
爬虫抓取糯米网上所有商家数据
前段时间写了 爬取美团商家信息的博客 爬虫抓取美团网上所有商家信息 ,这次说说爬取糯米网,由于某些原因无法提供源代码,但是,代码不是关键,最关键的是思想,懂了思想,代码是很容易写的.
爬虫最重要的是分析请求过程,按照实际请求过程去请求数据.
分析是否需要处理cookie,有些网站比较严格请求某些接口的数据时是需要cookie,获取cookie的链接一般是首页,一般的系统会有一个JsessionId 来保持会话.从你访问一个页面开始服务器就会返回这个JsessionId给你,但是访问某些接口,没有带这个cookie,服务器就不会返回数据给你, 这个可以看看我之前写的 使用python爬取12306上面所有车次数据 ,在爬取12306时就需要处理cookie.
分析网站的请求限制,由于爬虫会增加他们服务器压力,流量浪费,数据损失.所以很多网站都会有请求次数的限制.但是他们数据既然是开放的,就一定可以爬取到.只是付出的代价大小的问题.一般会根据ip来限制请求,请求到一定次数时会有验证码. 比如在爬天眼查的数据时,就遇到这个问题.可以使用代理.现在获取代理很容易,也很便宜.
分析网站的数据是否是通过ajax加载的,返回的数据是否有加密.一般这种情况可以使用无界面的浏览器来请求,浏览器中会自己处理好这些事情.
抓取页面,解析想要数据,这个就比较简单了.页面已经抓取下来了,可以使用一些开源的框架解析页面中数据,也可以使用正则.
下面分析如何抓取糯米网上的数据.
经过分析发现糯米 不需要处理cookie,没有ajax加载的情况,有请求的限制,所以就只需要使用代理就可以了.
我们现在分析要如何才能爬取全部数据.
