Selenium浏览器自动化测试框架
selenium简介
介绍
Selenium [1] 是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,Opera等。这个工具的主要功能包括:测试与浏览器的兼容性——测试你的应用程序看是否能够很好得工作在不同浏览器和操作系统之上。测试系统功能——创建回归测试检验软件功能和用户需求。支持自动录制动作和自动生成 .Net、Java、Perl等不同语言的测试脚本。
功能
-
框架底层使用JavaScript模拟真实用户对浏览器进行操作。测试脚本执行时,浏览器自动按照脚本代码做出点击,输入,打开,验证等操作,就像真实用户所做的一样,从终端用户的角度测试应用程序。
-
使浏览器兼容性测试自动化成为可能,尽管在不同的浏览器上依然有细微的差别。
-
使用简单,可使用Java,Python等多种语言编写用例脚本。
优势
Selenium 测试直接在浏览器中运行,就像真实用户所做的一样。Selenium 测试可以在 Windows、Linux 和 Macintosh上的 Internet Explorer、Chrome和 Firefox 中运行。其他测试工具都不能覆盖如此多的平台。使用 Selenium 和在浏览器中运行测试还有很多其他好处。
下面是主要的两大好处:
通过编写模仿用户操作的 Selenium 测试脚本,可以从终端用户的角度来测试应用程序。通过在不同浏览器中运行测试,更容易发现浏览器的不兼容性。Selenium 的核心,也称browser bot,是用 JavaScript 编写的。这使得测试脚本可以在受支持的浏览器中运行。browser bot 负责执行从测试脚本接收到的命令,测试脚本要么是用 HTML 的表布局编写的,要么是使用一种受支持的编程语言编写的。
chromedriver下载:http://chromedriver.storage.googleapis.com/index.html
chromedriver与chrome的对应关系表:https://www.jb51.net/article/151629.htm
基本使用
安装: pip install selenium
from selenium import webdriver browser = webdriver.Chrome(executable_path='chromedriver.exe') # 声明一个浏览器对象 指定使用chromedriver.exe路径 browser.get("https://www.baidu.com") # 打开Chrome input = browser.find_element_by_id("kw") # 通过id定位到input框 input.send_keys("python") # 在输入框内输入python print(browser.current_url) # 打印url print(browser.get_cookies()) # 打印Cookies print(browser.page_source) # 打印网页源代码 browser.close() # 关闭浏览器
获取单节点
from selenium import webdriver browser = webdriver.Chrome() browser.get("https://www.taobao.com") # 找到搜索框 input_id = browser.find_element_by_id("q") # 通过id找 input_name = browser.find_element_by_name("q") # 通过name属性值找 input_css = browser.find_element_by_css_selector("#q") # 根据css选择器找 input_xpath = browser.find_element_by_xpath('//*[@id="q"]') # 根据xpath找 print(input_id,input_name,input_css,input_xpath) browser.close() """ <selenium.webdriver.remote.webelement.WebElement (session="1dfb3c1ac919b0a5ff778cd3bf6db759", element="84b6d58e-04d6-4483-9a3f-f2e116437075")> <selenium.webdriver.remote.webelement.WebElement (session="1dfb3c1ac919b0a5ff778cd3bf6db759", element="84b6d58e-04d6-4483-9a3f-f2e116437075")> <selenium.webdriver.remote.webelement.WebElement (session="1dfb3c1ac919b0a5ff778cd3bf6db759", element="84b6d58e-04d6-4483-9a3f-f2e116437075")> <selenium.webdriver.remote.webelement.WebElement (session="1dfb3c1ac919b0a5ff778cd3bf6db759", element="84b6d58e-04d6-4483-9a3f-f2e116437075")> """ # 其他获取单个节点方法 """ find_element_by_link_text find_element_by_partial_link_text find_element_by_tag_name find_element_by_class_name """ # 通过方法 # find_element(By.ID,"q") # 参数为查找方式和值
获取多节点
