消息队列rabbitmq
消息队列
工作流程
消息队列一般有三个角色:
队列服务端
队列生产者
队列消费者
消息队列工作流程就如同一个流水线,有产品加工,一个输送带,一个打包产品
输送带就是 不停运转的消息队列服务端
加工产品的就是 队列生产者
在传输带结尾打包产品的 就是队列消费者
队列产品
RabbitMQ Erlang编写的消息队列产品,企业级消息队列软件,支持消息负载均衡,数据持久化等。 ZeroMQ saltstack软件使用此消息,速度最快。 Redis key-value的系统,也支持队列数据结构,轻量级消息队列 Kafka 由Scala编写,目标是为处理实时数据提供一个统一、高通量、低等待的平台
消息队列的作用
1)程序解耦 允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束。 2)冗余: 消息队列把数据进行持久化直到它们已经被完全处理,通过这一方式规避了数据丢失风险。 许多消息队列所采用的"插入-获取-删除"范式中,在把一个消息从队列中删除之前,需要你的处理系统明确的指出该消息已经被处理完毕,从而确保你的数据被安全的保存直到你使用完毕。 3)峰值处理能力: (大白话,就是本来公司业务只需要5台机器,但是临时的秒杀活动,5台机器肯定受不了这个压力,我们又不可能将整体服务器架构提升到10台,那在秒杀活动后,机器不就浪费了吗?因此引入消息队列) 在访问量剧增的情况下,应用仍然需要继续发挥作用,但是这样的突发流量并不常见。 如果为以能处理这类峰值访问为标准来投入资源随时待命无疑是巨大的浪费。 使用消息队列能够使关键组件顶住突发的访问压力,而不会因为突发的超负荷的请求而完全崩溃。 4)可恢复性: 系统的一部分组件失效时,不会影响到整个系统。 消息队列降低了进程间的耦合度,所以即使一个处理消息的进程挂掉,加入队列中的消息仍然可以在系统恢复后被处理。 5)顺序保证: 在大多使用场景下,数据处理的顺序都很重要。 大部分消息队列本来就是排序的,并且能保证数据会按照特定的顺序来处理。(Kafka保证一个Partition内的消息的有序性) 6)缓冲: 有助于控制和优化数据流经过系统的速度,解决生产消息和消费消息的处理速度不一致的情况。 7)异步通信: 很多时候,用户不想也不需要立即处理消息。比如发红包,发短信等流程。 消息队列提供了异步处理机制,允许用户把一个消息放入队列,但并不立即处理它。想向队列中放入多少消息就放多少,然后在需要的时候再去处理它们。
你了解的消息队列
生活里的消息队列,如同邮局的邮箱,
如果没邮箱的话,
邮件必须找到邮件那个人,递给他,才玩完成,那这个任务会处理的很麻烦,很慢,效率很低
但是如果有了邮箱,
邮件直接丢给邮箱,用户只需要去邮箱里面去找,有没有邮件,有就拿走,没有就下次再来,这样可以极大的提升邮件收发效率!
rabbitmq是一个消息代理,它接收和转发消息,可以理解为是生活的邮局。
你可以将邮件放在邮箱里,你可以确定有邮递员会发送邮件给收件人。
概括:
rabbitmq是接收,存储,转发数据的。
官方教程:http://www.rabbitmq.com/tutorials/tutorial-one-python.html
消息(Message)是指在应用间传送的数据。消息可以非常简单,比如只包含文本字符串,也可以更复杂,可能包含嵌入对象。
消息队列(Message Queue)是一种应用间的通信方式,消息发送后可以立即返回,由消息系统来确保消息的可靠传递。消息发布者只管把消息发布到 MQ 中而不用管谁来取,消息使用者只管从 MQ 中取消息而不管是谁发布的。这样发布者和使用者都不用知道对方的存在。
公司在什么情况下会用消息队列?
