我看依赖注入
我看依赖注入
new代码味道——狎昵(xia ni)关系:过分亲近
这个主题是我比较想重点聊聊的,因为我个人的理解是依赖注入思想最终想解决的问题就是消除对象之间的耦合,再通俗一点讲就是消除new代码味道,解决的指导思想是将组件的配置和使用分离。
什么是代码味道?
- 如果某段代码可能存在问题,就可以说有代码味道。这里使用“可能”是因为少量的代码味道并不一定就是问题。
- 代码味道还可能表明有技术债务存在,而技术债务的修复是有代价的。背负技术债务越久,债务修复就会越难。
- 代码味道有许多分类。
思考一下为什么除了一些特殊情况外,凡是出现new关键字的地方都是代码味道?
一个示例,展示如何通过实例化对象来破坏代码的自适应能力
public class AccoutController
{
private readonly SecurityService securityService;
public AccountController()
{
this.securityService = new SecurityService();
}
[HttpPost]
public void ChangePassword(long userId,string newPassword)
{
var userRepository = new UserRepository();
var user = userRepository.GetById(userId);
this.securityService.ChangePassword(user,newPassword);
}
}
这段代码就比较接近业务代码了,代码中有下列一些问题,这些问题是由于两个显式调用new关键字的构造对象实例引起的。
- AccoutController类永远依赖SecurityService类以及UserRepository类的具体实现。
- AccoutController类隐式依赖SecurityService类以及UserRepository类的所有依赖。
- AccoutController类很难测试,因为无法使用伪实现(模拟对象或存根)来模拟和替代SecurityService类和UserRepository类。
- SecurityService类的ChangePassword方法需要客户端预选加载好User类的实例对象(变相的依赖)。
详细剖析一下这几个问题。
1.无法增强实现——违反了OCP开闭原则
当我们想改变SecurityService类的实现时,只有两种选择,要么改动AccountController来直接引用新的实现,要么给现有的SecurityService类添加新功能。我们会发现这两种选择都不好。第一种选择违反了对修改关闭,对扩展开放的开闭原则;第二种可能会违反SRP单一职责原则。这样的代码无法增强实现,无异于一锤子买卖。
2.依赖关系链——违反了DIP控制反转原则
AccoutController类依赖SecurityService类,SecurityService类也会有自己的依赖关系。上面的示例代码SecurityService类可能看起来没有什么依赖,但是实际上可能会是这样:
public SecurityService()
{
this.Session = SessionFactory.GetSession();
}
SecurityService类实际上依赖SessionFactory获取Session对象,这就意味着AccoutController类也隐式依赖SessionFactory。违反了DIP控制反转原则:更高层次的模块不能依赖低层模块,两者都应该依赖抽象接口或者抽象类。而示例代码中到处都是对低层模块的依赖。
3.缺乏可测试性——违反了代码的可测试性
代码的可测试性也非常重要,它需要代码以一定的格式构建。如果不这样做,测试将变得极其困难。我们写过单元测试一定知道,单元测试第一步便是要对待测试对象进行依赖隔离,只有这样我们的测试才是稳定的(排除了依赖对象的不稳定性)、可重复的。我们使用的隔离框架moq(其实是所有隔离框架)都是通过使用模拟实现来替代待测试对象的依赖对象工作的。示例代码中依赖的对象在代码编译阶段就已经被确定了,无法在代码运行阶段动态的替换依赖对象,所以也就不具备可测试性了。
对象构造的替代方法
怎样做才可以同时改进AccountController和SecurityService这两个类,或者其他任何不合适的对象构造调用呢?如何才能正确设计和实现这两个类以避免上节所讲述的任何问题呢?下面有一些互补的方式可供选择。
1.针对接口编程
我们首先需要做的改动是将SecurityService类的实现隐藏在一个接口后。这样AccountController类只会依赖SecurityService类的接口而不是它的具体实现。第一个代码重构就是为SecurityService类提取一个接口。
为SecurityService类提取一个接口:
public interface ISecurityService
{
void ChangePassword(long userId,string newPassword);
}
public class SecurityService:ISecurityService
{
public void ChangePassword(long userId,string newPassword)
{
//...
}
}
下一步就是改动客户端代码类调用ISecurityService接口,而不是SecurityService类。
AccountController类现在依赖ISecurityService接口:
public class AccountController
{
private readonly ISecurityService securityService;
public AccountController ()
{
this.securityService = new SecurityService();
}
public void ChangePassword(long userId,string newPassword)
{
securityService.ChangePassword(userId,newPassword);
}
}
重构仍然没有结束,因为依然直接调用了SecurityService类的构造函数,所以重构后的AccountController类依然依赖SecurityService类的具体实现。要将这两个具体类完全解耦,还需要作进一步的重构。引入依赖注入(DI)。
2.使用依赖注入
这个主题比较大,无法用很短的篇幅讲完。并且后面我们会详细的探讨依赖注入,所以现在我只会从使用依赖注入的类的角度来讲解一些基本的要点。
继续我们的重构,重构后的构造函数代码部分已经加粗显示,重构动作的改动非常小,但是管理依赖的能力却大不相同。AccountController类不再要求构造SecurityService类的实例,而是要求它的客户端代码提供一个ISecurityService接口的实现。
使用依赖注入从AccountController类中移除对SecurityService类的依赖:
public class AccountController
{
private readonly ISecurityService securityService;
public AccountController (ISecurityService securityService)
{
if(securityService == null)
{
throw new ArgumentNullException("securityService");
}
this.securityService = securityService;
}
public void ChangePassword(long userId,string newPassword)
{
this.securityService.ChangePassword(userId,newPassword);
}
}
本节我们主要讨论了new代码味道及其缺点,也通过重构代码的方式引出了new代码味道两种互补的方式--针对接口编码和使用依赖注入。之所以说是互补的方式,是因为针对接口编码只能让代码部分解耦,还是没有解决直接调用被依赖类的构造函数的问题;而使用依赖注入虽然解决了这个问题,但是使用依赖注入是依赖于针对接口编程的。可以说只有我们针对接口编码,才有可能使用依赖注入解决掉new代码味道。
忘记是谁说的了,了解学习一件事物之前要先了解学习它的发展历史。学习任何知识,很重要的一点是学习其中的思维方式,看待问题,解决问题的思维方式。所以我希望能通过一个很简单的小游戏力求形象的描述依赖注入的演变历程,以及是什么推进了依赖注入的演变历程。希望大家看完之后都能有所收获,也希望大家看完之后对于依赖注入有自己的理解。让我们开始吧!
鸭猫大战
好了,让我们从最简单的开始,希望我们能从简单到复杂,慢慢理解从面向接口编程到依赖注入的思想:
我现在要设计一个鸭猫大战的游戏,采用标准的OO技术,首先设计一个鸭子的抽象类。
public abstract class Duck
{
public void Eat(){};
public void Run(){};
public abstract void Display();
}
假设在游戏中鸭子的吃东西、跑等行为都是相同的,唯一不同的是鸭子的外观,所以Display方法设置为抽象的,具体的实现在子类中实现。
public class BeijingDuck:Duck
{
public override void Display()
{
//北京鸭
};
}
public class ShandongDuck:Duck
{
public override void Display()
{
//山东鸭
};
}
//其他鸭...
好了,现在鸭鸭大战第一版已经上线了。现在产品想让游戏中的鸭子可以叫,最简单的一种实现方式就是在抽象基类中增加一个Shout()方法,这样所有的继承鸭子类型都可以叫了。不过我们很快就会发现问题来了,这样做的
话所有的所有的鸭子都会叫了,这显然是不符合逻辑的。那么有人肯定会想到使用接口了,将Shout()方法提取到
接口中,然后让会叫的鸭子类型实现接口就可以了。
public interface IShout
{
void Shout();
}
public class BeijingDuck:Duck,IShout
{
public override void Display()
{
//北京鸭
};
public void Shout()
{
//呱呱
}
}
public class ShandongDuck:Duck,IShout
{
public override void Display()
{
//山东鸭
};
public void Shout()
{
//呱呱
}
}
上面的实现看起来很好,但是、但是、但是需求总是在变化的。

现在产品要求鸭子不仅要会叫,而且每种鸭子类型叫声还要求不一样,并且不同的鸭子类型叫声还可能会一样。那么上面的这种实现当时的缺点就显示出来了,代码会在多个子类中重复,并且运行时不能修改(继承体系的缺点,代码在编译时就已经确定,无法动态改变)等。

理解为什么要“面向接口编程,而不要面向实现编程”
接下来我们可以把变化的地方提取出来,多种行为的实现用统一的接口实现。当我们想增加一种行为时,只需要继承接口就可以了,对其它行为没有任何影响。
public interface IShout
{
void Shout();
}
public class GuaGuaShout:IShout
{
public void Shout()
{
//呱呱
}
}
public class GaGaShout:IShout
{
public void Shout()
{
//嘎嘎
}
}
//其他叫声行为类
现在某一种具体的鸭子类型实现就变成了:
public class BeijingDuck:Duck
{
IShout shout;
public BeijingDuck(IShout shout)
{
this.shout = shout;
}
public void Shout()
{
shout.Shout();
}
//可以在运行时动态改变行为
public void SetShout(IShout shout)
{
this.shout = shout;
}
public override void Display()
{
//北京鸭
};
}
这样的设计的优点就在于可以在运行时动态的改变行为,而且在不影响其他类的情况下增加更改行为。所以这样的设计是充满弹性的。而对比前面的设计我们就会发现,之前的设计依赖于继承抽象类和实现接口,这两种设计都依赖于“实现”,对象的行为在编译完成的那一刻就已经被决定了,无法改变。(组合优于继承)
理解为什么要“依赖抽象,而不要依赖具体类”
现在我们要开始鸭猫游戏,首先我们创建一个鸭子对象才能开始游戏,就像下面这样。
//创建一只会呱呱叫的北京鸭
new BeijingDuck(new GuaGuaShout());
//创建一只会嘎嘎叫的北京鸭
new BeijingDuck(new GaGaShout());
//创建一只会嘎嘎叫的北京鸭
new ShandongDuck(new GuaGuaShout());
问题又出现了,代码中充斥着的大量的"new"代码。当我们使用“new”的时候,就是在实例化具体类。当出现实体类的时候,代码就会更缺乏“弹性”。越是缺乏弹性越是难于改造。在后面我们还会继续讨论“new代码味道”。
简单工厂
让我们继续回到游戏。为了增加游戏的交互性,你可以选择鸭或猫中的任一角色开始游戏。如果我们选择了鸭子角色开始游戏,那么我们应该在固定的场景会遇到固定的猫。在波斯会遇到波斯猫,在中国遇到狸花猫,在欧洲遇到挪威森林猫。用简单工厂不难实现。
public interface ICat
{
void Scratch();
}
//波斯猫
public class PersianCat:ICat
{
public void Scratch()
{
//来自波斯猫的挠
}
}
//狸花猫
public class FoxFlowerCat:ICat
{
public void Scratch()
{
//来自狸花猫的挠
}
}
//挪威森林猫
public class NorwegianForestCat:ICat
{
public void Scratch()
{
//来自挪威森林猫的挠
}
}
生产猫的工厂:
public class CatFactory
{
public ICat GetCat(string catType)
{
if(catType.IsNullOrEmpty())
{
return null;
}
if(catType == "PersianCat")
{
return new PersianCat();
}else if(catType == "FoxFlowerCat")
{
return new FoxFlowerCat();
}else if(catType == "NorwegianForestCat")
{
return new NorwegianForestCat();
}
return null;
}
}
