redis之哨兵集群
一、主从复制背景问题
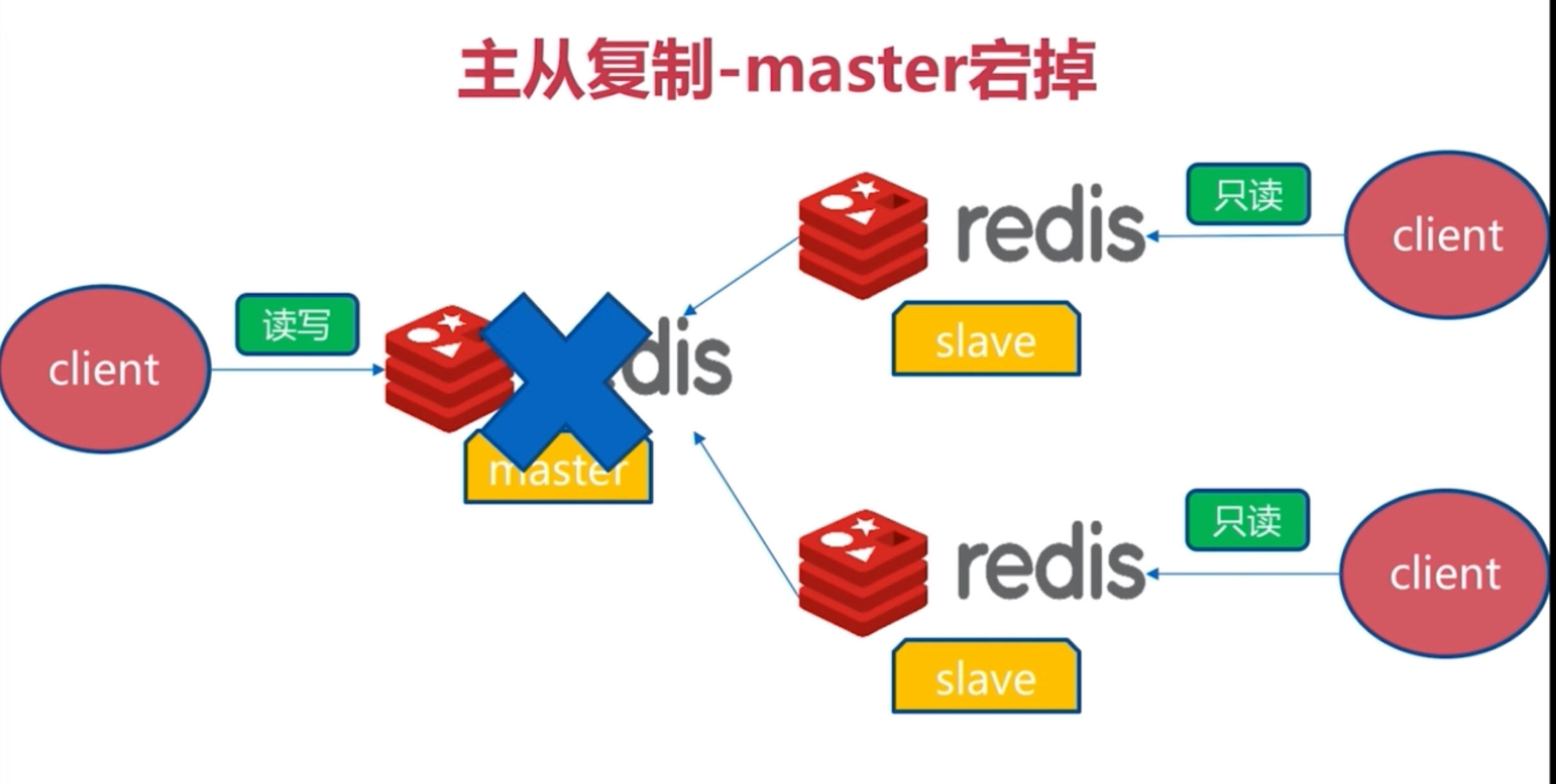
Redis主从复制可将主节点数据同步给从节点,从节点此时有两个作用:
- 一旦主节点宕机,从节点作为主节点的备份可以随时顶上来。
- 扩展主节点的读能力,分担主节点读压力。
但是问题是:
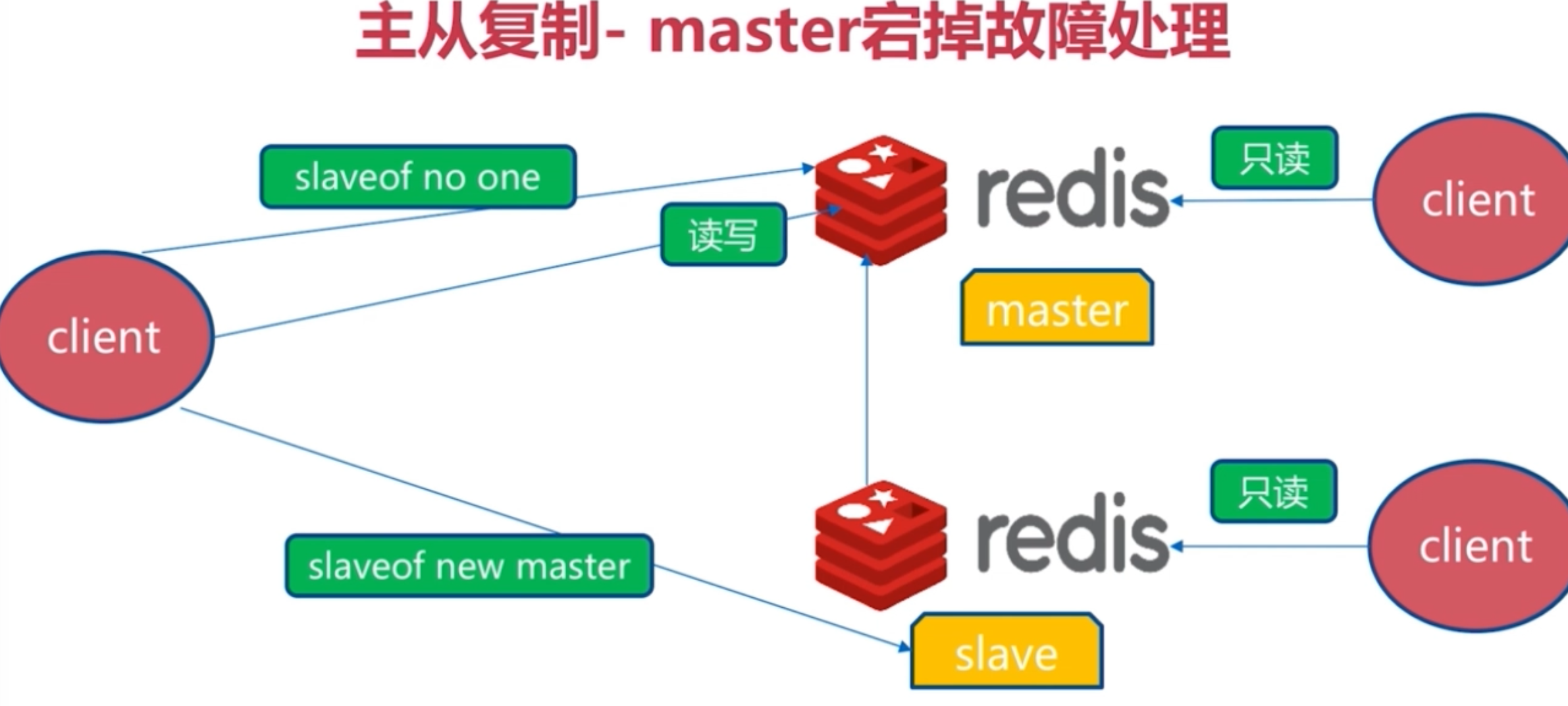
- 一旦主节点宕机,从节点上位,那么需要人为修改所有应用方的主节点地址(改为新的master地址),还需要命令所有从节点复制新的主节点
那么这个问题,redis-sentinel就可以解决了
二、Redis-Sentinel
Redis-Sentinel是redis官方推荐的高可用性解决方案, 当用redis作master-slave的高可用时,如果master本身宕机,redis本身或者客户端都没有实现主从切换的功能。 而redis-sentinel就是一个独立运行的进程,用于监控多个master-slave集群, 自动发现master宕机,进行自动切换slave > master。
三、Sentinel工作方式


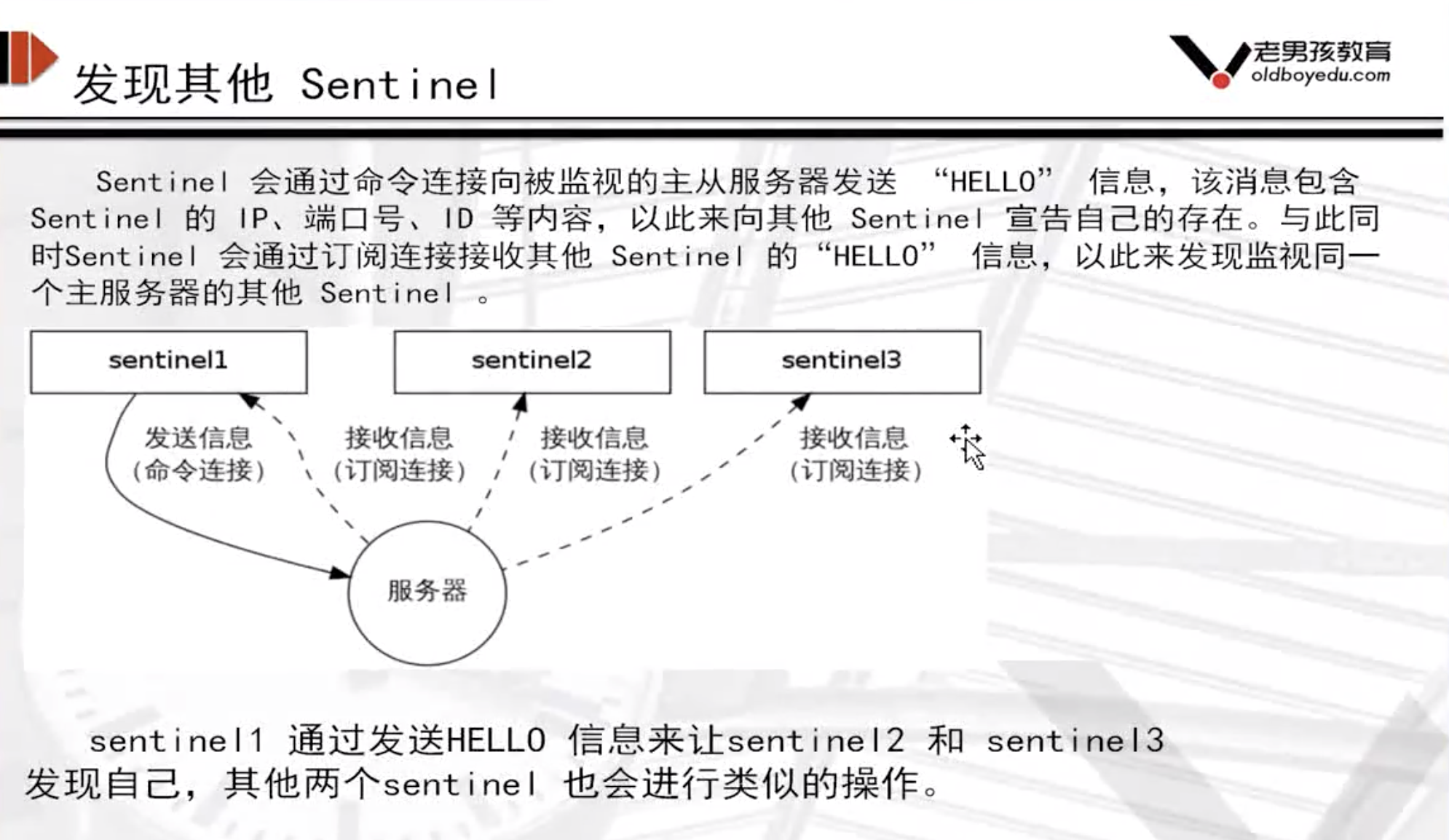
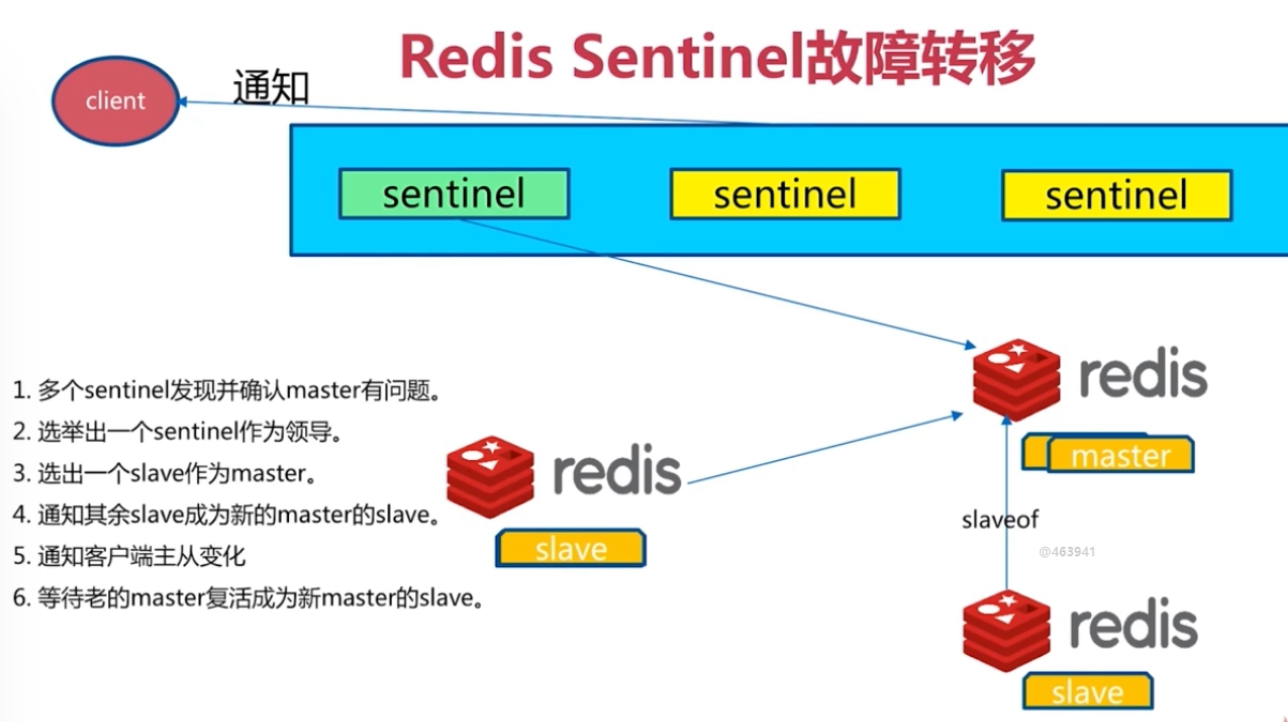
每个Sentinel以每秒钟一次的频率向它所知的Master,Slave以及其他 Sentinel 实例发送一个 PING 命令 如果一个实例(instance)距离最后一次有效回复 PING 命令的时间超过 down-after-milliseconds 选项所指定的值, 则这个实例会被 Sentinel 标记为主观下线。 