Oracle Redo Log 机制 小结(转载)
Oracle 的Redo 机制DB的一个重要机制,理解这个机制对DBA来说也是非常重要,之前的Blog里也林林散散的写了一些,前些日子看老白日记里也有说明,所以结合老白日记里的内容,对oracle 的整个Redo log 机制重新整理一下。
一.Redo log 说明
Oracle 的Online redo log 是为确保已经提交的事务不会丢失而建立的一个机制。 因为这种健全的机制,才能让我们在数据库crash时,恢复数据,保证数据不丢失。
1.1 恢复分类
恢复分两种:
(1) Crash recovery
(2) Media recovery
这两种的具体说明,参考:
Oracle 实例恢复时 前滚(roll forward) 后滚(rollback) 问题
http://blog.csdn.net/tianlesoftware/article/details/6286330
这两种的区别是:
(1) Crash Recovery 是在启动时DB 自动完成,而MediaRecovery 需要DBA 手工的完成。
(2) Crash Recovery 使用online redo log,Media Recovery 使用archived log 和 online redo log。
(3) Media Recovery 可能还需要从备份中Restore datafile。
1.2 Crash Recovery 过程
当数据库突然崩溃,而还没有来得及将buffer cache里的脏数据块刷新到数据文件里,同时在实例崩溃时正在运行着的事务被突然中断,则事务为中间状态,也就是既没有提交也没有回滚。这时数据文件里的内容不能体现实例崩溃时的状态。这样关闭的数据库是不一致的。
下次启动实例时,Oracle会由SMON进程自动进行实例恢复。实例启动时,SMON进程会去检查控制文件中所记录的、每个在线的、可读写的数据文件的END SCN号。
数据库正常运行过程中,该END SCN号始终为NULL,而当数据库正常关闭时,会进行完全检查点,并将检查点SCN号更新该字段。
而崩溃时,Oracle还来不及更新该字段,则该字段仍然为NULL。当SMON进程发现该字段为空时,就知道实例在上次没有正常关闭,于是由SMON进程就开始进行实例恢复了。
1.2.1 前滚
SMON进程进行实例恢复时,会从控制文件中获得检查点位置。于是,SMON进程到联机日志文件中,找到该检查点位置,然后从该检查点位置开始往下,应用所有的重做条目,从而在buffer cache里又恢复了实例崩溃那个时间点的状态。这个过程叫做前滚,前滚完毕以后,buffer cache里既有崩溃时已经提交还没有写入数据文件的脏数据块,也还有事务被突然终止,而导致的既没有提交又没有回滚的事务所弄脏的数据块。
1.2.2 回滚
前滚一旦完毕,SMON进程立即打开数据库。但是,这时的数据库中还含有那些中间状态的、既没有提交又没有回滚的脏块,这种脏块是不能存在于数据库中的,因为它们并没有被提交,必须被回滚。打开数据库以后,SMON进程会在后台进行回滚。
有时,数据库打开以后,SMON进程还没来得及回滚这些中间状态的数据块时,就有用户进程发出读取这些数据块的请求。这时,服务器进程在将这些块返回给用户之前,由服务器进程负责进行回滚,回滚完毕后,将数据块的内容返回给用户。
总之,Crash Recovery时,数据库打开会占用比正常关闭更长的时间。
1.2.3 必须先前滚,在回滚
回滚段实际上也是以回滚表空间的形式存在的,既然是表空间,那么肯定就有对应的数据文件,同时在buffer cache 中就会存在映像块,这一点和其他表空间的数据文件相同。
当发生DML操作时,既要生成REDO(针对DML操作本身的REDO Entry)也要生成UNDO(用于回滚该DML操作,记录在UNDO表空间中),但是既然UNDO信息也是使用回滚表空间来存放的,那么该DML操作对应的UNDO信息(在BUFFER CACHE生成对应中的UNDO BLOCK)就会首先生成其对应的REDO信息(UNDO BLOCK's REDO Entry)并写入Log Buffer中。
这样做的原因是因为Buffer Cache中的有关UNDO表空间的块也可能因为数据库故障而丢失,为了保障在下一次启动时能够顺利进行回滚,首先就必须使用REDO日志来恢复UNDO段(实际上是先回复Buffer Cache中的脏数据块,然后由Checkpoint写入UNDO段中),在数据库OPEN以后再使用UNDO信息来进行回滚,达到一致性的目的。
生成完UNDO BLOCK's REDO Entry后才轮到该DML语句对应的REDO Entry,最后再修改Buffer Cache中的Block,该Block同时变为脏数据块。
实际上,简单点说REDO的作用就是记录所有的数据库更改,包括UNDO表空间在内。
