机器学习-Kmeans
1|0一、什么是聚类算法?
1、用于发现共同的群体(cluster),比如:邮件聚类、用户聚类、图片边缘。
2、聚类唯一会使用到的信息是:样本与样本之间的相似度(跟距离负相关)
给定N个训练样本(未标记的){x 1 , . . . , x N },同时给定结果聚类的个数K 目标:把比较“接近”的样本放到一个cluster里,总共得到K个cluster

2|0二、不同场景的判定内容
图片检索:图片内容相似度
图片分割:图片像素(颜色)相似度
网页聚类:文本内容相似度
社交网络聚类:(被)关注人群,喜好,喜好内容
电商用户聚类:点击/加车/购买商品,行为序列…
3|0三、样本—向量—距离

4|0 四、Kmeans聚类和层次聚类
4|1Kmeans聚类:
得到的聚类是一个独立于另外一个的


收敛:
聚类中心不再有变化 每个样本到对应聚类中心的距离之和不再有很大变化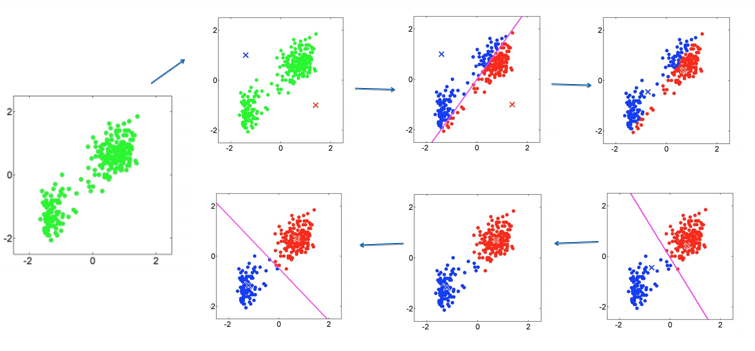
4|2层次聚类:
可以看做树状层叠 无需初始输入聚类个数

4|3k-means聚类与层次聚类区别:
kmeans每次聚类产生一个聚类结果,层次聚类可以通过聚类程度不同产生不同结果 kmeans需要指定聚类个数K,层次聚类不用 kmeans比层次聚类更快 kmeans用的多,且可以用k-median
5|0 五、损失函数