如果一个Master被标记为主观下线,则正在监视这个Master的所有 Sentinel 要以每秒一次的频率确认Master的确进入了主观下线状态。 当有足够数量的 Sentinel(大于等于配置文件指定的值)在指定的时间范围内确认Master的确进入了主观下线状态, 则Master会被标记为客观下线 在一般情况下, 每个 Sentinel 会以每 10 秒一次的频率向它已知的所有Master,Slave发送 INFO 命令 当Master被 Sentinel 标记为客观下线时,Sentinel 向下线的 Master 的所有 Slave 发送 INFO 命令的频率会从 10 秒一次改为每秒一次 若没有足够数量的 Sentinel 同意 Master 已经下线, Master 的客观下线状态就会被移除。 若 Master 重新向 Sentinel 的 PING 命令返回有效回复, Master 的主观下线状态就会被移除。 主观下线和客观下线 主观下线:Subjectively Down,简称 SDOWN,指的是当前 Sentinel 实例对某个redis服务器做出的下线判断。 客观下线:Objectively Down, 简称 ODOWN,指的是多个 Sentinel 实例在对Master Server做出 SDOWN 判断,并且通过 SENTINEL is-master-down-by-addr 命令互相交流之后,得出的Master Server下线判断,然后开启failover. SDOWN适合于Master和Slave,只要一个 Sentinel 发现Master进入了ODOWN, 这个 Sentinel 就可能会被其他 Sentinel 推选出, 并对下线的主服务器执行自动故障迁移操作。 