java-Stream的总结
JAVA中的Stream
01.什么是Stream
Stream是JDK8中引入,Stream是一个来自数据源的元素序列并支持聚合操作。可以让你以一种声明的方式处理数据,Stream 使用一种类似用 SQL 语句从数据库查询数据的直观方式来提供一种对 Java 集合运算和表达的高阶抽象。Stream API可以极大提高Java程序员的生产力,让程序员写出高效率、干净、简洁的代码。
02.Stream特点
- 元素:是特定类型的对象,形成一个序列。 Java中的Stream并不会存储元素,而是按需计算。
- 数据源:流的来源可以是集合,数组,I/O channel等。
- 过滤、聚合、排序等操作:类似SQL语句一样的操作, 比如filter, map, reduce, find, match, sorted等
- Pipelining(流水线/管道): 中间操作都会返回流对象本身。 这样多个操作可以串联成一个管道, 如同流式风格(fluent style)。 这样做可以对操作进行优化, 比如延迟执行(laziness)和短路( short-circuiting)。
- 内部迭代: 以前对集合遍历都是通过Iterator或者For-Each的方式, 显式的在集合外部进行迭代, 这叫做外部迭代。 Stream提供了内部迭代的方式。
- 只能遍历一次:数据流的从一头获取数据源,在流水线上依次对元素进行操作,当元素通过流水线,便无法再对其进行操作
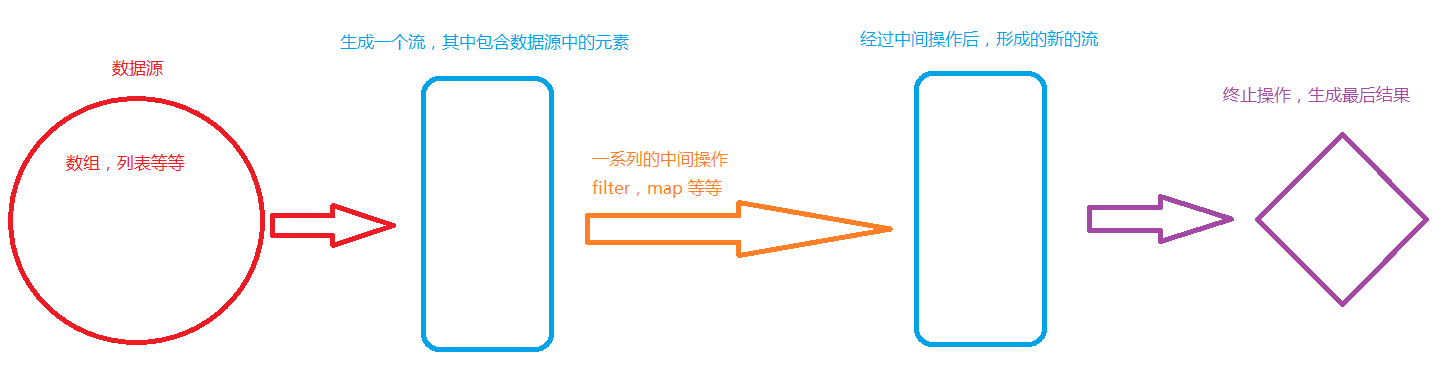
一个stream是由三部分组成的。数据源,零个或一个或多个中间操作,一个或零个终止操作。
中间操作是对数据的加工,注意:中间操作是lazy操作,并不会立马启动,需要等待终止操作才会执行。
终止操作是stream的启动操作,只有加上终止操作,stream才会真正的开始执行。
03.Stream入门案例
//要求把list1中的空字符串过滤掉,并把结果保存在列表中
public class Test {
public static void main(String[] args) {
List<String> list1 = Arrays.asList("ab", "", "cd", "ef", "mm","", "hh");
System.out.println(list1);//[ab, , cd, ef, mm, , hh]
List<String> result = list1.stream().filter(s -> !s.isEmpty()).collect(Collectors.toList());
System.out.println(result);//[ab, cd, ef, mm, hh]
}
}
上面这个例子可以看出list1是一个字符串的列表,其中有两个空字符串,在stream的操作过程中,我们使用了stream()、filter()、collect()等方法,在filter()过程中,我们引入了Lambda表达式s->!s.isEmpty(),结果是把两个空字符串过滤掉后,形成了一个新的列表result。
上面这个需求如果我们使用传统的代码完成如下:
public class Test {
public static void main(String[] args) {
List<String> list1 = Arrays.asList("ab", "", "cd", "ef", "mm","", "hh");
List<String> result = new ArrayList<>();
for (String str : list1) {
if(str.isEmpty()){
continue;
}
result.add(str);
}
System.out.println(result);
}
}
比较两段代码,我们可以发现在第二段代码中我们自己创建了一个字符串对象列表,开启一个for循环遍历字符串对象列表,在for循环中判断是否当前的字符串是空串,如果不是,加到结果列表中。而在第一段程序中,我们并不需要自己开启for循环遍历,stream会在内部做迭代,我们只需要传入我们的过滤条件就可以了,最后这个字符串列表也是代码自动创建出来的,并且把结果放入了列表中,可以看出,第一段代码简洁优雅。
04.Stream操作分类
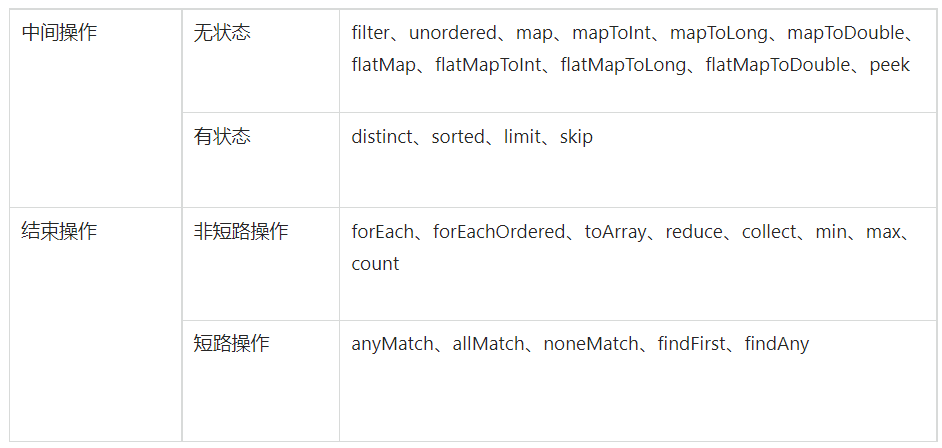
- 无状态:指元素的处理不受之前元素的影响;
- 有状态:指该操作只有拿到所有元素之后才能继续下去。
- 非短路操作:指必须处理所有元素才能得到最终结果;
- 短路操作:指遇到某些符合条件的元素就可以得到最终结果,如 A || B,只要A为true,则无需判断B的结果。
05.Stream使用案例
5.1.创建流
5.1.1.使用Collection下的 stream() 和 parallelStream() 方法
public class Test {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
Stream<String> stream = list.stream(); //获取一个串行流
Stream<String> parallelStream = list.parallelStream(); //获取一个并行流
}
}
5.1.2.使用Arrays 中的 stream() 方法,将数组转成流
public class Test {
public static void main(String[] args) {
Integer[] nums = new Integer[10];
Stream<Integer> stream = Arrays.stream(nums);
}
}
5.1.3.使用Stream中的静态方法:of()、iterate()、generate()
public class Test {
public static void main(String[] args) {
Stream<Integer> stream = Stream.of(1,2,3,4,5,6);
stream.forEach(System.out::print);//1 2 3 4 5 6
System.out.println("==========");
Stream<Integer> stream2 = Stream.iterate(0, (x) -> x + 2).limit(6);
stream2.forEach(System.out::print); // 0 2 4 6 8 10
System.out.println("==========");
Stream<Double> stream3 = Stream.generate(Math::random).limit(2);
stream3.forEach(System.out::print);//随机产生两个小数
}
}
5.1.4.使用 BufferedReader.lines() 方法,将每行内容转成流
public class Test {
public static void main(String[] args) throws FileNotFoundException {
BufferedReader reader = new BufferedReader(new FileReader("d:\\study\\demo\\test_stream.txt"));
Stream<String> lineStream = reader.lines();
lineStream.forEach(System.out::println);
}
}
5.1.5.使用 Pattern.splitAsStream() 方法,将字符串分隔成流
public class Test {
public static void main(String[] args) {
Pattern pattern = Pattern.compile(",");
Stream<String> stringStream = pattern.splitAsStream("tom,jack,jerry,john");
stringStream.forEach(System.out::println);
}
}
5.2.中间操作
5.2.1.筛选与切片
- filter:过滤流中的某些元素
- limit(n):获取n个元素
- skip(n):跳过n元素,配合limit(n)可实现分页
- distinct:通过流中元素的 hashCode() 和 equals() 去除重复元素
//filter 测试
public class Test {
public static void main(String[] args) {
List<String> list = Arrays.asList("aaa", "ff", "dddd","eeeee","hhhhhhh");
//把字符串长度大于3的过滤掉
Stream<String> stringStream = list.stream().filter(s -> s.length() <= 3);
stringStream.forEach(System.out::println);
System.out.println("===================");
//验证整个流只遍历一次
//stream只有遇到终止操作才会触发流启动,中间操作都是lazy
Stream.of(1, 2, 3, 4, 5)
.filter(i -> {
System.out.println("filter1的元素:" + i);
return i > 0;
}).filter(i -> {
System.out.println("filter2的元素:" + i);
return i == 5;
}).forEach(i-> System.out.println("最后结果:"+i));
}
}
//limit 测试
public class Test {
public static void main(String[] args) {
List<String> list = Arrays.asList("aaa", "ff", "dddd","eeeee","hhhhhhh");
//取三个元素
List<String> result = list.stream().limit(3).collect(Collectors.toList());
System.out.println(result);
}
}
//limit 和 skip 测试
public class Test {
public static void main(String[] args) {
List<String> list = Arrays.asList("11", "22", "33","44","55","66","77","88","99");
//演示skip:跳过前三条记录
list.stream().skip(3).forEach(System.out::println);
//模拟翻页,每页3条记录
//第一页
List<String> page1= list.stream().skip(0).limit(3).collect(Collectors.toList());
System.out.println(page1);
//第二页
List<String> page2= list.stream().skip(3).limit(3).collect(Collectors.toList());
System.out.println(page2);
//第三页
List<String> page3= list.stream().skip(6).limit(3).collect(Collectors.toList());
System.out.println(page3);
//limit和skip顺序换一下
//可以看出,最终的结果会收到执行顺序的影响
List<String> page4= list.stream().limit(3).skip(1).collect(Collectors.toList());
System.out.println(page4);
}
}
