
软件工程第二次作业 词频统计
1.项目名称:词频统计
2.代码地址:https://coding.net/u/songyuu/p/python_wf/git
3.代码如下:
1 import os 2 import re 3 import collections 4 #print(os.getcwd()) #显示wf.py路径 5 #print(os.listdir())#显示目录下的文件 6 file_name=input("wf ") 7 if not os.path.isfile(file_name+'.txt'): 8 print('文件不在当前文件夹') 9 else: 10 file_name_word = open(file_name+'.txt').read() 11 # print(len(file_name_word),type(len(file_name_word))) 12 file_name_word_list = re.split("[^A-Za-z0-9_'-]+", file_name_word.lower())#9月26日修改 13 # lower变小写 split 切割 re正则表达式 14 if ("") in file_name_word_list: 15 #print(file_name_word_list) 16 file_name_word_list.remove('') 17 #print(file_name_word_list) 18 #file_name_word_list.remove("") 19 # 删除列表中的空元素 20 # print(type(file_name_word_list)) 21 file_name_word_list_t = collections.Counter(file_name_word_list) 22 # collections 模块调用,统计列表 23 print("total", len(file_name_word_list_t), "words\n") # 列表中有多少个元组 24 a = file_name_word_list_t.most_common(10) 25 #print(a) 26 # 显示次数最高的前10 27 for i in a: # 输出结果换行 28 j=(i[0].ljust(15),i[1])#对齐 29 k = str(j) # 元组变字符串 30 l = k.replace("'", "") 31 m = l.replace("(", "") 32 n = m.replace(")", "")# 去除字符串标点 33 print(n.replace(",", " ")) 34 35 print('-------------------') 36 input()
4.测试:


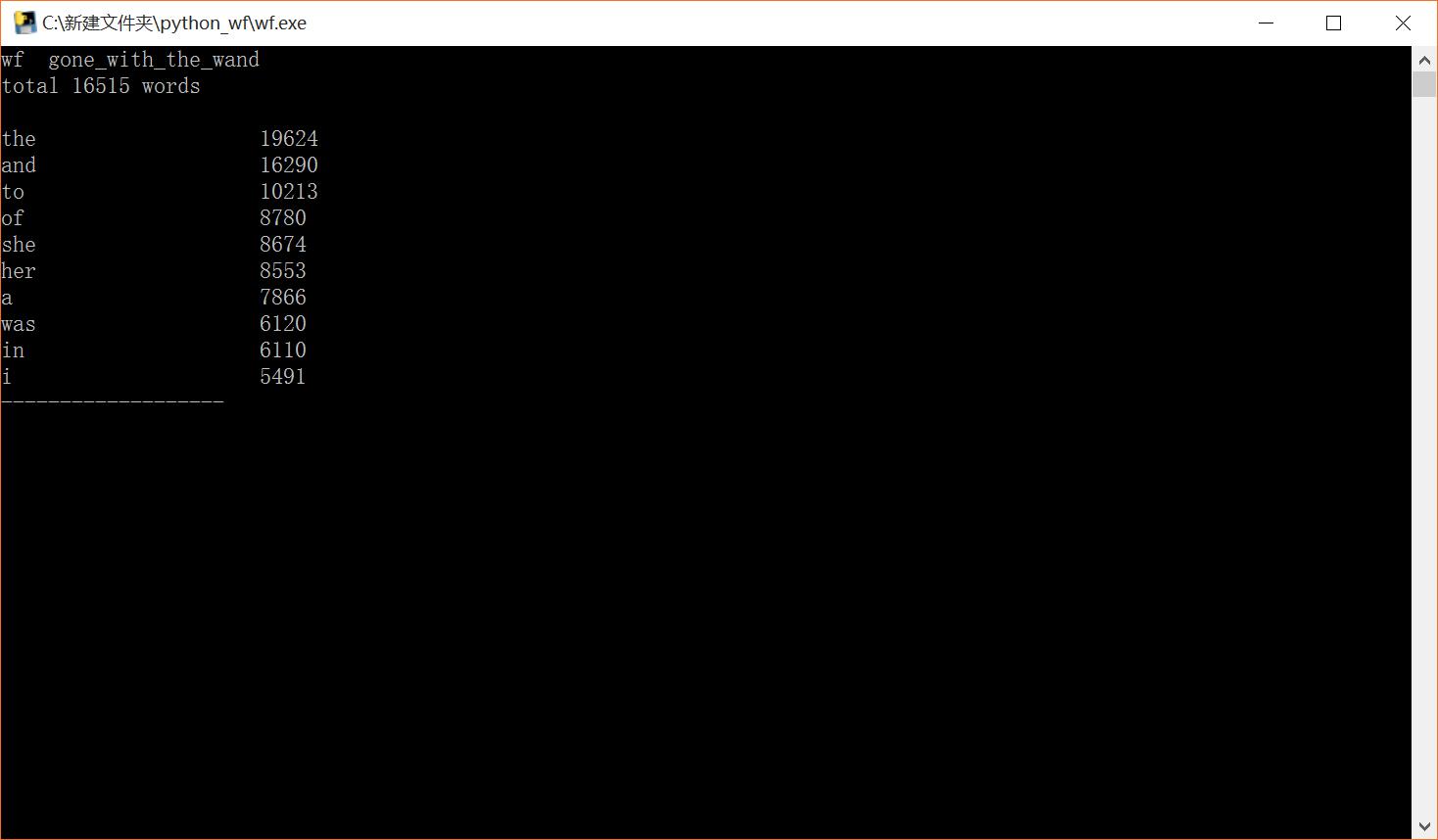
5.总结:
时间紧迫,只实现前两个功能,遇到问题如下:
输出结果是元组,为了符合作业要求,转换成字符串然后把标点符号删掉,我觉得应该还有更好的方法,现在还没又找到。
统计时发现在word中apple.pear算一个单词,apple. pear算两个单词,有的句子末尾没有加空格,有的句子末尾加空格,word计数不一样。
有的名词中间也有标点符号(.)和(-),所以我感觉要做出完美的词频统计还需要考虑很多,我做的这个小程序还不是很完善。
通过做作业得到的感受:
因为是刚学习python,列表、元组、字符串经常弄混,经过这次作业记忆深刻一些。在作业中我用的都是很基础的知识,没有定义函数,代码显得有点“低端”,以后尽力提高。
6.PSP阶段表格:


