
Oracle分析函数
先通过一个例子,直观的感受下分析函数的简洁方便:
create table CRISS_SALES ( DEPT_ID VARCHAR2(6), --部门号 SALE_DATE DATE, --销售日期 GOODS_TYPE VARCHAR2(4), --货物类型 SALE_CNT NUMBER(10) --销售数量 );
插入测试数据:
insert into CRISS_SALES values ('D01', TO_DATE('20140304', 'YYYYMMDD'), 'G00', 700); insert into CRISS_SALES values ('D02', TO_DATE('20140306', 'YYYYMMDD'), 'G00', 500); insert into CRISS_SALES values ('D01', TO_DATE('20140408', 'YYYYMMDD'), 'G01', 200); insert into CRISS_SALES values ('D02', TO_DATE('20140427', 'YYYYMMDD'), 'G01', 300); insert into CRISS_SALES values ('D01', TO_DATE('20140430', 'YYYYMMDD'), 'G03', 800); insert into CRISS_SALES values ('D02', TO_DATE('20140502', 'YYYYMMDD'), 'G03', 900); insert into CRISS_SALES values ('D01', TO_DATE('20140504', 'YYYYMMDD'), 'G02', 80); insert into CRISS_SALES values ('D02', TO_DATE('20140408', 'YYYYMMDD'), 'G02', 100);
需求:求出全公每个时点司累计的销售数量,利用分析函数SQL如下:
SELECT T.DEPT_ID , T.SALE_DATE , T.GOODS_TYPE , T.SALE_CNT, SUM(SALE_CNT) OVER(ORDER BY SALE_DATE ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) ALL_CMP_CNT FROM CRISS_SALES T
结果如下:
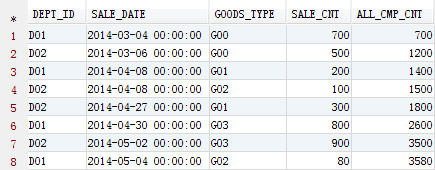
通过这个例子,可以看到利用分析函数解决某些场景下的问题非常的直观简便。
分析函数是什么?
分析函数是Oracle专门用于解决复杂报表统计需求的功能强大的函数,它可以在数据中进行分组然后计算基于组的某种统计值,并且每一组的每一行都可以返回一个统计值。
分析函数和聚合函数的不同之处是什么?
普通的聚合函数用group by分组,每个分组返回一个统计值,而分析函数采用partition by分组,并且每组每行都可以返回一个统计值。
分析函数的形式?
分析函数带有一个开窗函数over(),包含三个分析子句:分组(partition by), 排序(order by), 窗口(rows) ,他们的使用形式如下:over(partition by xxx order by yyy rows between zzz and qqq)。
分析函数适用于哪些场景?
1.表内数据聚合累加
2.表内分组累加
3.分组排名
4.滚动统计
5.范围求值SUM MAX MIN
6.相邻行比较
等等...
Oracle提供的分析函数有哪些?
===================================================================================================================
统计方面:
--统计全表 sum() over ([partition by ] [order by ]) --统计前n行到后m行 sum() over ([partition by ] [order by ] rows between n preceding and m following) --统计前n行到当前行 sum() over ([partition by ] [order by ] rows between n preceding and current row) --统计开始行到当前行 sum() over ([partition by ] [order by ] rows between unbounded preceding and current row) --统计开始行到当前行之后的第n行 sum() over ([partition by ] [order by ] rows between unbounded preceding and n following) --统计从首行累积到当前行 sum() over ([partition by ] [order by ] rows between unbounded preceding and current row)
其他的有兴趣可以自行实验下结果
有关排列或排名:
--非连续排名 rank() over ([partition by ] [order by ] [nulls first/last]) --连续排名 dense_rank() over ([patition by ] [order by ] [nulls first/last]) --排序行号 row_number() over ([partitionby ] [order by ] [nulls first/last]) --ntile是要把查询得到的结果平均分为几组,如果不平均则分给第一组 ntile() over ([partition by ] [order by ])
例如:
create table s_score ( s_id number(6), score number(4,2) ); insert into s_score values(001,98); insert into s_score values(002,66.5); insert into s_score values(003,99); insert into s_score values(004,98); insert into s_score values(005,98); insert into s_score values(006,80); select s_id ,score ,rank() over(order by score desc) rank ,dense_rank() over(order by score desc) dense_rank ,row_number() over(order by score desc) row_number from s_score; S_ID SCORE RANK DENSE_RANK ROW_NUMBER ------- ------ ---------- ---------- ---------- 3 99.00 1 1 1 1 98.00 2 2 2 4 98.00 2 2 3 5 98.00 2 2 4 6 80.00 5 3 5 2 66.50 6 4 6
最大值/最小值查找:
min()/max() keep (dense_rank first/last [partition by ] [order by ])
首记录/末记录查找:
first_value / last_value(sum() over ([patition by ] [order by ] rows between preceding and following ))
相邻记录之间比较 lead/lag:
lag(sum(), 1) over([patition by ] [order by ])

 浙公网安备 33010602011771号
浙公网安备 33010602011771号