【学习笔记】【字符串基础】Hash表、KMP、Trie树
 姑且算我更新结束了。
可能之后会修改或者添加一些题目。
姑且算我更新结束了。
可能之后会修改或者添加一些题目。
字符串基础
点击查看目录
Hash
基本概念
\(\mathtt{Hash}\) 是一种数据结构,用来快速定位想要查找的记录,采用函数映射的思想将记录存储位置与记录关键字联系,从而达到快速查找的效果。
简单来说,我们现在有一个电话簿:
初音ミク 120 0708 3139
洛天依 120 1207 1215
乐正绫 120 1404 1216
星尘 120 1508 1216
……
我们暴力枚举找“初音ミク”的电话时间复杂度显然是\(O(N)\)的,二叉树也达到了\(O(logN)\),但是利用\(Hash\)表,我们可以让“初音ミク”这个名字和她的电话号码联系起来,达到\(O(1)\)的效果。
这个联系叫做映射函数,基本形式为:\(f:key—>address\),
设置Hash函数
\(Hash\)函数的设计决定了\(Hash\)表的操作效率,先随便设计一个:
\(address(初音ミク)=ASCII(M)+ASCII(I)+ASCII(K)+ASCII(U)=77+73+75+85=310\)
显然这个函数设计的太失败了。
因为它浪费了大量的储存空间,但是用到的空间却很少,明明是大写首字母排序,却使用\(ASCII\)码还不如从'\(A\)'开始标号标到'\(Z\)',而且较大可能会造成 \(\mathtt{Hash}\) 碰撞。
当然我们有一个更好的设计:我们设计一个 \(26\) 进制数表示 \(26\) 个字母,再转为 \(10\) 进制。
这种设计叫做进制哈希,是最简单较常见的。
Hash碰撞
简单来说,就是存在了 \(key_1 \neq key_2\),但是 \(address(key_1)=address(key_2)\) 的情况。
哈希碰撞不可避免,如同查词典,\(key\)是 我查询的页码,\(address\) 是我想得到的词,“蚌埠住了”和“绷不住了”大抵是在同一页上的,你除非给每一个词都单独开一页,要不然肯定有多个词在一个页码的情况。
因此我们的目标就是将 \(\mathtt{Hash}\) 碰撞的影响缩小,概率缩小,通过设计一个优秀的函数来实现。
好的Hash函数应该有这样的特点:
1.尽可能使得 \(key\) 平均分配在 \(\mathtt{Hash}\) 表中。
2.关键字较小的变化可以造成 \(\mathtt{Hash}\) 值较大的变化。
常用的 \(base\) 与模数
我们通过一些质数来设计一个映射,如 \(233\)、\(19491001\)、\(13331\)、\(999983\) 等。
但是有一种算法叫 \(\mathtt{time33}\) 算法,没懂。
解决哈希碰撞
1.开发定址法
就是有冲突就放到空的地方,不要跟添购一样。
“你就围着她转吧!饭也别吃了,觉也别睡了,你就围着她转吧!”

示例代码
namespace MikuHash{
const int base1=1e9+7,base2=233,Mod=999983,maxh=1e6+5;
il ll MyMod(ll x){ return x<Mod?x:x-Mod; }
PII map[maxh];bool exist[maxh];
il void Hash_clear(){ memset(map,0,sizeof(map));memset(exist,0,sizeof(exist)); }
il int trans(PII p){
if(p.first>p.second) std::swap(p.first,p.second);
int hsh=MyMod(1ll*p.first*base1%Mod+1ll*p.second*base2%Mod);
while(exist[hsh] && map[hsh]!=p) hsh=MyMod(hsh+1);
exist[hsh]=true;map[hsh]=p;
return hsh;
}
}using namespace MikuHash;
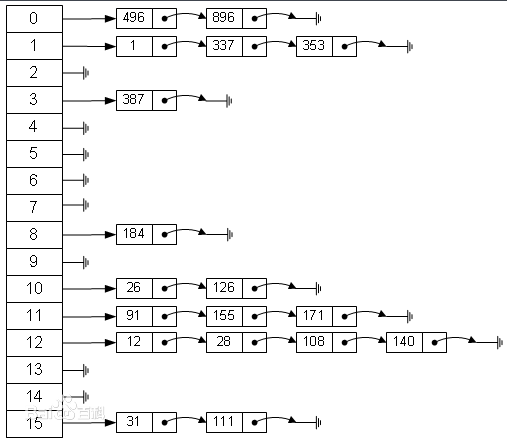
2.链定址法
那我们万一没有剩余的空间呢?
还记得词典吧,我们一页上多写几个词排列不就好了?