1.2.4 Crash Recovery 再细分
Crash Recovery 可以在细分成两种:
(1) 实例恢复(InstanceRecovery)
(2) 崩溃恢复(CrashRecovery)
InstanceRecovery与CrashRecovery是存在区别的:针对单实例(singleinstance)或者RAC中所有节点全部崩溃后的恢复,我们称之为Crash Recovery。 而对于RAC中的某一个节点失败,存活节点(surviving instance)试图对失败节点线程上redo做应用的情况,我们称之为InstanceRecovery。
不管是Instance Recovery还是Crash Recovery,都由2个部分组成:cache recovery和transaction recovery。
根据官方文档的介绍,Cache Recovery也叫Rolling Forward(前滚);而Transaction Recovery也叫Rolling Back(回滚)。
1.3 Redo log 说明
REDO LOG 的数据是按照THREAD 来组织的,对于单实例系统来说,只有一个THREAD,对于RAC 系统来说,可能存在多个THREAD,每个数据库实例拥有一组独立的REDO LOG 文件,拥有独立的LOG BUFFER,某个实例的变化会被独立的记录到一个THREAD 的REDO LOG 文件中。
对于单实例的系统,实例恢复(Instance Recovery)一般是在数据库实例异常故障后数据库重启时进行,当数据库执行了SHUTDOWN ABORT 或者由于操作系统、主机等原因宕机重启后,在ALTER DATABASE OPEN 的时候,就会自动做实例恢复。
在RAC 环境中,如果某个实例宕了,或者实例将会接管,替宕掉的实例做实例恢复。除非是所有的实例都宕了,这样的话,第一个执行ALTER DATABASE OPEN 的实例将会做实例恢复。这也是REDO LOG 是实例私有的组件,但是REDO LOG 文件必须存放在共享存储上的原因。
Oracle 数据库的CACHE 机制是以性能为导向的,CACHE 机制应该最大限度的提高数据库的性能,因此CACHE 被写入数据文件总是尽可能的推迟。这种机制大大提高了数据库的性能,但是当实例出现故障时,可能出现一些问题。
首先是在实例故障时,可能某些事物对数据文件的修改并没有完全写入磁盘,可能磁盘文件中丢失了某些已经提交事务对数据文件的修改信息。
其次是可能某些还没有提交的事务对数据文件的修改已经被写入磁盘文件了。也有可能某个原子变更的部分数据已经被写入文件,而部分数据还没有被写入磁盘文件。
实例恢复就是要通过ONLINE REDO LOG 文件中记录的信息,自动的完成上述数据的修复工作。这个过程是完全自动的,不需要人工干预。
1.3.1 如何确保已经提交的事务不会丢失?
解决这个问题比较简单,Oracle 有一个机制,叫做Log-Force-at-Commit,就是说,在事务提交的时候,和这个事务相关的REDO LOG 数据,包括COMMIT 记录,都必须从LOG BUFFER 中写入REDO LOG 文件,此时事务提交成功的信号才能发送给用户进程。通过这个机制,可以确保哪怕这个已经提交的事务中的部分BUFFER CACHE 还没有被写入数据文件,就发生了实例故障,在做实例恢复的时候,也可以通过REDO LOG 的信息,将不一致的数据前滚。
1.3.2 如何在数据库性能和实例恢复所需要的时间上做出平衡?
既确保数据库性能不会下降,又保证实例恢复的快速,解决这个问题,oracle是通过checkpoint 机制来实现的。
Oracle 数据库中,对BUFFER CAHCE 的修改操作是前台进程完成的,但是前台进程只负责将数据块从数据文件中读到BUFFERCACHE 中,不负责BUFFERCACHE 写入数据文件。BUFFERCACHE 写入数据文件的操作是由后台进程DBWR 来完成的。DBWR 可以根据系统的负载情况以及数据块是否被其他进程使用来将一部分数据块回写到数据文件中。这种机制下,某个数据块被写回文件的时间可能具有一定的随机性的,有些先修改的数据块可能比较晚才被写入数据文件。
而CHECKPOINT 机制就是对这个机制的一个有效的补充,CHECKPOINT 发生的时候,CKPT 进程会要求DBWR 进程将某个SCN 以前的所有被修改的块都被写回数据文件。这样一旦这次CHECKPOINT 完成后,这个SCN 前的所有数据变更都已经存盘,如果之后发生了实例故障,那么做实例恢复的时候,只需要冲这次CHECKPOINT 已经完成后的变化量开始就行了,CHECKPOINT 之前的变化就不需要再去考虑了。
1.3.3 有没有可能数据文件中的变化已经写盘,但是REDO LOG 信息还在LOG BUFFER 中,没有写入REDO LOG 呢?