ODOWN只适用于Master,对于Slave的 Redis 实例,Sentinel 在将它们判断为下线前不需要进行协商, 所以Slave的 Sentinel 永远不会达到ODOWN。
四、主从复制架构
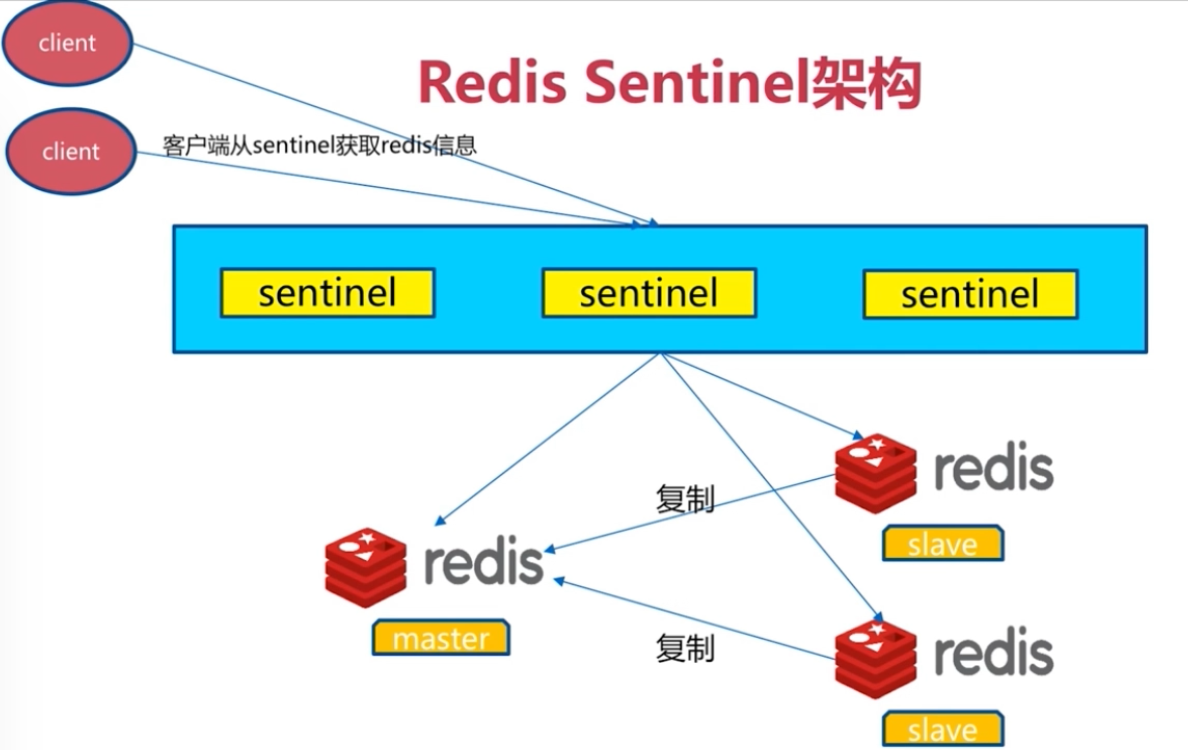
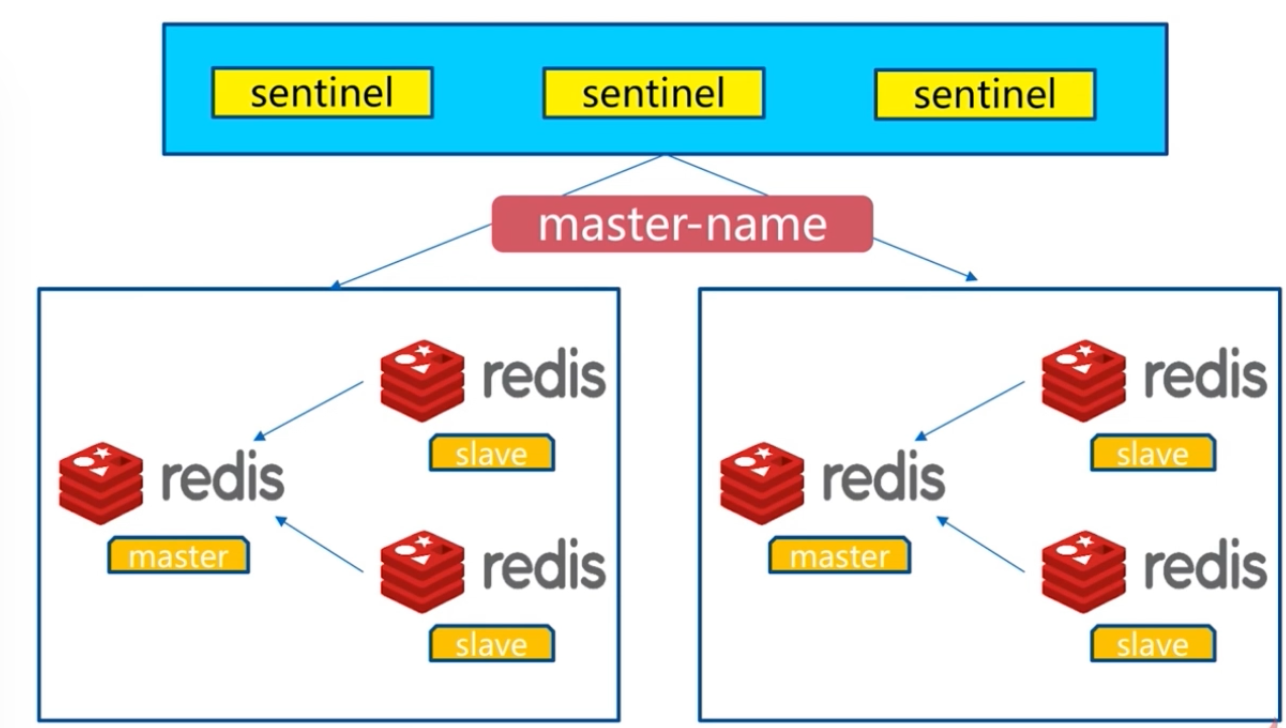
五、Redis Sentinel架构
Sentinel是redis的一个进程,但是不存储数据,只是监控redis
六、redis命令
官网地址:http://redisdoc.com/ redis-cli info #查看redis数据库信息 redis-cli info replication #查看redis的复制授权信息 redis-cli info sentinel #查看redis的哨兵信息
七、环境配置
redis的哨兵,自动的主从故障切换
# 准备3个redis数据库实例 主库:端口6379 从库:端口6380 从库:端口6381 # 准备3个redis-sentinel哨兵 redis-server redis-6379.conf redis-server redis-6380.conf redis-server redis-6381.conf # 三个哨兵同时监测主库6379的运行状况,宕机后三个哨兵根据算法选择从库中的一个切换成主库
redis数据库实例
生成数据文件夹
mkdir -p /var/redis/data/{6379,6380,6381}
主库6379配置文件redis-6379.conf