这就是链定址法,在原地址新创建一个空间,然后以链表节点的形式插入。
(下图来自百度)
典型例题
【模板】字符串哈希
题目描述
如题,给定 \(N\) 个字符串(第 \(i\) 个字符串长度为 \(M_i\),字符串内包含数字、大小写字母,大小写敏感),请求出 \(N\) 个字符串中共有多少个不同的字符串。
友情提醒:如果真的想好好练习哈希的话,请自觉。
输入格式
第一行包含一个整数 \(N\),为字符串的个数。
接下来 \(N\) 行每行包含一个字符串,为所提供的字符串。
输出格式
输出包含一行,包含一个整数,为不同的字符串个数。
样例 #1
样例输入 #1
5
abc
aaaa
abc
abcc
12345
样例输出 #1
4
提示
对于 \(30\%\) 的数据:\(N\leq 10\),\(M_i≈6\),\(Mmax\leq 15\)。
对于 \(70\%\) 的数据:\(N\leq 1000\),\(M_i≈100\),\(Mmax\leq 150\)。
对于 \(100\%\) 的数据:\(N\leq 10000\),\(M_i≈1000\),\(Mmax\leq 1500\)。
样例说明:
样例中第一个字符串(abc)和第三个字符串(abc)是一样的,所以所提供字符串的集合为{aaaa,abc,abcc,12345},故共计4个不同的字符串。
Tip:
感兴趣的话,你们可以先看一看以下三题:
BZOJ3097:http://www.lydsy.com/JudgeOnline/problem.php?id=3097
BZOJ3098:http://www.lydsy.com/JudgeOnline/problem.php?id=3098
BZOJ3099:http://www.lydsy.com/JudgeOnline/problem.php?id=3099
如果你仔细研究过了(或者至少仔细看过AC人数的话),我想你一定会明白字符串哈希的正确姿势的_
(ps:上面一直在讲思想,利用这个模板题把代码说一说吧)
进制哈希
#include<bits/stdc++.h>
using namespace std;
typedef unsigned long long intx;
const int base=131;
//131是一个可以使hash值分散的值,类似time33
intx a[10010];
char s[10010];
int n,ans=1;
int prime=233317;
//加上一个质数,可以降低hash的可能
intx mod=212370440130137957ll;
intx hashe(char s[]){ //得到字符串的hash值
int len=strlen(s);
intx ans=0;
for (int i=0;i<len;i++)
ans=(ans*base+(intx)s[i])%mod+prime;
return ans;
}
int main(){
scanf("%d",&n);
for(int i=1;i<=n;i++){
scanf("%s",s);
a[i]=hashe(s);
}
sort(a+1,a+n+1);
for(int i=1;i<n;i++){
if(a[i]!=a[i+1])
ans++;
}
printf("%d",ans);
}
[NOI2017] 蚯蚓排队
链定址会就能做。
题意概括
给出 \(n\) 个数字可以排列成数字串,通过 \(1\) 和 \(2\) 操作,要求排列成数字串之后再给出一个长度至少为 \(k\) 的数字串,问对于这个数字串中长度为 \(k\) 的子串,在所有数字串中与其相等的个数并相乘。
操作处理
- 合并数字串。
我们设两个数组记录一个蚯蚓的前一蚯蚓和后一蚯蚓,然后将这个串超过合并位置的都放入链表即可。
- 断开数字串
同上,我们将这个串超过断开位置的都在链表中删去即可。
- 查询
利用链表,判断原值是否相同,如果相同,证明存在这样的子串。
Code
Miku's Code
#include<bits/stdc++.h>
using namespace std;
inline int read(){
char c=getchar();
int x=0,f=1;
while(c<48){if(c=='-')f=-1;c=getchar();}
while(c>47)x=(x*10)+(c^48),c=getchar();
return x*f;
}
typedef long long intx;
const int maxn=2e5+50,maxm=5e5+50,maxk=100,maxs=1e7+50;
const int mod=998244353;
const intx p=17,mm=19491001;
int n,m,ewl[maxn];
intx pp[maxk],p10[maxk],vcnt[maxk];
char ns[maxs];
int nlen;
int to[maxn],tp[maxn]; //to[i],tp[i]分别表示i的后一个和前一个
int s1[maxk],s2[maxk]; //s1是x之前的数字串,s2是y之后的数字串
int t=0,head[mm+50];
struct edge{
int next_,cnt;
intx w;
};edge e[mm+50];
void input(){
n=read(),m=read();
for(int i=1;i<=n;i++){
ewl[i]=read();
vcnt[ewl[i]]++;
}
pp[0]=p10[0]=1;
for(int i=1;i<=99;++i){
pp[i]=pp[i-1]*p%mm;
p10[i]=p10[i-1]*10;
}
}
void add(intx hash,intx q){
//哈希表,如果对于hash这个值有q这个原值则++cnt,否则新开一点
for(int i=head[hash];i;i=e[i].next_){
if(e[i].w==q){
e[i].cnt++;
return;
}
}
e[++t].cnt=1;
e[t].w=q;
e[t].next_=head[hash];
head[hash]=t;
}
void delet(intx hash,intx q){
//删边肯定有这个边啊,--cnt就可以了
for(int i=head[hash];i;i=e[i].next_){
if(e[i].w==q){
e[i].cnt--;
return;
}
}
}
int query(intx hash,intx q){
for(int i=head[hash];i;i=e[i].next_){