这里引入一个名词:Write-Ahead-Log,就是日志写入优先。日志写入优先包含两方面的算法:
第一个方面是,当某个BUFFER CACHE 的修改的变化矢量还没有写入REDO LOG 文件之前,这个修改后的BUFFER CACHE 的数据不允许被写入数据文件,这样就确保了再数据文件中不可能包含未在REDO LOG 文件中记录的变化;
第二个方面是,当对某个数据的UNDO 信息的变化矢量没有被写入REDOLOG 之前,这个BUFFERCACHE的修改不能被写入数据文件。
二.LOG BUFFER 和LGWR
2.1 Redo Log 说明
REDO LOG是顺序写的文件,每次写入的数据量很小,TEMP文件虽然也就有部分顺序读写的特点,但是TEMP每次读写的数据量较大,和REDO 的特性不同。UNDO是典型的随机读写的文件,索引更是以单块读为主的操作。
REDO LOG 的产生十分频繁,几乎每秒钟都有几百K 到几M 的RED LOG 产生,甚至某些大型数据库每秒钟产生的REDO LOG 量达到了10M 以上。不过前台进程每次产生的REDO量却不大,一般在几百字节到几K,而一般一个事务产生的REDO 量也不过几K到几十K。
基于REDO 产生的这个特点,如果每次REDO产生后就必须写入REDOLOG 文件,那么就会存在两个问题,一个是REDO LOG 文件写入的频率过高,会导致REDO LOG文件的IO 存在问题,第二个是如果由前台进程来完成REDO LOG 的写入,那么会导致大量并发的前台进程产生REDO LOG 文件的争用。
为了解决这两个问题,Oracle 在REDO LOG 机制中引入了LGWR 后台进程和LOGBUFFER。
LOG BUFFER 是Oracle 用来缓存前台进程产生的REDO LOG 信息的,有了LOG BUFFER,前台进程就可以将产生的REDO LOG 信息写入LOG BUFFER,而不需要直接写入REDO LOG 文件,这样就大大提高了REDO LOG 产生和保存的时间,从而提高数据库在高并发情况下的性能。既然前台进程不将REDOLOG 信息写入REDO LOG 文件了,那么就必须要有一个后台进程来完成这个工作。这个后台进程就是LGWR,LGWR 进程的主要工作就是将LOG BUFFER 中的数据批量写入到REDO LOG 文件中。对于Oracle 数据库中,只要对数据库的改变写入到REDO LOG 文件中了,那么就可以确保相关的事务不会丢失了。
引入LOG BUFFER 后,提高了整个数据库RDMBS 写日志的性能,但是如何确保一个已经提交的事务确确实实的被保存在数据库中,不会因为之后数据库发生故障而丢失呢?实际上在前面两节中我们介绍的REDO LOG 的一些基本的算法确保了这一点。
首先WRITE AHEAD LOG 协议确保了只要保存到REDO LOG 文件中的数据库变化一定能够被重演,不会丢失,也不会产生二义性。其次是在事务提交的时候,会产生一个COMMIT 的CV,这个CV 被写入LOG BUFFER 后,前台进程会发出一个信号,要求LGWR 将和这个事务相关的REDO LOG 信息写入到REDO LOG 文件中,只有这个事务相关的REDO LOG 信息已经确确实实被写入REDO LOG 文件的时候,前台进程才会向客户端发出事务提交成功的消息,这样一个事务才算是被提交完成了。在这个协议下,只要客户端收到了提交完成的消息,那么可以确保,该事务已经存盘,不会丢失了。
LGWR 会绕过操作系统的缓冲,直接写入数据文件中,以确保REDO LOG 的信息不会因为操作系统出现故障(比如宕机)而丢失要求确保写入REDO LOG 文件的数据。
实际上,虽然Oracle 数据库使用了绕过缓冲直接写REDO LOG 文件的方法,以避免操作系统故障导致的数据丢失,不过我们还是无法确保这些数据已经确确实实被写到了物理磁盘上。因为我们RDBMS 使用的绝大多数存储系统都是带有写缓冲的,写缓冲可以有效的提高存储系统写性能,不过也带来了另外的一个问题,就是说一旦存储出现故障,可能会导致REDO LOG 的信息丢失,甚至导致REDO LOG 出现严重损坏。存储故障的概率较小,不过这种小概率事件一旦发生还是会导致一些数据库事务的丢失,因此虽然Oracle 的内部算法可以确保一旦事务提交成功,事务就确认被保存完毕了,不过还是可能出现提交成功的事务丢失的现象。
实际上,Oracle 在设计REDO LOG 文件的时候,已经最大限度的考虑了REDO LOG 文件的安全性,REDO LOG 文件的BLOCK SIZE 和数据库的BLOCK SIZE 是完全不同的,REDO LOG 文件的BLOCK SIZE 是和操作系统的IO BLOCK SZIE 完全相同的,这种设计确保了一个REDO LOG BLOCK 是在一次物理IO 中同时写入的,因此REDOLOG BLOCK 不会出现块断裂的现象。
2.2 LOG BUFFER 说明
2.2.1 Log Buffer 说明
--官网的说明:
The redolog buffer is a circular buffer in the SGA that stores redo entriesdescribing changes made to the database. Redo entries contain theinformation necessary to reconstruct, or redo, changes made to the database byDML or DDL operations. Database recovery applies redo entries to data files toreconstruct lost changes.