port 6379 daemonize yes logfile "6379.log" dbfilename "dump-6379.rdb" dir "/var/redis/data/6379"
从库6380配置文件redis-6380.conf
port 6380 daemonize yes logfile "6380.log" dbfilename "dump-6380.rdb" dir "/var/redis/data/6380" slaveof 127.0.0.1 6379
从库6381配置文件redis-6381.conf
port 6381 daemonize yes logfile "6380.log" dbfilename "dump-6380.rdb" dir "/var/redis/data/6381" slaveof 127.0.0.1 6379
分别启动三个redis数据库实例
redis-server redis-6379.conf redis-server redis-6380.conf redis-server redis-6381.conf
准备三个redis-sentinel哨兵的配置文件
创建配置文件
touch redis-sentinel-26379.conf touch redis-sentinel-26380.conf touch redis-sentinel-26381.conf
参数详解
port 26379 dir /var/redis/data/26379 logfile "26379.log" // 当前Sentinel节点监控 127.0.0.1:6379 这个主节点 // 2代表判断主节点失败至少需要2个Sentinel节点节点同意 // mymaster是主节点的别名 sentinel monitor s20master 127.0.0.1 6379 2 //每个Sentinel节点都要定期PING命令来判断Redis数据节点和其余Sentinel节点是否可达,如果超过30000毫秒30s且没有回复,则判定不可达 sentinel down-after-milliseconds s20master 30000 //当Sentinel节点集合对主节点故障判定达成一致时,Sentinel领导者节点会做故障转移操作,选出新的主节点, 原来的从节点会向新的主节点发起复制操作,限制每次向新的主节点发起复制操作的从节点个数为1 sentinel parallel-syncs s20master 1 //故障转移超时时间为180000毫秒 sentinel failover-timeout s20master 180000 //让哨兵在后台运行 daemonize yes
注意
如果主库中设置了密码,我们需要在哨兵配置文件中加上下面的参数:
protected-mode no sentinel auth-pass

redis-sentinel-26379.conf
port 26379 dir /var/redis/data/26379 logfile "26379.log" sentinel monitor s20master 127.0.0.1 6379 2 sentinel down-after-milliseconds s20master 30000 sentinel parallel-syncs s20master 1 sentinel failover-timeout s20master 180000 daemonize yes
redis-sentinel-26380.conf
port 26380 dir /var/redis/data/26380 logfile "26380.log" sentinel monitor s20master 127.0.0.1 6379 2 sentinel down-after-milliseconds s20master 30000 sentinel parallel-syncs s20master 1 sentinel failover-timeout s20master 180000 daemonize yes
redis-sentinel-26380.conf
port 26381 dir /var/redis/data/26381 logfile "26381.log" sentinel monitor s20master 127.0.0.1 6379 2 sentinel down-after-milliseconds s20master 30000 sentinel parallel-syncs s20master 1 sentinel failover-timeout s20master 180000 daemonize yes
分别运行三个哨兵进程
redis-sentinel redis-26379.conf redis-sentinel redis-26380.conf redis-sentinel redis-26381.conf # 保证sentinel的配置正确,否则,你在启动报错后,配置文件的内容会发生变化,这是个坑!!!!