if(e[i].w==q){
return e[i].cnt;
}
}
return 0;
}
void merge(int x,int y){
//把x之前的hash取出来,在后面加上y的hash
int l1=0,l2=0;
intx hsh=0,q=0,hxh=0,qx=0;
to[x]=y;
tp[y]=x;
for(int i=x;i && l1<49;i=tp[i]){
s1[++l1]=ewl[i];
hsh=(hsh+ewl[i]*pp[l1-1])%mm;
q=q+ewl[i]*p10[l1-1];
//将x与x之前的串(最长50)倒序取出,s1是倒叙的,hsh是正序的
}
for(int i=y;i && l2<49; i=to[i]) s2[++l2]=ewl[i];
//将y与y之后的串(最长50)正序取出
for(int i=l1;i>=1;i--){
//倒序取出的串倒叙枚举
hxh=0;qx=0;
for(int j=1;j<=l2 && i+j<=50;j++){
hxh=(hxh*p+s2[j])%mm;
qx=qx*10+s2[j];
add((hsh*pp[j]%mm+hxh)%mm,q*p10[j]+qx);
}
hsh=((hsh-pp[i-1]*s1[i])%mm+mm)%mm;
q=q-p10[i-1]*s1[i];
}
}
void separate(int x,int y){
//同merge
int l1=0,l2=0;
intx hsh=0,q=0,hxh=0,qx=0;
to[x]=0;
tp[y]=0;
for(int i=x;i && l1<49;i=tp[i]){
s1[++l1]=ewl[i];
hsh=(hsh+ewl[i]*pp[l1-1])%mm;
q=q+ewl[i]*p10[l1-1];
}
for(int i=y;i && l2<49;i=to[i]){
s2[++l2]=ewl[i];
}
for(int i=l1;i>=1;i--){
hxh=0,qx=0;
for(int j=1;j<=l2 && i+j<=50;++j){
hxh=(hxh*p+s2[j])%mm;
qx=qx*10+s2[j];
delet((hsh*pp[j]%mm+hxh)%mm,q*p10[j]+qx);
}
hsh=((hsh-pp[i-1]*s1[i])%mm+mm)%mm;
q=q-p10[i-1]*s1[i];
}
}
void work3(int x){
intx hsh=0,q=0,ans=1;
if(x==1){
//询问长度为1的串,在读入的时候我们开了一个桶vcnt统计答案
for(int i=1;i<=nlen;i++) ans=ans*vcnt[ns[i]-'0']%mod;
printf("%lld\n",ans%mod);
return;
}
for(int i=1;i<=x;i++){
hsh=(hsh*p+ns[i]-'0')%mm;
q=q*10+(ns[i]-'0');
}
ans=query(hsh,q)%mod;
for(int i=x+1;i<=nlen;i++){
hsh=(((hsh-(ns[i-x]-'0')*pp[x-1])%mm+mm)%mm*p+ns[i]-'0')%mm;
//求长度为x的字符串的哈希值
q=(q-(ns[i-x]-'0')*p10[x-1])*10+ns[i]-'0';
ans=ans*query(hsh,q)%mod;
}
printf("%lld\n",ans);
}
int main(){
input();
int opt=0,x=0,y=0;
while(m--){
opt=read();
if(opt==1){
x=read(),y=read();
merge(x,y);
}
else if(opt==2){
x=read();
separate(x,to[x]);
}
else{
scanf("%s",ns+1);
nlen=strlen(ns+1);
scanf("%d",&x);
work3(x);
}
}
return 0;
}
KMP
但是我还是感觉参考博客写的有一点点的难理解,于是按照我的理解方式重新写了一遍。
前言:暴力匹配算法
在学习 \(\mathtt{KMP}\) 之前,我们首先要解决一个问题:
有两个字符串,一个是主串 \(S\) ,一个是模式串 \(P\) ,\((S.len>P.len)\),要求求出 \(P\) 在 \(S\) 中的位置,不存在输出 \(-1\).
看到这样的问题,先写一个暴力,时间复杂度统统不管,都暴力了要什么自行车
我们从第一位开始匹配:
我们设暴力匹配时,\(S\) 的枚举位置是 \(i\),\(P\) 的枚举位置是 \(j\)。
\(i=0,j=0\)
\(S\) 的第一位是 \(B\),\(P\) 的第一位是 \(A\),不匹配,移动 \(i\) 向前一位,\(j\) 不变为 \(0\)。
依旧不匹配,向前至匹配时候。
现在 \(i=3,j=0\),\(S_3=P_0=A\),匹配上了,\(++i,++j\)。
\(i=4,j=1,S_4=P_1=B\),还在匹配。
\(i=6,j=3,S_6=A,P_3=D\),最后一位没匹配上。。。怎么办?
如果没有匹配上,而且我们还匹配上了几步,肯定不能像之前一样直接\(++i\),必须从零开始,与此同时\(++i\),
操作应为\(i=i-j+1;j=0;\),下一次匹配是这样的:
于是就有了代码:
暴力匹配代码
int ViolentMatch(char* s, char* p)
{
int sLen = strlen(s);
int pLen = strlen(p);
int i = 0;
int j = 0;
while (i < sLen && j < pLen)
{
if (s[i] == p[j])
{
//①如果当前字符匹配成功(即S[i] == P[j]),则i++,j++
i++;
j++;
}
else
{
//②如果失配(即S[i]! = P[j]),令i = i - (j - 1),j = 0
i = i - j + 1;
j = 0;
}
}
//匹配成功,返回模式串p在文本串s中的位置,否则返回-1
if (j == pLen)
return i - j;
else
return -1;
}
然后这个暴力显然是不够优雅的,我们看我们最后一个匹配例子:
在之前的匹配中我们知道 \(i=4,j=1,S_4=P_1=B\neq P_0=A\),\(i\) 回溯是浪费我们的时间,就应该直接跳到 \(i=7,S_7=A\) 的正确位置。
1.正确位置在哪里?