Oracle Databaseprocesses copy redo entriesfrom the user memory space to the redo log buffer in the SGA. The redo entriestake up continuous, sequential space in the buffer. The background process logwriter (LGWR) writes the redo log buffer to the active online redo loggroup on disk. Figure14-8 shows this redo buffer activity.
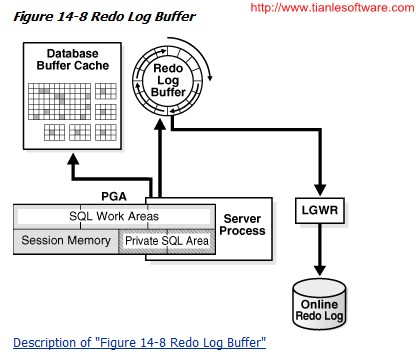
LGWR writes redosequentially to disk while DBWn performs scattered writes of data blocksto disk. Scattered writes tend to be much slower than sequential writes.Because LGWR enable users to avoid waiting for DBWn to complete its slowwrites, the database delivers better performance.
The LOG_BUFFER initializationparameter specifies the amount of memory that Oracle Database uses whenbuffering redo entries. Unlike other SGA components, the redo log buffer andfixed SGA buffer do not divide memory into granules.
--MOS: [ID 147471.1]
The redo logbuffer is a circular buffer in the SGA that holds information about changesmade to the database. This information is stored in redo entries. Redo entriescontain the information necessary to reconstruct, or redo changes made to thedatabase . Redo entries are used for database recovery, if necessary.
Redo entries arecopied by Oracle server processes from the user's memory space to the redo logbuffer in the SGA. The redo entries take up continuous, sequential space in thebuffer. The background process LGWR writes the redo log buffer to the activeonline redo log file (or group of files) on disk.
The initialization parameter LOG_BUFFER determines the size (in bytes) of the redolog buffer. In general, larger values reduce log file I/O, particularly iftransactions are long or numerous. The default setting is four times themaximum data block size for the host operating system prior to 8i and 512k or128k x cpu_count whichever is greater, from 8i onwards.
-- MOS: [ID 147471.1] Redolog Latches
Whena change to a data block needs to be done, it requires to create a redo recordin the redolog buffer executing the following steps:
(1) Ensure that no other processeshas generated a higher SCN
(2) Find for space available towrite the redo record. If there is no space available then the LGWR must writeto disk or issue a log switch
(3) Allocate the space needed inthe redo log buffer
(4) Copy the redo record to the logbuffer and link it to the appropriate structures for recovery purposes.
The database has threeredo latches to handle this process:
(1)Redo Copy latch
The redocopy latch is acquired for the whole duration of the process describedabove. The init.ora LOG_SIMULTANEOUS_COPIES determines the number of redo copylatches. It is only released when a log switch is generated to release freespace and re-acquired once the log switch ends.
(2)Redo allocation latch
The redoallocation latch is acquired to allocate memory space in the log buffer. BeforeOracle9.2, the redo allocation latch is unique and thus serializes the writingof entries to the log buffer cache of the SGA. In Oracle 9.2. EntrepriseEdition, the number of redo allocation latches is determined by init.oraLOG_PARALLELISM. The redo allocation latch allocates space in the logbuffer cache for each transaction entry. If transactions are small, or ifthere is only one CPU on the server, then the redo allocation latch also copiesthe transaction data into the log buffer cache. If a log switch is needed toget free space this latch is released as well with the redo copy latch.
(3)Redo writing latch
This uniquelatch prevent multiple processes posting the LGWR process requesting logswitch simultaneously. A process that needs free space must acquire the latchbefore of deciding whether to post the LGWR to perform a write, execute a logswitch or just wait.
-- MOS: [ID 147471.1]
Instance ParametersRelated with the Redolog Latches
In Oracle7 andOracle 8.0, there are two parameters that modify the behavior of the latchallocation in the redolog buffer: LOG_SIMULTANEOUS_COPIES (This parametercontrols the number of redo copy latches when the system has morethan one CPU), and LOG_SMALL_ENTRY_MAX_SIZE. When LOG_SIMULTANEOUS_COPIESis set to a non-zero value, and the size of the transaction entry is smallerthan the value of the LOG_SMALL_ENTRY_MAX_SIZE parameter then the copy of thetransaction entry into the log buffer cache is performed by the redoallocation latch. If the size of the transaction entry exceedsLOG_SMALL_ENTRY_MAX_SIZE, then the transaction entry is copied into the logbuffer cache by the redo copy latch.