//distinct去重测试
//注意:当我们自己重写hashcode和equals的方法的时候,要遵循一个原则:
//如果两个对象的hashcode相等,那么用equals比较不一定相等;反之,如果两个对象用equals比较相等,那么他们的hashcode也一定相等
public class Student {
private Integer id;
private String name;
public Student(Integer id, String name) {
this.id = id;
this.name = name;
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
return getId().equals(student.getId()) &&
getName().equals(student.getName());
}
@Override
public int hashCode() {
return Objects.hash(getId(), getName());
}
@Override
public String toString() {
return "Student{" +
"id=" + id +
", name='" + name + '\'' +
'}';
}
}
//去掉重复的student
//1.Student类的hashcode和equals包含了id和name
//2.Student类的hashcode和equals中只包含name
public class Test {
public static void main(String[] args) {
List<Student> studentList = Arrays.asList(
new Student(1, "zhangsan"),
new Student(6, "zhangsan"),
new Student(2, "lisi"),
new Student(5, "lisi"),
new Student(3, "wangwu"));
//1.学生对象去重
List<Student> result = studentList.stream().distinct().collect(Collectors.toList());
System.out.println(result);
//2.普通字符串去重
Stream<String> stringStream = Stream.of("a", "a", "b", "c", "d");
List<String> stringList = stringStream.distinct().collect(Collectors.toList());
System.out.println(stringList);
}
}
5.2.2.映射(map和flatMap)
public class Test {
public static void main(String[] args) {
//第一个例子对比
List<String> list = Arrays.asList("a,b,c", "1,2,3");
//将每个元素转成一个新的且不带逗号的元素
//注意:这里元素是值在list中的元素,一共有两个,分别是"a,b,c" 和"1,2,3"
//map函数传入的lambda表达式就是我们的转换逻辑,需要返回一个转换之后的元素
Stream<String> s1 = list.stream().map(s -> s.replaceAll(",", ""));
s1.forEach(System.out::println); // abc 123
System.out.println("===============");
List<Integer> integerList = Arrays.asList(1, 2, 3);
integerList.stream().map(i->i*2).forEach(System.out::println);
System.out.println("===============");
//将每个元素转换成一个stream
//注意:flatMap跟上面的map函数对比
//两者传入的lambda都是转换逻辑,但是map中的lambda返回的是一个转换后的新元素,
//flatMap可以把每一个元素进一步处理:例如"a,b,c"进一步分隔成a b c三个元素
//返回的是这三个元素形成的三个stream,最终把这些单独的stream合并成一个stream返回
//总结:可以看出,flatMap相比于map,它可以把每一个元素再进一步拆分成更多的元素,
// 最后,拆分出来的元素个数会多于最初输入的列表中的元素个数
//就这个例子而言,最初输入两个元素"a,b,c" 和"1,2,3",结果是6个元素 a b c 1 2 3
Stream<String> s3 = list.stream().flatMap(s -> {
String[] split = s.split(",");
Stream<String> s2 = Arrays.stream(split);
return s2;
});
s3.forEach(System.out::println); // a b c 1 2 3
System.out.println("===============");
//第二个例子(嵌套的list)[["a","b","c"],["d","e","f"],["h","k"]]
//输出结果要求是:["A","B","C","D","E","F","G","H"]
List<List<String>> nestedList = Arrays.asList(
Arrays.asList("a","b","c"),
Arrays.asList("d","e","f"),
Arrays.asList("h","k")
);
Stream<String> s4 = nestedList.stream()
.flatMap(Collection::stream)
.map(s -> s.toUpperCase());