这个正确位置,在 \(\mathtt{KMP}\) 中是 \(next\)。
我们上面找的例子里面模式串 \(P\) 中没有重复的字符,没有代表性,所以我们重新整一个新的例子:
直接匹配到该回溯的位置,\(i=9,j=6,S_9=A \neq P_6=D\):
暴力匹配下一步应该是这样的,\(i=4,j=0,S_4=B\neq P_0=A\):
但是我们希望是这样的,\(i=9,j=2,S_9=A\neq P_2=C\):
这样是不重不漏的,而且 \(i\) 也不变。
这里我们的 \(j\) 向前移动了 \(4\) 个位置,因为 \(j\) 向前移动 \(4\) 个位置又有一个 \(AB\) 刚好匹配上,因此我们就得到了 \(next\) 的定义:
\(next\) 代表当前字符之前的字符串中,有多大的相同前缀后缀。
(ps:有人说《算法导论》中写的是“前缀子串与以 \(i\) 结尾的非前缀子串能够匹配的最长长度”,请移步百度百科,搜索一下你会发现非前缀子串的意思就是不能和 \(A\) 完全相等的后缀子串)
拿这个举例子,\(j=6\),之前的字符串是 \(A\ B\ C\ D\ A\ B\)。
| 选几个字符 | 前缀 | 后缀 | 最大公共元素长度 |
|---|---|---|---|
| \(0\) | 空 | 空 | \(0\) |
| \(1\) | \(A\) | \(B\) | \(0\) |
| \(2\) | \(AB\) | \(AB\) | \(2\) |
| \(3\) | \(ABC\) | \(DAB\) | \(0\) |
| …………………… |
我们发现 \(next\) 的数值是 \(2\),刚好是我们希望的正确位置 \(j=2\)。
然后比较重要的一点是:对于字符串第一个位置前没有字符串,其 \(next\) 数组值为 \(-1\)。
如果 \(j=-1\lor S_i=p_j\) 都使得 \(++i,++j\)
2.代码实现递推next
我们将上面的总结成稍微数学一些的语言:
对于整数 \(k\),如果有模式串 \(P\) 中的字符串 \(p_0,p_1,p_2,p_3,……,p_{k-1}\) 与 \(p_{j-k},p_{j-k+1},……,p_{j-1}\) 相同,我们就说 \(next_j=k\)。
假设我们已知 \(next_0,next_1,……,next_{j-1},next_{j}\),如何求 \(next_{j+1}\) 呢?
对于
设 \(k=next_{j}\),如果 \(p_{k}=p_{j}\),那么 \(next_{j+1}=next_{j}+1=k+1\)。
我们还是像之前的一样先举个例子:\(P=A\ B\ C\ D\ A\ B\ C\ E\)
| \(p_j\) | \(A\) | \(B\) | \(C\) | \(D\) | \(A\) | \(B\) | \(C\) | \(E\) |
|---|---|---|---|---|---|---|---|---|
| 前缀后缀相同长度 | \(0\) | \(0\) | \(0\) | \(0\) | \(0\) | \(1\) | \(2\) | \(?\) |
| \(next\)值 | \(-1\) | \(0\) | \(0\) | \(0\) | \(0\) | \(1\) | \(2\) | \(?\) |
| 索引 | \(p_0\) | \(p_{k-1}\) | \(p_k\) | \(p_{k+1}\) | \(p_{j-k}\) | \(p_{j-1}\) | \(p_{j}\) | \(p_{j+1}\) |
显然 \(?==3\)。
如果 \(p_k\neq p_j\) 呢?我们还是举一个例子:\(P==A\ B\ C\ D\ A\ B\ D\ E\)。
| \(p_j\) | \(A\) | \(B\) | \(C\) | \(D\) | \(A\) | \(B\) | \(D\) | \(E\) |
|---|---|---|---|---|---|---|---|---|
| 前缀后缀相同长度 | \(0\) | \(0\) | \(0\) | \(0\) | \(0\) | \(1\) | \(2\) | \(?\) |
| \(next\)值 | \(-1\) | \(0\) | \(0\) | \(0\) | \(0\) | \(1\) | \(2\) | \(?\) |
| 索引 | \(p_0\) | \(p_{k-1}\) | \(p_k\) | \(p_{k+1}\) | \(p_{j-k}\) | \(p_{j-1}\) | \(p_{j}\) | \(p_{j+1}\) |
字符 \(E\) 之前的字符 \(D\neq C\),即 \(p_k \neq p_j\),因此我们不断递归索引 \(k=next_k\),在前缀中寻找是否可以找到 \(p_j\)。
(至于为什么不断递归 \(next\) 可以得到,类比上面的失配为什么用\(next\))
过程如下图:
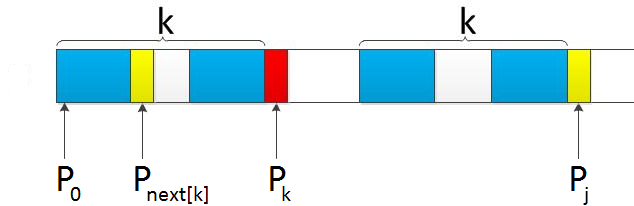
最终没有在前缀中找到 \(D\),\(?==0\)。
再举一个可以找到的例子:
\(P=D\ A\ B\ C\ D\ A\ B\ D\ E\)
| \(p_j\) | \(D\) | \(A\) | \(B\) | \(C\) | \(D\) | \(A\) | \(B\) | \(D\) | \(E\) |
|---|---|---|---|---|---|---|---|---|---|
| 前缀后缀相同长度 | \(0\) | \(0\) | \(0\) | \(0\) | \(0\) | \(1\) | \(2\) | \(3\) | \(?\) |
| \(next\)值 | \(-1\) | \(0\) | \(0\) | \(0\) | \(0\) | \(1\) | \(2\) | \(3\) | \(?\) |
| 索引 | \(p_0\) | \(p_1\) | \(p_{k-1}\) | \(p_{k}\) | \(p_{j-k}\) | \(p_{j-2}\) | \(p_{j-1}\) | \(p_{j}\) | \(p_{j+1}\) |
\(p_k=C \neq p_j=D\),于是去\(p_k\)的\(next\)值\(0\)中找到\(p_0=D \neq p_j=D\),\(next_j=1\)
递推得next代码
//len1表示模式串p的长度
void Next(){
int i=0,j=-1;
next_[i]=j;
while(i<len1){
if(j==-1||p1[i]==p1[j]){
++i;
++j;
next_[i]=j;
}
else j=next_[j];
}
}
当然上面的是下标从 \(0\) 开始的,还有一种下标从一开始的:
从1开始的next递推
void Next(){ //预处理Next数组
next_[1]=0;
for(int i=1,j=0;i<plen;++i){
while(j && p[i+1]!=p[j+1]) j=next_[j];
if(p[i+1]==p[j+1]) ++j;
next[i+1]=j;
}
}
上面的递推还有一种常见的写法:
i=2开始
void getnxt()
{
for(int i=2,j=0;i<=plen;i++)
{
while(j&&s[i]!=s[j+1]) j=nxt[j];
if(s[i]==s[j+1]) j++;
nxt[i]=j;
}
}
3.典型例题
COGS 1570. [POJ3461]乌力波
题目链接
内存限制:256 MiB
时间限制:1000 ms
标准输入输出
题目类型:传统
评测方式:文本比较
题目描述
法国作家乔治·佩雷克(Georges Perec,1936-1982)曾经写过一本书,《敏感字母》(La disparition),全篇没有一个字母‘e’。他是乌力波小组(Oulipo Group)的一员。下面是他书中的一段话:
Tout avait Pair normal, mais tout s’affirmait faux. Tout avait Fair normal, d’abord, puis surgissait l’inhumain, l’affolant. Il aurait voulu savoir où s’articulait l’association qui l’unissait au roman : stir son tapis, assaillant à tout instant son imagination, l’intuition d’un tabou, la vision d’un mal obscur, d’un quoi vacant, d’un non-dit : la vision, l’avision d’un oubli commandant tout, où s’abolissait la raison : tout avait l’air normal mais…
佩雷克很可能在下面的比赛中得到高分(当然,也有可能是低分)。在这个比赛中,人们被要求针对一个主题写出甚至是意味深长的文章,并且让一个给定的“单词”出现次数尽量少。我们的任务是给评委会编写一个程序来数单词出现了几次,用以得出参赛者最终的排名。参赛者经常会写一长串废话,例如500000个连续的‘T’。并且他们不用空格。
因此我们想要尽快找到一个单词出现的频数,即一个给定的字符串在文章中出现了几次。更加正式地,给出字母表{'A','B','C',...,'Z'}和两个仅有字母表中字母组成的有限字符串:单词W和文章T,找到W在T中出现的次数。这里“出现”意味着W中所有的连续字符都必须对应T中的连续字符。T中出现的两个W可能会部分重叠。
输入格式
输入包含多组数据。
输入文件的第一行有一个整数,代表数据组数。接下来是这些数据,以如下格式给出:
第一行是单词W,一个由{'A','B','C',...,'Z'}中字母组成的字符串,保证1<=|W|<=10000(|W|代表字符串W的长度)
第二行是文章T,一个由{'A','B','C',...,'Z'}中字母组成的字符串,保证|W|<=|T|<=1000000。
输出格式
对每组数据输出一行一个整数,即W在T中出现的次数。
样例
样例输入
3
BAPC
BAPC
AZA
AZAZAZA
VERDI
AVERDXIVYERDIAN
样例输出
1
3
0
kmp模板题目。
注意先输入的模式串。
(ps:据说这道题也可以用Hash做)
Miku's Code
#include<bits/stdc++.h>
using namespace std;
const int maxn=1e7+50;
int T,len1,len2,next_[maxn];
char s1[maxn],s2[maxn];
void input(){
//memset(next_,0,sizeof(next_));
scanf("%s %s",s1,s2);
len1=strlen(s1);
len2=strlen(s2);
}
void Next(){
int i=0,j=-1;
next_[i]=j;
while(i<len1){
if(j==-1 || s1[i]==s1[j]){
++i;
++j;
next_[i]=j;
}
else j=next_[j];
}
}
int kmp(){
Next();
int i=0,j=0,ans=0;
while(i<len1 && j<len2){
if(i==-1 || s1[i]==s2[j]){
++i;
++j;
}
else i=next_[i];
if(i==len1){
++ans;
i=next_[i];
}
}
return ans;
}
int main(){
scanf("%d",&T);
for(int i=1;i<=T;++i){
input();
printf("%d\n",kmp());
}
return 0;
}
Hash解
#include<bits/stdc++.h>
#define p 131
using namespace std;
inline long long read()
{long long f(1),x(0);
char ch=getchar();
for(;!isdigit(ch);ch=getchar()) if(ch=='-') f=-1;
for(;isdigit(ch);ch=getchar()) x=(x<<1)+(x<<3)+(ch^48);
return f*x;
}
inline void write(long long x)
{if(x<0) putchar('-'),x=-x;
if(x>9) write(x/10);
putchar(x%10+'0');
}
long long t,ans;
char ci[10001],wen[1000001];
long long lenc,lenw;
long long f[1000001],tar;
long long pi[1000001];
int main()
{t=read();
pi[0]=1;
while(t--)
{cin>>(ci+1);
cin>>(wen+1);
lenc=strlen(ci+1),lenw=strlen(wen+1);
memset(f,0,sizeof(f));
ans=0,tar=0;
for(long long i=1;i<=lenc;i++)
{tar=(tar*p+(ci[i]-'A'));
}
for(long long i=1;i<=lenw;i++)
{f[i]=(f[i-1]*p+(wen[i]-'A'));
pi[i]=p*pi[i-1];
}
for(long long i=1;i<=lenw-lenc+1;i++)
{if((f[i+lenc-1]-f[i-1]*pi[lenc])==tar)
{ans++;
}
}
write(ans),putchar('\n');
}
return 0;
}
[NOI2014] 动物园
这道题太好了,直接考验你对\(next\)的理解。
[NOI2014] 动物园
题目描述
近日,园长发现动物园中好吃懒做的动物越来越多了。例如企鹅,只会卖萌向游客要吃的。为了整治动物园的不良风气,让动物们凭自己的真才实学向游客要吃的,园长决定开设算法班,让动物们学习算法。
某天,园长给动物们讲解 KMP 算法。
园长:“对于一个字符串 \(S\),它的长度为 \(L\)。我们可以在 \(O(L)\) 的时间内,求出一个名为 \(\mathrm{next}\) 的数组。有谁预习了 \(\mathrm{next}\) 数组的含义吗?”
