
关于HDFS的NameNode和SecondaryNameNode的一些疑问解答
2021-10-09 14:47 DataBases 阅读(565) 评论(0) 编辑 收藏 举报https://mp.weixin.qq.com/s/xAvsxEGaCfLCPdVFuJZWPA
https://mp.weixin.qq.com/s/dOuRVOlI3CJABpbrTx3Aqg
https://mp.weixin.qq.com/s/caCk3mM5iXy0FaXCLkDwYQ
https://mp.weixin.qq.com/s/_KLIX3y-adhdaHgEDCTYPg
https://mp.weixin.qq.com/s/DNZbpKsLqccnuiPLVb1T5Q
Hadoop NameNode详解
NameNode在内存中保存着整个文件系统的名字空间和文件数据块的地址映射(Blockmap)。如果NameNode宕机,那么整个集群就瘫痪了。
整个HDFS可存储的文件数受限于NameNode的内存大小。
这个关键的元数据结构设计得很紧凑,因而一个有4G内存的Namenode就足够支撑大量的文件和目录。
NameNode负责:文件元数据信息的操作以及处理客户端的请求
NameNode管理:HDFS文件系统的命名空间NameSpace。
NameNode维护:文件系统树(FileSystem)以及文件树中所有的文件和文件夹的元数据信息(matedata),维护文件到块的对应关系和块到节点的对应关系
NameNode文件:namespace镜像文件(fsimage),操作日志文件(edit log),这些信息被Cache在RAM中,当然这两个文件也会被持久化存储在本地硬盘。
NameNode记录:每个文件中各个块所在的数据节点的位置信息。但它并不永久保存块的位置信息,因为这些信息在系统启动时由数据节点重建。从数据节点重建:在nameNode启动时,DataNode向NameNode进行注册时发送给NameNode。
NN和SecondaryNameNode(2NN)工作机制
思考:NameNode中的元数据是存储在哪里的?
首先,我们做个假设,如果存储在NameNode节点的磁盘中,因为经常需要进行随机访问,还有响应客户请求,必然是效率过低。因此,元数据需要存放在内存中。但如果只存在内存中,一旦断电,元数据丢失,整个集群就无法工作了。因此产生在磁盘中备份元数据的FsImage。
这样又会带来新的问题,当在内存中的元数据更新时,如果同时更新FsImage,就会导致效率过低,但如果不更新,就会发生一致性问题,一旦NameNode节点断电,就会产生数据丢失。
因此,引入Edits文件(只进行追加操作,效率很高)。每当元数据有更新或者添加元数据时,修改内存中的元数据并追加到Edits中。这样,一旦NameNode节点断电,可以通过FsImage和Edits的合并,合成元数据。
但是,如果长时间添加数据到Edits中,会导致该文件数据过大,效率降低,而且一旦断电,恢复元数据需要的时间过长。因此,需要定期进行FsImage和Edits的合并,如果这个操作由NameNode节点完成,又会效率过低。因此,引入一个新的节点SecondaryNamenode,专门用于FsImage和Edits的合并。
Fsimage:NameNode内存中元数据序列化后形成的文件。
Edits:记录客户端更新元数据信息的每一步操作(可通过Edits运算出元数据)。
NameNode启动时,先滚动Edits并生成一个空的edits.inprogress,然后加载Edits和Fsimage到内存中,此时NameNode内存就持有最新的元数据信息。Client开始对NameNode发送元数据的增删改的请求,这些请求的操作首先会被记录到edits.inprogress中(查询元数据的操作不会被记录在Edits中,因为查询操作不会更改元数据信息),如果此时NameNode挂掉,重启后会从Edits中读取元数据的信息。然后,NameNode会在内存中执行元数据的增删改的操作。
由于Edits中记录的操作会越来越多,Edits文件会越来越大,导致NameNode在启动加载Edits时会很慢,所以需要对Edits和Fsimage进行合并(所谓合并,就是将Edits和Fsimage加载到内存中,照着Edits中的操作一步步执行,最终形成新的Fsimage)。SecondaryNameNode的作用就是帮助NameNode进行Edits和Fsimage的合并工作。
SecondaryNameNode首先会询问NameNode是否需要CheckPoint(触发CheckPoint需要满足两个条件中的任意一个,定时时间到和Edits中数据写满了)。直接带回NameNode是否检查结果。SecondaryNameNode执行CheckPoint操作,首先会让NameNode滚动Edits并生成一个空的edits.inprogress,滚动Edits的目的是给Edits打个标记,以后所有新的操作都写入edits.inprogress,其他未合并的Edits和Fsimage会拷贝到SecondaryNameNode的本地,然后将拷贝的Edits和Fsimage加载到内存中进行合并,生成fsimage.chkpoint,然后将fsimage.chkpoint拷贝给NameNode,重命名为Fsimage后替换掉原来的Fsimage。NameNode在启动时就只需要加载之前未合并的Edits和Fsimage即可,因为合并过的Edits中的元数据信息已经被记录在Fsimage中。
HDFS 进程各自的职责以及如何协调工作
为了便于理解,举个简单的例子:我们可以把整个 HDFS 系统看作是动物园, 里面有许多嗷嗷待哺的小动物(DataNode),管理员们(Client)负责投喂和收餐盘(读写数据),但是动物太多,管理员没法准确知道需要去哪个位置投喂,所以需要有一个中转站,中转站里有一张记录小动物位置和种类信息(元数据信息)的表格(NameNode)放在固定的地方,投喂前管理员们都来中转站看一下表格,然后去找具体的位置。表格的数据很重要,如果丢了管理员就会手足无措了,所以我们将表格再备份一份(Standby NameNode)放在抽屉里,每次数据修改都将数据同步到备份的表格处(JournalNode),如果主表格丢失了,监控(ZKFC)发现后保安(Zookeeper)立马把备份表格拿出来使用。
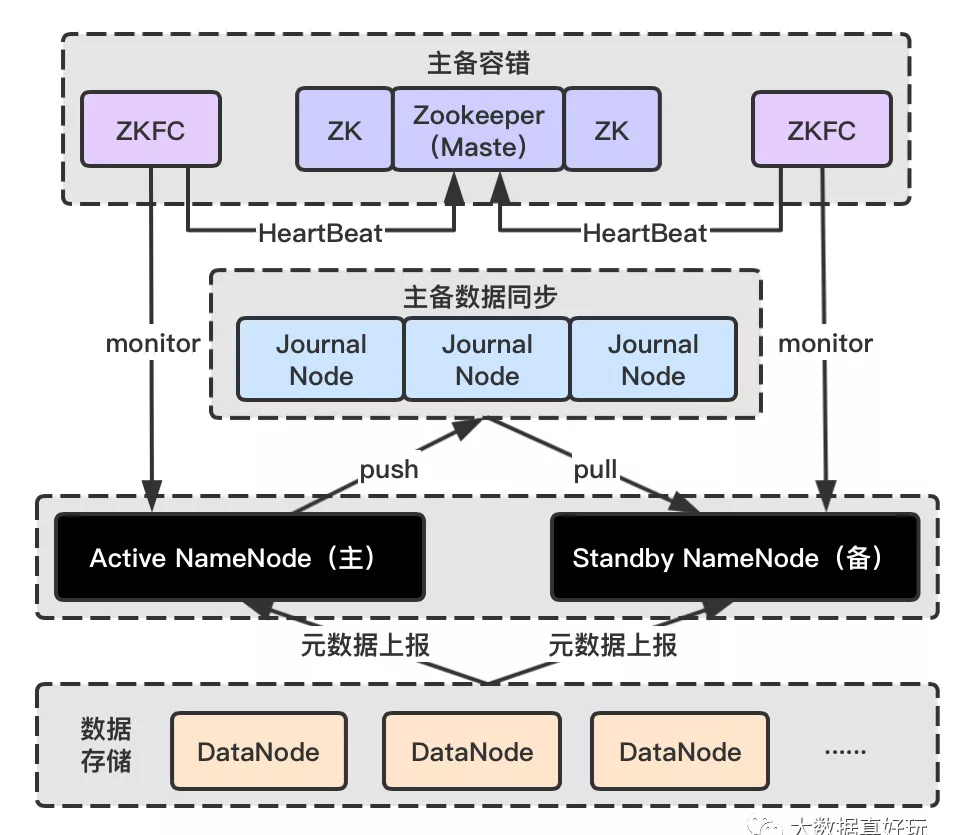
上面的例子帮助大家简单理了一下逻辑,下面进入正题,HDFS 进程还是比较多的,每个进程有各自的职责,然后按照既定的规则与其他进程交互,目的是维持系统正常稳定地运行。
-
Active NameNode:它是 HDFS 对外提供读写服务的唯一 Master 节点,管理着文件系统的 Namespace;维护着文件的元数据,包括文件名、副本数、文件的 BlockId 以及 Block 所在的服务器等信息;同时会接受来自 Client 端的读写请求,和接受 DataNode 的 Block 信息上报。
-
Standby NameNode:Active NameNode 的备用节点,它会及时从 JournalNode 中读取 EditLog 数据并更新内存,以保证当前状态尽可能与主节点同步。需要注意的是,集群中最多一台处于 Active 状态,最多一台处于 Standby 状态。
-
JournalNode Cluster:用于主备 NameNode 之间共享 Editlog 的一致性共享存储系统。负责存储 Editlog 以及将元数据从主节点实时同步到备用节点。流程是主节点先将 EditLog 文件 push 进 JournalNode,备节点再从 JournalNode 节点 Pull 数据,JournalNode 不主动进行数据交换。集群由 2N + 1 个 JournalNode 进程组成,可以容忍最多 N 台 JournalNode 节点挂掉。
-
