面试题
1.print(2>1 and 3 or 4)
输出什么
2>1 是True 所以在 2>1 and 3 中输出的是 3 . 3 or 4 中 3 为True 所以直接输出 3
and ---> 左 ---> 右
若左为真,就输出【右】;若左为假,则直接输出【左】
or ---> 左 ---> 右 若左为真,就直接输出【左】;若左为假,就输出【右】
2.ascii码 有8位: 0000 0000
第一位是什么
第一位是0,因为那是预留位,当时的字母,数字,特殊符号加起来不超过 128 位 [2的七次方].
3.多位数相加【简易的加法计算器】
#因为只是加法,所以用到“+”分割
content = input('请输入内容') s = content.split('+') #以“+”分割成列表 sum = 0 #求和 初始值为零 for i in s: #有限循环列表的内容 z = i #赋值,【如果不赋值,会报错】 a = int(z) #将str转化为int sum += a print(sum)
4.排序问题
5.分别赋值概念
设:a = 1, b = 2 print(a,b) = ?
a , b = 1 , 2 #可以理解为a = 1 ; b = 2 print(a,b) a , b = ('alex' , '34') #同理 print(a,b) a , b = ['alex' , '34'] #同理 print(a , b) 1 2 alex 34 alex 34 #不能出现下面的情况 a , b = 1 , 2 ,4 print(a,b) #会报错 #或 a , b = 1 , 2 print(a,b,c) #会报错
6.str的替换
我们可以直接给字符串进行替换操作,例题:错题锦集,敏感词
li = '我是宋子键,我热爱学习' li1 = li.replace('坂田征四郎','*') print(li1) 我是宋子键,我热爱学习 #因为没有敏感词,所以没有替换 li = '我是坂田征四郎,我热爱学习' li1 = li.replace('坂田征四郎','*') print(li1) 我是*,我热爱学习 #出现敏感词,直接替换
7、 我想让 utf-8 的 bytes ----> gbk 的 bytes
不同的密码本之间的二进制是不能互相识别的,容易报错或者产生乱码
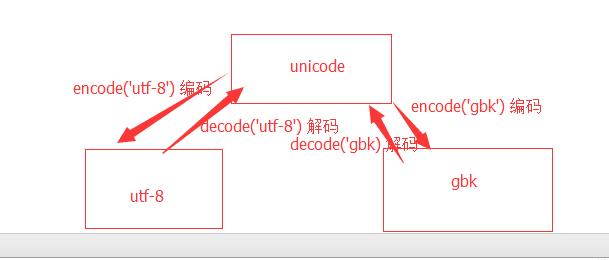
8、 l1 = [11, 22, ['barry', [55, 66]], [11, 22]] l2 = l1.copy() 我要把 [55, 66] 改为[55, 102] 请问:l2的值变不变
l1 = [11, 22, ['barry', [55, 66]], [11, 22]] l2 = l1.copy() l1[2][1][1] = 102 print(l1,id(l1[2][1])) print(l2,id(l2[2][1])) [11, 22, ['barry', [55, 102]], [11, 22]] 3224167235784 [11, 22, ['barry', [55, 102]], [11, 22]] 3224167235784
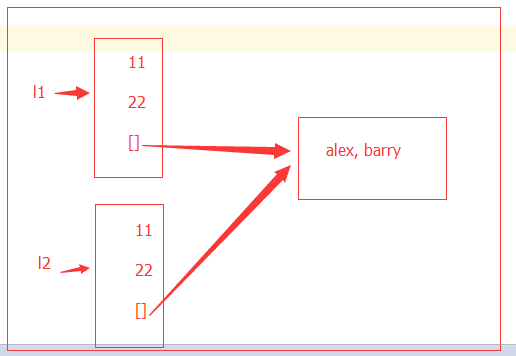
对于浅copy来说,第一次创建的是新的内存地址,而从第二层开始指向的都是一个内存地址,所以对于第二层以及更深的层数来说,保持一致性。
1.对扩展是开放的
为什么要对扩展开放呢?
我们说,任何一个程序,不可能在设计之初就已经想好了所有的功能并且未来不做任何更新和修改。所以我们必须允许代码扩展、添加新功能。
2.对修改是封闭的
为什么要对修改封闭呢?