from selenium import webdriver browser = webdriver.Chrome() browser.get("https://www.taobao.com") lis = browser.find_elements_by_css_selector(".service-bd li") # 注意是elements多个s print(lis) # 输出为列表 """ [<selenium.webdriver.remote.webelement.WebElement (session="588f61b0d90f7bf199d3f0ede6f9fb99", element="454d656c-1730-410e-891e-210bfdf0d248")>, <selenium.webdriver.remote.webelement.WebElement (session="588f61b0d90f7bf199d3f0ede6f9fb99", element="119177aa-014a-48c1-8bea-8ca9a50b446e")>, <selenium.webdriver.remote.webelement.WebElement (session="588f61b0d90f7bf199d3f0ede6f9fb99", element="974860cf-1218-4ddf-a745-85f86090e188")>, <selenium.webdriver.remote.webelement.WebElement (session="588f61b0d90f7bf199d3f0ede6f9fb99", element="e5877c0c-f4df-4847-9875-1c81d56f21ee")>] """ # 其他获取多个节点方法 """ find_elements_by_id("q") find_elements_by_name("q") find_elements_by_css_selector("#q") find_elements_by_xpath('//*[@id="q"]') find_elements_by_link_text find_elements_by_partial_link_text find_elements_by_tag_name find_elements_by_class_name """ # 通过方法 # find_elements(By.CSS_SELECTOR,".service-bd li") # 参数为查找方式和值
节点交互
import time from selenium import webdriver browser = webdriver.Chrome() browser.get("https://www.taobao.com") """ selenium可以驱动浏览器来执行一些动作: 输入文字用send_keys() 清空文字用clear() 点击按钮用click() """ input = browser.find_element_by_id("q") input.send_keys("iPhone") #在搜索框输入iPhone input.clear() # 清空搜索框的文字 time.sleep(2) input.send_keys("iPad") # 在搜索框输入iPad button = browser.find_element_by_class_name("btn-search") # 获取点击按钮 button.click() # 点击搜索
动作链
from selenium import webdriver from selenium.webdriver import ActionChains # 引入动作链 browser = webdriver.Chrome() url = "https://www.runoob.com/try/try.php?filename=jqueryui-api-droppable" browser.get(url) browser.switch_to.frame("iframeResult") # 切换到元素所在的frame[框架] """ 可以传入id、name、index以及selenium的WebElement对象,index从0开始 """ source = browser.find_element_by_css_selector("#draggable") # 找到被拖拽对象 target = browser.find_element_by_css_selector("#droppable") # 找到目标 actions = ActionChains(browser) # 声明actions对象 actions.drag_and_drop(source,target) # 拖拽元素的起点和终点 actions.perform() # 执行动作
action.click_and_hold() # 点击且长按,更多方法查看官方文档
执行JavaScript代码
from selenium import webdriver browser = webdriver.Chrome() url = "https://www.zhihu.com/explore" browser.get(url) browser.execute_script("window.scrollTo(0,document.body.scrollHeight)") # 将进度条下拉到最底部 browser.execute_script("alert('hello word')") # 弹出alert提示窗
获取节点信息