使用工厂创建猫对象:
public class FactoryPatternDemo
{
public static void main(String[] args)
{
CatFactory factory = new CatFactory();
//创建波斯猫对象
ICat persianCat = factory.GetCat("PersianCat");
//创建狸花猫对象
ICat foxFlowerCat = factory.GetCat("FoxFlowerCat");
//创建挪威森林猫对象
ICat norwegianForestCat = factory.GetCat("NorwegianForestCat");
}
}
简单工厂设计模式属于创建型模式,它提供了一种创建对象的最佳方式。这是设计模式里对于工厂模式的说明。
工厂模式确实在一定程度上解决了创建对象的难题,项目中不会再到处充斥了“new代码味道”。但是有一个问题没有解决,要实例化哪一个对象,是在运行时由一些条件决定。当一旦有变化或扩展时,就要打开这段代码(工厂实现代码)进行修改,这违反了“对修改关闭”的原则。还有就是这段代码依赖特别紧密,并且是高层依赖底层(客户端依赖具体类(工厂类)的实现),因为判断创建哪种对象是在工厂类中实现的。幸运的是,我们还有“依赖倒置原则”和“抽象工厂模式”来拯救我们。
抽象工厂和依赖倒置原则
客户端(高层组件)依赖于抽象Cat,各种猫咪(底层组件)也依赖于抽象Cat,虽然我们已经创建了一个抽象Cat,但是仍然在代码中创建了具体的Cat,这个抽象其实并没有什么影响力。使用抽象工厂模式可以将这些实例化对象的代码隔离出来。这符合软件设计中的对于可以预见变化的部分,要使用接口进行隔离。让我们继续回到游戏中,之前我们提到过,在固定的场景会遇到固定的游戏角色,所以我们需要为不同游戏场景创建场景对象。
首先我们要创建一个工厂接口:
public interface IFactory
{
ICat CreateCat();
Duck CreateDuck();
}
然后创建创建场景的工厂类:
public class BeijingSceneFactory:IFactory
{
public ICat CreateCat()
{
return new FoxFlowerCat();
}
public Duck CreateDuck()
{
return new BeijingDuck();
}
}
public class ShanDongSceneFactory:IFactory
{
public ICat CreateCat()
{
return new FoxFlowerCat();
}
public Duck CreateDuck()
{
return new ShanDongDuck();
}
}
构建场景类(伪代码):
public class Scene
{
private ICat cat;
private Duck duck;
IFactory factory;
public Scene(IFactory factory)
{
this.factory = factory;
}
public void Create(string role)
{
if(role == "duck")
{
duck = factory.CreateDuck();
}
if(role == "cat")
{
cat = factory.CreateCat();
}
}
}
这样一来,游戏场景改变不由代码来改变,而是由客户端动态的决定。相当于变相的减少了高层对底层的依赖。现在其实我们已经能大体理解依赖倒置的原则:依赖抽象,而不依赖具体类。
客户端代码实现:
public class FactoryPatternDemo
{
public static void main(String[] args)
{
IFactory factory = new BeijingSceneFactory();
Scene scene = new Scene(factory);
scene.Create("duck");
}
}
现在的代码设计已经比较靠近“注入”的概念了(穷人的依赖注入),仔细看 Scene scene = new Scene(factory);,
创建场景的工厂对象是抽象的接口类型,而且是通过构造函数动态传入的,通过这样的改造就为我们使用依赖注入框架提供了可能性。当然在抽象工厂和依赖注入之间,还有一个问题值得我们去思考。这个问题就是“如何将组件的配置和使用分离”,答案也已经很明了了——依赖注入。
理解将组件的配置和使用分离
如果觉得组件这个比较抽象的话,我们可以把“组件”理解为“对象”(底层组件),那么相应的“组件的配置”就理解成为“对象的初始化”。现在“将组件的配置和使用分离”这句话就很好理解了
,就是将对象的创建和使用分离。这样做的优点很明显,将对象的创建推迟到了部署阶段(这句话可能不太好理解),就是说对象的创建全部依赖于我们统一的配置,我们可以修改配置动态的把我们不想使用的对象替换成我们想使用的对象,而不用修改任何使用对象的代码。原则上我们需要把对象的装配(配置)和业务代码(使用)分离开来。
依赖注入
依赖注入(DI)是一个很简单的概念,实现起来也很简单。尽管如此,这种简单性却掩盖了该模式的重要性。当某些事情很简单也很重要时,人们就会将它过度复杂化,依赖注入也一样。要理解依赖注入,我们首先要这个词拆开来解读——依赖和注入。
什么是依赖?