就像我们刚刚提到的,因为我们写的一个函数,很有可能已经交付给其他人使用了,如果这个时候我们对其进行了修改,很有可能影响其他已经在使用该函数的用户。
装饰器完美的遵循了这个开放封闭原则
函数内部如果有变量名与全局变量名相同,且对函数内部的变量进行改变
那么 python 就会将你引用的那个变量 (全局变量)视为局部定义的变量,但是局部没有定义,则他会报错
count = 1 # 全局变量 def func1(): count = count + 1 # 里面的 count 与全局变量名相同,并对他进行改变 # python 会将外面的 count 视为局部定义的的变量,但是局部没有定义 print(count) func1() # 执行后报错
在使用 global 时必须把它放声明的变量 使用前
 正确格式错误示范
正确格式错误示范
随机验证码
手机版 6位 数字
网页版 6位 字母数字
发红包
__new__
两个文件之间的相互导入 【 import】
有哪些研发相关的架构
怎样通过IP地址找到物理地址 arp 协议
交换机的通讯方式:
你认为tcp 和 udp 的区别
请描述 osi 五层模型
网段ip怎么确定
请描述 B/S 的优势
4、小常识,浏览器中如何在一段时间内记录了你的登录验证?
5、简单说一下这个ftp
并发编程 进程同步部分 锁
秀一波 🐱👤 代码的爱情
print('\n'.join([''.join([('Love'[(x-y) % len('Love')] if ((x*0.04)**2+(y*0.1)**2-1)**3-(x*0.04)**2*(y*0.1)**3 <= 0 else ' ') for x in range(-30, 30)]) for y in range(30, -30, -1)]))
MySQL之储存过程(仅面试)
储存过程的定义:
储存在数据库目录中的一坨声明性MySQL语句
储存的优点:
1、通常储存过程有助于提高应用程序的性能。当创建储存过程被编译之后,就储存在数据库中。但是,MySQL实现的储存过程略有不同。MySQL储存过程按需编译。在编译储存过程之后,,MySQL将其放入缓存中。MySQL为每个链接维护自己的存储高速缓存。如果应用程序在单个连接中多次使用储存过程,则使用编译版本,否则储存过程的方式类似于查询
2、储存过程有助于减少应用程序和数据库服务器之间的流量,因为应用程序不必发送多个冗长的MySQL语句 ,而只能发送储存过程的名称和参数
3、储存的程序对任何应用程序都是可重复的和透明的。储存过程将数据库借口暴露给所有应用程序,以便开发人员不必开发储存过程中已经支持的功能。
4、初春的程序是安全的。数据库管理员可以向访问数据库中储存过程的应用程序授予适当的权限,而不向基础数据库提供任何权限
储存过程的缺点
1、如果使用大量储存过程,那么使用这些储存过程的每一个链接的内存使用量将大大增加。此外,如果您在储存过程中过度使用大量的逻辑操作,则CPU使用率也会增加,因为数据库服务器的设计不当。。。
2、储存过程的构造使得开发具有复杂的业务逻辑的储存过程变得更加困难
3、很难调试储存过程。只有少数数据库管理系统允许您调试储存过程。不幸的是MySQL就是这种
4、开发和维护储存过程并不容易。开发和维护储存过程通常需要一个不是所有应用程序开发人员拥有的专业技能。这可能会导致应用程序开发和维护阶段的问题
默认参数的坑:可变类型(麻袋问题)

只用一行代码:使用 filter(过滤函数) 和 lambda(匿名函数) 输出下列列表中索引为奇数的对应元素
lis = [ 0,1,2,3,4,5,6,7,8,9,10]

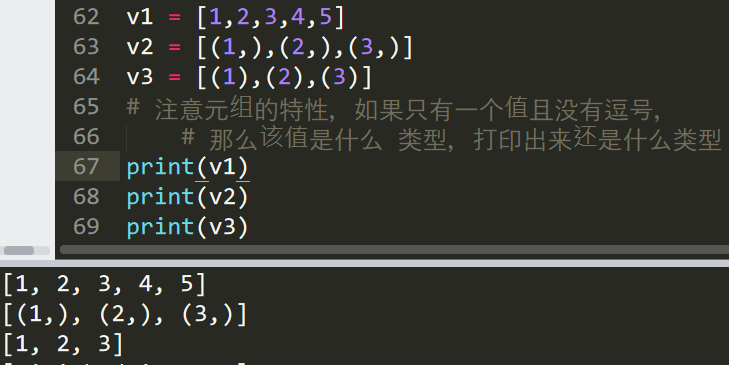
问:v1 v2 v3 打印出来各是什么结果
递归:上台阶问题
一次可以上1个或2个或3个(最多上三个台阶)台阶,现在总共有 n 个台阶,一共有多少种走法
上1个台阶 需要1种方法 (1)
上2个台阶 需要2种方法 (1,1) (2)
上3个台阶 需要4种方法 (1,1,1) (1,2) (2,1) (3)递归建议反着推导
最后几个台阶的情况
在第 n-1 个台阶 有1种走法
在第 n-2 个台阶 有1种走法
原本有两种(1,1)和(2) 但是在 n-1 时 就已经存在(1,1)了
在第 n-3 个台阶 有1种走法
原本有4种方法 但是(1,1,1)(1,2)(2,1)在前面 n-2 n-1 已经有了
所以我们可以得出 递归函数
def func(n): if n == 1: return 1 elif n == 2: return 2 elif n == 3: return 4 return func(n-1)+func(n-2)+func(n-3)
列表推导式+匿名函数(还有生成器推导式的陷阱)

注意点:
列表推导式和生成器推导式的区别:
列表推导式是一下子生成然后存到内存中,即 在最后退出列表
生成器推导式是一个一个取,即 取一个值就退出
匿名函数:参数是 x 返回值是 x*i 注意:在列表退出时 i == 3
结果为[ 6,6,6,6 ]

def func(X):
for i in range(4):
s = X*i
return s # 当列表打印完后退出,打印完时 i == 3
print(func(2))
编写函数 ip转化为 整数
本题考察的是:
Python内置函数:bin()、oct()、int()、hex()可实现进制转换的一些用法, bin()、oct()、hex()的返回值均为字符串,且分别带有0b、0o、0x前缀。