from selenium import webdriver browser = webdriver.Chrome() url = "https://www.zhihu.com/explore" browser.get(url) """ WebElement常用属性: get_attribute 获取属性值 text 获取文本值 id 获取节点id location 获取节点在页面中的相对位置 tag_name 获取标签名称 size 获取节点大小(宽和高) """ # 获取属性 logo = browser.find_element_by_id("zh-top-link-logo") # 获取logo节点 print(logo) # 返回值为WebElement对象 logo_class = logo.get_attribute("class") # 获取zh-top-link-logo节点的class属性值 print(logo_class) # 获取文本值 text_Ele = browser.find_element_by_css_selector(".question_link") # 通过css选择器获取文本内容所在的标签 text = text_Ele.text # 取出标签内的文本内容 print(text) # 获取ID 位置 标签名和大小 test = browser.find_element_by_class_name("zu-top-add-question") print(test.id) # 0bfe7ae6-ebd9-499a-8f4e-35ae34776687 print(test.location) # {'x': 759, 'y': 7} print(test.tag_name) # button print(test.size) # {'height': 32, 'width': 66}
切换frame
from selenium import webdriver browser = webdriver.Chrome() url = "https://www.runoob.com/try/try.php?filename=jqueryui-api-droppable" browser.get(url) """ 网页中有一种节点叫做iframe,也就是子Frame,相当于页面的子页面, 他的结构和外部网页的结构完全一致。 selenium打开页面后,他默认是在父级Frame里面操作, 而此时如果页面中还有子Frame,他是不能获取到子Frame里面的节点的, 这时候就需要使用switch_to.frame()方法来切换Frame。 """ browser.switch_to.frame("iframeResult") logo = browser.find_elements_by_class_name("logo") print(logo) # [<selenium.webdriver.remote.webelement.WebElement (session="1ccb11403013c749ce9fceda50a00975", element="88e5924e-d655-44c3-a905-8af1947b9d86")>]
延时等待
---------------------------隐式等待------------------------- from selenium import webdriver browser = webdriver.Chrome() # 隐式等待 browser.implicitly_wait(2) # 设定等待时间 url = "https://www.zhihu.com/explore" browser.get(url) input = browser.find_element_by_class_name("aaa") print(input) # 报错信息 """ raise exception_class(message, screen, stacktrace) selenium.common.exceptions.NoSuchElementException: Message: no such element: Unable to locate element: {"method":"css selector","selector":".aaa"} (Session info: chrome=75.0.3770.142) """ """ 如果selenium没有在DOM中找到节点,将继续等待,超出设定事件后,则抛出找不到节点的异常。 当查找节点而节点并没有立即出现的时候,隐式等待将等待一段时间在查找DOM,默认时间是0 """ --------------------------显式等待------------------------ # 显示等待 from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC browser = webdriver.Chrome() browser.get("https://www.taobao.com/") wait = WebDriverWait(browser,2) input = wait.until(EC.presence_of_element_located((By.ID,"q"))) button = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR,".btn-search"))) print(input,button) # 等待条件 # EC.presence_of_element_located 节点出现 # EC.element_to_be_clickable 可点击 # 更多等待条件查看260页 """ 引入WebDriverWait对象指定最长等待时间,调用它的until方法, 传入要等待的条件expected_conditions,比如这里传入例如presence_of_element_located 这个条件,代表节点出现的意思,其参数是节点的定位元组,也就是ID为q的搜索框。 这样可以做到的效果就是,在10秒内如果ID为q的节点(即搜索框)成功加载出来,就返回该节点, 如果10秒还没有加载出来,就抛出异常。 """ """ 异常: TimeoutException """ """ 指定要查找的节点,然后指定一个最长等待时间,如果在规定时间内加载出来了这个节点, 就返回查找的节点,如果到了规定时间依然没有加载出该节点,则抛出【超时】异常 """
前进和后退