检查redis的哨兵状态
redis-cli -p 26379 info sentinel redis-cli -p 26380 info sentinel redis-cli -p 26381 info sentinel
sentinel_masters:1 sentinel_tilt:0 sentinel_running_scripts:0 sentinel_scripts_queue_length:0 sentinel_simulate_failure_flags:0 # 看到最后一条信息正确即成功了哨兵,哨兵主节点名字叫做s20master,状态ok,监控地址是127.0.0.0:6379,有两个从节点,3个哨兵 master0:name=s20master,status=ok,address=127.0.0.1:6379,slaves=2,sentinels=3
八、redis高可用故障实验
大致思路
- 杀掉主节点的redis进程6379端口,观察从节点是否会进行新的master选举,进行切换
- 重新恢复旧的“master”节点,查看此时的redis身份
首先查看三个redis的进程状态
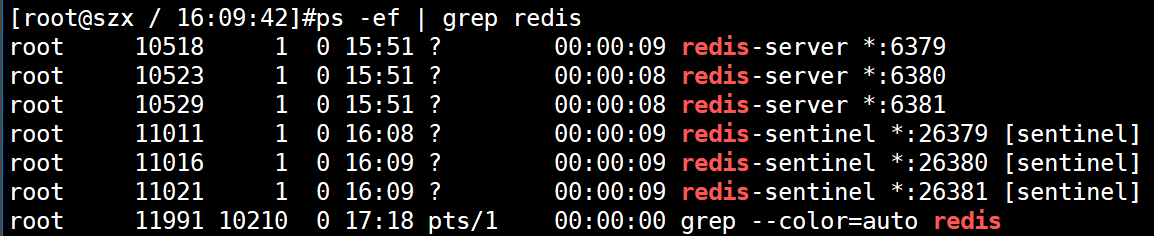
检查三个节点的复制身份状态
redis-cli -p 端口 info replication
【6379】
[root@szx / 17:18:24]#redis-cli -p 6379 info replication # Replication role:master connected_slaves:2 # 两个从库 slave0:ip=127.0.0.1,port=6380,state=online,offset=837877,lag=1 slave1:ip=127.0.0.1,port=6381,state=online,offset=838011,lag=0 master_replid:a4ecb61110814dc5b117db545c0c96c904990fc4 master_replid2:0000000000000000000000000000000000000000 master_repl_offset:838011 second_repl_offset:-1 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:1 repl_backlog_histlen:838011
【6380】
