hadoop Shuffle Spark Shuffle
2020-05-24 22:15 DataBases 阅读(333) 评论(0) 编辑 收藏 举报什么是大数据处理的Shuffle?
无论是Hadoop还是Spark,都要实现Shuffle。Shuffle描述数据从map tasks的输出到reduce tasks输入的这段过程。
Shuffle是连接map和reduce之间的桥梁,map的输出要用到reduce中必须经过shuffle这个环节,shuffle的性能高低
直接影响了整个程序的性能和吞吐量。因为在分布式情况下,reduce task需要跨节点去拉取其它节点上的map task的结果。
这一过程将会产生网络资源消耗和内存,磁盘io的消耗。
通常shuffle分为两个部分:map阶段的数据准备和reduce阶段的数据拷贝处理。一般将在map端的shuffle称之为shuffle write,
在reduce端的shuffle称之为shuffle Read。
为什么大数据集群处理需要进行Shuffle?
map tasks的output向着reduce tasks的输入input映射的时候,并非节点一一对应的,在节点A上做map任务的输出结果,
可能要分散跑到reduce节点A、B、C、D ,就好像shuffle的字面意思“洗牌”一样,
这些map的输出数据要打散然后根据新的路由算法(比如对key进行某种hash算法),发送到不同的reduce节点上去。
Hadoop和Spark的Shuffle分别是如何实现的?
在map端,一个task经历了:输入(input)过程、切分(partition)过程、溢写spill过程、merge过程;其中spill和merge都要排序,
而combiner【备注:combiner相当于map端的reduce】是可选的。在reduce端,当有一个map task完成后,yarn会告知reducer拉取(fetch)任务,
在所有的map任务完成之前,reducer都是在重复的拉取(copy)数据、merge这两个步骤。需要注意的是,这两个步骤是来源与不同的map task结果生成的文件,
并且,reducer只merge属于自己分区的文件。
Spark Shuffle
每一个key对应的value不一定都是在一个partition中 ,也不太可能在同一个节点上,因为RDD是分布式的弹性的数据集,它的partition极有可能分布在各个节点上。
既然出现如上的问题,那么Spark如何进行聚合?
– Shuffle Write:上一个stage的每个map task就必须保证将自己处理 的当前分区中的数据相同的key写入一个分区文件中,可能会写入多个不同的分区文件中。
– Shuffle Read:reduce task就会从上一个stage的所有task所在的机器上寻找属于自己的那些分区文件,这样就可以保证每一个key所对应的value都会汇聚到同一个节点上去处理和聚合。
Hash-Based Shuffle–普通机制||合并机制
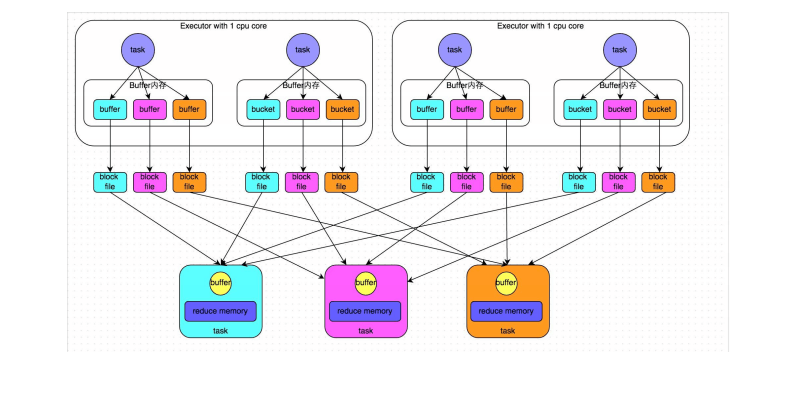
hashshuffle会产生m*r个磁盘小文件 m:maptask的个数 r:reducetask的个数
如果m=1000,r=1000,磁盘小文件数就是100w。
磁盘小文件过多会有什么问题?
