
spark概述
Spark背景:MapReduce局限性
MapReduce框架局限性
1、仅支持Map和Reduce两种操作,提供给用户的只有这两种操作
2、处理效率低效
Map中间结果写磁盘,Reduce写HDFS,多个MR之间通过HDFS交换数据
任务调度和启动开销大:mr的启动开销一,客户端需要把应用程序提交给resourcesManager,resourcesManager去选择节点去运行,快的话几秒钟,慢的话1分钟左右,开销二,maptask和reducetask的启动,当他俩被resourcesManager调度的时候,会先启动一个container进程,然后让他俩运行起来,每一个task都要经历jvm的启动,销毁等,这两点就是mr启动开销
无法充分利用内存
3、Map端和Reduce端均需要排序:map和Reduce是都需要进行排序的,但是有的程序完全不需要排序(比如求最大值求最小值,聚合等),所以就造成了性能的低效
4、不适合迭代计算(如机器学习、图计算等),交互式处理(数据挖掘)和流式处理(点击日志分析):因为任务调度和启动开销大,所以不适合交互式处理,比如你启动要一分钟,任务调度要几分钟,我得等半天,这不适合
MapReduce编程不够灵活
map和reduce输入输出类型格式限制死了,可尝试scala函数式编程语言
背景:框架多样化
现有的各种计算框架各自为战
批处理:MapReduce、Hive、Pig
流式计算:Storm
交互式计算:presto,Impala
能否有一种灵活的框架可同时进行批处理、流式计算、交互式计算等?
大数据时代,最重要的两种技术
一个是存储的技术,如hdfs,hbase,一个是计算的技术,如上述说的MR、Storm、Impala
Spark特点
1、高效(比MapReduce快10~100倍)
内存计算引擎,提供Cache机制来支持需要反复迭代计算或者多次数据共享,减少数据读取的IO开销
DAG引擎,这种引擎的特点是,不同任务之间互相依赖,减少多次计算之间中间结果写到HDFS的开销
使用多线程池模型来减少task启动开稍(特指MR中每个task都要经历JVM启动运行销毁操作,Spark的做法是,启动一些常驻的进程,在进程内部会有多个线程去计算task,来一个task,计算task,并回收线程,以此循环,这样就没有JVM的开销),shuffle过程中避免不必要的sort操作以及减少磁盘IO操作
2、易用
提供了丰富的API,支持Java,Scala,Python和R四种语言
代码量比MapReduce少2~5倍
3、与Hadoop集成
读写HDFS/Hbase
与YARN集成
Spark核心概念—RDD
RDD:Resilient Distributed Datasets,弹性分布式数据集
数据集与分布式:
分布在集群中的只读对象集合(由多个Partition构成)
可以存储在磁盘或内存中(多种存储级别)
弹性:
通过并行“转换”操作构造,数据通过一些转换方式,在转换成其他数据集
失效后自动重构,数据有自恢复能力

大白话:
rdd丢了,要用该rdd的时候,才会重构,不是丢掉的时候去重构
rdd有三个分区,比如partition1丢了,就去重构partition1,其他分区不会重构
rdd包含两部分,数据部分,元信息部分,元信息包含有哪些分区,分区放在哪些地点,分区的父分区id,及如何从父分区生成该分区(如map算子),元信息放在一个中心节点,当重构后,名字什么的元信息是不变的,如果中心节点挂掉,那整个程序就失败,也就无所谓rdd元信息丢不丢了
rdd的个数:
如果文件是在hdfs上的,那么hdfs上有多少个block,就有多少个rdd
如果源数据是在内存里的,那么就可以随意指定分区数
RDD基本操作(operator)
Transformation
可通过Scala集合或者Hadoop数据集构造一个新的RDD
通过已有的RDD产生新的RDD
举例:map, filter,groupBy,reduceBy
Action
通过RDD计算得到一个或者一组值
举例:count,reduce,saveAsTextFile

Spark RDD cache/persist
Spark RDD Cache
允许将RDD缓存到内存中或磁盘上,以便于重用
Spark提供了多种缓存级别,以便于用户根据实际需求进行调整

