论文解析 "A Non-Local Cost Aggregation Method for Stereo Matching"
传统的使用窗口的方法缺陷主要在
1.窗口外的像素不能参与匹配判断.
2.在低纹理区域很容易产生错误匹配
论文的主要贡献在代价聚类上(左右图像带匹配点/区域的匹配代价计算),目标是图像内所有点都对该点传递一个support,距离该点较远的或者颜色差别很大的点传递较小的Support.
本文利用MST(最小生成树)来构建这个代价聚类的结构,根据MST结构我们知道,当把图像看做是一个四联通区域的图时,图像两点所形成边的权值我们定义为这两点灰度值的差值,这种定义下生成的MST结构正好符合我们的期望。这一做法相当于在局部算法上加了全局性质,所以称之为非局部算法.更为难得的是这一算法根据作者推倒的公式只需要对MST遍历两次即可得到所有点的代价聚类.
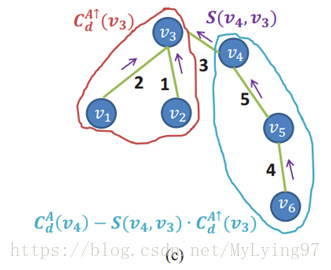
MST可以将计算范围从所有节点缩小到父节点和子节点上,而父节点只有一个或多个子节点,其实最多只有3个,因为是4邻居(这块我还没明白).基于每个像素点作为根节点循环,计算复杂度就比较高,作者又提出了两次遍历MST,当v4作为根节点时候,第一次是从叶节点向根节点聚集,更新每个根节点的代价聚集值且只更新根节点的聚集值(即图中的V4节点),此时v3,v5里面是临时值,v1,v2,v6都是0,第二次是从根节点向叶节点聚集,主要解决v1,v2,v6的值,之后再v3作为根节点,则v4一支作为v3的子节点,v3的值需要v4减去<v3,v4>。这样省去了复杂并且不断重复的死板运算。
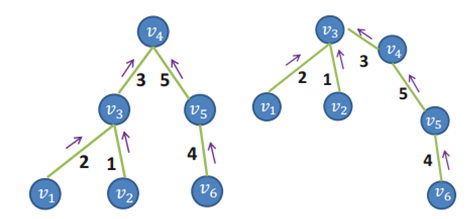
对于上图左图,对应如下的公式,其中不带向上箭头的Cd()是已经聚集完的.
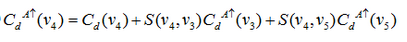
对于上图右图,对应如下公式
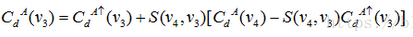
这样任何一个点如果即将作为根节点,都可以从他的父节点(parent)得到值.如下公式
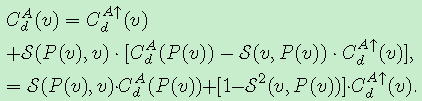
另外每个非根节点的值可以由如下公式获得
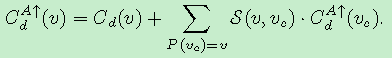
以上公式所用到的公共项:
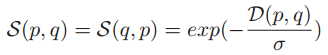 , 其中D(p,q)表示p和q在MST上的距离,其中D(p,q)=D(q,p) (这个还不知道什么意思)
, 其中D(p,q)表示p和q在MST上的距离,其中D(p,q)=D(q,p) (这个还不知道什么意思)
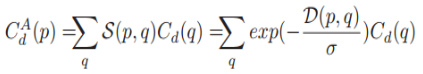
其中Cd(q)表示每个像素q在视差级别d下的匹配代价
Note that in Eqn. (6) and (7), S(v, vc), S(P(v), v) and 1−S2(v,P(v)) only depend on the edges of MST and can be pre-computed, thus only a total of 2 addition/subtraction operations and 3 multiplication operations will be required for each node at each disparity level during cost aggregation.