[root@szx / 17:19:14]#redis-cli -p 6380 info replication # Replication role:slave master_host:127.0.0.1 # 主库ip master_port:6379 # 主库端口 master_link_status:up # 状态正常 master_last_io_seconds_ago:1 master_sync_in_progress:0 slave_repl_offset:852447 slave_priority:100 slave_read_only:1 connected_slaves:0 master_replid:a4ecb61110814dc5b117db545c0c96c904990fc4 master_replid2:0000000000000000000000000000000000000000 master_repl_offset:852447 second_repl_offset:-1 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:1 repl_backlog_histlen:852447
【6381】
[root@szx / 17:20:27]#redis-cli -p 6381 info replication # Replication role:slave master_host:127.0.0.1 master_port:6379 master_link_status:up master_last_io_seconds_ago:0 master_sync_in_progress:0 slave_repl_offset:874725 slave_priority:100 slave_read_only:1 connected_slaves:0 master_replid:a4ecb61110814dc5b117db545c0c96c904990fc4 master_replid2:0000000000000000000000000000000000000000 master_repl_offset:874725 second_repl_offset:-1 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:15 repl_backlog_histlen:874711
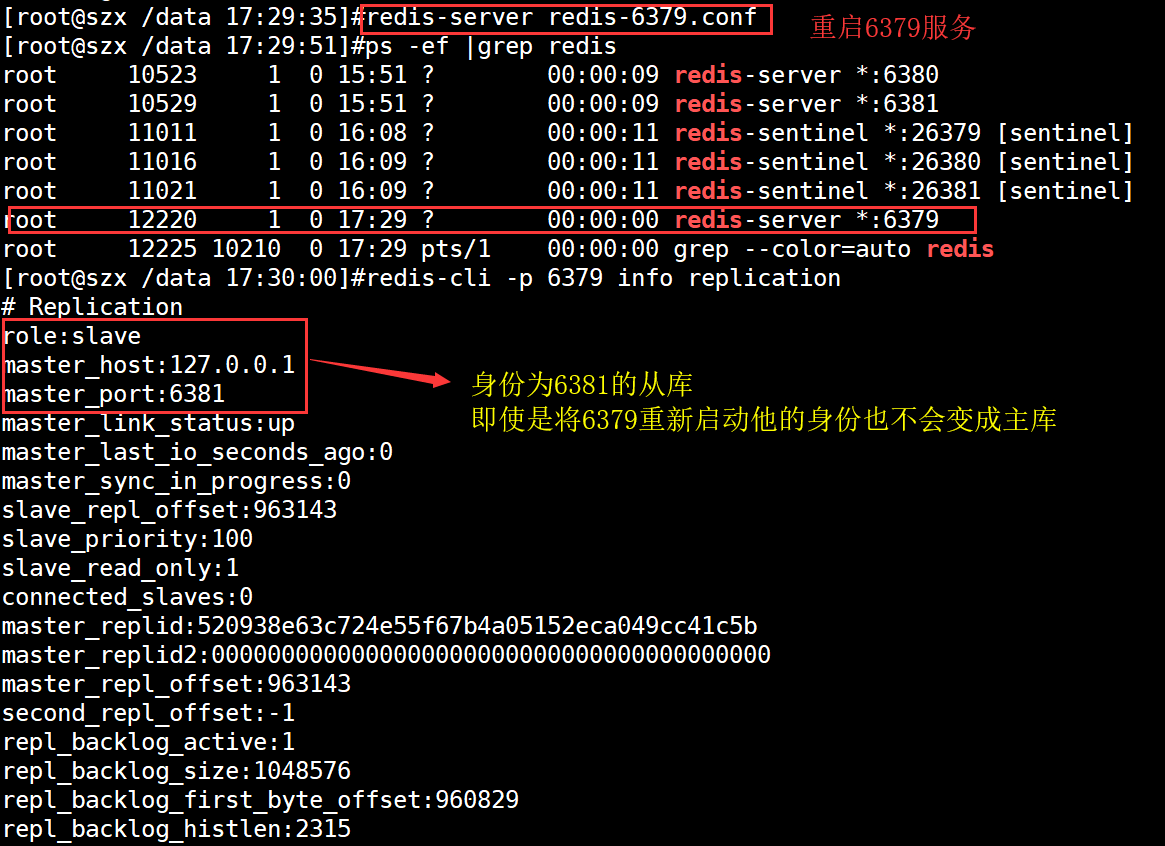
此时,干掉master!!!然后等待其他两个节点是否能自动被哨兵sentienl,切换为master节点

查看剩余的6380和6381的节点身份
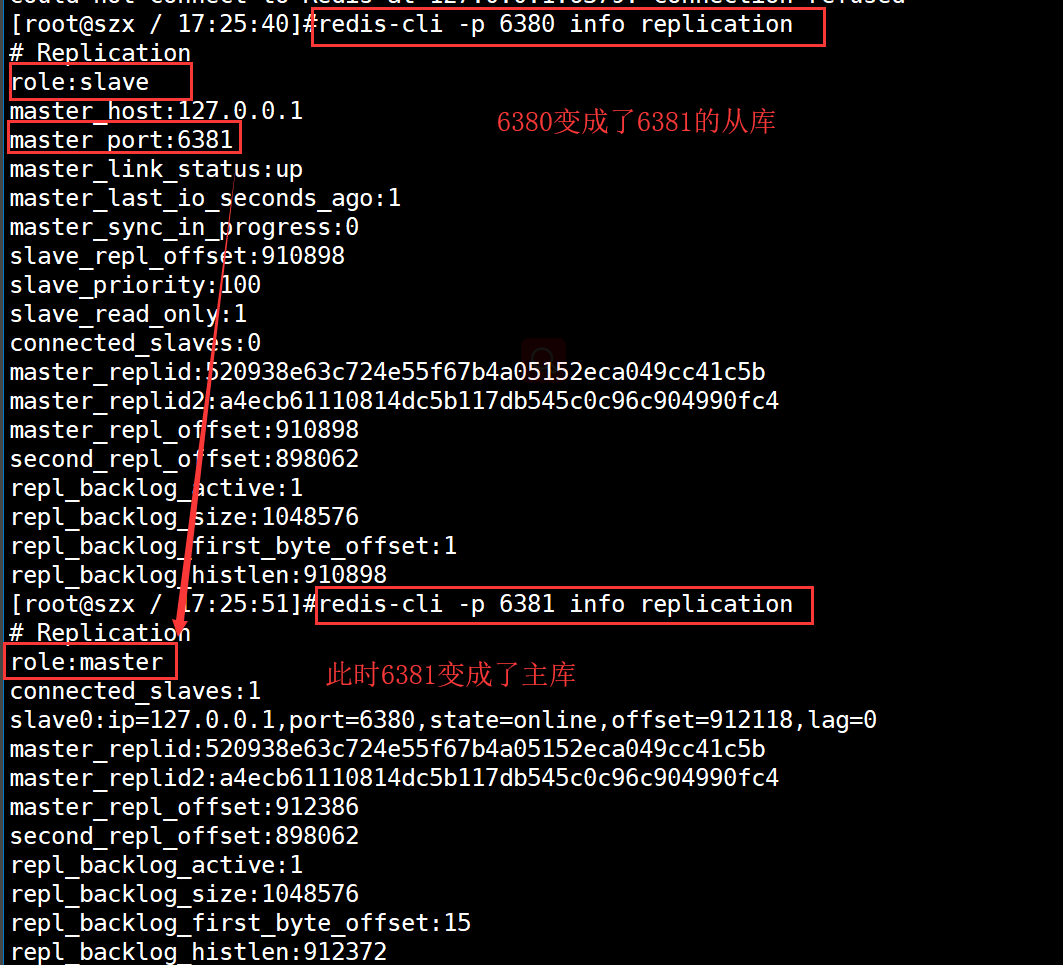
注意:重新启动6379redis服务