电商订单
想必同学们都点过外卖,点击下单后的业务逻辑可能包括:检查库存、生成单据、发红包、短信通知等,如果这些业务同步执行,完成下单率会非常低,如发红包,短信通知等不必要的流程,异步执行即可。
此时使用MQ,可以在核心流程(扣减库存、生成订单记录)等完成后发送消息到MQ,快速结束本次流程。消费者拉取MQ消息时,发现红包、短信等消息时,再进行处理。
场景:双11是购物狂节,用户下单后,订单系统需要通知库存系统,传统的做法就是订单系统调用库存系统的接口

这种做法有一个缺点:
-
当库存系统出现故障时,订单就会失败。(这样马云将少赚好多好多钱钱。。。。)
-
订单系统和库存系统高耦合.
引入消息队列:

订单系统:用户下单后,订单系统完成持久化处理,将消息写入消息队列,返回用户订单下单成功。
库存系统:订阅下单的消息,获取下单消息,进行库操作。 就算库存系统出现故障,消息队列也能保证消息的可靠投递,不会导致消息丢失(马云这下高兴了,钞票快快的来呀~~).
秒杀活动
流量削峰一般在秒杀活动中应用广泛 场景:秒杀活动,一般会因为流量过大,导致应用挂掉,为了解决这个问题,一般在应用前端加入消息队列。
作用:
1.可以控制活动人数,超过此一定阀值的订单直接丢弃(怪不得我一次秒杀都没抢到过。。。。。wtf???)
2.可以缓解短时间的高流量压垮应用(应用程序按自己的最大处理能力获取订单)
3.用户的请求,服务器接收到之后,写入消息队列,超过定义的阈值就直接丢弃请求,或者跳转错误页面。
4.业务系统取出队列中的消息,再做后续处理。

rabbitMQ安装
rabbitmq的安装使用 1.通过阿里云的yum源,在epel源中有这个rabbitmq yum install rabbitmq-server erlang -y 2.启动rabbitmq-server systemctl start rabbitmq-server 如果 rabbitmq-server启动不了,就改一下 hosts文件,写入 127.0.0.1 和你自己的主机名 3.开启后台管理界面 rabbitmq-plugins enable rabbitmq_management 4.创建rabbitmq的账号密码 rabbitmqctl add_user henry 123456 5.设置用户为管理员 sudo rabbitmqctl set_user_tags henry administrator 6.设置用户有权限访问所有队列 #语法:
对何种资源具有配置、写、读的权限通过正则表达式来匹配,具体命令如下:
rabbitmqctl set_permissions [-p <vhostpath>] <user> <conf> <write> <read> rabbitmqctl set_permissions -p "/" henry ".*" ".*" ".*" 7.重启rabbitmq服务端,让用户生效 systemctl restart rabbitmq-server 8.访问web管理界面,登录,查看队列信息 http://192.168.16.142:15672/#/queues 9.用python操作rabbitmq,实现生产消费者模型 1.安装pika模块,模块版本需要指定,因为代码参数发生了变化 pip3 install -i https://pypi.douban.com/simple pika==0.13.1
rabbitmq相关命令


// 新建用户 rabbitmqctl add_user {用户名} {密码} // 设置权限 rabbitmqctl set_user_tags {用户名} {权限} // 查看用户列表 rabbitmqctl list_users // 为用户授权 添加 Virtual Hosts : rabbitmqctl add_vhost <vhost> // 删除用户 rabbitmqctl delete_user Username // 修改用户的密码 rabbitmqctl change_password Username Newpassword // 删除 Virtual Hosts : rabbitmqctl delete_vhost <vhost> // 添加 Users : rabbitmqctl add_user <username> <password> rabbitmqctl set_user_tags <username> <tag> ... rabbitmqctl set_permissions [-p <vhost>] <user> <conf> <write> <read> // 删除 Users : delete_user <username> // 使用户user1具有vhost1这个virtual host中所有资源的配置、写、读权限以便管理其中的资源 rabbitmqctl set_permissions -p vhost1 user1 '.*' '.*' '.*' // 查看权限 rabbitmqctl list_user_permissions user1 rabbitmqctl list_permissions -p vhost1 // 清除权限 rabbitmqctl clear_permissions [-p VHostPath] User //清空队列步骤 rabbitmqctl reset 需要提前关闭应用rabbitmqctl stop_app , 然后再清空队列,启动应用 rabbitmqctl start_app 此时查看队列rabbitmqctl list_queues 查看所有的exchange: rabbitmqctl list_exchanges 查看所有的queue: rabbitmqctl list_queues 查看所有的用户: rabbitmqctl list_users 查看所有的绑定(exchange和queue的绑定信息): rabbitmqctl list_bindings 查看消息确认信息: rabbitmqctl list_queues name messages_ready messages_unacknowledged 查看RabbitMQ状态,包括版本号等信息:rabbitmqctl status #开启web界面rabbitmq rabbitmq-plugins enable rabbitmq_management #访问web界面 http://server-name:15672/
RabbitMQ组件解释
AMQP AMQP协议是一个高级抽象层消息通信协议,RabbitMQ是AMQP协议的实现。它主要包括以下组件: 1.Server(broker): 接受客户端连接,实现AMQP消息队列和路由功能的进程。 2.Virtual Host:其实是一个虚拟概念,类似于权限控制组,一个Virtual Host里面可以有若干个Exchange和Queue,但是权限控制的最小粒度是Virtual Host 3.Exchange:接受生产者发送的消息,并根据Binding规则将消息路由给服务器中的队列。ExchangeType决定了Exchange路由消息的行为,例如,在RabbitMQ中,ExchangeType有direct、Fanout和Topic三种,不同类型的Exchange路由的行为是不一样的。 4.Message Queue:消息队列,用于存储还未被消费者消费的消息。 5.Message: 由Header和Body组成,Header是由生产者添加的各种属性的集合,包括Message是否被持久化、由哪个Message Queue接受、优先级是多少等。而Body是真正需要传输的APP数据。 6.Binding:Binding联系了Exchange与Message Queue。Exchange在与多个Message Queue发生Binding后会生成一张路由表,路由表中存储着Message Queue所需消息的限制条件即Binding Key。当Exchange收到Message时会解析其Header得到Routing Key,Exchange根据Routing Key与Exchange Type将Message路由到Message Queue。