python爬虫之—爬取拉勾网招聘信息
1 import requests #网络请求 2 import re #正则表达式 3 import time #时间模块 4 import random #随机时间 5 import pandas as pd #数据框 6 7 for n in range(1,10): 8 time.sleep(random.randint(3,5)) #随机时间 9 10 url = 'https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false' 11 dat = {'first':'false', 12 'kd':'python', 13 'pn':1} #提交的参数 14 dat['pn']=n #翻页 15 header = { 16 'Host': 'www.lagou.com', 17 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0', 18 'Accept': 'application/json, text/javascript, */*; q=0.01', 19 'Accept-Language': 'zh-CN,en-US;q=0.7,en;q=0.3', 20 'Accept-Encoding': 'gzip, deflate, br', 21 'Referer': 'https://www.lagou.com/jobs/list_Python?labelWords=&fromSearch=true&suginput=', 22 'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8', 23 'X-Requested-With': 'XMLHttpRequest', 24 'X-Anit-Forge-Token': 'None', 25 'X-Anit-Forge-Code': '0', 26 'Content-Length': '26', 27 'Connection': 'keep-alive', 28 'Pragma': 'no-cache', 29 'Cache-Control': 'no-cache' 30 } #请求头部 31 html = requests.request('post',url,data=dat,headers=header) 32 data = re.findall('companyId":.*?,"positionId":(.*?),"positionName":"(.*?)","education":"(.*?)","city":"(.*?)","createTime":".*?","financeStage":"(.*?)","companyShortName":"(.*?)","companyLogo":".*?","salary":"(.*?)"',html.text) 33 #data = re.findall('"salary":"(.*?)","industryField":"(.*?)","district":"(.*?)"',html.text) 34 data2 = pd.DataFrame(data) #转成数据框 35 data2.to_csv('C:\\Users\\Administrator\\Desktop\\lagouwang\\lagou.csv',header=False,index=False,mode='a+',encoding='gbk') #写入本地
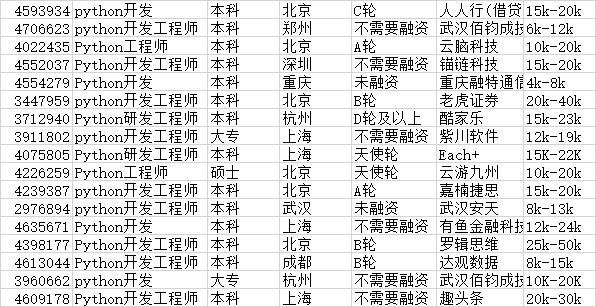
执行结果如下: