百度指数信息采集
需要登录后才可以进行搜索
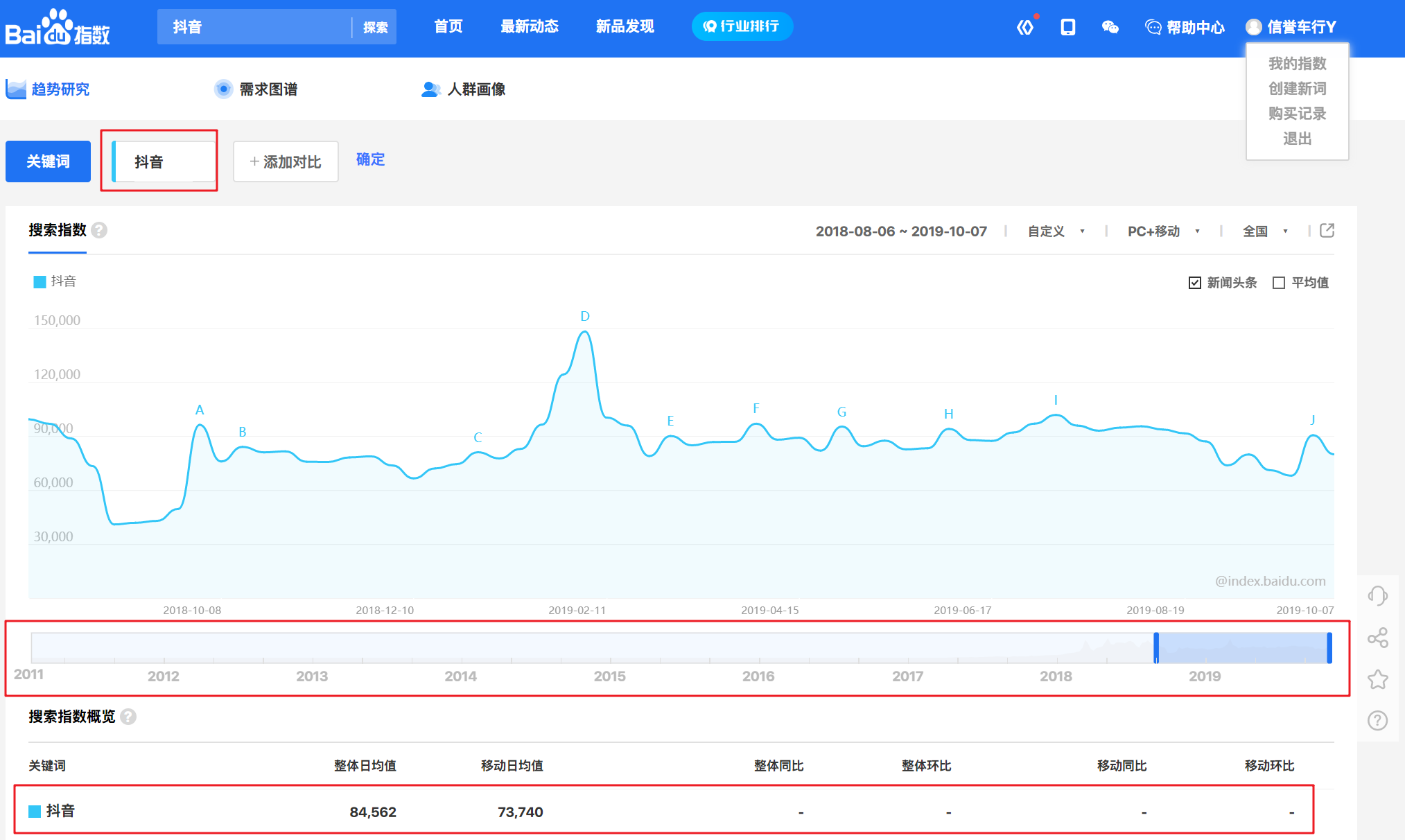
某个时间点的搜索指数
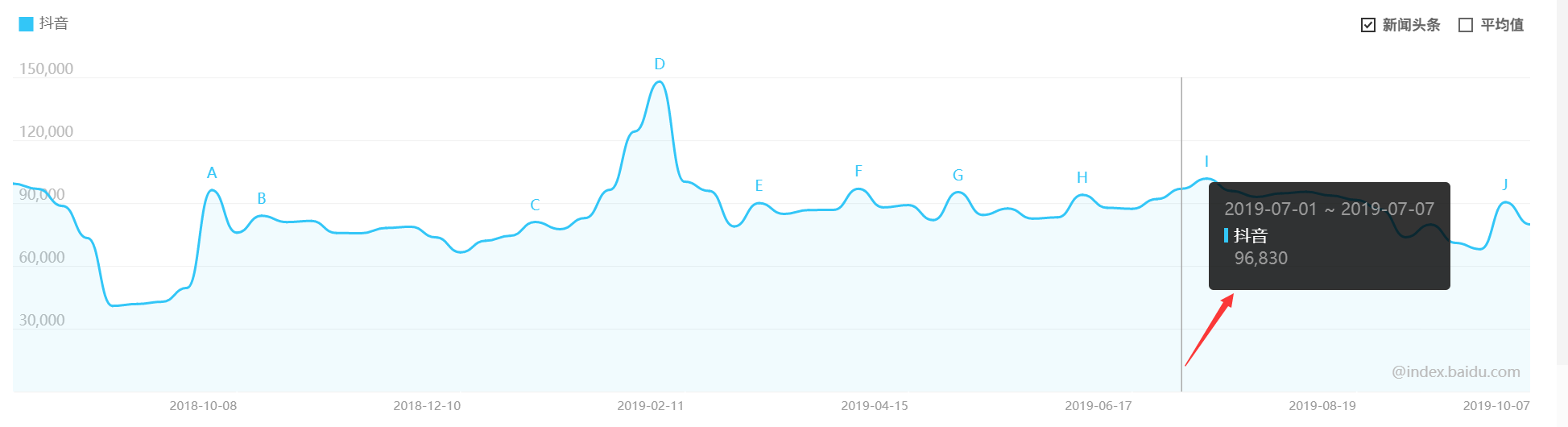
拖动上面选择时间范围的功能 查看发出的请求
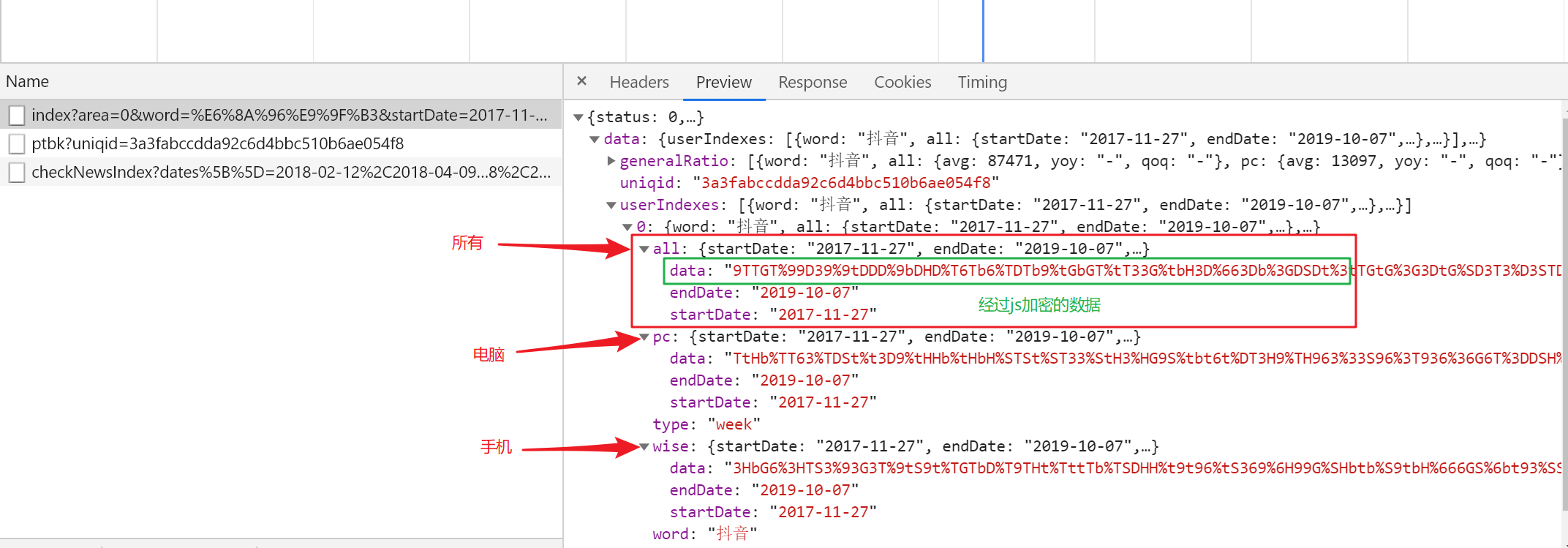

刷新页面让所有js文件全部加载
其中data可以看到应该是加密了的,all是表示全部数据,pc是指pc端,wise是移动端,这些可以在js文件里找到;首先先搞清楚这个像加密了的data是怎么解密的;我们现在知道这个数据是json格式,那么它处理肯定要从中取出这些data,所以,重新刷新一下网页,目的是为了让所有js都能加载出来,然后利用搜索功能从中找。搜索过程就不上图了,我是搜索 decrypt找到的;首先,我用decrypt找到了一个js文件,其中有一个名为decrypt的方法
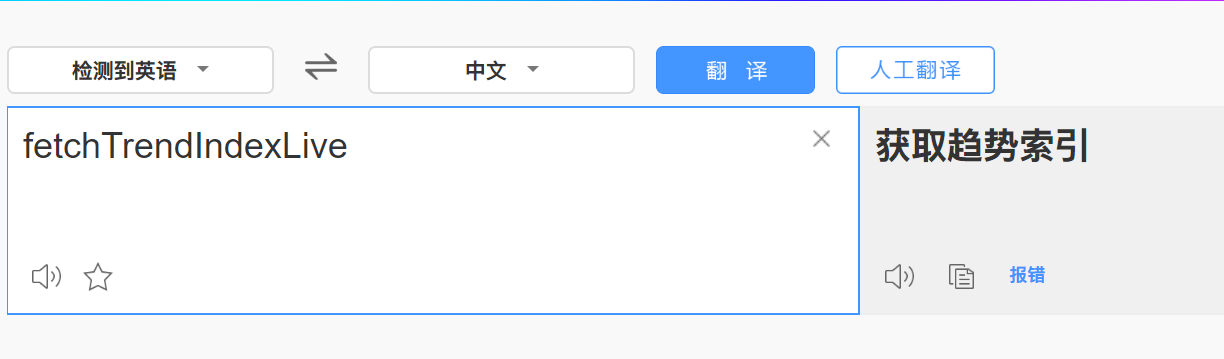
这个js文件中有很多decrypt的搜索结果,在不知道多少行处找到了一个名为 fetchTrendIndexLive 的方法,这个方法名用我工地英语翻译为 获取趋势指数

下面调用了decrypt方法
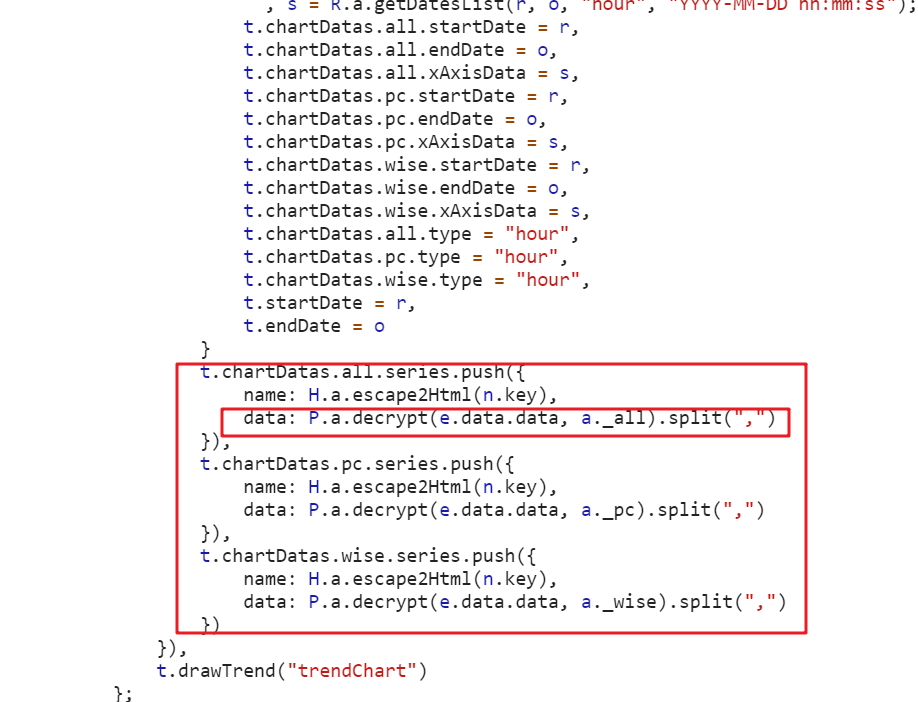
找到decrypt打断点并刷新页面

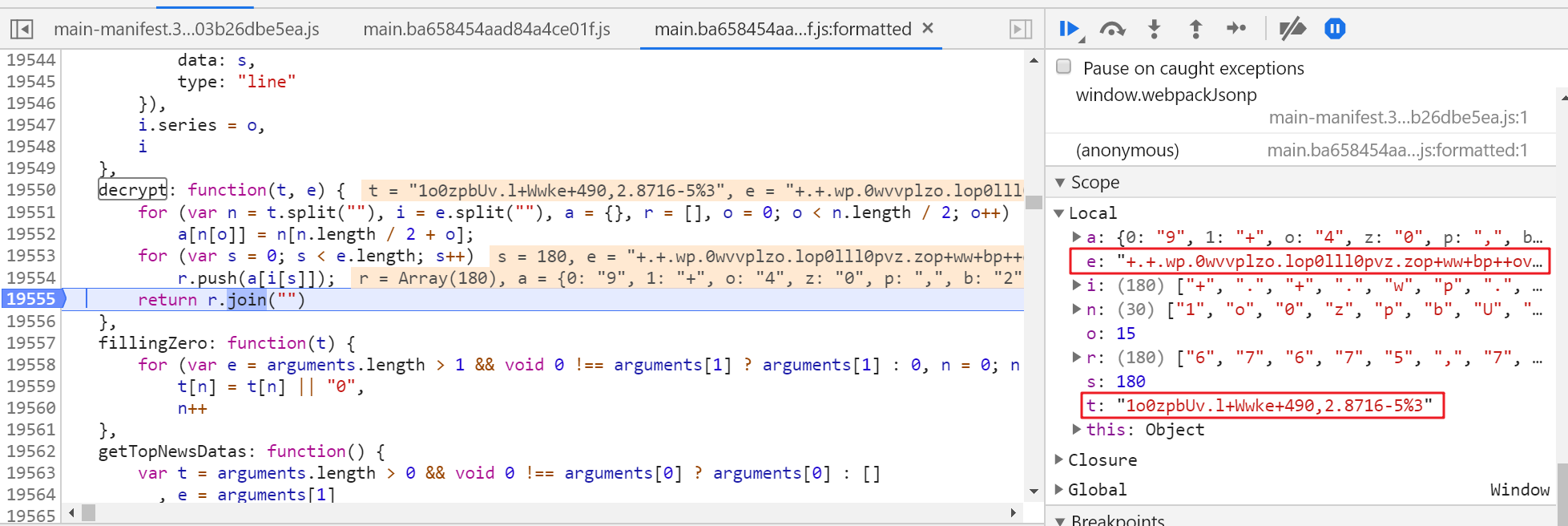
想要知道这两个参数是什么很简单,回到Network看请求里的json;其中参数e是data,t参数是拿着uniqid请求获得得相应数据,
既然我们找到了加密data得函数,接下来就是解析data数据了
解析数据有两种方法:
1、读js代码通过python代码实现函数功能
2、利用execjs模块直接调用js函数得到我们想要得数据


# -*- coding: utf-8 -*- # @Time : 2019/10/11 10:27 # 通过反写js函数解析data参数 def decrypt(t,e): n = list(t) i = list(e) a = {} result = [] ln = int(len(n)/2) start = n[ln:] end = n[:ln] for j,k in zip(start,end): a.update({k:j}) for j in e: result.append(a.get(j)) return ''.join(result) print(decrypt(",LOZpxFG1THnh0w+.6854310%9-2,7","0000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000Gw1H0GZZH0F1GF0FxOx0G1GOh0GxHhG0wpZ10OhHw0p1OH0p1pp0xppH0FhHx0GH110FGOZ0hOFw0hHFF0h1Zp0GFh10GhHw0GG110G1p10HxG0ZFh0GhOO0Gpwx0GhOp0G1ZF0HxG0ZGO0wHF0whZ0wwh0OHF0wpO0OOZ0ppO0OxZ0OGx0w1O0O110O1H0hZpZ0GGhG0Zxp0pZF0pGF0OZH0OGp0whH0Zwx0wFp0OwO0OwF0OGH0OGG0pZH0pwx0pFx0p1O0xwG0xZw0pHF0p1Z0xZG0wZO0Ohp0pwO0OhG0O1p0Ohh0O1G0px10OxF0Op10OHF0pZO0pFZ"))
// 解析data的js函数 function decrypt(t, e) { for (var n = t.split(""), i = e.split(""), a = {}, r = [], o = 0; o < n.length / 2; o++) a[n[o]] = n[n.length / 2 + o]; for (var s = 0; s < e.length; s++) r.push(a[i[s]]); return r.join("") } // t = "ev-fxk9T8V1lwAL6,51348+.9270-%" // e = "k-kvk--v-flv-fkvke-v-w9vkklv-x1vkw-vkkkvkl-vkeVvk-Vvk-1v9k-v-99v-f9vkk-vkf1vkklvkxVvkwkvkl9vk-9vkVkv-1Vvkxwvkxxvkxwvk11"
import requests def get_data(): word = input("请输入搜索内容(例如:抖音)>>>:") startDate = input("请输入起始时间(日期格式:2016-01-01)>>>:") endDate = input("请输入结束时间(日期格式:2019-01-01)>>>:") # data_url = "http://index.baidu.com/api/SearchApi/index?area=0&word=%E4%BB%A3%E5%8F%A4%E6%8B%89k&startDate=2016-04-04&endDate=2019-10-07" data_url = "http://index.baidu.com/api/SearchApi/index?area=0&word={}&startDate={}&endDate={}".format(word, startDate,endDate) headers = { # 复制登录后的cookie "Cookie": "BIDUPSID=4A07C21356D1BA0EAAD29B8C0975E123; BAIDUID=8A31AB81DDA338814808187277D5E210:FG=1; PSTM=1569552931; BDUSS=DhUcGVrMTFKdWJYYkpXbTQwM0YwV3lkNzJqZldlelBuOU9KQXd1NkNEcmp3TVpkRVFBQUFBJCQAAAAAAAAAAAEAAAC7Nb900MXT~rO10NBZAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAOMzn13jM59dT; CHKFORREG=cb90d87a921fe9ba821433dbe4ca8c43; Hm_lvt_d101ea4d2a5c67dab98251f0b5de24dc=1570714599; bdindexid=j089gd49ojceqnnmnvrcmue6l0; Hm_lpvt_d101ea4d2a5c67dab98251f0b5de24dc=1570714707", "Referer": "http://index.baidu.com/v2/main/index.html", "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36" } # 获取data和uniqid res = requests.get(url=data_url,headers=headers).json() data = res["data"]["userIndexes"][0]["all"]["data"] uniqid = res["data"]["uniqid"] # print("data:",data) # print("uniqid:",uniqid) # 获取js函数中的参数t = "ev-fxk9T8V1lwAL6,51348+.9270-%" t_url = "http://index.baidu.com/Interface/ptbk?uniqid={}".format(uniqid) rep = requests.get(url=t_url,headers=headers).json() t = rep["data"] return {"data":data,"t":t}
# -*- coding: utf-8 -*- # @Time : 2019/10/11 10:39 import execjs from get_data import get_data def get_search_index(): # 调用get_data获取data和uniqid res = get_data() e = res["data"] t = res["t"] # 读取js文件 with open('parsing_data_function.js', encoding='utf-8') as f: js = f.read() # 通过compile命令转成一个js对象 docjs = execjs.compile(js) # 调用function方法 res = docjs.call('decrypt',t,e) return res if __name__ == '__main__': res = get_search_index() print(res)
方式二我们分了三个文件
1、将加密data参数得js代码提炼出来
2、请求搜索得url获取响应数据
3、将响应数据中得data参数通过execjs传给js函数得到解析数据

注意:运行程序之前请先替换cookie,cookie如果不更新返回来的数据是假数据与百度指数的对不上;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号