B + id;
hash = hash*B + name.hashCode();
return hash;
}
}
3、Java中的哈希函数
Object类(Java中所有类的默认父类)中有hashCode方法,根据对象的地址值将其映射为一个 int 整型
public native int hashCode(); // 是一个本地方法,返回对象的地址值。
Java的设计中该方法的返回值是 int 型,自然会有负的返回值,所以要由哈希值映射到哈希表的索引,则需要在哈希表中另作处理。(在Java中,一般对hashCode的计算结果取绝对值即可)
// 测试 hashCode()
public static void main(String[] args) {
String str1 = "go";
String str3 = new String("go");
System.out.println(str1.hashCode()); // 3304
System.out.println(str3.hashCode()); // 3304
Integer a = 10;
Integer b = -10;
System.out.println(a.hashCode()); // 10
System.out.println(b.hashCode()); // -10
Float c = 0.5f;
Float d = -0.5f;
System.out.println(c.hashCode()); // 1056964608
System.out.println(d.hashCode()); // -1090519040
}
// 哈希值取绝对值
hashCode(object) & 0x7fffffff
4、解决哈希冲突
哈希冲突:"键"通过哈希函数的转换,对应了相同的"索引"。
为了解决哈希冲突,需要比较发生冲突的对象,看它们是否实际的相等"equal",如果相等则说明哈希冲突不存在,如果不相等再另作处理解决冲突。
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
return grade == student.grade &&
cls == student.cls &&
id == student.id &&
Objects.equals(name, student.name);
}
4.1、链地址法 Separate Chaining
哈希表(本质是M大的数组)的内部使用查找表(链表、平衡树等),则在发生冲突时,在同一个索引处还可以继续存入。
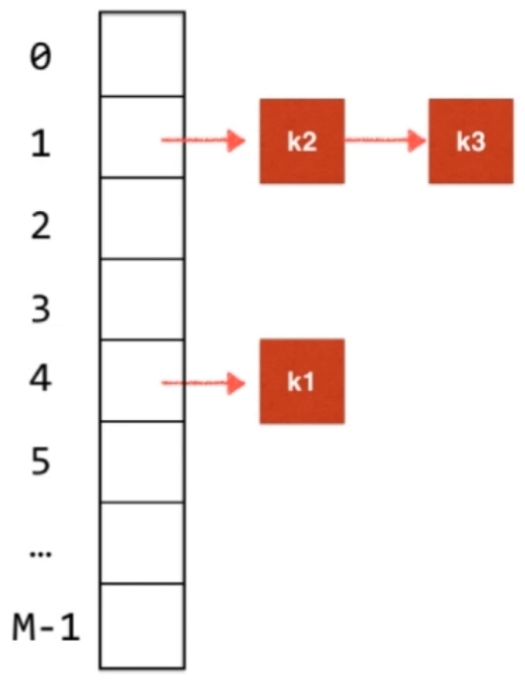
Java中的 HashMap 从本质上讲就是一个 TreeMap 数组,HashSet就是一个 TreeSet 数组。
Java标准库中哈希表的相关实现:Java8之前,每一个位置对应一个链表;Java8开始,当哈希冲突达到一定程度每一个位置从链表转成红黑树。
4.2、开放地址法(加补偿)
- 线性探测:遇到哈希冲突,算得的哈希值对应的索引+1
- 平方探测:遇到哈希冲突,算得的哈希值对应的索引+1、+4、+9、+16 ...
- 二次哈希:使用hash1计算遇到哈希冲突, 算得的哈希值对应的索引+hash2(key)
4.3、再哈希法 Rehashing
简单理解:使用hash1,发生哈希冲突,则转而使用hash2计算哈希值。
4.4、Coalesced Hashing
5、代码
底层使用 TreeMap 数组,便于解决哈希冲突。(PS:尽管使用链地址法可以有效地解决哈希冲突,但还是应避免发生哈希冲突,所以哈希表的容量应动态化)
代码bug:TreeMap 的 key 是要求具有可比较性的,而这里实现的哈希表的 key 不要求具有可比较性,所以在添加不具有可比较性的对象就会发生错误。
package hashTable;
import java.util.TreeMap;
public class HashTable<K, V> {
// 自定义平均每个地址承载元素的上限
private static final int upperTol = 10;
// 自定义平均每个地址承载元素的下限
private static final int lowerTol = 2;
private int capacityIndex = 0;
// 素数M(哈希表的容量)的大小 采用查表法获取
private final int[] capacity = {53,97,193,389,769,1543,3079,6151,12289,24593,49157,98317,
196613,393241,789433,1572869,3145739,6291469,12582917,25165843,50331653,100663319,
201326611,402653189,805306457,1610612741
};
// 底层是TreeMap数组
private TreeMap<K, V>[] hashTable;
private int size;
private int M;
public HashTable() {
this.M = capacity[capacityIndex];
size = 0;
hashTable = new TreeMap[M];
for (int i = 0; i < M; i++)
hashTable[i] = new TreeMap<>();
}
private int hash(K key){
return (key.hashCode() & 0x7fffffff) % M;
}
public int getSize(){
return size;
}
public void add(K key, V value){
TreeMap<K, V> map = hashTable[hash(key)];
if(map.containsKey(key))
map.put(key, value);
// 发生哈希冲突
else {
map.put(key, value);
size++;
if(size >= upperTol*M && capacityIndex+1 < capacity.length){
capacityIndex++;
resize(capacity[capacityIndex]);
}
}
}
public V remove(K key){
V remove = null;
TreeMap<K, V> map = hashTable[hash(key)];
if(map.containsKey(key)){
remove = map.remove(key);
size--;
if(size <= lowerTol*M && capacityIndex-1 > 0){
capacityIndex--;
resize(capacity[capacityIndex]);
}
}
return remove;
}
public void set(K key, V value){
TreeMap<K, V> map = hashTable[hash(key)];
if(!map.containsKey(key))
throw new IllegalArgumentException(key + "不存在");
map.put(key, value);
}
public boolean contains(K key){
return hashTable[hash(key)].containsKey(key);
}
public V get(K key){
return hashTable[hash(key)].get(key);
}
private void resize(int newM) {
TreeMap<K, V>[] newHashTable = new TreeMap[newM];
for(int i = 0 ; i < newM ; i ++)
newHashTable[i] = new TreeMap<>();
int oldM = M;
this.M = newM;
for(int i = 0; i< oldM; i++){
TreeMap<K, V> map = hashTable[i];
for (K key : map.keySet())
newHashTable[hash(key)].put(key, map.get(key));
}
this.hashTable = newHashTable;
}
}
6、总结
- 哈希表的本质是一个数组,空间大小为 M,其大小取决于数据的规模
- 哈希表存储的是一个个的实例对象
- 哈希函数根据情况进行重写
- 索引由哈希函数计算生成,由于索引不能为负,所以需要去除负号
- 解决哈希冲突
