scrapy框架之shell
scrapy shell
scrapy shell是一个交互式shell,您可以在其中快速调试 scrape 代码,而不必运行spider。它本来是用来测试数据提取代码的,但实际上您可以使用它来测试任何类型的代码,因为它也是一个常规的Python shell。
shell用于测试xpath或css表达式,并查看它们是如何工作的,以及它们从您试图抓取的网页中提取的数据。它允许您在编写spider时交互地测试表达式,而不必运行spider来测试每个更改。
一旦你熟悉了 Scrapy Shell,你就会发现它是开发和调试蜘蛛的宝贵工具。
配置shell
如果你有 IPython 安装后,scrapy shell将使用它(而不是标准的python控制台)。这个 IPython 控制台功能更强大,提供智能自动完成和彩色输出等功能。
通过Scrapy的设置,您可以将其配置为使用 ipython , bpython 或标准 python shell,无论安装了什么。这是通过设置 SCRAPY_PYTHON_SHELL 环境变量;或通过在 scrapy.cfg ;
[settings]
shell = bpython
启动shell
使用 shell 命令如下:
scrapy shell <url> # <url>是要抓取的url
shell 也适用于本地文件。如果你想玩一个网页的本地副本,这很方便。 shell 了解本地文件的以下语法:
# UNIX-style scrapy shell ./path/to/file.html scrapy shell ../other/path/to/file.html scrapy shell /absolute/path/to/file.html # File URI scrapy shell file:///absolute/path/to/file.html
使用相对文件路径时,请使用 ./ (或) ../ 表示文件存储的路径
scrapy shell ./index.html
![]()
使用shell
scrappyshell只是一个普通的python控制台(或者 IPython 控制台,如果你有它的话),它提供一些额外的快捷功能,以方便。
可用的快捷方式
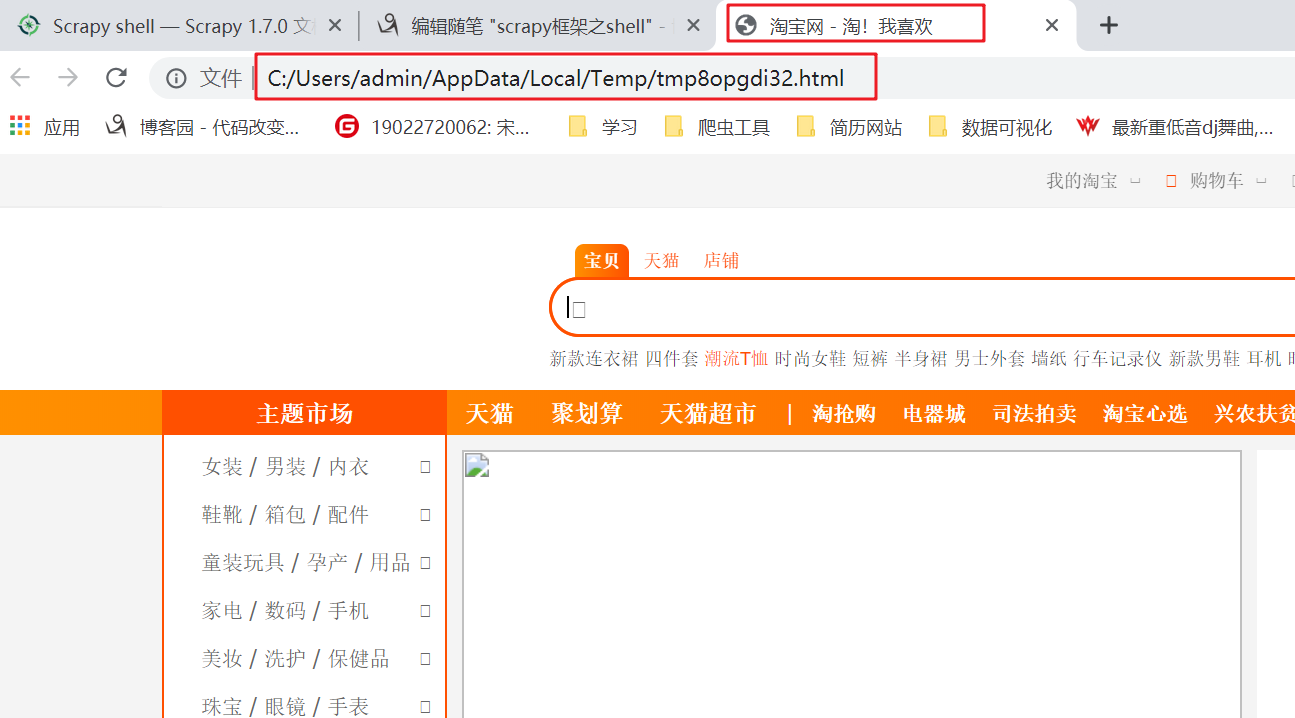
shelp() -打印有关可用对象和快捷方式列表的帮助 fetch(url[, redirect=True]) - 从给定URL获取一个新的响应,并相应地更新所有相关对象。您可以选择请求HTTP 3xx重定向,以避免传递 fetch(request) -从给定的请求中获取新的响应,并相应地更新所有相关对象。 view(response) -在本地Web浏览器中打开给定的响应以进行检查。这将增加一个 <base> tag 到响应主体,以便外部链接(如图像和样式表)正确显示。但是请注意,这将在您的计算机中创建一个临时文件,该文件不会自动删除。
可用的srapy对象
Scrapy Shell自动从下载的页面创建一些方便的对象,例如 Response 对象与 Selector 对象(用于HTML和XML内容)。
这些对象是:
Shell会话示例
下面是一个典型的shell会话的例子,我们从抓取https://scrappy.org页面开始,然后继续抓取https://reddit.com页面。最后,我们修改(reddit)请求方法来发布和重新获取它,得到一个错误。我们通过在Windows中键入ctrl-d(在UNIX系统中)或ctrl-z来结束会话。