要用文字解释这个概念可能不太好理解(文不如表,表不如图),我们可以使用有向图对依赖建模。一个依赖关系包含了两个实体,它们之间的联系方向是从依赖者到被依赖者。
使用有向图对依赖建模:
A依赖B:
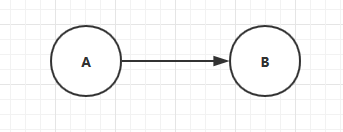
B依赖A:
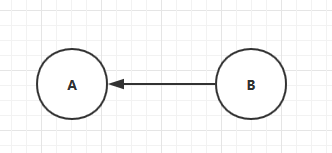
互联网提供很多服务,服务依赖互联网:

包(包括程序集和命名空间)既是客户也是服务:

客户端类依赖服务类:
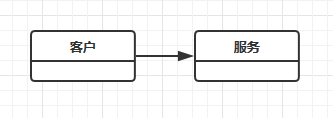
有些服务会隐藏在接口后面:

有向图中有一种特殊的循环叫做自循环:
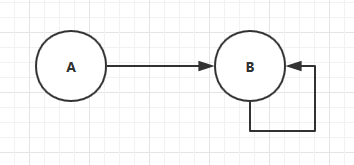
方法层的递归就是一个很好的自循环的例子。
软件系统中的依赖
我们都知道,在采用面向对象设计的软件系统中,万物皆对象。所有的对象通过彼此的合作,完成整个系统的工作。就好比下面的齿轮系统,每个齿轮转动带动整个齿轮系统的运转。但是这样的设计就意味着强依赖,强耦合。如果某个齿轮出问题不转动了,整个齿轮系统就会瘫痪掉,这显然是我们所不能接受的。
图1.软件系统中耦合的对象:

什么是控制反转(IOC)?
耦合关系不仅会出现在对象与对象之间,也会出现在软件系统的各模块之间,以及软件系统和硬件系统之间。如何降低系统之间、模块之间和对象之间的耦合度,是软件工程永远追求的目标之一。为了解决对象之间的耦合度过高的问题,软件专家Michael Mattson提出了IOC理论,用来实现对象之间的“解耦”。目前这个理论已经被成熟的应用到项目当中,衍生出了各式各样的IOC框架产品。
IOC理论提出的观点大致是这样的:借助于“第三方”实现具有依赖关系的对象之间的解耦。如下图:
图2.IOC解耦过程:
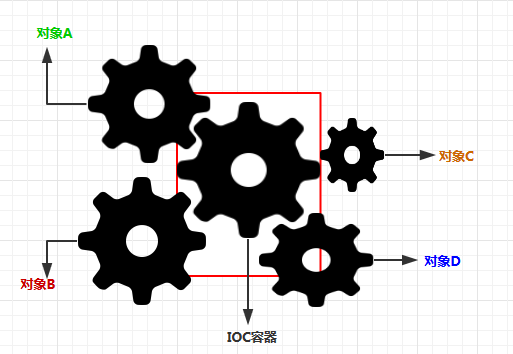
由于引进了中间位置的“第三方”,也就是IOC容器,使得A、B、C、D这4个对象没有了耦合关系,齿轮之间的传动全部依靠“第三方”了,全部对象的控制权全部上缴给“第三方”IOC容器,所以,IOC容器成了整个系统的关键核心,它起到了一种类似“粘合剂”的作用,把系统中的所有对象粘合在一起发挥作用,如果没有这个“粘合剂”,对象与对象之间会彼此失去联系,这就是有人把IOC容器比喻成“粘合剂”的由来。
那么如果我们把IOC容器拿掉,系统会是什么样子呢?