import time from selenium import webdriver browser = webdriver.Chrome() browser.get("https://www.baidu.com") browser.get("https://www.taobao.com") browser.get("https://www.jd.com") browser.back() # 后退 time.sleep(2) browser.forward() # 前进 browser.close() # 关闭浏览器 # 连续访问三个页面
cookies
from selenium import webdriver browser = webdriver.Chrome() browser.get("https://www.zhihu.com/explore") cookies = browser.get_cookies() # 获取cookies print(cookies) browser.add_cookie({"name":"name","domain":"www.zhihu.com","vlue":"germey"}) browser.delete_all_cookies() # 删除所有cookies
选项卡管理
import time from selenium import webdriver browser = webdriver.Chrome() browser.get("https://www.baidu.com") browser.execute_script("window.open()") print(browser.window_handles) # ['CDwindow-7106D94FF002752ADF198B986343E31D', 'CDwindow-B669BA9559DBB78D8D6EC9C5AA699C40'] browser.switch_to.window(browser.window_handles[1]) browser.get("https://www.taobao.com") time.sleep(1) browser.switch_to.window(browser.window_handles[0]) browser.get("https://jd.com") """ 1、打开百度网页 2、新开一个选项卡,调用execute_script()方法传入JavaScript语法window.open() 3、切换到新打开的选项卡,调用window_handles属性获取当前开启的所有选项卡,返回的是选项卡的代号列表, 要想切换选项卡只需要调用switch_to.window()方法,这里我们将第二个选项卡代号传入, 即跳转到第二个选项卡,在第二个选项卡里打开新页面https://www.taobao.com,然后切换回第一个选项卡打开jd页面 """
异常处理
from selenium import webdriver browser = webdriver.Chrome() browser.get("https://www.baidu.com") try: browser.find_element_by_id("hello") except Exception as e: print(e) # 打印错误信息 Exception捕获所有错误信息赋给e finally: browser.close() """ 在使用selenium的过程中,难免遇到一些异常,例如超时、节点未找到错误, 一旦出现此类错误,程序便不会在继续运行了,这里我们使用try except语句来捕获各种异常 """
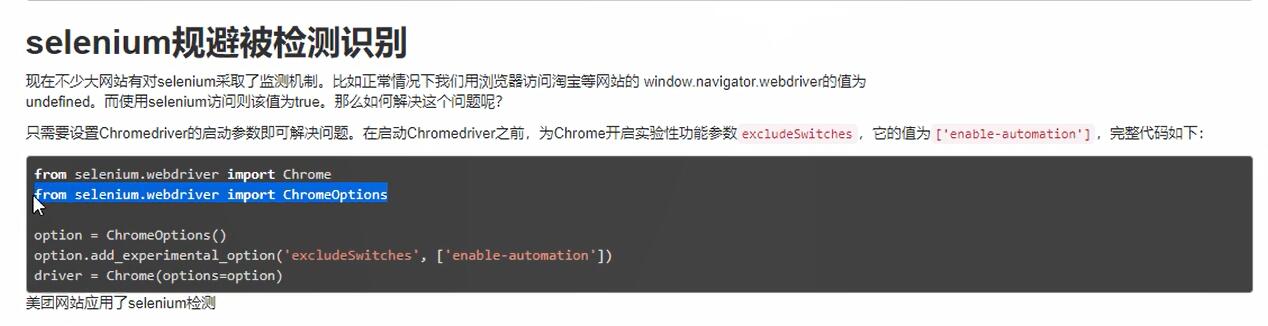
选项卡切换
import time from selenium import webdriver from selenium.webdriver import ChromeOptions option = ChromeOptions() browser = webdriver.Chrome(executable_path='D:\chromedriver.exe',options=option) # 声明一个浏览器对象 option.add_experimental_option('excludeSwitches', ['enable-automation']) browser.get("https://www.baidu.com") # 打开Chrome input = browser.find_element_by_id("kw") # 通过id定位到input框 input.send_keys("爱奇艺") # 在输入框内输入python browser.find_element_by_id("su").click() time.sleep(3) browser.find_element_by_xpath('//*[@id="1"]/h3').click() time.sleep(10) browser.switch_to_window(browser.window_handles[1]) # 切换到新打开的选项卡定位爱奇艺的搜索框 search = browser.find_element_by_xpath("//input[@class='search-box-input']").send_keys("青春有你") browser.close() # 关闭浏览器
无头浏览器
from selenium import webdriver from selenium.webdriver.chrome.options import Options # 创建chrome参数对象 opt = Options() # 把chrome设置成无界面模式,不论windows还是linux都可以,自动适配对应参数 opt.add_argument('--headless') # 创建chrome无界面对象 driver = webdriver.Chrome(options=opt) driver.get("http://www.baidu.com") print(driver.page_source)