shuffle write:写磁盘的对象会增多,100w写磁盘的对象, 耗时低效的I/O操作。
shuffle read:建立连接(磁盘小文件过多,建立连接会非常的频繁),拉取磁盘小文件(每一次拉取,都需要创建一个读文件的对象)
jvm中对象过多,对象存储在堆内存中,会引起GC OOM等一系列问题。
HashShuffle合并机制(针对上述情况的优化)
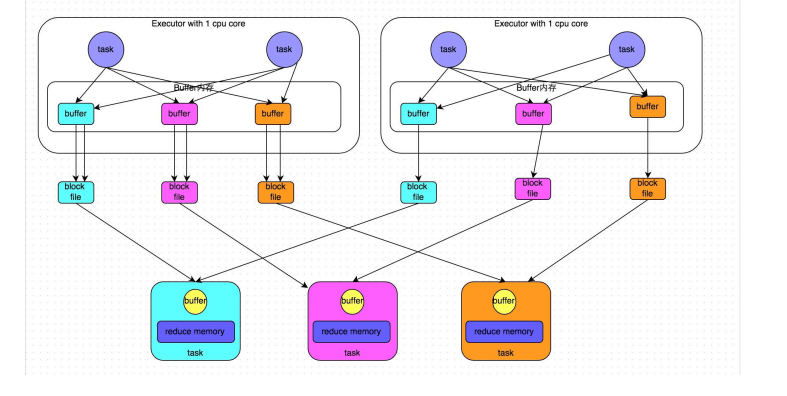
shuffle file group: task2会复用task1的小文件
磁盘小文件的数量为:core * reduce的个数
SortShuffle–普通运行机制|| bypass运行机制
SortShuffle–普通机制(排序)
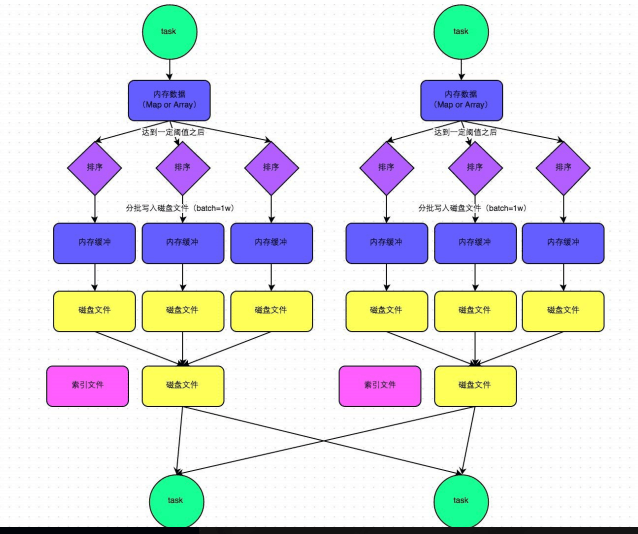
【流程描述】:
1.map task 计算的结果一条一条的写入内存的数据结构里面去,内存的数据结构初始大小是5M,如果现在内存数据结构的大小超过5M(比如5.01M,它会再次申请5.01*2-5=0.02M的内存,
如果现在有空闲的内存就不会溢写,如果没有空闲的空间供它使用,就会发生溢写,在溢写之前会将内存数据结构中的额数据进行排序,排序完成之后分批写入到磁盘,每一批1W条数据,
写入磁盘的时候使用了buffer(加速写磁盘的速度)map task 执行完成后,溢写到磁盘上的磁盘小文件会合并为一个大的文件,同时还会创建一个索引(就是这个大文件的一个目录)
2.reduce task 来数据之前,首先解析这个索引文件,然后拉取大文件中相应的数据
SortShuffle–bypass机制(不排序)
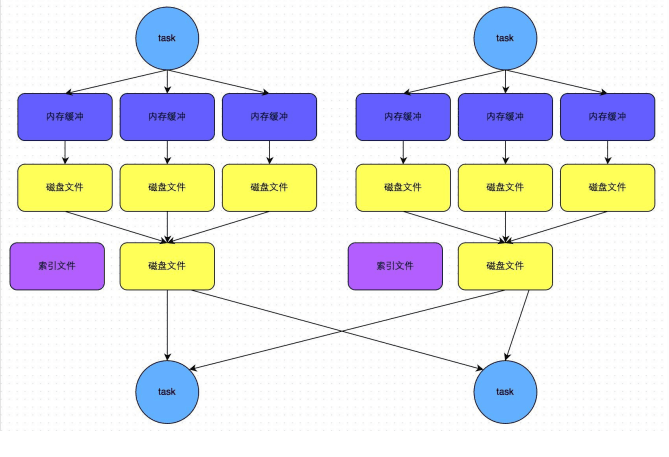
注意:shuffle reduce task的数量小于spark.shuffle.sort.bypassMergeThreshold参数的值触发
Spark的map阶段完成之后直接输出文件到磁盘,reduce从多个file读取map的结果,然后汇总计算。