s4.forEach(System.out::print);
}
}
5.2.3.排序
- sorted():自然排序,流中元素需实现Comparable接口
- sorted(Comparator com):定制排序,自定义Comparator排序器
//字符串排序
public class Test {
public static void main(String[] args) {
List<String> list = Arrays.asList("aaa", "ff", "dddd");
//String 类自身已实现Compareable接口,可以按照字符的自然顺序【升序】排序
list.stream().sorted().forEach(System.out::println);// aaa dddd ff
System.out.println("=====");
//给sorted函数传入一个lambda表达式
//1.自定义排序规则,按照字符串的长度【升序】排序,也就是字符串长度最短的排在最前面
list.stream().sorted((s1,s2)->s1.length()-s2.length()).forEach(System.out::println);//ff aaa dddd
System.out.println("=====");
//2.自定义排序规则,按照字符串的长度【降序】排序,也就是字符串长度最长的排在最前面
list.stream().sorted((s1,s2)->s2.length()-s1.length()).forEach(System.out::println);//dddd aaa ff
}
}
//对象排序
public class Employee {
private String name;
private Integer salary;
public Employee(String name,Integer salary) {
this.name = name;
this.salary = salary;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getSalary() {
return salary;
}
public void setSalary(Integer salary) {
this.salary = salary;
}
@Override
public String toString() {
return "Employee{" +
"name='" + name + '\'' +
", salary=" + salary +
'}';
}
}
//测试类
public class Test {
public static void main(String[] args) {
List<Employee> list = Arrays.asList(
new Employee("Tom",1000),
new Employee("Jack",900),
new Employee("John",1300),
new Employee("Jack",2000)
);
//自定义排序规则,先按照名称【升序】,如果名称相同,再按照工资【降序】
list.stream().sorted((e1,e2)->{
if(e1.getName().equals(e2.getName())){
return e2.getSalary()-e1.getSalary();
}else{
return e1.getName().compareTo(e2.getName());
}
}).forEach(System.out::println);
//输出结果:
// Employee{name='Jack', salary=2000}
// Employee{name='Jack', salary=900}
// Employee{name='John', salary=1300}
// Employee{name='Tom', salary=1000}
//打印原始列表,看看是否被改变,注意我们通过stream进行排序操作,原始的列表元素顺序没有变化,也就是说我们没有修改原始的list
System.out.println(list);
//Stream排序和集合本身的排序方法对比
//我们使用List接口本身的sort方法再来排序一下看看
list.sort((e1,e2)->{
if(e1.getName().equals(e2.getName())){
return e2.getSalary()-e1.getSalary();
}else{
return e1.getName().compareTo(e2.getName());
}
});
//排序后再次打印一下list本身,可以发现,list本身元素的顺序被修改过了
System.out.println(list);
}
}
5.2.4.消费
peek:如同于map,能得到流中的每一个元素。但map接收的是一个Function表达式,有返回值;而peek接收的是Consumer表达式,没有返回值。
//为Tom增加500工资
public class Test {
public static void main(String[] args) {
List<Employee> list = Arrays.asList(
new Employee("Tom",1000),
new Employee("John",1300),
new Employee("Jack",2000)
);
//如果是Tom,工资增加500
list.stream().peek(e->{
if("Tom".equals(e.getName())){
e.setSalary(500+e.getSalary());
}
}).forEach(System.out::println);
//输出结果
// Employee{name='Tom', salary=1500}
// Employee{name='John', salary=1300}
// Employee{name='Jack', salary=2000}