ZKFailoverController(ZKFC):ZKFailoverController 以独立进程运行,正常情况每个 ZKFC 都会监控自己负责的 NameNode 的心跳,如果异常,则会断开与 ZooKeeper 的连接,释放分布式锁,另外一个 NameNode 上的 ZKFC 则会获取锁,然后会把对应的 NameNode 的状态从 Standby 切换到 Active。ZKFC 主要负责:NameNode 健康状况检测;借助 Zookeeper 实现 NameNode 自动选主;操作 NameNode 进行主从切换。
-
Zookeeper:为 ZKFC 实现自动选主功能提供统一协调服务。通过 watcher 监听机制,通知 ZKFC 异常 NameNode 的下线;保证同一时刻只有一个 Active Name 节点,并告知客户端。
-
DataNode:负责实际数据的存储,在如图 NameNode 高可用的架构下,DataNode 会同时向主备两个 NameNode 节点进行元数据上报,但是仅执行主节点下发的指令。
另外,secondNameNode 由于会有单点问题已经很少应用,这里不讨论了,他的工作可以被 JournalNode 取代。
相关面试题
-
HDFS 客户端与 NameNode 和 DataNode 的通信和交互过程?
-
Secondary NameNode 的功能在高可用架构下被那个进程所取代?
-
NameNode 会存储哪些数据?
-
HDFS 是如何保证 NameNode 高可用的?
-
ZKFC 是如何实现主节点异常切换的?
-
Zookeeper 在异常切换中起到的作用?
这些问题都是进程的职责相关的内容,答案都在上面的知识点中都有详细描述,问的方式有千千万万种,但是万变不离其宗,背后的知识点都是固定的。这里考察的是对 HDFS 组件比较常规的了解,各组件的职责和工作方式,重点需要掌握的是 ZKFC 和 JournalNode 的作用,不容有失。
Block & Packet & Chunk
-
Block:HDFS 中的文件在物理上是分块存储,即 Block。每个 Block 大小:Hadoop 2.x 版本为 128 MB;Hadoop 1.x 版本为 64 MB 。
-
Packet:Packet 是 Client 端向 DataNode,或 DataNode 的 PipLine 之间传数据的基本单位,默认 64KB。
-
Chunk:Chunk 是最小的单位,它是 Client 向 DataNode 或 DataNode 的 PipLine 之间进行数据校验的基本单位,默认 512Byte,因为用作校验,故每个 chunk 需要带有 4 Byte 的校验位。所以实际每个 chunk 写入 packet 的大小为 516 Byte。
为什么 Block 会从老版本的 64MB 升级到 128MB? 以前服务器的配置大多是 5400 转硬盘,平均读写理论上在 60-90MB/s,现在常用的是 7200 转,读写大致在 130-190MB/s。数据写磁盘是需要消耗寻址时间的,最优的理论情况是寻址时间仅占传输时间的 1%,为了降低寻址开销,最优情况当然是一次寻址写完这次传输的所有数据。
安全模式
安全模式是 HDFS 处于初始化状态的一种自我保护机制,在这种模式下,HDFS 对于客户端来说是只读的。NameNode 主节点启动时,HDFS 就会进入安全模式。在安全模式中, DataNode 会向 NameNode 上报可用 Block 的信息,即告知 NameNode 当前集群中有哪些可用数据,因为 NameNode 初始时本身是不知道集群中有哪些 Block 的。退出安全模式的条件?
-
HDFS 可用 Block 占总数的比例(dfs.namenode.safemode.threshold-pct):默认 99.9%
-
可用的数据节点数量符合要求(dfs.namenode.safemode.min.datanodes):默认 0,即无要求。
-
满足上面两个条件的持续时间(dfs.namenode.safemode.extension):默认 1ms,即维持正常状态 1ms 就退出安全模式。
源码级客户端读写数据交互流程
数据读写流程在面试过程中是最常见的问题,答案其实很简单,但是想要答得出彩其实是不容易的,如这个知识点所描述的,从源码级别去看待这个读写流程,能看得更透彻,给面试官的印象也会更深刻。
写数据流程?