Binding Key由Consumer在Binding Exchange与Message Queue时指定,而Routing Key由Producer发送Message时指定,两者的匹配方式由Exchange Type决定。 7.Connection:连接,对于RabbitMQ而言,其实就是一个位于客户端和Broker之间的TCP连接。 8.Channel:信道,仅仅创建了客户端到Broker之间的连接后,客户端还是不能发送消息的。需要为每一个Connection创建Channel,AMQP协议规定只有通过Channel才能执行AMQP的命令。一个Connection可以包含多个Channel。之所以需要Channel,是因为TCP连接的建立和释放都是十分昂贵的,如果一个客户端每一个线程都需要与Broker交互,如果每一个线程都建立一个TCP连接,暂且不考虑TCP连接是否浪费,就算操作系统也无法承受每秒建立如此多的TCP连接。RabbitMQ建议客户端线程之间不要共用Channel,至少要保证共用Channel的线程发送消息必须是串行的,但是建议尽量共用Connection。 9.Command:AMQP的命令,客户端通过Command完成与AMQP服务器的交互来实现自身的逻辑。例如在RabbitMQ中,客户端可以通过publish命令发送消息,txSelect开启一个事务,txCommit提交一个事务。
消息队列应用场景
生产-消费者模型
P 是生产者
C 是消费者
中间hello是消息队列
可以有多个P、多个C
P发送消息给hello队列,C消费者从队列中获取消息,默认轮询方式

生产者send.py
我们的第一个程序send.py将向队列发送一条消息。我们需要做的第一件事是建立与RabbitMQ服务器的连接。
#!/usr/bin/env python3 import pika # 创建凭证,使用rabbitmq用户密码登录 # 去邮局取邮件,必须得验证身份 credentials = pika.PlainCredentials("henry","123456") # 新建连接,这里localhost可以更换为服务器ip # 找到这个邮局,等于连接上服务器 connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.16.142',credentials=credentials)) # 创建频道 # 建造一个大邮箱,隶属于这家邮局的邮箱,就是个连接 channel = connection.channel() # 声明一个队列,用于接收消息,队列名字叫“水许传” channel.queue_declare(queue='水许传') # 注意在rabbitmq中,消息想要发送给队列,必须经过交换(exchange),初学可以使用空字符串交换(exchange=''),它允许我们精确的指定发送给哪个队列(routing_key=''),参数body值发送的数据 channel.basic_publish(exchange='', routing_key='水许传', body='武大郎出摊卖烧饼了') print("已经发送了消息") # 程序退出前,确保刷新网络缓冲以及消息发送给rabbitmq,需要关闭本次连接 connection.close()

可以同时存在多个接受者,等待接收队列的消息,默认是轮训方式分配消息
接受者receive.py,可以运行多次,运行多个消费者
import pika # 建立与rabbitmq的连接 credentials = pika.PlainCredentials("henry","123456") connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.16.142',credentials=credentials)) channel = connection.channel() channel.queue_declare(queue="水许传") def callbak(ch,method,properties,body): print("消费者接收到了数据:%r"%body.decode("utf8")) # 有消息来临,立即执行callbak,没有消息则夯住,等待消息 # 老百姓开始去邮箱取邮件啦,队列名字是水许传 channel.basic_consume(callbak,queue="水许传",no_ack=True) # 开始消费,接收消息 channel.start_consuming()