图3.拿掉IOC容器的系统:
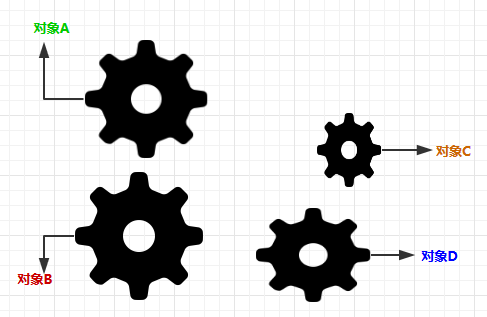
拿掉IOC容器的系统,A、B、C、D这4个对象之间已经没有了耦合关系,彼此毫无联系,这样的话,当你在实现A的时候,根本无须再去考虑B、C和D了,对象之间的依赖关系已经降低到了最低程度。
软件系统在没有引入IOC容器之前,如图1所示,对象A依赖于对象B,那么对象A在初始化或者运行到某一点的时候,自己必须主动去创建对象B或者使用已经创建的对象B。无论是创建还是使用对象B,控制权都在自己手上。软件系统在引入IOC容器之后,这种情形就完全改变了,如图3所示,由于IOC容器的加入,对象A与对象B之间失去了直接联系,所以,当对象A运行到需要对象B的时候,IOC容器会主动创建一个对象B注入到对象A需要的地方。通过前后的对比,我们不难看出来:对象A获得依赖对象B的过程,由主动行为变为了被动行为,控制权颠倒过来了,这就是“控制反转”这个名称的由来。
什么是依赖注入?
2004年,Martin Fowler探讨了同一个问题,既然IOC是控制反转,那么到底是“哪些方面的控制被反转了呢?”,经过详细地分析和论证后,他得出了答案:“获得依赖对象的过程被反转了”。控制被反转之后,获得依赖对象的过程由自身管理变为了由IOC容器主动注入。于是,他给“控制反转”取了一个更合适的名字叫做“依赖注入(Dependency Injection)”。他的这个答案,实际上给出了实现IOC的方法:注入。所谓依赖注入,就是由IOC容器在运行期间,动态地将某种依赖关系注入到对象之中。
所以现在我们知道,控制反转(IOC)和依赖注入(DI)是从不同角度对同一件事物的描述。就是通过引入IOC容器,利用注入依赖关系的方式,实现对象之间的解耦。
使用控制反转(IOC)容器
我们在开发时经常会遇到这种情况,开发中的类委托某些抽象完成动作,而这些被委托的抽象又被其他的类实现,这些类又委托其他的一些抽象完成某种动作。最终,在依赖链终结的地方,都是一些小且直接的类,它们已经不需要任何依赖了。我们已经知道如何通过手动构造类实例并把它们传递给构造函数的方式来实现依赖注入的效果(穷人的依赖注入)。尽管这种方式可以任意替换依赖的实现,但是构造的实例对象图依旧是静态的,也就是说编译时就已经确定了。控制反转允许我们将构建对象图的动作推迟到运行时。
控制反转容器组成的系统能够将应用程序使用的接口和它的实现类关联起来,并能在获取实例的的同时解析所有相关的依赖。
示例代码中没有手动构造实现的实例,而是通过使用Unity控制反转容器来建立类和接口的映射关系:
public partial class App:Application
{
private IUnityContainer container;
private void OnApplicationStartUp()
{
container = new UnityContainer();
container.RegisterType<ISettings,ApplicationSettings>();
container.RegisterType<ITaskService,TaskService>();
var taskService = container.Resolve<ITaskService>();
}
}
1.代码的第一步就是初始化得到一个UnityContainer实例。
2.在创建好Unity容器后,我们需要告诉该容器应用程序生命周期内每个接口对应的具体实现类是什么。Unity遇到任何接口时,都会知道去解析哪个实现。如果我们没有为某个接口指定对应的实现类,Unity会提醒我们该接口无法实例化。