6|0 六、K的选定
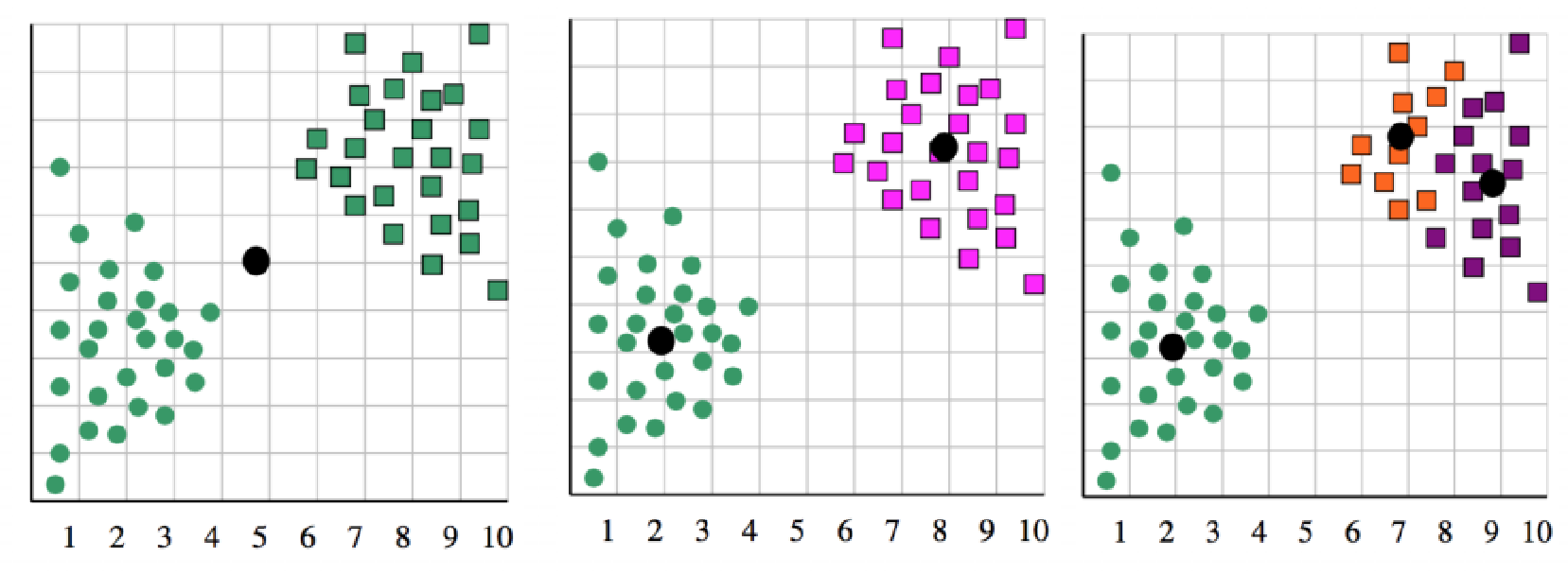
6|1k值的影响:
k过大过小对结果都不好
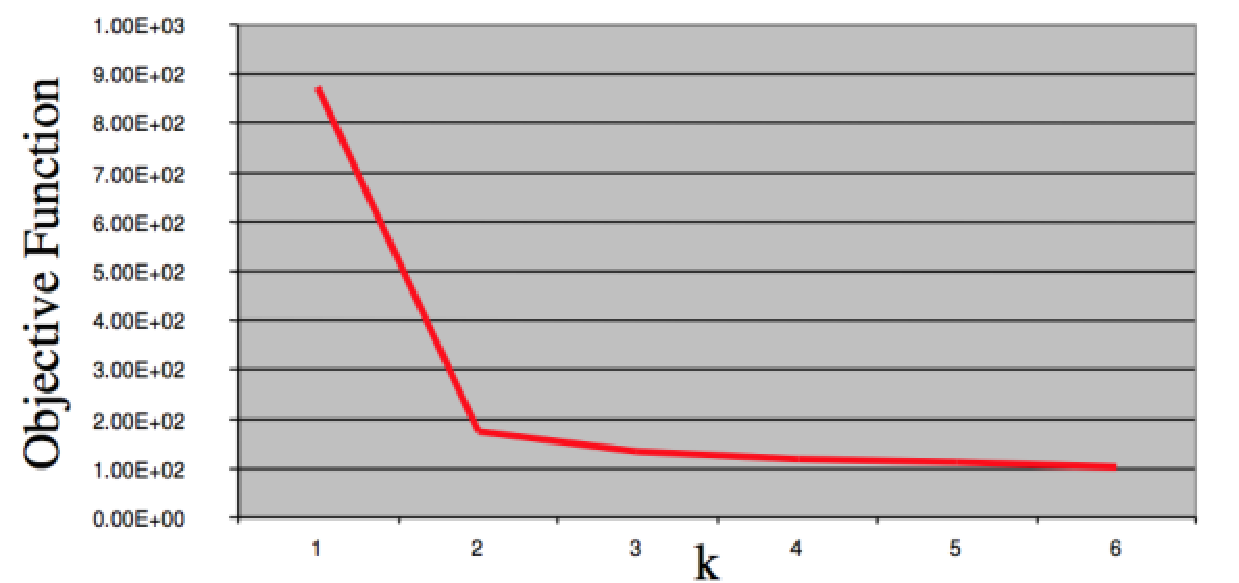
6|2“肘点”法:
选取不同的K值,画出损失函数曲线,选取“肘点”值
7|0 七、优缺点
7|1优点:
1. 易于理解,聚类效果不错;
2. 处理大数据集的时候,该算法可以保证较好的伸缩性和高效率;
3. 当簇近似高斯分布的时候,效果非常不错 。
7|2缺点:
1. k值是用户给定的,进行数据处理前,k值是未知的,不同的k值得到的结果不一样;
2. 对初始簇中心点是敏感的;
3. 对于团状的数据点集区分度好,对于带状(环绕)等“非凸”形状不太好。(用谱聚类或者做特征映射)
4. 对异常点的“免疫力”很差,我们可以通过一些调整(比如中心不直接取均值,而是找均值最近的样本点代替)
8|0八、代码示例
9|0九、层次聚类
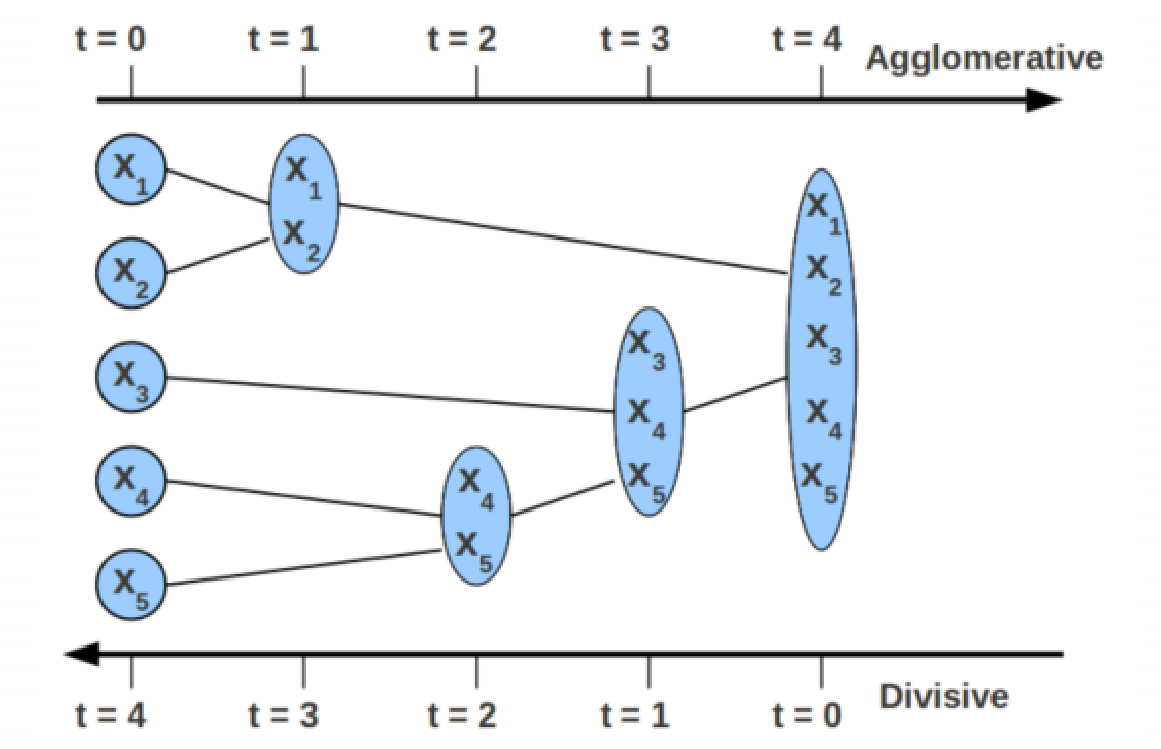