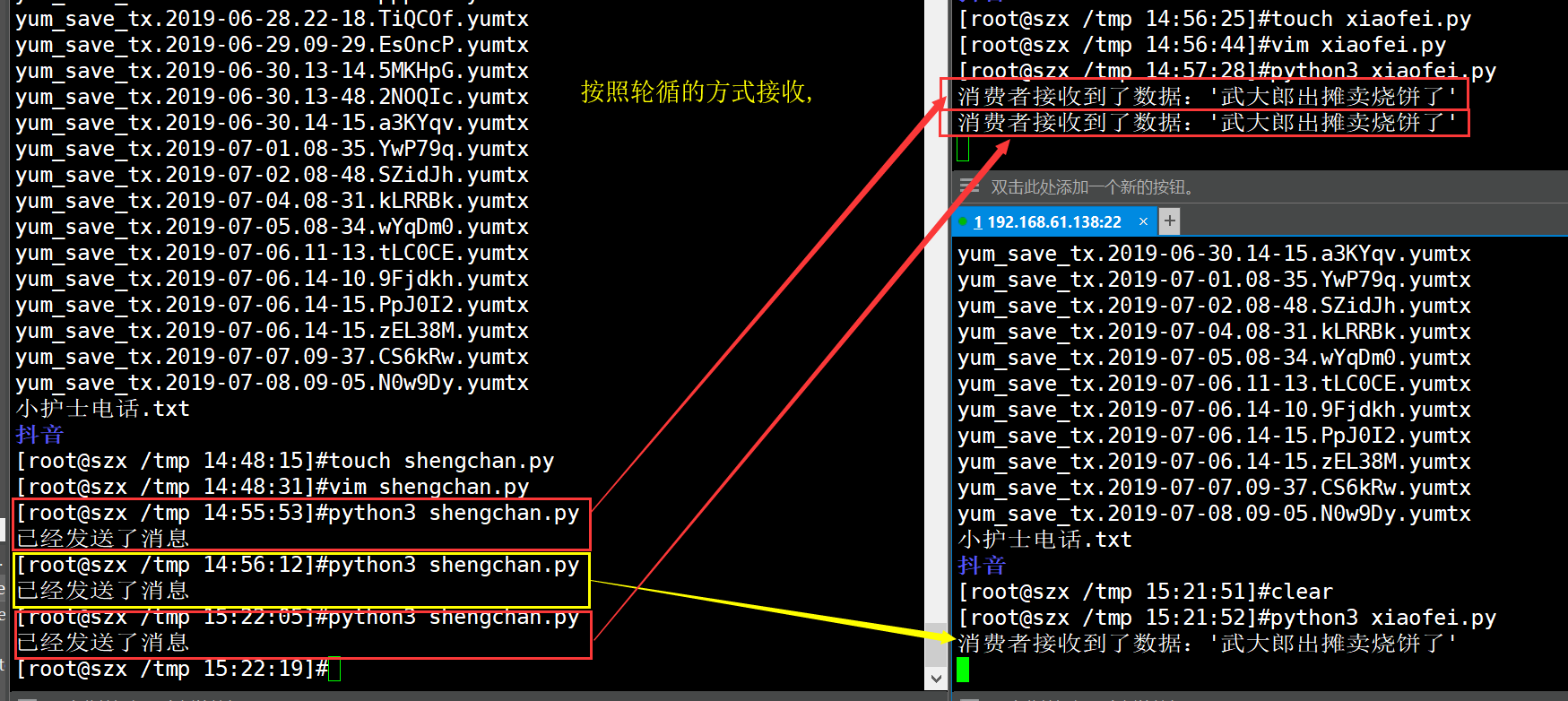
生产者向消息队列中发送一条消息

消费者从消息队列中取走消息
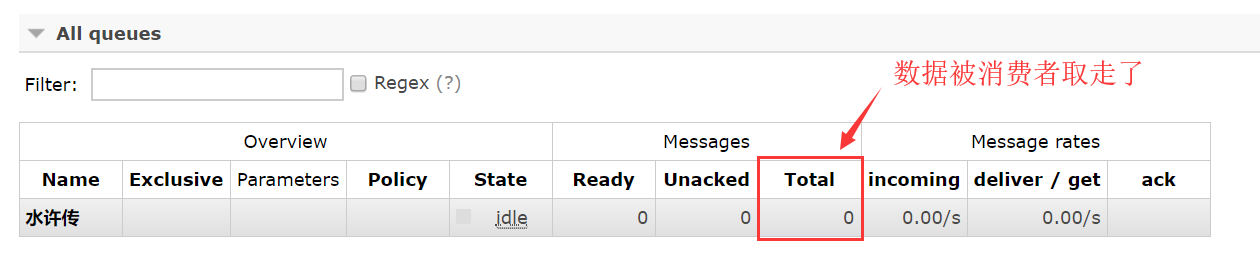
默认情况下,生产者发送数据给队列,消费者取出消息后,数据将被清除。
特殊情况,如果消费者处理过程中,出现错误,数据处理没有完成,那么这段数据将从队列丢失
为了保证消息发送的可靠性,不丢失消息,使消息持久化了。同时为了防止接收端在处理消息时down掉,只有在消息处理完成后才发送ack消息。
rabbitmq消息确认之ack
no-ack机制
不确认机制也就是说每次消费者接收到数据后,不管是否处理完毕,rabbitmq-server都会把这个消息标记完成,从队列中删除
没有确认机制的消息队列是数据不安全的
ACK机制
ACK机制用于保证消费者如果拿了队列的消息,客户端处理时出错了,那么队列中仍然还存在这个消息,提供下一位消费者继续取
机制流程:
1.生产者无须变动,发送消息 2.消费者如果no_ack=True啊,数据消费后如果出错就会丢失 反之no_ack=False,数据消费如果出错,数据也不会丢失 3.ack机制在消费者代码中演示
生产者.py 只负责发送数据即可,无须变动
#!/usr/bin/env python3 import pika # 创建凭证,使用rabbitmq用户密码登录 # 去邮局取邮件,必须得验证身份 credentials = pika.PlainCredentials("henry","123456") # 新建连接,这里localhost可以更换为服务器ip # 找到这个邮局,等于连接上服务器 connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.16.142',credentials=credentials)) # 创建频道 # 建造一个大邮箱,隶属于这家邮局的邮箱,就是个连接 channel = connection.channel() # 新建一个hello队列,用于接收消息 # 这个邮箱可以收发各个班级的邮件,通过 channel.queue_declare(queue='西游记') # 注意在rabbitmq中,消息想要发送给队列,必须经过交换(exchange),初学可以使用空字符串交换(exchange=''),它允许我们精确的指定发送给哪个队列(routing_key=''),参数body值发送的数据 channel.basic_publish(exchange='', routing_key='西游记', body='大师兄,师傅被蔡许坤抓走了') print("已经发送了消息") # 程序退出前,确保刷新网络缓冲以及消息发送给rabbitmq,需要关闭本次连接 connection.close()
消费者.py给与ack回复
拿到消息必须给rabbitmq服务端回复ack信息,否则消息不会被删除,防止客户端出错,数据丢失
import pika credentials = pika.PlainCredentials("selfju","cxk") connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.16.142',credentials=credentials)) channel = connection.channel() # 声明一个队列(创建一个队列) channel.queue_declare(queue='西游记') def callback(ch, method, properties, body): print("消费者接受到了任务: %r" % body.decode("utf-8")) # int('asdfasdf') 模拟处理消息的时候发生了错误 # 我告诉rabbitmq服务端,我已经取走了消息 # 回复方式在这 ch.basic_ack(delivery_tag=method.delivery_tag) # 关闭no_ack,代表给与服务端ack回复,确认给与回复 channel.basic_consume(callback,queue='西游记',no_ack=False) channel.start_consuming()
