09 mysql高级查询:where、group by、having、order by、limit分页
数据表
学生信息表
-- 学生信息表
create table student(
id int PRIMARY key auto_increment COMMENT '学生id',
name varchar(10) COMMENT '姓名',
gender enum('男','女','保密') default '男' COMMENT '性别,默认 男',
age TINYINT DEFAULT 18 COMMENT '年龄,默认18岁',
hobby set('读书','游戏','睡觉','足球','篮球','羽毛球','乒乓器','跳高') COMMENT '兴趣爱好',
score float comment '分数',
class_id int COMMENT '所属班级 ID'
);
-- 插入数据
INSERT into student VALUES(NULL,'小明','女',20,'足球,篮球',1),
(NULL,'小兰','女',21,'睡觉',2),
(NULL,'张三',default,25,'足球,篮球,跳高',3),
(NULL,'武义','女',26,'足球,篮球',4),
(NULL,'蓝色','女',25,'足球,篮球',5),
(NULL,'李飞',default,21,'足球,篮球',1);
-- 给student 新增一个score 字段
alter table student add scrore float;
班级表
-- 创建 班级信息表
CREATE table class(
id int PRIMARY key auto_increment COMMENT '班级id',
name varchar(20) COMMENT '班级名称'
);
-- 插入数据
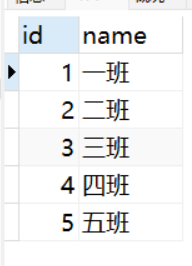
INSERT INTO class(name) VALUES('一班'),('二班'),('三班'),('四班'),('五班');
SELECT * from class;
完整的查询sql语句
select select选项 字段列表 from table表数据源 where where条件 group by group分组条件 having having条件 order by order排序 limit limit限制
1 select选项:
- all 默认,可以省略,表示保存所有查询的结果
- distinct:去重,去除重复记录(所有的字段都相同才是重复的数据)
2 字段列表:
有的时候需要从多张表中获取数据,此时就可能存在不同表中的字段名相同,需要将同名的字段命名成不同的名字,可以使用 别名
语法:
// as 可以省略
字段名 [as] 新的字段名
3 from数据源
数据源只要是 符合二维表结构的数据就可以
单表数据 -- 常用
语法: form 表名
-- member一张表
select * from member;
多表数据 -- 不建议用,没有实际意义
语法:from 表1,表2,....
多表数据查询的时候,得到的结果是:将多表的字段数合并,记录数相乘
意义不大,除了给数据库制造压力
动态数据:数据源是查询得到的二维表
from后面的数据源不是一个实体表,而是一个从表中查询出来的得到的二维结果表
语法:
from (select 字段列表 from 表名) as 新表名
-- from 后面一定要as 重命名
SELECT * from (SELECT * from member2) as m2;
4 聚合函数
count():统计每组中的数量,如果统计的目录是字段,那么不统计为NULL的字段
avg():求平均值
sum():求和
max():求最大值
min():求最小值
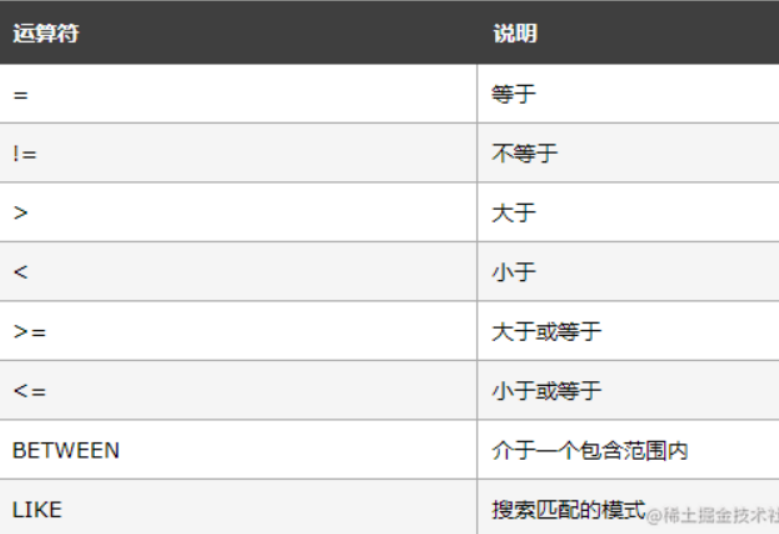
5 where 子句:条件筛选
where 子句:用来从数据表中获取数据的时候,进行条件的筛选,可以得到条件筛选后的数据
where 子句的后面,不可以使用聚合函数
SELECT column FROM table WHERE column operator value
operator 常用运算符如下:
6 group by 子句:分组统计
group by 子句:根据指定的字段,将数据进行分组,主要是用户数据的统计
SELECT列表中的每一列都必须在GROUP BY子句中给出,或者被用作聚合函数的参数
-- 打印每个班级的总人数
SELECT class_id 班级, count(*) '总数' from student GROUP BY class_id;
多分组
将数据按照某个字段进行分组后,对已经分组的数据再次进行分组
-- 语法:先按照字段1分组,之后将结果再按照字段2分组
group by 字段1,字段2...
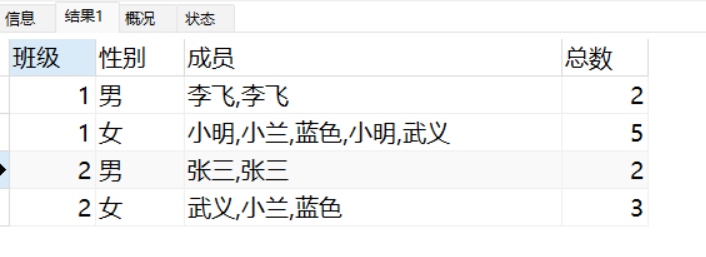
-- 查看每个班级的男女总人数
-- GROUP_CONCAT(name):查看分组中的成员数据
-- 1、 对班级分组
-- 2、 对男女分组
-- ORDER BY class_id:按照班级排序
SELECT class_id 班级,gender '性别',GROUP_CONCAT(name), count(gender) '总数' from student GROUP BY class_id,gender ORDER BY class_id;
分组排序
在mysql中,分组有默认排序功能,一般是按照分组的字段,默认升序
group by 字段 [asc|desc]
回溯统计
当分组进行多分组后,往上统计的过程中,需要层层上报,将这种层层上报统计的过程,称为 回溯统计
语法:
-- 向上回滚
group by 字段 [asc|desc] with rollup;
7 having 子句:分组后的条件筛选
having的本质和where一样,都可以用来进行条件筛选
having 和 where的区别:
-
having子句必须在grouop by 分组后,可以针对分组后的数据进行筛选统计,where不行
-
where 子句的后面,不可以使用聚合函数,having可以在group by 分组后使用聚合函数或者字段别名
-- 查询班级人数大于4的班级
-- 先对 班级进行分组
-- 在对分组后的结果 今天条件筛选 HAVING num>4
SELECT class_id 班级, count(*) as num from student GROUP BY class_id HAVING num>4;
8 order by 排序
语法:
-- asc升序(默认) desc降序
-- 也可以多个字段排序:执行的顺序是 先 按照第一个字段排序,然后再按照第二个字段排序,以此类推...
order by 字段1 asc|desc,字段2 asc|desc..
-- 按照成绩降序排序
SELECT * from student ORDER BY score desc;
9 limit限制
limit限制子句,主要是用来限制记录条数的获取
记录数量限制
-- 语法:
limit 数量;
-- 获取前3条数据
SELECT * from student LIMIT 3;
分页(常用):获取指定区间的数据
-- 语法:
-- offset:从第几条数据开始,默认是从0开始
-- length:获取多少条数据,每页展示的数量
limit offset, length;
-- length:每页展示2条数据
-- 第1页 offset=(page-1)*length=0
SELECT * from student LIMIT 0,2;
-- 第2页 offset=(page-1)*length=2
SELECT * from student LIMIT 2,2;
-- 第3页 offset=(page-1)*length=4
SELECT * from student LIMIT 4,2;
-- 第4页 offset=(page-1)*length=6
SELECT * from student LIMIT 6,2;
10查询中的运算符
算数运算符
一般是用于基本的算数运算,通常不在条件中使用,而是用于运算结果: select 字段1+字段2
+
-
*
/
%
- 在mysql中,除法的运算结果都是浮点数,除法中的除数如果是0,运算后的结果是NULL
- NULL进行任何运算结果都是NULL
比较运算符
通常用来在条件中限定结果
>
>=
<
<=
=
<> 不等于
-- 条件1 必须 小于 条件2
between 条件1 and 条件2;
逻辑运算符
-- 逻辑 与
and
-- 查询60分以上90分以下的数据
SELECT * from student WHERE score>=60 and score<90;
-- 逻辑 或
or
-- 逻辑 非
not
in运算符
表示在 什么什么的里面,通常是操作一个结果集
-- 语法:
in (结果1,结果2,....)
-- 查询id为 1,2,9的学生信息
SELECT * from student WHERE id in (1,2,9);
-- 等价于下面的
SELECT * from student WHERE id=1 or id=2 or id=9;
is运算符
专门用来判断字段是否为NULL的运算符
is null
is not null
-- 查询姓名不为空的数据
SELECT * from student WHERE name is not null;
like运算符:模糊查询
-- 语法
like '匹配模式';
-- 在匹配模式中,有2种常见的
-:匹配对应的单个字符
%:匹配多个字符

 浙公网安备 33010602011771号
浙公网安备 33010602011771号