3.在完成接口和对应实现类的关系注册后,我们需要获得一个TaskService类的实例。Unity容器的Resolve方法会检查TaskService类的构造函数,然后尝试去实例化构造函数要注入的依赖项。如此反复,直到完全实例化整个依赖链上的所有依赖项的实例后,Resolve方法会成功实例化TaskService类的实例。
控制反转(IOC)容器的工作模式——注册、解析、释放模式
所有的控制反转容器都符合一个只有三个的方法的简单接口,Unity也不例外。
尽管每个控制反转容器实现不完全相同,但是都符合下面这个通用的接口:
public interface IContainer:IDisposable
{
void Register<TInterface,TImplementation>()
where TImplementation:TInterface;
TImplementation Resolve<TInterface>();
void Release();
}
- Register:应用程序首先会调用此方法。而且该方法会被多次调用以注册不同的接口及其实现之间的映射关系。这里的Where子句用来强制TImplementation类型必须实现它所继承的TInterface接口。
- Resolve:应用程序运行时会调用此方法获取对象实例。
- Release:应用程序生命周期中,当某些类的的实例不再需要时,就可以调用此方法释放它们占用的资源。这有可能发生在应用程序结束时,也有可能发生在应用程序运行的某个恰当时机。
我们都知道在我们使用的Unity容器注册时可以配置是否开启单例模式。通常情况下,资源只对单次请求有效,每次请求后都会调用Release方法。但是当我们配置开启单例模式时,只有在应用程序关闭时才会调用Release方法。
命令式与声明式注册
到此为止,我们都是使用的命令式注册:命令式的从容器对象上调用方法。
命令式注册优点:
-
比较简洁,易读。
-
编译时检查问题的代价非常小(比如防止代码输入错误等)。
命令式注册缺点: -
注册的过程在编译时已经确定了,如果想要替换实现,必须修改源代码,然后重新编译。
如果通过XML配置进行声明式注册,就不需要重新编译。
应用程序配置文件:
<configuration>
<configSections name="unity"
type="Microsoft.Practices.Unity.Configuration.UnityConfigurationSection">
</configSections>
<unity>
<container>
<register type="ISettings" mapTo="ApplicationSettings"/>
<register type="ITaskService" mapTo="TaskService"/>
</container>
</unity>
</configuration>
应用程序入口:
public partial class App:Application
{
private IUnityContainer container;
private void OnApplicationStartUp()
{
var section = (UnityConfigurationSection)ConfigurationManager.GetSection("unity");
container = new UnityContainer().LoadConfiguration(section);
var taskService = container.Resolve<ITaskService>();
}
}
声明式注册优点:
- 将接口和相应的实现的映射动作推迟到配置时。
声明式注册缺点: - 太繁琐,配置文件会巨大。
- 注册时的错误会跳过编译,直到运行时才能被发现和捕获。
三种依赖注入方式及其优缺点
首先大家思考一下为什么在项目中会要求大家在控制器层使用属性注入,在业务逻辑层使用构造函数注入?