字符串的方法:zfill(width) width指定字符串的宽度,字符串右对齐,不够的用 0 补足
例如:‘12’.zfill(4) --> ‘0012’
def IP(n): int_list = [] n_list = n.split('.') for i in n_list: i = int(i) # 转化为字符串 ip_int = bin(i) ip = ip_int[2:] # bin()、oct()、hex()的返回值均为字符串,且分别带有0b、0o、0x前缀。 # 用 切片的方法 去掉 前缀 v = 8 - len(ip) int_list.append('0' * v + ip) # 通过字符串的拼接补足 8 位 s = ' '.join(int_list) # 列表的 连接 return s print(IP(input('请输入IP地址:》》》')))
def ip(value): res = value.split('.') s='' for i in res: i = (bin(int(i)).strip('0b')) if len(i) != 8: print('001-->',i) i = i.zfill(8) # zfill(width) : 字符串的方法, width指定字符串的宽度,字符串右对齐,不够的用 0 补足 print('002-->',i) s+=i return s print(ip('13.2.9.12'))
| ↓ | 2进制 | 8进制 | 10进制 | 16进制 |
| 2进制 | - | bin(int(x, 8)) | bin(int(x, 10)) | bin(int(x, 16)) |
| 8进制 | oct(int(x, 2)) | - | oct(int(x, 10)) | oct(int(x, 16)) |
| 10进制 | int(x, 2) | int(x, 8) | - | int(x, 16) |
| 16进制 | hex(int(x, 2)) | hex(int(x, 8)) | hex(int(x, 10)) | - |
注意:int 可以让所有的编码转化成 10进制,但必须声明该编码的类型,如: int(‘0b1110’,2) 这是二进制编码 '0b1110' 要转化成 10 进制 返回 int 类型
bin 可以让所有编码转化成 2 进制 返回 字符串类型 有前缀 0b
oct 可以让所有编码转化成 8 进制 返回 字符串类型 有前缀 0o
hex 可以让所有编码转化成 8 进制 返回 字符串类型 有前缀 0x
int([number | string[, base]])
int([数]字符串[,基] ]
Convert a number or string to an integer. If no arguments are given, return 0. If a number is given, return number.__int__(). Conversion of floating point numbers to integers truncates towards zero. A string must be a base-radix integer literal optionally preceded by ‘+’ or ‘-‘ (with no space in between) and optionally surrounded by whitespace. A base-n literal consists of the digits 0 to n-1, with ‘a’ to ‘z’ (or ‘A’ to ‘Z’) having values 10 to 35. The default base is 10. The allowed values are 0 and 2-36. Base-2, -8, and -16 literals can be optionally prefixed with 0b/0B, 0o/0O, or 0x/0X, as with integer literals in code. Base 0 means to interpret exactly as a code literal, so that the actual base is 2, 8, 10, or 16, and so that int('010', 0) is not legal, while int('010') is, as well as int('010', 8).
将数字或字符串转换为整数。如果不给出任何参数,返回0。如果给出一个数字,返回数。浮点数到整数的转换截断为零。一个字符串必须是一个基数整数字,可选地前面加上“+”或“--”(中间没有空格),并且可选地由空格包围。一个BASE-N文字由数字0到N-1组成,具有“A”到“Z”(或“A”到“Z”)的值为10到35。默认基数为10。允许值为0和2-36。BASE-2、-8和-16文字可以可选地以0b/0b、0o/0o或0x/0x为前缀,就像代码中的整数文本一样。基0意味着准确地解释为代码文字,因此实际基为2, 8, 10或16,因此int(‘010’,0)不是合法的,而int('010')也是int('010',8)。
面向对象的 MRO(钻石继承)
nmmc''