通过名字就大概知道对应的是什么存储策略,其中,DISK_ONLY_2指的是只存储在磁盘,在其他节点上额外存储一份
不指定的话,默认是NONE,就是不存储,指定了后才存储
带SER的表示对数据进行压缩,优点是省内存,缺点是,取数据的时候需要解压
RDD cache使用
val data = sc.textFile(“hdfs://nn:8020/input”) data.cache() //实际上是data.persist(StorageLevel.MEMORY_ONLY) //data.persist(StorageLevel.DISK_ONLY_2)
RDD Transformation & Action
接口定义方式不同
Transformation:RDD[X] --> RDD[Y]
Action: RDD[X] --> Z (Z不是一个RDD, 可能是基本类型,数组等)
惰性执行(Lazy Execution)
Transformation只会记录RDD转化关系,并不会触发计算,rdd[x] transfer到rdd[y] ,并不会生成一个结果,数据也不会变化,而是把计算过程记录下来,到执行action的时候,才会计算最终rdd
Action是触发程序执行(分布式)的算子
spark运行模式
程序执行流程

如上述代码,resultRdd的生成过程会产生四个RDD,前面三个RDD的分区是一对一的关系,第三个到第四个则是多对一,这里有一种说法,叫做宽依赖(一个分区依赖前面多个分区)和窄依赖
提交Spark程序(运行在YARN上)
export YARN_CONF_DIR=/opt/hadoop/yarn-client/etc/hadoop bin/spark-submit \ --master yarn-cluster \ --class com.hulu.examples.SparkPi \ --name sparkpi \ --driver-memory 2g \ --driver-cores 1 \ --executor-memory 3g \ --executor-cores 2 \ --num-executors 2 \ --queue spark \ --conf spark.pi.iterators=500000 \ --conf spark.pi.slices=10 \ $FWDIR/target/scala-2.10/spark-example-assembly-1.0.jar
--master yarn-cluster,指定启动在那种模式,如果是本地,则local[k]
程序架构
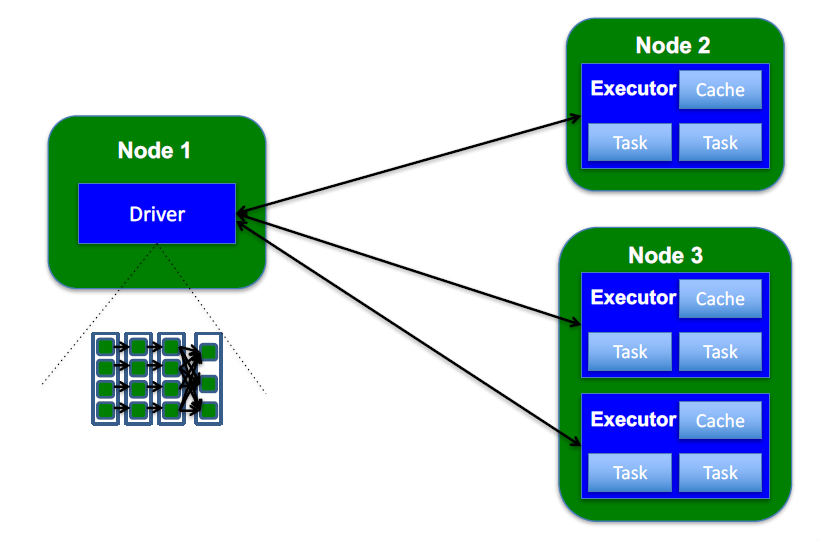
下面指的是跑在yarn上:
上面刚才的代码就会运行在driver上,driver可以认为是spark的context,这里还有另外一个角色,就是executor,spark为了加速程序的运行,它会预先启动一些常驻内存的进程,这些进程上可以运行任务,这些进程就是executor,他跟mr不一样,mr是当我有一个任务的时候,才会启动一个jvm去计算这个任务
driver可以把任务分解发到给executor,executor去执行这些任务,执行完后,executor空闲出来,driver就又可以发送任务给executor,这样就省出了jvm的启动开销
executor是一个分布式执行的进程,在不同的物理节点上,会存在多个executor
元信息全部存放在driver上,rdd的数据信息是存放在executor上的,executor上面有一个cache,在这个内存里存储了rdd的每一个分区的数据,如果我指定了把这个rdd缓存起来,那么这里就会被driver记录我这个rdd存放在哪个executor上
数据信息存放在executor上的cache(mem_only)上, 或者exec那个node的disk(disk_only)上
Spark运行模式
local(本地模式)
什么是本地模式?将Spark应用以多线程方式,所有executor都是跑在一个节点的一个进程里面的,每一个executor都是一个线程,直接运行在本地,便于调试
本地模式分类:
local:只启动一个executor
local[K]:启动K个executor
local[*]:启动跟cpu数目相同的executor
standalone(独立模式)
独立运行在一个集群中
standalone是spark自己提供的,在这种模式里,spark自己有一个master程序。在master程序里,它会管理很多worker节点,在worker节点里面,他的driver和executor都是跑在对应的worker之上的
YARN/mesos
运行在资源管理系统上,比如YARN或mesos,上面那个架构就是yarn运行模式
yarn这种,driver和executor都是跑在yarn的container里面的,就是跑在每一个nodemanager之上的
Spark On YARN存在两种模式
yarn-client
yarn-cluster
程序运行模式:独立(Standlone)模式

standalone中,它有一个master以及多个slave节点,这都是物理的机器,在每一个slave上他都运行着很多的executor,driver程序实际上是跑在一个executor之上的,这个driver会直接向executor发送任务
master是管理整个集群的节点,master不参与整个任务的分配,他管理的是这些driver的启动,driver到task的启动是由driver来控制的,不是由master来控制的
在这个架构里,master是一个单点的,为了防止单点,他是通过zookeeper来进行协作的,还有一个备份的master,一旦主master挂掉,所有的slaver会将汇报转发给备份master,master之间的切换是通过zookeeper来进行的
程序运行模式:YARN分布式模式(yarn-client)

这里,他是有一个客户端把程序提交到resourcesManager申请资源,然后由resourcesManager去选择一个空闲的nodeManager,去运行一个applicationmaster程序,applicationmaster会为nodemanagers去向resourcesManager申请资源,得到nodemanagers各个executor,他让各个executor启动后去将自己注册到客户端的driver程序上,然后driver在运行过程中,会将任务发送给各个executor,executor里面的task是driver的task
下面这个图更清晰一些:
 yarn-client这种模式的应用场景解释:
yarn-client这种模式的应用场景解释:
这种模式启动后,会把所有信息都发送到driver端,driver端一旦退出,整个应用程序会全部销毁,所以在跑长期的应用,比如要跑十几个小时,你把电脑关上,那就失败,那就不要用yarn-client了
程序运行模式:YARN分布式模式(yarn-cluster)
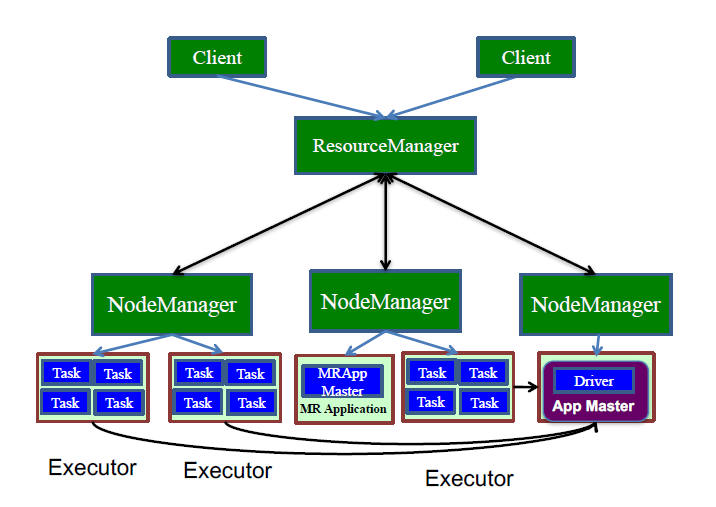
yarn-cluster和yarn-client比较类似,但是driver不在运行在client端,driver运行在applicationmaster之上,除了这里不一样,其他都一样
即,yarn-cluster下,client端,他的作用只是把你的任务提交到集群里面,然后由集群选择一个节点去运行,此时你的客户端程序完全退出对集群没有任何关系,集群是会继续跑你的程序
对比之下,yarn-client存在的原因还有:
在yarn-cluster里面你的applicationmaster是跑在任意一个nodemanager的,这个节点上,你是没法控制它的,比如我想控制程序的执行,再输入一个参数什么的,是很难做到这样的
再比如
yarn-client这种模式,我可以在client端做各种各样的事情,比如进行一些初始化,加载一些东西,或者像python需要一些必要的环境,这个时候,就需要在client端把事情都做好,依赖的软件都装好,由client去运行程序就行了,而如果是cluster这种,把程序提交到任意一个节点,万一那个节点缺少一些环境,那就没法运行
其他
随后将为这些输入分片生成具体的Task。InputSplit与Task是一一对应的关系。
随后这些具体的Task每个都会被分配到集群上的某个节点的某个Executor去执行。
- 每个节点可以起一个或多个Executor。
- 每个Executor由若干core组成,每个Executor的每个core一次只能执行一个Task。
- 每个Task执行的结果就是生成了目标RDD的一个partiton。
注意: 这里的core是虚拟的core而不是机器的物理CPU核,可以理解为就是Executor的一个工作线程。
而 Task被执行的并发度 = Executor数目 * 每个Executor核数。
最后
sparkjobserver很多大公司都在用

 浙公网安备 33010602011771号
浙公网安备 33010602011771号