In Oracle8i andOracle9.0, a redo copy latch is always required regardless of the redo size sothe check is no longer performed. The init.ora LOG_SIMULTANEOUS_COPIES becomesobsolete and the number of redo copy latches defaults to twice the number ofcpus. The parameter LOG_SMALL_ENTRY_MAX_SIZE is also obsolete. For furtherdetail on the change of this parameters in Oracle 8i seeNote:94271.1
In Oracle9.2 andhigher, multiple redo allocation latches become possible with init.oraLOG_PARALLELISM. The log buffer is split in multiple LOG_PARALLELISM areas thateach have a size of init.ora LOG_BUFFER. The allocation job of each area isprotected by a specific redo allocation latch. The number of redo copy latchesis still determined by the number of cpus
LOG BUFFER 是SGA中一块循环使用的内存区域,它一般很小.
在Oracle 10g之前,LOG BUFFER参数的默认设置为Max(512 KB,128 KB * CPU_COUNT),按照默认设置,LOG_BUFFER消耗的内存都不会太高,而由于LGWR对Log Buffer内容的写出非常频繁,所以很小的Log Buffer也可以工作得很好,根据经验,有很多对Log Buffer的指导性设置,比如经常提到的3MB大小,但是在Oracle10g中,Redo Log Buffer默认的已经大大超过了原来的想象。
这和Oracle 9i引入了Granule的概念有关,在动态SGA管理中,Granule是最小的内存分配单元,其大小与SGA及操作系统平台有关。
在10g中ORACLE会自动调整它的值,他遵循这样一个原则,'Fixed SGA Size'+ 'Redo Buffers'是granule size 的整数倍(如果是一倍,那么他们的比值可能为0.999...如果是2倍,那么他们的比值可能是1.999...)。
一般的granule value 为4194304 ,也就是4M, 而fixed size 一般为 1.2M,这个值不确定,也不精确,根据不同的平台有所差异,而默认的log_buffer+fixedsize 的大小为 granulesize 的整数倍,所以默认的情况下你看见的log_buffer大小约为6.67m或者为2.7M。
所以如果我们手动的设置log_buffer的值,那么ORACLE会将它加上fixedsize 然后除以granule ,得到一个值,然后四舍五入,看最接近哪个整数,然后就取最接近的那个值。
SQL> select * from v$version whererownum <2;
BANNER
----------------------------------------------------------------
Oracle Database 10g Enterprise EditionRelease 10.2.0.4.0 - Prod
SQL> select * from v$sgainfo where namein ('Fixed SGA Size','Redo Buffers','Granule Size');
NAME BYTES RES
-------------------------------- -------------
Fixed SGA Size 1270508 No
Redo Buffers 2920448 No
Granule Size 4194304 No
SQL> select sum(bytes)/1024/1024 fromv$sgainfo where name in ('Fixed SGA Size','Redo Buffers');
SUM(BYTES)/1024/1024
--------------------
3.9968071
--查看'FixedSGA Size' + 'Redo Buffers' 与 Granule Size的比值:
SQL> select 3.9968071/4 from dual;
3.9968071/4
-----------
.999201775
这里验证了我们前面的说法:'Fixed SGA Size' + 'Redo Buffers' 是Granule Size 整数倍。
2.2.2 Log Buffer 中的Latch
由于log buffer是一块“共享”内存,为了避免冲突,它是受到redo allocation latch保护的,每个服务进程需要先获取到该latch才能分配redobuffer。因此在高并发且数据修改频繁的oltp系统中,我们通常可以观察到redoallocation latch的等待。
为了减少redo allocation latch等待,在oracle 9.2中,引入了log buffer的并行机制。其基本原理就是,将log buffer划分为多个小的buffer,这些小的buffer被成为Shared Strand。每一个strand受到一个单独redo allocation latch的保护。多个shared strand的出现,使原来序列化的redo buffer分配变成了并行的过程,从而减少了redo allocationlatch等待。
为了进一步降低redo buffer冲突,在10g中引入了新的strand机制——Private strand。Private strand不是从log buffer中划分的,而是在shared pool中分配的一块内存空间。
Private strand的引入为Oracle的Redo/Undo机制带来很大的变化。每一个Private strand受到一个单独的redo allocation latch保护,每个Private strand作为“私有的”strand只会服务于一个活动事务。获取到了Private strand的用户事务不是在PGA中而是在Private strand生成Redo,当flush private strand或者commit时,Privatestrand被批量写入log文件中。如果新事务申请不到Private strand的redo allocation latch,则会继续遵循旧的redo buffer机制,申请写入shared strand中。事务是否使用Private strand,可以由x$ktcxb的字段ktcxbflg的新增的第13位鉴定。
对于使用Private strand的事务,无需先申请Redo Copy Latch,也无需申请Shared Strand的redo allocation latch,而是flush或commit是批量写入磁盘,因此减少了Redo Copy Latch和redo allocation latch申请/释放次数、也减少了这些latch的等待,从而降低了CPU的负荷。
2.2.3 Log Buffer 大小问题
一般默认情况下的log_buffer的大小够用了,查看Log_buffer是否需要调整,可以查看数据库是否有大量的log buffer space等待事件出现。redo log 最开始是在pga中的uga产生的(数据库一般是专有模式),oracle会把它拷贝到SGA中的log_buffer中去,如果log_buffer过小,或者lgwr不能够快速将redo 写入到log file中,那么就会产生log buffer space等待事件,遇到此类问题,可以增加 log_buffer大小,调整log file 到裸设备,I/0快的磁盘中。
MOS有两篇相关的文章:
(1)Oracle Calculation of Log_Buffer Size in 10g [ID604351.1]
A big difference can be seen between 10.2.0.3 and 10.2.0.4 when usingthe same system configuration (in terms of the application and its dbobjects and datafiles, ram size, number of CPUs etc). In 10.2.0.3 it was set byOracle to 14M and now in 10.2.0.4 to 15M.
--在10.2.0.3 中Log Buffer 默认值是14M,在10.2.0.4中,默认值是15M。
The LOG_BUFFERsize will be set by default, by Oracle internal algorithm.
In 10G R2,Oracle combines fixed SGA area and redo buffer [log buffer] together.
(2)Tuning the Redolog Buffer Cache and Resolving RedoLatch Contention [ID 147471.1]
相关内容出处链接:
http://blog.csdn.net/tianlesoftware/article/details/5594080
2.3 LOG BUFFER 和LGWR 的算法
了解LOG BUFFER 和LGWR 的算法,有助于我们分析和解决相关的性能问题,因此我们需要花一点时间来了解LOG BUFFER 相关的基本算法。用一句话来概括,LOG BUFFER是一个循环使用的顺序型BUFFER。这句话里包含了两个含义,一个是LOG BUFFER 是一个顺序读写的BUFFER,LOG BUFFER 数据的写入是顺序的;第二个含义是LOG BUFFER是一个循环BUFFER,当LOG BUFFER 写满后,会回到头上来继续写入REDO LOG 信息。
LOG BUFFER 数据的写入是由前台进程完成的,这个写入操作是并发的,每个前台进程在生成了REDOLOG 信息后,需要首先在LOGBUFFER 中分配空间,然后将REDOLOG 信息写入到LOGBUFFER 中去。在LOG BUFFER中分配空间是一个串行的操作,因此Oracle 在设计这方面的算法的时候,把LOG BUFFER 空间分配和将REDO LOG 数据拷贝到LOG BUFFER 中这两个操作分离了,一旦分配了LOG BUFFER 空间,就可以释放相关的闩锁,其他前台进程就可以继续分配空间了(这里所说的前台进程只是一个泛指,是为了表述方便而已,读者一定要注意,因为后台进程也会对数据库进行修改,也需要产生REDO LOG 信息,后台进程的REDO 操作和前台进程是大体一致的)。
前台进程写入REDO 信息会使LOG BUFFER的尾部指针不停的向前推进,而LGWR这个后台进程不听的从LOG BUFFER 的头部指针处开始查找还未写入REDO LOG 文件的LOG BUFFER 信息,并将这些信息写入REDO LOG 文件中,并且将BUFFER 头部指针不停的向后推进,一旦LOG BUFFER 的头部指针和尾部指针重合,那么就说嘛了当前的LOG BUFFER 是空的。
而如果前台进程在LOG BUFFER 中分配空间会使LOG BUFFER 的尾部指针一直向前推进,一旦LOG BUFFER 的尾部指针追上了LOG BUFFER 的头部指针,那么说明目前LOG BUFFER 中无法分配新的空间给后台进程了,后台进程必须要等候LGWR将这些数据写入REDOLOG 文件,然后向前推进了头部指针,才可能再次获得新的可用BUFFER 空间。这个时候,前台进程会等待LOG FILE SYNC 事件。
为了让LGWR 尽快将LOG BUFFER 中的数据写入REDO LOG 文件,以便于腾出更多的空闲空间,Oracle 数据库设计了LGWR 写的触发条件:
1. 用户提交
2. 有1/3重做日志缓冲区未被写入磁盘
3. 有大于1M的重做日志缓冲区未被写入磁盘
4. 每隔3 秒钟
5. DBWR 需要写入的数据的SCN大于LGWR记录的SCN,DBWR 触发LGWR写入。
当事务提交时,会产生一个提交的REDO RECORD,这个RECORD 写入LOG BUFFER 后,前台进程会触发LGWR 写操作,这个时候前台进程就会等待LOG FILE SYNC 等待,直到LGWR 将相关的数据写入REDOLOG 文件,这个等待就会结束,前台进程就会收到提交成功的消息。如果我们的系统中,每秒的事务数量较大,比如几十个或者几百个,甚至大型OLTP 系统可能会达到每秒数千个事务。在这种系统中,LGWR由于事务提交而被激发的频率很高,LOG BUFFER 的信息会被很快的写入REDO LOG 文件中。
而对于某些系统来说,平均每个事务的大小很大,平均每个事务生成的REDO LOG 数据量也很大,比如1M 甚至更高,平均每秒钟的事务数很少,比如1-2 个甚至小于一个,那么这种系统中LGWR 由于事务提交而被激发的频率很低,可能导致REDO LOG 信息在LOG BUFFER 中被大量积压,oracle 设计的LOG BUFFER 中数据超过1M 的LGWR 激发条件就是为了解决这种情况而设计的,当LOG BUFFER 中的积压数据很多时,虽然没有事务提交,也会触发LGWR 将BUFFER 中的数据写入REDO LOG 文件。