}
}
5.3.终止操作
5.3.1.匹配
public class Test {
public static void main(String[] args) {
List<Integer> list = Arrays.asList(2, 1, 3, 4, 5);
//流中所有的元素都匹配,返回true,否则返回false
boolean allMatch = list.stream().allMatch(e -> {
System.out.println(e);
return e > 10;
}); //false
System.out.println("allMatch:"+allMatch);
//流中没有任何的元素匹配,返回true,否则返回false
boolean noneMatch = list.stream().noneMatch(e -> {
System.out.println(e);
return e > 10;
}); //true
System.out.println("noneMatch:"+noneMatch);
//流中只要有任何一个元素匹配,返回true,否则返回false
boolean anyMatch = list.stream().anyMatch(e -> {
System.out.println(e);
return e > 1;
}); //true
System.out.println("anyMatch:"+anyMatch);
//返回流的第一个元素
Integer findFirst = list.stream().findFirst().get(); //2
System.out.println("findFirst"+findFirst);
//返回流中的任意元素
Integer findAny = list.stream().findAny().get(); //2
System.out.println("findAny:"+findAny);
}
}
5.3.2.聚合
public class Test {
public static void main(String[] args) {
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5);
//计算元素总的数量
long count = list.stream().count(); //5
System.out.println(count);
//找出最大的元素(需要传入Lambda比较器)
Integer max = list.stream().max(Integer::compareTo).get(); //5
System.out.println(max);
//找出最小元素(需要传入Lambda比较器)
Integer min = list.stream().min(Integer::compareTo).get(); //1
System.out.println(min);
}
}
5.3.3.归约
在java.util.stream.Stream接口中,reduce有下面三个重载的方法
/**
第一次执行时,accumulator函数的第一个参数为流中的第一个元素,第二个参数为流中元素的第二个元素;第二次执行时,第一个参数为第一次函数执行的结果,第二个参数为流中的第三个元素;依次类推。
*/
Optional<T> reduce(BinaryOperator<T> accumulator);
/**
流程跟上面一样,只是第一次执行时,accumulator函数的第一个参数为identity,而第二个参数为流中的第一个元素。
*/
T reduce(T identity, BinaryOperator<T> accumulator);
/**
在串行流(stream)中,该方法跟第二个方法一样,即第三个参数combiner不会起作用。
在并行流(parallelStream)中,我们知道流被fork join创建出多个线程进行执行,此时每个线程的执行流程就跟第二个方法reduce(identity,accumulator)一样,而第三个参数combiner函数,则是将每个线程的执行结果当成一个新的流,然后使用第一个方法reduce(accumulator)流程进行归约。
*/
<U> U reduce(U identity,
BiFunction<U, ? super T, U> accumulator,
BinaryOperator<U> combiner);
归约应用举例
public class Test {
public static void main(String[] args) {
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
Integer v = list.stream().reduce((a1, a2) -> a1 + a2).get();
System.out.println("reduce计算v="+v); // 55
Integer v1 = list.stream().reduce(10, (a1, a2) -> a1 + a2);
System.out.println("reduce计算v1="+v1); //65
Integer v2 = list.stream().reduce(0,
(a1, a2) -> {
return a1 + a2;
},
(a1, a2) -> {
return 1000; //第二个表达式在串行流中无效,这里返回1000测试
});
System.out.println("reduce计算v2="+v2);
//并行流reduce传三个参数
Integer v3 = list.parallelStream().reduce(0,
(a1, a2) -> {
System.out.println(Thread.currentThread().getName()+":parallelStream accumulator: a1:" + a1 + " a2:" + a2);
return a1 + a2;