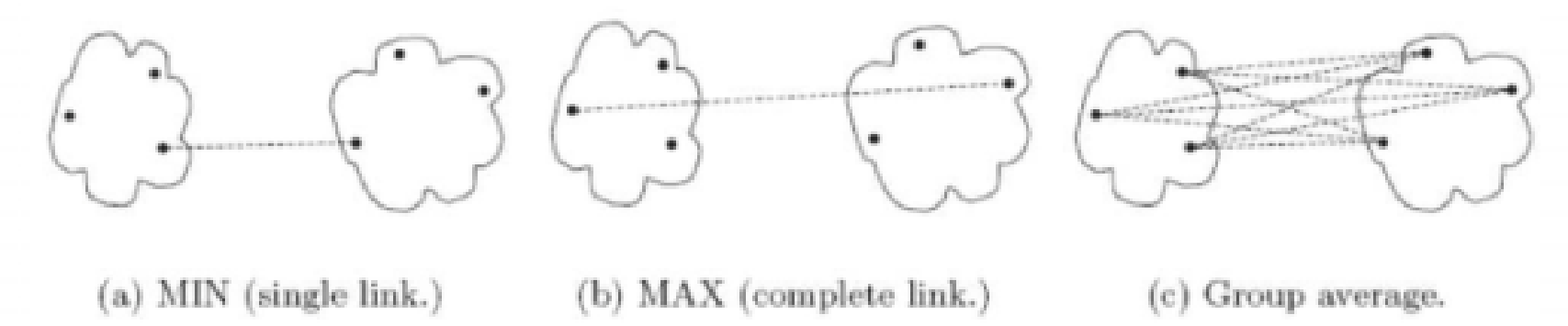
9|1 cluster R和cluster S之间距离怎么界定?

__EOF__
作 者:逸繁
出 处:https://www.cnblogs.com/songyifan427/p/16498805.html
关于博主:编程路上的小学生,热爱技术,喜欢专研。评论和私信会在第一时间回复。或者直接私信我。
版权声明:署名 - 非商业性使用 - 禁止演绎,协议普通文本 | 协议法律文本。
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是博主的最大动力!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 终于写完轮子一部分:tcp代理 了,记录一下
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理