除此之外,Oracle 还通过了_LOG_IO_SIZE 这个隐含参数来进一步控制LGWR 写操作,当LOGBUFFER 中的数据超过了这个隐含参数的规定的大小,也会触发LGWR 被激发。这个参数的缺省值是LOGBUFFER 大小的1/3,这个参数单位是REDO LOG BLOCK。这个参数可以控制当LOG BUFFER 中有多少个数据块被占用时,就要触发LGWR 写操作,从而避免LOG BUFFER 被用尽。
如果一个系统很空闲,很长时间都没有事务提交,LOG BUFFER 的使用也很少,就可能会导致LOG BUFFER 中的数据长期没有被写入REDO LOG 文件,带来丢失数据的风险,因此Oracle 还设计了一个LGWR 写的激发控件,设置了一个时间触发器,每隔的尾部已经追上了LOG BUFFER 的头部,那么前台进程就要等待LGWR 进程将头部的数据写入REDOLOG 文件,然后释放LOGBUFFER 空间。这个时候,没有做提交操作的前台进程都会等待LOG FILE SYNC 事件。这种情况下,加大LOG BUFFER 就可能可以减少大部分的LOG FILE SYNC 等待了。
加大LOG BUFFER 的大小,可能会带来另外一个问题,比如LOG BUFFER 从1M 增加到30M(关于LOG BUFFER 是否需要大于3M 的问题,以前我们已经多次讨论,因此在这里不再讨论了,大家只需要记住一点就可以了,LOG BUFFER 大于3M 浪费空间,对性能影响不大的观点是错误的),那么_LOG_IO_SIZE 自动会从300K 增加到10M,在一个平均每秒事务数较少,并且每个事务的REDO SIZE 较大的系统中,触发LGWR 写操作的LOG BUFFER 数据量会达到1M。
一般来说,在一个大型的OLTP 系统里,每次LGWR 写入REDO LOG 文件的大小在几K 到几十K 之间,平均LOG FILE SYNC 的时间在1-10 毫秒之间。如果平均每次写入的数据量过大,会导致LOG FILE SYNC 的等待时间变长。因此在这种情况下,就可能需要设置_LOG_IO_SIZE 参数,确保LOG FILE SYNC 等待不要过长。
如果每次写入REDO LOG 文件的数据量也不大,而LOG FILE SYNC 等待时间很吵,比如说超过100 毫秒,那么我们就要分析一下REDOLOG 文件的IO 性能了,如果REDO LOG 文件IO 性能不佳,或者该文件所在的IO 热点较大,也可能导致LOGFILE SYNC 等待时间偏大,这种情况,我们可以查看后台进程的LOG FILE PARALLEL WRITE 这个等待事件,这个等待事件一般的等待时间为几个毫秒,如果这个等待事件的平均等待时间较长,那么说明REDO LOG 文件的IO 性能不佳,需要将REDOLOG 文件放到IO 量较小,性能较快的磁盘上。
在OLTP 系统上,REDO LOG 文件的写操作主要是小型的,比较频繁,一般的写大小在几K,而每秒钟产生的写IO 次数会达到几十次,数百次甚至上千次。因此REDO LOG文件适合存放于IOPS 较高的转速较快的磁盘上,IOPS 仅能达到数百次的SATA 盘不适合存放REDO LOG 文件。另外由于REDO LOG 文件的写入是串行的,因此对于REDO LOG文件所做的底层条带化处理,对于REDO LOG 写性能的提升是十分有限的。
三.日志切换和REDO LOG 文件
当前台进程在LOG BUFFER 中分配空间的时候,实际上已经在REDO LOG 文件中预先分配了空间,如果REDO LOG 文件已经写满,无法再分配空间给前台进程的时候,就需要做一次日志切换,这个时候前台进程会想LGWR 发出一个日志切换的请求,然后等待log file switch completion 等待事件。
日志切换请求发出后,CKPT 进程会进行一次日志切换CHECKPOINT,而LGWR 开始进行日志切换工作。首先LGWR 进程会通过控制文件中的双向链表,查找到一个可用的REDO LOG 文件,作为新的CURRENT REDO LOG。 查找新的CURRENT REDO LOG 的算法是要求该日志是非ACTIVE 的,并且已经完成了归档(如果是归档模式),oracle 会优先使用unused 状态的REDO LOG 组作为CURRENT REDO LOG。