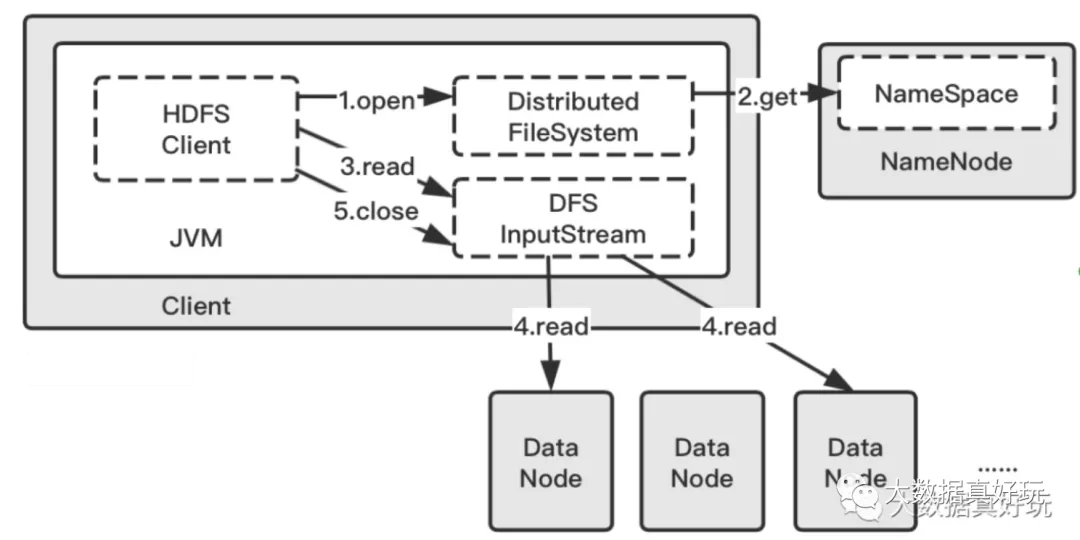
-
首先 client 端通过在 DistributedFileSystem 上调用 create() 方法来创建一个文件。其中,DistributedFileSystem 是客户端用户创建的一个对象,用户可以通过调用 DistributedFileSystem 的方法来对 HDFS 做读写操作。
-
在收到 client 端 create 动作之后,DistributedFileSystem 通过 RPC 与 NameNode 通信 ,让它在文件系统的 namespace 上创建一个独立的新文件,NameNode 会确认文件是否已经存在以及客户端是否有权限。确认成功后,NameNode 会生成一条新文件的记录并返回一个负责 client 端与 datanode 和 namenode 进行 I/O 操作的 DFSOutputStream 对象给客户端,另外还会包含可写入的 DataNode 的信息。如文件创建失败,客户端会抛出一个 IOException。
-
当客户端开始写数据,DFSOutputStream 将文件分割成很多很小的块,然后将每个小块放进一个个 package 中, packages 会写进一个内部队列中,准备往 DataNode 写数据。
-
此时会根据 NameNode 返回的可写入的 DataNode 列表来构成一个 pipeline,默认是有三个 DataNode 组成, DataStreamer 将能够组成块的包先流入 pipeline 中的第一个 DataNode ,第一个 DataNode 会先存储来到的包,然后继续将所有的包转交到 pipeline 中的第二个 DataNode 中,以此类推。
-
DFSOutputStream 还维护了另一个确认队列,该队列等待 DataNode 的写入确认。当一个包已经被 pipeline 中的所有 DataNode 确认了写如磁盘成功,这个包才会从确认队列中移除。
-
当 Client 完成了数据写入,会在流上调用 close() 方法。需注意,这一步不是在 4 和 5 第一次完成之后,而是客户端需要写入的所有数据写完了之后。这个行为会将所有剩下的包 flush 进 DataNode 中。
-
等到确认信息全部都到达,即步骤 5 完成之后,Client 会再次与 NameNode 通信告知完成。NameNode 会确认该文件的备份数是否满足要求。
读数据流程?