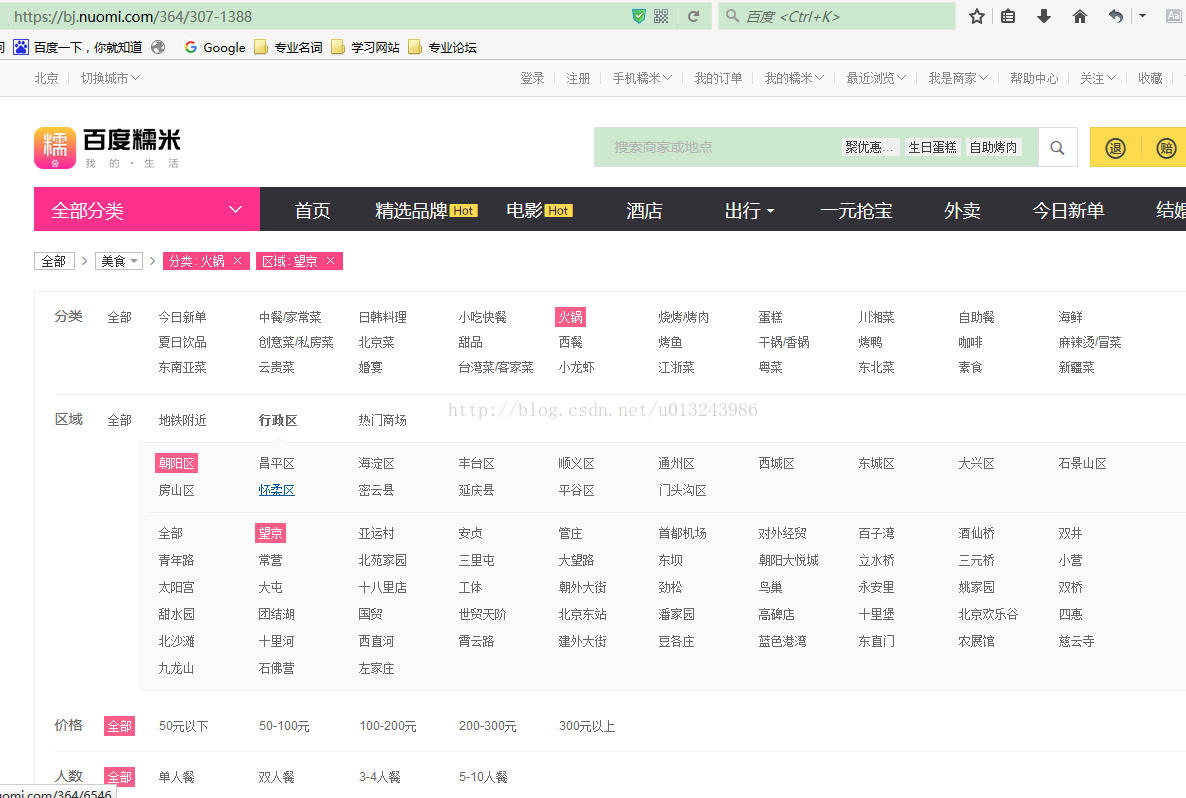
从链接https://bj.nuomi.com/364/307-1388 可以猜测 bj就是北京, 364是火锅的分类,307-1388就是地区.提前收集这些数据后面爬取的时候直接拼接就可以,方便快捷.
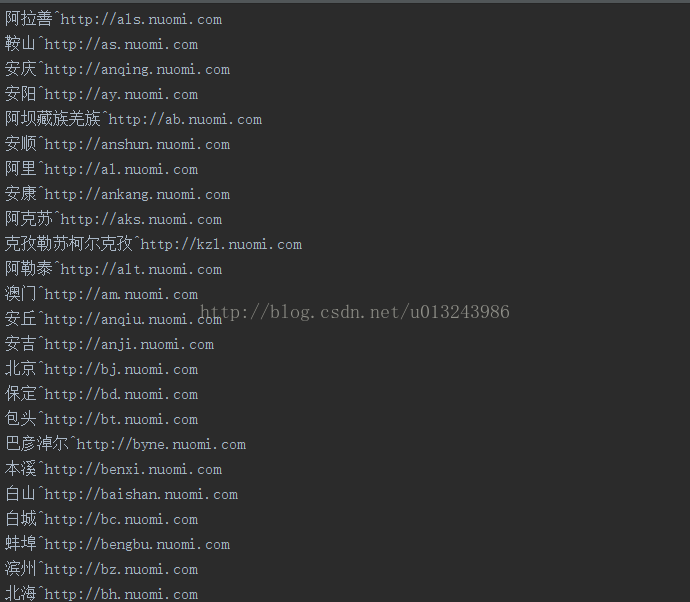
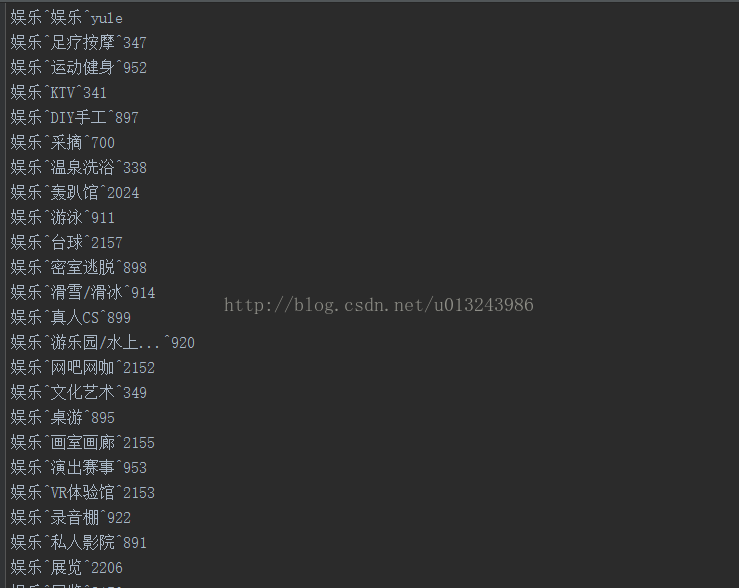
这里我只整理到城市,没有整理到区,所以区和商圈是我们爬取时需要处理,可以先拼接城市和分类然后获取区/县
再遍历区县,获取商圈,再遍历,最后就可以获取团购数据
- # 区/县
- def getArea(cityUrl,cityName,type,subType,subTypeCode):
- url=cityUrl+"/"+subTypeCode
- soup=download_soup_waitting(url)
- try:
- geo_filter_wrapper=soup.find("div",attrs={"class":"filterDistrict"})
- J_filter_list=geo_filter_wrapper.find("div",attrs={"class":"district-list-ab"})
- lis=J_filter_list.findAll("a")
- for li in lis :
- # a=li.find("a")
- url='http:'+li['href']
- area=li.text
- getSubArea(url,area,cityName,type,subType)