熊猫:“对于字符串 \(S\) 的前 \(i\) 个字符构成的子串,既是它的后缀又是它的前缀的字符串中(它本身除外),最长的长度记作 \(\mathrm{next}[i]\)。”
园长:“非常好!那你能举个例子吗?”
熊猫:“例 \(S\) 为 \(\verb!abcababc!\),则 \(\mathrm{next}[5]=2\)。因为\(S\)的前\(5\)个字符为 \(\verb!abcab!\),\(\verb!ab!\) 既是它的后缀又是它的前缀,并且找不到一个更长的字符串满足这个性质。同理,还可得出 \(\mathrm{next}[1] = \mathrm{next}[2] = \mathrm{next}[3] = 0\),\(\mathrm{next}[4] = \mathrm{next}[6] = 1\),\(\mathrm{next}[7] = 2\),\(\mathrm{next}[8] = 3\)。”
园长表扬了认真预习的熊猫同学。随后,他详细讲解了如何在 \(O(L)\) 的时间内求出 \(\mathrm{next}\) 数组。
下课前,园长提出了一个问题:“KMP 算法只能求出 \(\mathrm{next}\) 数组。我现在希望求出一个更强大 \(\mathrm{num}\) 数组一一对于字符串 \(S\) 的前 \(i\) 个字符构成的子串,既是它的后缀同时又是它的前缀,并且该后缀与该前缀不重叠,将这种字符串的数量记作 \(\mathrm{num}[i]\)。例如 \(S\) 为 \(\verb!aaaaa!\),则 \(\mathrm{num}[4] = 2\)。这是因为\(S\)的前 \(4\) 个字符为 \(\verb!aaaa!\),其中 \(\verb!a!\) 和 \(\verb!aa!\) 都满足性质‘既是后缀又是前缀’,同时保证这个后缀与这个前缀不重叠。而 \(\verb!aaa!\) 虽然满足性质‘既是后缀又是前缀’,但遗憾的是这个后缀与这个前缀重叠了,所以不能计算在内。同理,\(\mathrm{num}[1] = 0,\mathrm{num}[2] = \mathrm{num}[3] = 1,\mathrm{num}[5] = 2\)。”
最后,园长给出了奖励条件,第一个做对的同学奖励巧克力一盒。听了这句话,睡了一节课的企鹅立刻就醒过来了!但企鹅并不会做这道题,于是向参观动物园的你寻求帮助。你能否帮助企鹅写一个程序求出\(\mathrm{num}\)数组呢?
特别地,为了避免大量的输出,你不需要输出 \(\mathrm{num}[i]\) 分别是多少,你只需要输出所有 \((\mathrm{num}[i]+1)\) 的乘积,对 \(10^9 + 7\) 取模的结果即可。
输入格式
第 \(1\) 行仅包含一个正整数 \(n\),表示测试数据的组数。
随后 \(n\) 行,每行描述一组测试数据。每组测试数据仅含有一个字符串 \(S\),\(S\) 的定义详见题目描述。数据保证 \(S\) 中仅含小写字母。输入文件中不会包含多余的空行,行末不会存在多余的空格。
输出格式
包含 \(n\) 行,每行描述一组测试数据的答案,答案的顺序应与输入数据的顺序保持一致。对于每组测试数据,仅需要输出一个整数,表示这组测试数据的答案对 \(10^9+7\) 取模的结果。输出文件中不应包含多余的空行。
样例 #1
样例输入 #1
3
aaaaa
ab
abcababc
样例输出 #1
36
1
32
提示
| 测试点编号 | 约定 |
|---|---|
| 1 | \(n \le 5, L \le 50\) |
| 2 | \(n \le 5, L \le 200\) |
| 3 | \(n \le 5, L \le 200\) |
| 4 | \(n \le 5, L \le 10,000\) |
| 5 | \(n \le 5, L \le 10,000\) |
| 6 | \(n \le 5, L \le 100,000\) |
| 7 | \(n \le 5, L \le 200,000\) |
| 8 | \(n \le 5, L \le 500,000\) |
| 9 | \(n \le 5, L \le 1,000,000\) |
| 10 | \(n \le 5, L \le 1,000,000\) |
我们来看这道题,这道题我是用下标为\(1\)开始做的,我们的\(next\)数组是前缀后缀最大相同字符数量,而这道题要求我们求相同的个数。
举个例子:
\(ABABAC\)这个字符串的\(num\)值应该是\(1\)(\(A\)X\(A\))这并不是因为只有\(A\)一个字符,而是因为只有\(A\)这一种不交叉的方案。
我们很难让它的\(num\)不交叉,但是我们可以转换思路,设\(num_i\)是第\(i\)个字符前的字符串配对方案(包括其自身)。
使\(num_1=1\),\(num_i=num_{i的next}+1\),
那么我们可以在递推\(next\)的时候得到\(num\)。
Miku's Code
#include<bits/stdc++.h>
using namespace std;
typedef long long intx;
const int maxs=1e6+50,mod=1e9+7;
int T,num[maxs],next_[maxs],plen;
char s[maxs];
intx ans;
void Next(){
next_[1]=0;
for(int i=1,j=0;i<plen;++i){