},
(a1, a2) -> {
System.out.println(Thread.currentThread().getName()+":parallelStream combiner: a1:" + a1 + " a2:" + a2);
return a1 + a2;
});
System.out.println("并行流reduce计算v3=:"+v3);
}
}
5.3.4.收集
collect:接收一个Collector实例,将流中元素收集成另外一个数据结构
<R, A> R collect(Collector<? super T, A, R> collector);
应用举例:
//创建一个Person类
public class Person {
private String name;
private String sex;
private Integer age;
public Person(String name, String sex, Integer age) {
this.name = name;
this.sex = sex;
this.age = age;
}
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", sex='" + sex + '\'' +
", age=" + age +
'}';
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getSex() {
return sex;
}
public void setSex(String sex) {
this.sex = sex;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
}
public class Test {
public static void main(String[] args) {
//1.collect(Collectors.toList()) 把流转换成一个列表(允许重复值)
Stream<String> stringStream = Stream.of("aa","bb","dd","ee","bb");
List<String> listResult = stringStream.collect(Collectors.toList());
System.out.println(listResult);//[aa, bb, dd, ee, bb]
//2.collect(Collectors.toSet()) 把流转换成一个集合(去重)
Stream<String> stringStream1 = Stream.of("aa","bb","dd","ee","bb");
Set<String> setResult = stringStream1.collect(Collectors.toSet());
System.out.println(setResult);//[aa, bb, dd, ee]
//3.collect(Collectors.toCollection(LinkedList::new)) 把流转换成一个指定的集合类型(LinkedList)
Stream<String> stringStream2 = Stream.of("aa","bb","dd","ee","bb");
LinkedList<String> linkedListResult = stringStream2.collect(Collectors.toCollection(LinkedList::new));
System.out.println(linkedListResult);//[aa, bb, dd, ee, bb]
//4.collect(Collectors.toCollection(ArrayList::new)) 把流转换成一个指定的集合类型(ArrayList)
Stream<String> stringStream3 = Stream.of("aa","bb","dd","ee","bb");
ArrayList<String> arrayListResult = stringStream3.collect(Collectors.toCollection(ArrayList::new));
System.out.println(arrayListResult);//[aa, bb, dd, ee, bb]
//5.collect(Collectors.toCollection(TreeSet::new)) 把流转换成一个指定的集合类型(TreeSet)
Stream<String> stringStream4 = Stream.of("aa","bb","dd","ee","bb");
TreeSet<String> treeSetResult = stringStream4.collect(Collectors.toCollection(TreeSet::new));
System.out.println(treeSetResult);//[aa, bb, dd, ee]
//6.collect(Collectors.joining()) 使用joining拼接流中的元素
Stream<String> stringStream5 = Stream.of("A","B","C","D","E");
String result5 = stringStream5.collect(Collectors.joining());
System.out.println(result5);//ABCDE
//7.collect(Collectors.joining("-")) 使用joining拼接流中的元素并指定分隔符
Stream<String> stringStream6 = Stream.of("A","B","C","D","E");
String result6 = stringStream6.collect(Collectors.joining("-"));
System.out.println(result6);//A-B-C-D-E