在做日志切换时,首先要将LOG BUFFER 中还没有写入REDO LOG 文件的REDO RECORD 写入当前的REDO LOG 文件,然后将最后一个REDO RECORD 的SCN 作为本日志文件的HIGHSCN 记录在REDO LOG 文件头中。这些操作完成后,就可以关闭当前日志了。
完成了上一个步骤,就需要进行第二次控制文件事务,将刚刚关闭的REDO LOG 标识为ACTIVE,将新的当前REDO LOG标识为CURRENT,如果数据库处于归档模式,还要将老的日志组记录到控制文件归档列表记录中(在V$ARCHIVE 试图中科看到),并且通知归档进程对该日志文件进行归档。当所有的归档进程都处于忙状态的时候,并且归档进程总数没有超过log_archive_max_processes 的情况下,LGWR 还会生成一个新的归档进程来对老的日志文件进行归档。
这些操作完成后,LGWR 打开新的日志组的所有成员,并在文件头中记录下初始化信息。
这些完成后,LGWR 修改SGA 中的标志位,允许生成新的REDO LOG 信息。老的日志组目前还被标志位ACTIVE,当DBWR 完成了CHECKPOINT 所要求的写批量操作后,该日志组的状态会被标识为inactive。
从上述日志切换的步骤我们可以看出,日志切换还是有很多工作要做的,而且在日志切换开始到结束之间,日志的生成是被完全禁止的,因此在这个期间,对数据库的修改操作会被全部阻塞。这也是我们经常提到的:“日志切换是一种较为昂贵的操作”。既然日志切换十分昂贵,对系统性能的影响较大,那么我们就应该想办法减少日志切换的数量,提高日志切换的速度。
减少日志切换的数量我们可以从两个方面去考虑,一方面是减少日志的产生量,一方面是加大日志文件的大小。
对于减少日志产生量,常规的办法不外乎使用NOLOGGING 操作,使用BULK 操作、使用DIRECTPATH WRITE 操作等。不过大家要注意在归档模式下合非归档模式下,这些NOLOGGING 操作的效果是不同的。
有些DBA 担心加大REDO LOG 文件后会增加数据丢失的机会。的确,REDO LOG 文件越大,一个REDO LOG 文件所包含的REDO RECORD 的数量就越多,一旦整个REDO LOG文件丢失或者损坏,可能丢失的数据量就会增加。
实际上,整个REDO LOG 丢失的可能性极小,最主要的可能性是REDO LOG 文件被误删。如果存储出现故障,导致了REDO LOG 文件损坏,那么受影响的肯定是所有的REDO LOG 文件,而不是某一个REDO LOG 文件,无论REDO LOG 信息是存在一个REDO LOG 文件中还是存在2 个REDO LOG 文件中,其结果是完全一样的。
剩下一种情况就是最常见的情况了,就是服务器突然宕机,我们可以来分析一下服务器宕机这种情况,REDO LOG 文件的大小不同可能造成的数据丢失是否会不同。
首先我们要了解一下服务器宕机时可能丢失的数据可能是哪些,如果是已经提交的数据,CHECKPOINT已经推进到的部分,是已经被写入数据文件了,这部分数据是无论如何都不会丢失的,REDO LOG 是用来恢复最后一次CHECKPOINT 到宕机前被写入REDO LOG 文件的那部分数据。
由于REDO LOG 文件的写入是顺序的,因此无论这部分数据被写入到一个文件还是多个文件,并不影响这部分数据的恢复。因此我们可以看出,REDO LOG 文件大小和服务器宕机丢失数据的数量是无关的。
通过前面的分析我们应该已经了解到,系统故障时只有当整个REDO LOG 文件损坏时,REDO LOG 文件的大小才可能与丢失的数据量有关。在绝大多数情况下,加大REDO LOG 文件的大小并不会增加数据丢失的机会。因此我们在考虑REDO LOG 文件大小的时候,基本上可以忽略这个数据丢失的多少的问题。
不过在某些情况下,我们在需要加大REDO LOG 文件大小的时候,要适当的考虑,一是存在DATA GUARD 的情况下,为了减少FAILOVER 时的数据丢失量,我们不宜将REDO LOG 文件设置的过大。另外在存在CDC 或者流复制下游捕获的环境下,也需要考虑REDO LOG 文件大小和捕获延时的关系问题。
很多DBA 都受过教育,就是REDO LOG 切换的时间应该尽可能的不低于10-20 分钟,如果日志切换间隔低于这个值,就要考虑加大REDO LOG 文件的大小。事实上,没有任何铁律,只要日志切换并没有对系统的性能和安全产生严重的影响.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号