1.构造函数注入
public class TaskService
{
private ITaskOneRepository taskOneRepository;
private ITaskTwoRepository taskTwoRepository;
public TaskService(
ITaskOneRepository taskOneRepository,
ITaskTwoRepository taskTwoRepository)
{
this.taskOneRepository = taskOneRepository;
this.taskTwoRepository = taskTwoRepository;
}
}
优点:
- 在构造方法中体现出对其他类的依赖,一眼就能看出这个类需要其他那些类才能工作。
- 脱离了IOC框架,这个类仍然可以工作(穷人的依赖注入)。
- 一旦对象初始化成功了,这个对象的状态肯定是正确的。
缺点:
- 构造函数会有很多参数。
- 有些类是需要默认构造函数的,比如MVC框架的Controller类,一旦使用构造函数注入,就无法使用默认构造函数。
2.属性注入
public class TaskService
{
private ITaskRepository taskRepository;
private ISettings settings;
public TaskService(
ITaskRepository taskRepository,
ISettings settings)
{
this.taskRepository = taskRepository;
this.settings = settings;
}
public void OnLoad()
{
taskRepository.settings = settings;
}
}
优点:
- 在对象的整个生命周期内,可以随时动态的改变依赖。
- 非常灵活。
缺点:
- 对象在创建后,被设置依赖对象之前这段时间状态是不对的(从构造函数注入的依赖实例在类的整个生命周期内都可以使用,而从属性注入的依赖实例还能从类生命周期的某个中间点开始起作用)。
- 不直观,无法清晰地表示哪些属性是必须的。
3.方法注入
public class TaskRepository
{
private ISettings settings;
public void PrePare(ISettings settings)
{
this.settings = settings;
}
}
优点:
- 比较灵活。
缺点:
- 新加入依赖时会破坏原有的方法签名,如果这个方法已经被其他很多模块用到就很麻烦。
- 与构造方法注入一样,会有很多参数。
相信大家现在一定理解了项目中某一层指定某一种注入方式的原因:利用其优点,规避其缺点。
组合根和解析根
1.组合根
应用程序中只应该有一个地方直到依赖注入的细节,这个地方就是组合根。在使用穷人的依赖注入时就是我们手动构造类的地方,在使用控制反转容器时就是我们注册接口和实现类间映射关系的地方。组合根提供了一个查找依赖注入配置的公认位置,它能帮你避免把对容器的依赖扩散到应用程序的其他地方。
2.解析根
和组合根密切相关的一个概念是解析根。它是要解析的目标对象图中根节点的对象类型。
这样讲很抽象,举个例子:
MVC应用程序的解析根就是控制器。来自浏览器的请求都会被路由到被称为动作(action)的控制器方法上。每当请求来临时,MVC框架会将URL映射为某个控制器名称,然后找到对应名称的类实例化它,最后在该实例上触发动作。更确切的讲,实例化控制器的过程就是解析控制器的过程。这意味着,我们能轻易的按照注册、解析和释放的模式,最小化对Resolve方法的调用,理想状况下,就只应该在一个地方调用该方法。
组合根和解析根又是前面所讲的“将组件的配置和使用分离”一种体现。
依赖注入的技术点
IOC中最基本的技术就是“反射(Reflection)”编程。有关反射的相关概念大家应该都很清楚,通俗的讲就是代码运行阶段,根据给出的信息动态的生成对象。
总结
做一下总结,我们从new代码味道出发,引出了消除new代码味道(代码解耦)的两种方式——针对接口编码和使用依赖注入。然后我们通过开发一个小游戏,了解了面向接口编程到依赖注入的历程。最后深入了介绍了大Boss——控制反转(依赖注入),主要介绍了什么是依赖,控制反转(依赖注入)的概念,使用控制反转(IOC)容器,工作模式,命令式与声明式注册,三种依赖注入方式及其优缺点,组合根和解析根,依赖注入的技术点。
本次分享力求从原理和思想层面剖析依赖注入。因为我水平有限,可能有些点讲的有些片面或不够深入,所以给出我准备这次分享的参考资料。有兴趣深入研究的同学,可以自行去看一下这些资料:
1.C#敏捷开发实践
第2章 依赖和分层
第9章 依赖注入原则

2.HeadFirst设计模式
鸭猫大战改编自第一章 设计模式入门