在视差精化步骤,基于上述非局部代价聚集方法,先分别得到左右两个图像的视差图,然后进行左右一致性检测,得到稳定点和不稳定点,稳定点就可以通过检测,同时直接在左视差图上定义新的代价值,再同样利用原图所得的MST,对所有像素点重新进行代价聚合,最后利用WTA算法更新视差。其余不稳定点代价值为0。
由于MST的性质,使得原本对全部像素的比较,只需要对父节点,子节点的比较即可,每次计算代价聚合值,从上述公式看来只需要一次加法,一次减法和三次乘法,这样便极大提高了速度,同时又考虑到了全局像素的影响。在middlebury上数据集的平均计算时间仅为90毫秒。
有网友认为的不足有:
(1)非局部MST用到了整个图像,相当于每个像素都和其他所有像素有权值联系,但是实际上距离得远的像素点之间说不定就没有相关性,这样做反而觉得有点多余,所以我认为可以对图像进行分割操作,在每个分割块内做MST,但是这个方法可能复杂度比较高,但是至少可以把目标和背景分开再进行操作,应该可以更准确。
(2)这种方法在高纹理区域效果不是很好(主要由于噪声而且会导致左右视差图不连续),所以可以结合高斯滤波的方法,而且这种方法来自周围的支持像素点相对较少,这一点对高纹理区域来说影响也很大,所以是不是可以在高纹理区域进行一些处理。
(3)最小生成树的冗余性,树连接全局,同时也是它的局限性。
《A Non-Local Cost Aggregation Method for Stereo Matching》读后感
这篇论文主要创新在代价聚集步骤,传统的聚集一般是在局部区域,这样结果也只是局部最优。但是这篇论文提出了非局部代价聚集的方法,用一颗最小生成树(MST)将整个图像联系起来,它以全图的像素作为节点,构建过程中不断删除权值较大的边,边就是相邻像素间的最短距离(即两个节点间相似性最小,本篇文章的相邻像素点指的是4邻域,我认为可以用8邻域来尝试)。然后采用kruskal(克鲁斯卡尔)算法或prim(普里姆)算法进行计算,这样便得到了全图像素之间的关系。然后基于这层关系,构建代价聚合其中树的节点就是图像像素点,这样每个像素点作为根节点的时候都能接受来自整个图像其他像素点的支持,就只是权重的大小随距离远近变得不同而已,但至少不是局限在一个区域或者窗口里,这就是本文的创新点。但是基于每个像素点作为根节点循环,计算复杂度就比较高,作者又提出了两次遍历MST,第一次是从叶节点向根节点聚集,更新每个根节点的代价聚集值(即图中的V4节点),第二次是从根节点向叶节点聚集,更新每个叶节点的代价聚集值(图中的V3节点)。计算第二次的聚集值时,就不需要再一次以这个点为根节点,因为第一次聚集的值可以放在第二次用,只不过做个减法就好,这样省去了复杂并且不断重复的死板运算。
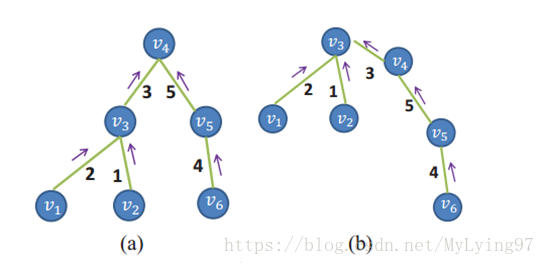
我把论文中一般公式具体化:
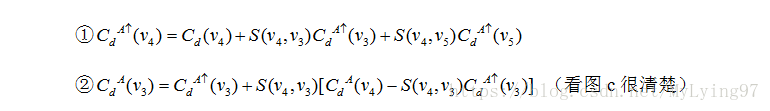
----------------------------------------------------------------------------------------------------------------------------------------------
算法基本上上面那些,在代码部分的解析如下
~ 程序首先先生成了两幅图像的梯度,这里面梯度实际上只考虑的每行某像素和其后面像素与它的插值,并没有考虑周围其他像素的差值.下图是左图像生成的梯度图

直接使用上面的梯度和颜色进行匹配的结果如下图所示(也就是程序中的m_cost_vol)



 浙公网安备 33010602011771号
浙公网安备 33010602011771号