请记住,在这里提取的数据在您尝试时可能不相同,因为这些页面不是静态的,在您测试时可能已经更改了。这个例子的唯一目的是让您熟悉下脚料外壳的工作原理。
首先,我们发射炮弹:
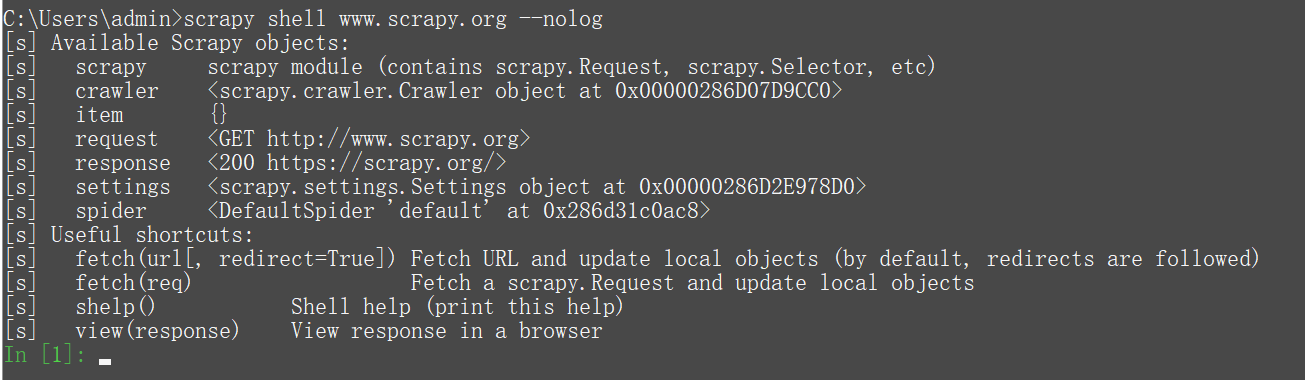
C:\Users\admin>scrapy shell www.scrapy.org --nolog
然后,shell获取URL(使用scrapy下载器)并打印可用对象和有用快捷方式的列表(您会注意到这些行都以 [s] 前缀):
之后我们开始使用对象:
In [1]: response.xpath('//title/text()').get() # 获取网页title Out[1]: 'Scrapy | A Fast and Powerful Scraping and Web Crawling Framework' In [5]: fetch('https://www.osgeo.cn/scrapy/topics/shell.html') # 切换网址 In [6]: response.xpath('//title//text()').get() # 获取网页title Out[6]: 'Scrapy shell — Scrapy 1.7.0 文档' In [7]: request = request.replace(method='post') # 改变request的请求方式为post In [8]: fetch(request) # 从新请求上面的网址 In [9]: response.status # 响应状态码 Out[9]: 405 In [10]: from pprint import pprint # 导入模块pprint In [11]: pprint(response.headers) # 打印请求头 {b'Content-Type': [b'text/html'], b'Date': [b'Sat, 10 Aug 2019 04:08:19 GMT'], b'Server': [b'nginx/1.10.3']} In [12]: pprint(type(response.headers)) # 打印类型 <class 'scrapy.http.headers.Headers'>
从spiders调用shell来检查响应
有时,您希望检查在您的蜘蛛的某个点上正在处理的响应,如果只是检查您期望的响应是否到达那里的话。
这可以通过使用 scrapy.shell.inspect_response 功能。
下面是一个例子,说明如何从您的蜘蛛中命名它:
import scrapy class MySpider(scrapy.Spider): name = "myspider" start_urls = [ "http://example.com", "http://example.org", "http://example.net", ] def parse(self, response): # We want to inspect one specific response. if ".org" in response.url: from scrapy.shell import inspect_response inspect_response(response, self) # Rest of parsing code.