while(j && s[i+1]!=s[j+1]) j=next_[j];
if(s[i+1]==s[j+1]) ++j;
next_[i+1]=j;num[i+1]=num[j]+1;
//num是包括自己的,递推得到的,前缀后缀相同的个数
}
}
int main(){
scanf("%d",&T);
while(T--){
memset(next_,0,sizeof(next_));
ans=1;
num[1]=1;
scanf("%s",s+1);
plen=strlen(s+1);
Next();
for(int i=1,j=0;i<plen;++i){
while(j && s[i+1]!=s[j+1]) j=next_[j];
if(s[i+1]==s[j+1]) ++j;
while((j<<1)>(i+1)) j=next_[j]; //不断暴力跳next,使得没有交部分
ans=(ans*(intx)(num[j]+1))%mod;
}
printf("%lld\n",ans);
}
return 0;
}
Trie树
(相比于上面的,Trie树是非常亲切的)
Trie树是一种数据结构,又被称为字典树。
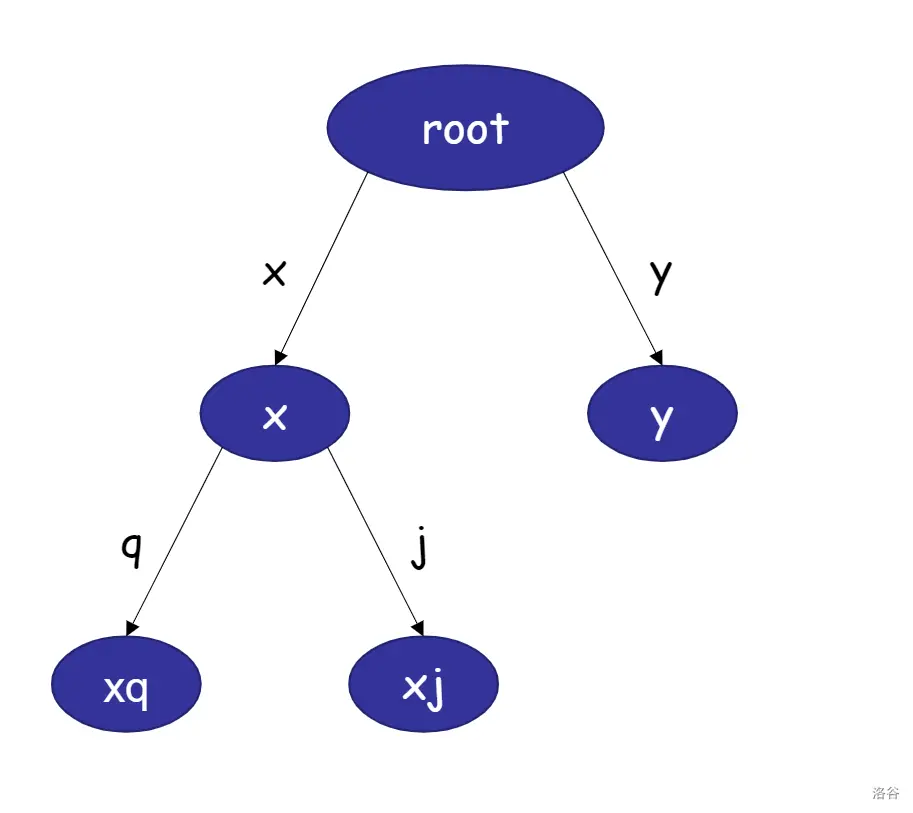
(图源:洛谷Celtic老师的题解)
它有以下特点:
-
用边表示字符
-
相同前缀的字符串公用前缀节点
-
根节点为空
-
字符串结束后用一个特殊字符表示(图中没有写)
insert
插入一个字符。
在图中可见,从左往右扫一个字符串,如果该字符在相应的根节点下没有出现过就插入这个字符,否则就顺着下行。
因此可设:\(trie_{i,j}=k\)表示字符-‘a’为\(i\)的节点的第\(j\)个孩子是编号为\(k\)的节点。
insert
void insert(){
len=strlen(s);
root=0;
for(int i=0;i<len;++i){
int id=s[i]-'a';
if(!trie[root][id]) trie[root][id]=++cnt;
root=trie[root][id];
}
}
search
我们可以查找一个前缀,也可以查找整个字符串,以查找前缀为例,从左往右扫描每个字母,顺着字典树下行,如果没有就返回。
search
bool search(){
len=strlen(s);
root=0;
for(int i=0;s[i];++i){
int id=s[i]-'a';
if(trie[root][id]==0) return false;
root=trie[root][id];
}
return ture;
}
-
如果是查询整个字符串,我们需要注意判断最后一个节点是不是没有孩子节点。
-
如果查询前缀出现次数,可以使用\(sum\)数组记录位置被访问的次数,最后返回\(sum_{root}\)
典型例题
【模板】字典树
【模板】字典树
题目描述
给定 \(n\) 个模式串 \(s_1, s_2, \dots, s_n\) 和 \(q\) 次询问,每次询问给定一个文本串 \(t_i\),请回答 \(s_1 \sim s_n\) 中有多少个字符串 \(s_j\) 满足 \(t_i\) 是 \(s_j\) 的前缀。
一个字符串 \(t\) 是 \(s\) 的前缀当且仅当从 \(s\) 的末尾删去若干个(可以为 0 个)连续的字符后与 \(t\) 相同。
输入的字符串大小敏感。例如,字符串 Fusu 和字符串 fusu 不同。
输入格式
本题单测试点内有多组测试数据。
输入的第一行是一个整数,表示数据组数 \(T\)。
对于每组数据,格式如下:
第一行是两个整数,分别表示模式串的个数 \(n\) 和询问的个数 \(q\)。
接下来 \(n\) 行,每行一个字符串,表示一个模式串。
接下来 \(q\) 行,每行一个字符串,表示一次询问。
输出格式
按照输入的顺序依次输出各测试数据的答案。
对于每次询问,输出一行一个整数表示答案。
样例 #1
样例输入 #1
3
3 3
fusufusu
fusu
anguei
fusu
anguei
kkksc
5 2
fusu
Fusu
AFakeFusu
afakefusu
fusuisnotfake
Fusu
fusu
1 1
998244353
9
样例输出 #1
2
1
0
1
2
1
提示
数据规模与约定
对于全部的测试点,保证 \(1 \leq T, n, q\leq 10^5\),且输入字符串的总长度不超过 \(3 \times 10^6\)。输入的字符串只含大小写字母和数字,且不含空串。
说明
std 的 IO 使用的是关闭同步后的 cin/cout,本题不卡常。
板子。
Miku's Code
#include<bits/stdc++.h>
using namespace std;
const int maxn=1e5+50,maxs=3e6+50;
int T,n,q,len,cnt;
char s[maxs];
int trie[maxs][128],sum[maxs];
void insert(int x){
int root=0;
for(int i=0;i<len;++i){
int k=s[i];
if(!trie[root][k]){
trie[root][k]=++cnt;
}
root=trie[root][k];
++sum[root];
}
}
int search(){
int root=0;
for(int i=0;i<len;++i){
int k=s[i];