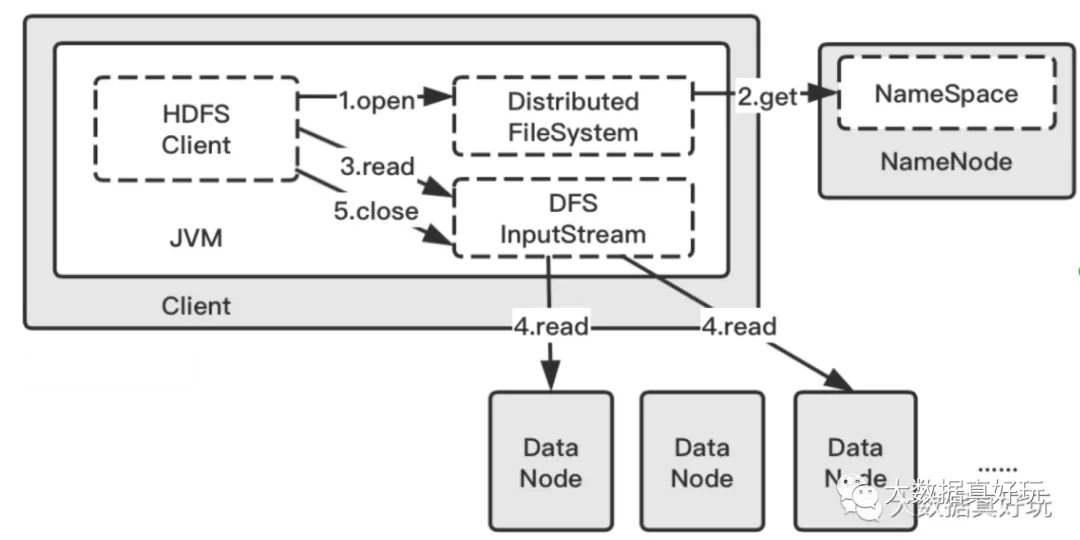
-
与写流程类似,第一步 Client 端同样是调用 DistributedFileSystem 对象,指定想要读的文件 target.txt ,使用 open() 方法。
-
此时 DistributedFileSystem 就会与 NameNode 进行 RPC 通信,获取组成 target.txt 的 block 信息,其中包含** block 存在于哪些 DataNode 中**。
-
然后 Client 就调用 read() 方法,这里同样会有一个 DFSInputStream 来负责与 DataNode 的 IO。此时会找到 DataNode 列表里离当前 Client 端最近的一个 DataNode(如何判断最近,后面的机架感知中会解释)。
-
然后 DFSInputStream 就通过重复调用 read() 方法,数据就从 DataNode 流动到了客户端。当该 DataNode 中最后一个块的读取完成了, DFSInputStream 会关闭与 DataNode 的连接,然后为下一块寻找最佳节点。这个过程对客户端来说是透明的,在客户端那边看来,就像是只读取了一个连续不断的流。
-
当客户端完成了读取,就会调用 close() 方法结束整个流程。**
HDFS 可用性保证机制
之前提到了 HDFS 是由 DataNode,NameNode,JournalNode,DFSZKFailoverController 这些组件组成的,所以可用性会涉及到各个组件,面试时也要从多个方面来回答这个问题。
-
首先 NameNode 的高可用由 JournalNode 和 DFSZKFailoverController 保证,NameNode 有主备两个节点,JournalNode 负责主备节点数据的同步保证数据一致性,ZKFC 负责主备的 Failover,即主节点宕机由备用节点接替主节点工作。
-
JournalNode 也是分布式的,因为有选举机制,所以默认要大于一的奇数个服务器在线,同样是具有可用性保证的。
-
DFSZKFailoverController(ZKFC)是部署在两个 NameNode 节点上的独立的进程,他的作用是辅助 zookeeper 做 NameNode 的健康监控,保证异常切换,而 **Zookeeper **是一个独立的分布式系统,用于管理和协调分布式系统的工作,它本身也会通过 zab 协议来保证数据一致,和主备节点的选举切换等机制来保证可用性。
-
DataNode节点的宕机会造成部分 block 的丢失,但是 block 一般都会有三个备份,且在不同的 DataNode,所以 DataNode 挂掉两台仍然能保证数据的完整性,同时NameNode 会负责副本数的补充。
-
对于数据的可用性保证,HDFS 还提供了数据完整性校验的机制,当客户端创建 HDFS 文件时,它会计算文件的每个块的校验和(checknums),并存储在 NameNode 中。当客户端读文件时,会验证从每个 DataNode 接收的数据是否与 checknums 匹配。如果匹配失败,则证明数据已经损坏,此时客户端会选择从其他 DataNode 获取该块的其他可用副本。