当你运行蜘蛛时,你会得到类似的东西:
2014-01-23 17:48:31-0400 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://example.com> (referer: None) 2014-01-23 17:48:31-0400 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://example.org> (referer: None) [s] Available Scrapy objects: [s] crawler <scrapy.crawler.Crawler object at 0x1e16b50> ... >>> response.url 'http://example.org'
然后,您可以检查提取代码是否工作:
>>> response.xpath('//h1[@class="fn"]') []
不,不是这样的。所以您可以在Web浏览器中打开响应,看看它是否是您期望的响应:
>>> view(response)
True
最后,单击ctrl-d(或在Windows中单击ctrl-z)退出shell并继续爬网:
>>> ^D 2014-01-23 17:50:03-0400 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://example.net> (referer: None) ...
请注意,您不能使用 fetch 这里的快捷方式,因为报废的引擎被shell挡住了。然而,当你离开shell后,蜘蛛会继续在它停止的地方爬行,如上图所示。
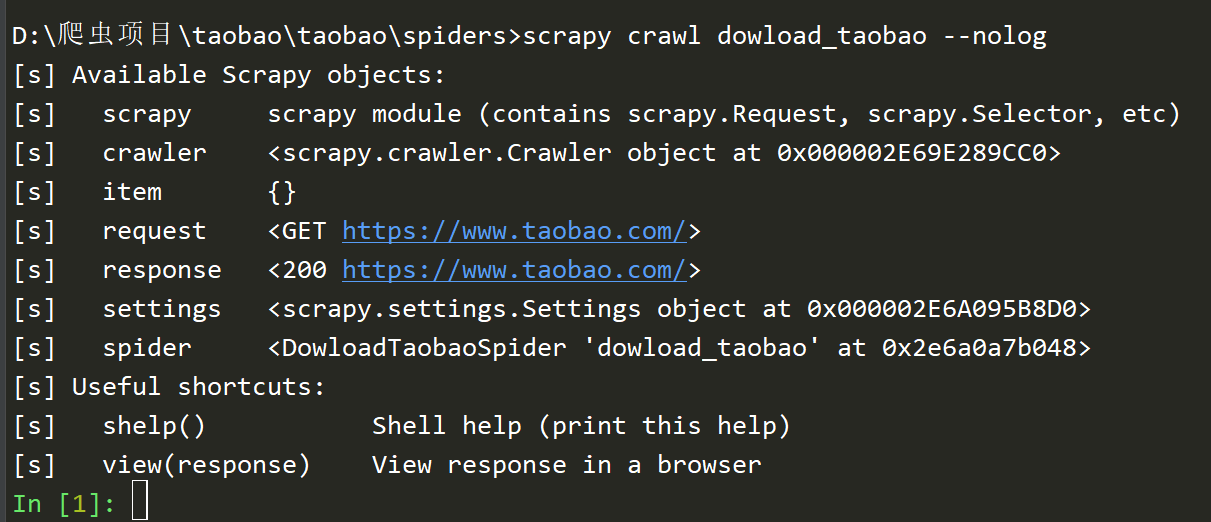
示例:
# -*- coding: utf-8 -*- import scrapy class DowloadTaobaoSpider(scrapy.Spider): name = 'dowload_taobao' allowed_domains = ['www.taobao.com'] start_urls = ['http://www.taobao.com/'] def parse(self, response): if '.com' in response.url: from scrapy.shell import inspect_response inspect_response(response,self)