- except:
- getBusiness(url,"","",cityName,type,subType)
- # 商圈
- def getSubArea(url,area,cityName,type,subType):
- soup=download_soup_waitting(url)
- geo_filter_wrapper=soup.find("div",attrs={"class":"district-sub-list-ab"})
- if geo_filter_wrapper==None:
- getBusiness(url,"",area,cityName,type,subType)
- return
- lis=geo_filter_wrapper.findAll("a")[1:]
- for li in lis :
- # a=li.find("a")
- url=li['href']
- subArea=li.text
- getBusiness("http:"+url,subArea,area,cityName,type,subType)
现在就来分析团购信息,

可以发现这不是商家,而是团购的商品,说明这些团购后面有很多是同个商家.我们分两层来爬取,因为这一层是有顺序的一个城市一个类别的爬.但是通过团购获取商家信息是没有顺序的.
爬取这一层之后的结果如下.
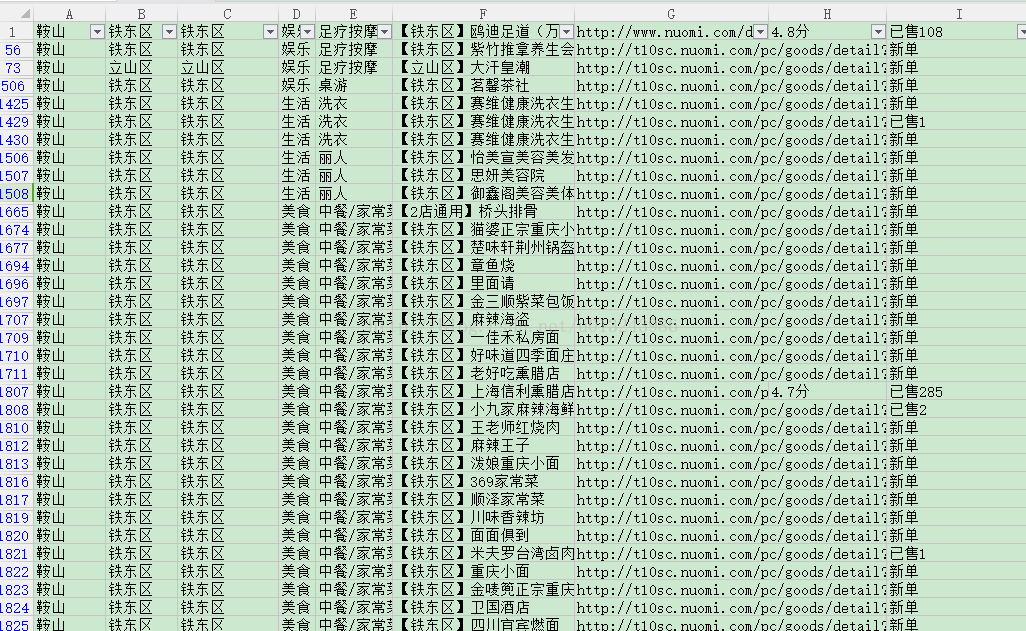
这一层是无法获取商家的更详细的信息,但是通过这个团购链接就可以获取到更加详细的信息.我们对这些团购链接进行排重,然后进行第二层爬取.
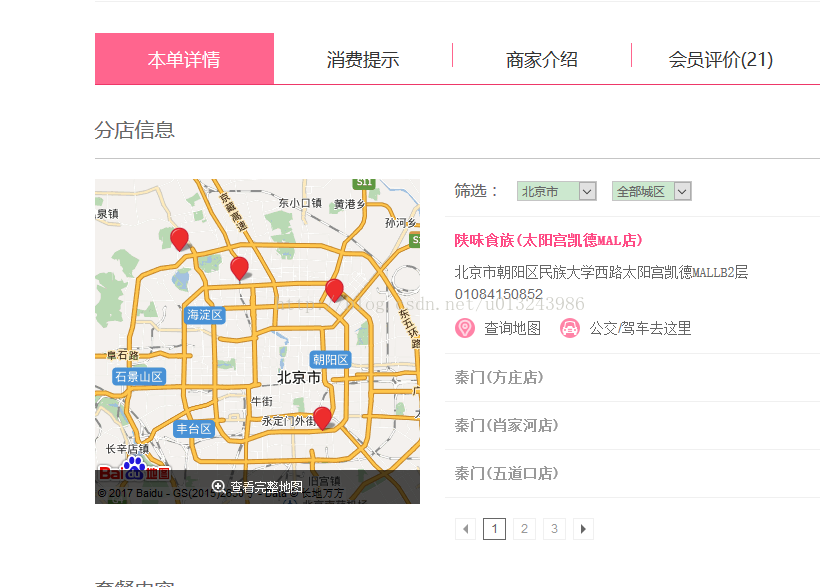
这里就是我们需要的数据,但是在实际爬取时发现抓取到的页面没有这个数据.可以猜测这是通过ajax来加载的.
立刻打开firebug,刷新页面
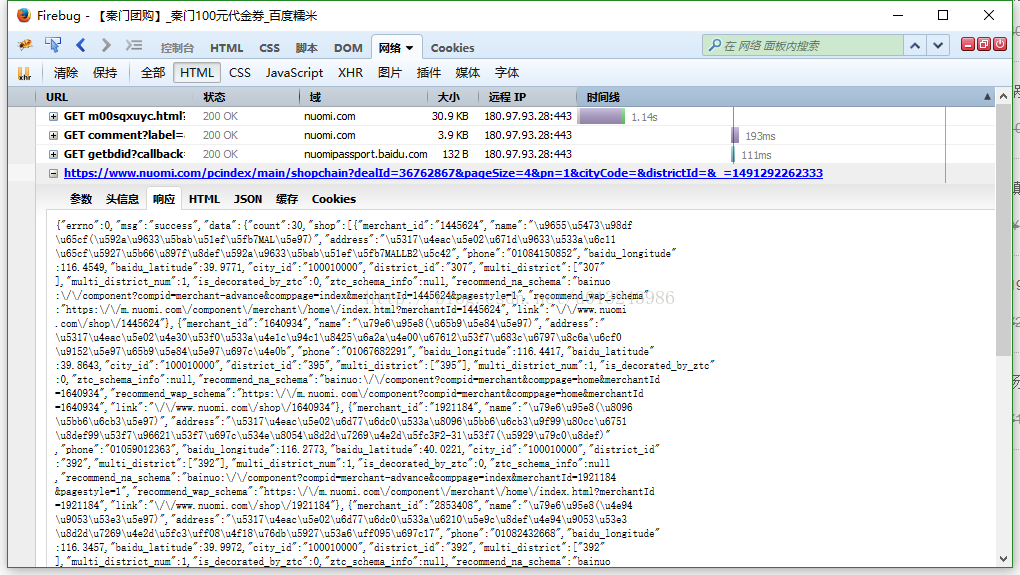
发现果然和我的猜想是一样的这块数据是通过ajax来加载的,查看链接发现,只要获取到dealid就可以拼接链接了.
最后只要只要对抓取的数据进行解析保存就可以了.
分析完全部的过程,写完代码,就可以让程序慢慢跑了,我的这个数据是运行了一个月才有结果.然后对数据进行整理.最终的数据如下:
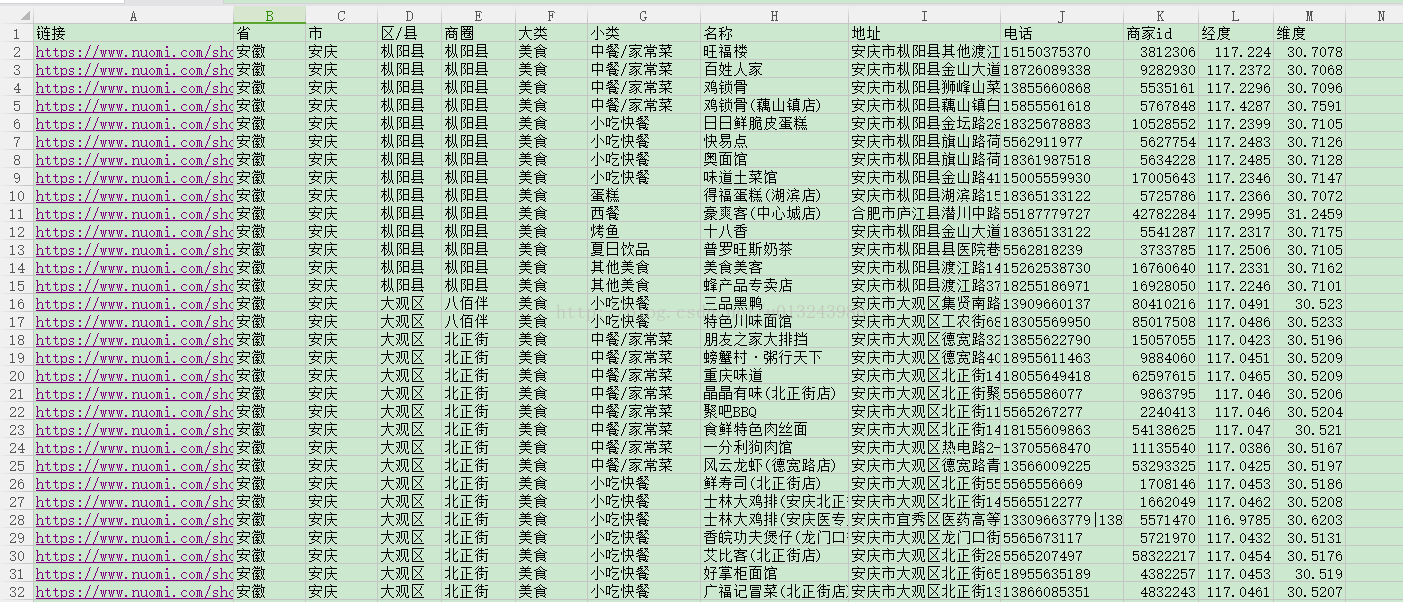
糯米美食 453792条数据
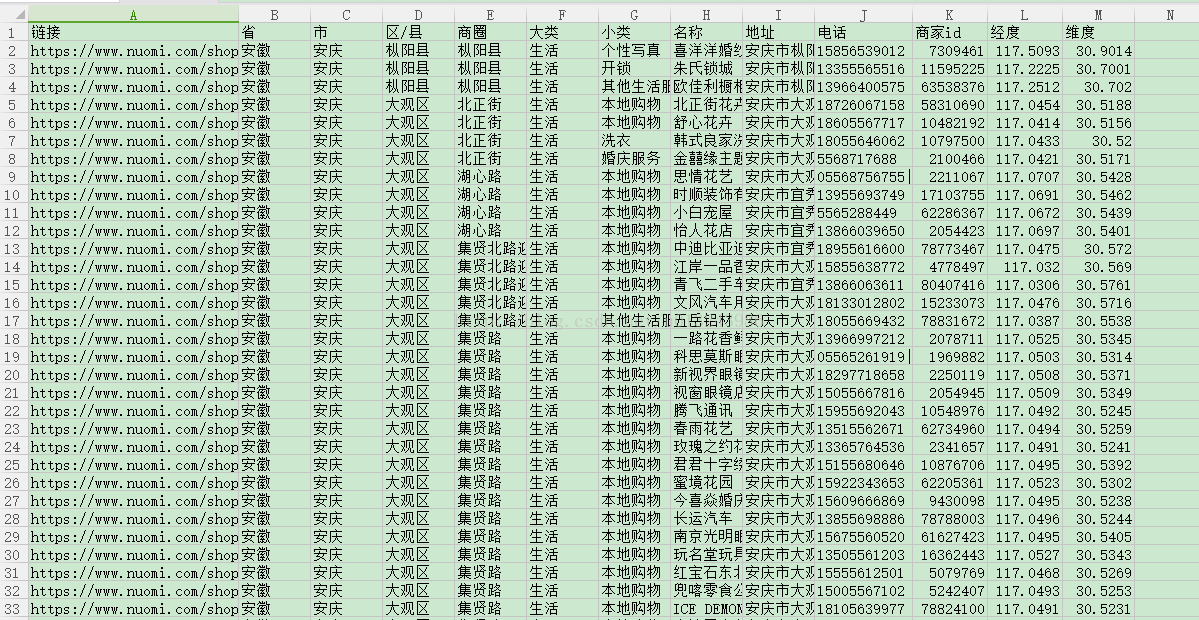
糯米生活 149002条数据
糯米娱乐 74932条数据
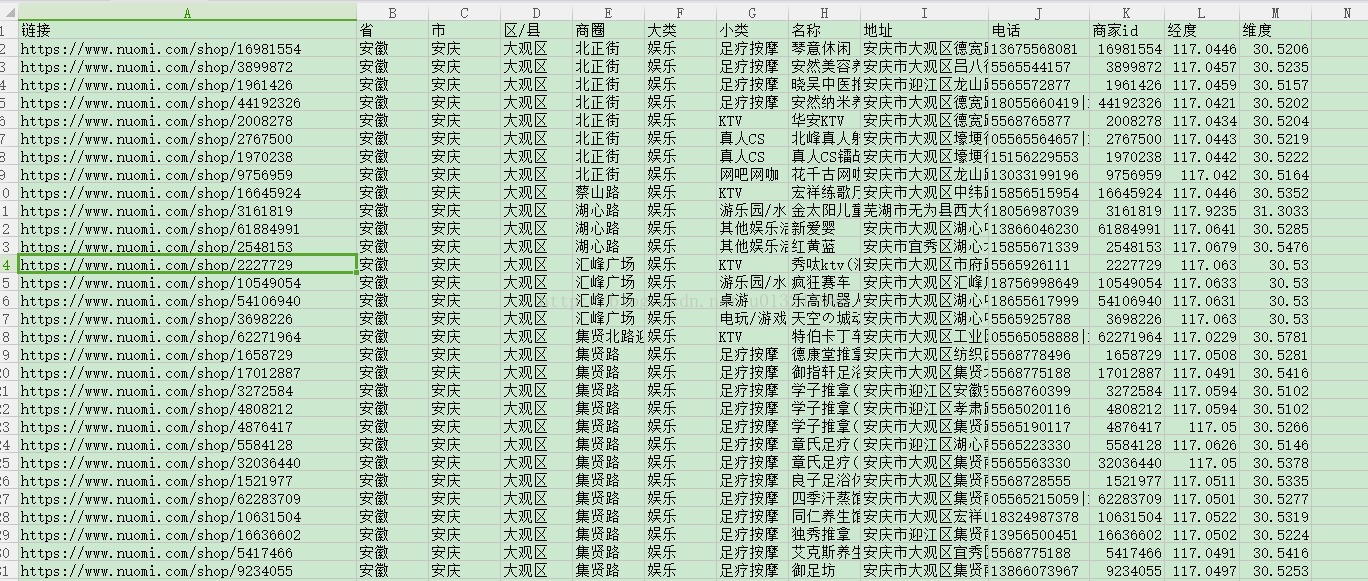
糯米丽人 73123条数据
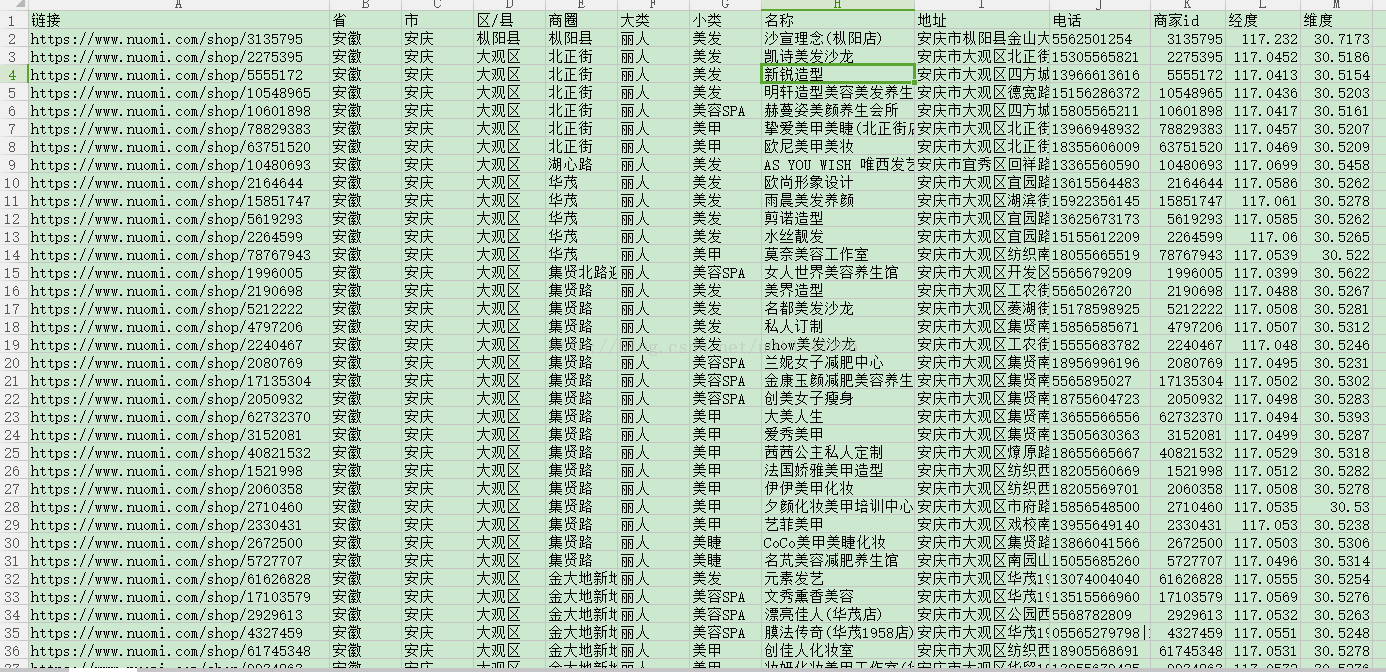
总的数据 750849 条数据
时间:20170404
https://blog.csdn.net/u013243986/article/details/69062941

 浙公网安备 33010602011771号
浙公网安备 33010602011771号