消息持久化
演示 1.执行生产者,向队列写入数据,产生一个新队列queue 2.重启服务端,队列丢失 3.开启生产者数据持久化后,重启rabbitmq,队列不丢失 4.依旧可以读取数据
消息的可靠性是RabbitMQ的一大特色,那么RabbitMQ是如何保证消息可靠性的呢——消息持久化。 为了保证RabbitMQ在退出或者crash等异常情况下数据没有丢失,需要将queue,exchange和Message都持久化。
支持持久化的队列和消息
生产者:
import pika # 有密码 credentials = pika.PlainCredentials("selfju","cxk") connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.16.142',credentials=credentials)) channel = connection.channel() # 声明一个队列(创建一个队列) # 默认此队列不支持持久化,如果服务挂掉,数据丢失 # durable=True 开启持久化,必须新开启一个队列,原本的队列已经不支持持久化了 ''' 实现rabbitmq持久化条件 delivery_mode=2 使用durable=True声明queue是持久化 ''' channel.queue_declare(queue='LOL',durable=True) channel.basic_publish(exchange='', routing_key='LOL', # 消息队列名称 body='我用双手成就你的梦想', # 支持数据持久化 properties=pika.BasicProperties( delivery_mode=2,#代表消息是持久的 2 ) ) connection.close()
消费者:
import pika credentials = pika.PlainCredentials("selfju","cxk") connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.16.142',credentials=credentials)) channel = connection.channel() # 确保队列持久化 channel.queue_declare(queue='LOL',durable=True) ''' 必须确保给与服务端消息回复,代表我已经消费了数据,否则数据一直持久化,不会消失 ''' def callback(ch, method, properties, body): print("消费者接受到了任务: %r" % body.decode("utf-8")) # 模拟代码报错 # int('asdfasdf') # 此处报错,没有给予回复,保证客户端挂掉,数据不丢失 # 告诉服务端,我已经取走了数据,否则数据一直存在 ch.basic_ack(delivery_tag=method.delivery_tag) # 关闭no_ack,代表给与回复确认 channel.basic_consume(callback,queue='LOL',no_ack=False) channel.start_consuming()
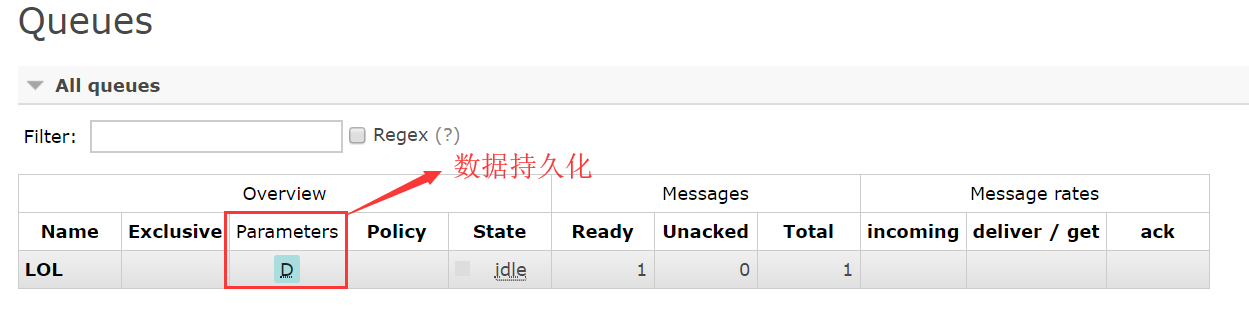
没有持久化的消息队列中的数据会消失;
消息队列持久化后即使生产者的服务器挂掉,重启后消息队列中的数据也不会消失;