if(!trie[root][k]) {return 0;}
root=trie[root][k];
}
return sum[root];
}
void input(){
scanf("%d %d",&n,&q);
for(int i=1;i<=n;++i){
scanf("%s",s);
len=strlen(s);
insert(i);
}
}
void clear(){
for(int i=0;i<=cnt;++i){
sum[i]=0;
for(int j=0;j<=127;++j){
trie[i][j]=0;
}
}
cnt=0;
}
int main(){
scanf("%d",&T);
while(T--){
input();
for(int i=1;i<=q;++i){
scanf("%s",s);
len=strlen(s);
printf("%d\n",search());
}
clear();
}
return 0;
}
Phone List
Phone List
题面翻译
给定\(n\)个长度不超过\(10\)的数字串,判断是否有两个字符串\(A\)和\(B\),满足\(A\)是\(B\)的前缀,若有,输出NO,若没有,输出YES。
Translated by @wasa855
题目描述

输入格式
输出格式

样例 #1
样例输入 #1
2
3
911
97625999
91125426
5
113
12340
123440
12345
98346
样例输出 #1
NO
YES
板子题目。
Miku's Code
#include<bits/stdc++.h>
using namespace std;
const int maxn=1e5+50,maxs=15;
char s[maxn];
int T,n,len;
int root,cnt,trie[maxn][maxs];
bool end_[maxn],vis[maxn],judge;
void insert(){
root=0;
len=strlen(s);
for(int i=0;i<len;++i){
int id=s[i]-'0';
if(!trie[root][id]){
trie[root][id]=++cnt;
vis[root]=true;
}
if(end_[root]){
judge=false;
return;
}
root=trie[root][id];
}
if(vis[root]) judge=false;
end_[root]=true;
return;
}
void input(){
memset(trie,0,sizeof(trie));
memset(vis,false,sizeof(vis));
memset(end_,false,sizeof(end_));
judge=true;
cnt=0;
scanf("%d",&n);
for(int i=1;i<=n;++i){
scanf("%s",s);
if(judge==true) insert();
//不能break不然输入就乱了
}
}
int main(){
scanf("%d",&T);
while(T--){
input();
if(judge==false) printf("NO\n");
else printf("YES\n");
}
return 0;
}
「一本通 2.3 例 2」The XOR Largest Pair
题目描述
在给定的 N 个整数 A_1,A_2,…,A_N 中选出两个进行异或运算,得到的结果最大是多少?
输入格式
第一行一个整数 N。
第二行 N 个整数 A_i。
输出格式
一个整数表示答案。
样例
输入
5
2 9 5 7 0
输出
14
数据范围与提示
对于 100% 的数据,\(1\le N\le 10^5, 0\le A_i <2^{31}\)。
这道题还算有趣,因为异或的运算法则是只有一个\(1\)时返回\(1\),这意味着只要我们相邻节点有\(0\)或\(1\)该位置该数位就可以为\(1\),而放入树时又是一条链下来的所以我们可以直接把数转换为二进制数放入。
点击查看代码
#include<bits/stdc++.h>
using namespace std;
typedef long long intx;
const int maxn=1e5+50;
int n,ns,len,cnt,ansl,s;
int tire[maxn*32][2];
inline int insert(int m){
int ans=0,root=0,root2=0;
for(int i=len;i>=0;--i){
int num=(m>>i)&1;
if(!tire[root][num]){
tire[root][num]=++cnt;
}
root=tire[root][num];
if(tire[root2][num^1]){
root2=tire[root2][num^1];
ans+=(1<<i);
//异或是只有一个1时为1,如果0和1都存在我们应该的答案应该有这一位1
}
else root2=tire[root2][num];
}
return ans;
}
void input(){
scanf("%d",&n);
for(int i=1;i<=n;++i){
scanf("%d",&ns);
len=31;
s=insert(ns);
if(s>ansl) ansl=s;
}
printf("%d",ansl);
}
int main(){
input();
return 0;
}