//7.collect(Collectors.joining("-","<",">")) 使用joining拼接流中的元素并指定分隔符
Stream<String> stringStream7 = Stream.of("A","B","C","D","E");
String result7 = stringStream7.collect(Collectors.joining("-","<",">"));
System.out.println(result7);//<A-B-C-D-E>
//8.collect(Collectors.groupingBy(Person::getSex) 对person流按照性别进行分组
Stream<Person> stringStream8 = Stream.of(
new Person("zhangsan", "男", 10),
new Person("lisi", "女", 11),
new Person("wangwu", "男", 15),
new Person("zhaoliu", "男", 12),
new Person("xiaoming", "女", 13)
);
Map<String, List<Person>> resultMap1 = stringStream8.collect(Collectors.groupingBy(Person::getSex));
System.out.println(resultMap1.toString());//{女=[Person{name='lisi', sex='女', age=11}, Person{name='xiaoming', sex='女', age=13}], 男=[Person{name='zhangsan', sex='男', age=10}, Person{name='wangwu', sex='男', age=15}, Person{name='zhaoliu', sex='男', age=12}]}
//9.collect(Collectors.groupingBy(Person::getSex, Collectors.mapping(Person::getName, Collectors.toList())))
// 对person流按照性别进行分组,并且把每一组对象流中人员的姓名转成列表
Stream<Person> stringStream9 = Stream.of(
new Person("zhangsan", "男", 10),
new Person("lisi", "女", 11),
new Person("wangwu", "男", 15),
new Person("zhaoliu", "男", 12),
new Person("xiaoming", "女", 13)
);
Map<String, List<String>> listMap = stringStream9.collect(
Collectors.groupingBy(Person::getSex, Collectors.mapping(Person::getName, Collectors.toList()))
);
System.out.println(listMap.toString());//{女=[lisi, xiaoming], 男=[zhangsan, wangwu, zhaoliu]}
//10.collect(Collectors.groupingBy(Person::getSex, Collectors.mapping(Person::getAge, Collectors.maxBy(Integer::compareTo))))
// 对person流按照性别进行分组,并统计每一组中年龄最大的人的年龄
Stream<Person> stringStream10 = Stream.of(
new Person("zhangsan", "男", 10),
new Person("lisi", "女", 11),
new Person("wangwu", "男", 15),
new Person("zhaoliu", "男", 12),
new Person("xiaoming", "女", 13)
);
Map<String, Optional<Integer>> listMap1 = stringStream10.collect(
Collectors.groupingBy(Person::getSex, Collectors.mapping(Person::getAge, Collectors.maxBy(Integer::compareTo)))
);
System.out.println(listMap1.toString());//{女=Optional[13], 男=Optional[15]}
//11.collect(
// Collectors.groupingBy(Person::getName,
// Collectors.reducing(BinaryOperator.maxBy(Comparator.comparingInt(Person::getAge)))
// )
//对person流按照性别进行分组,并统计每一组中年龄最大的人
//这个案例使用了groupingBy和reducing组合
Stream<Person> stringStream111 = Stream.of(
new Person("zhangsan", "男", 10),
new Person("lisi", "女", 11),
new Person("zhangsan", "男", 15),
new Person("zhaoliu", "男", 12),
new Person("lisi", "女", 13)
);
Map<String, Optional<Person>> resultMap111 = stringStream111.collect(
Collectors.groupingBy(Person::getSex,
Collectors.reducing(BinaryOperator.maxBy(Comparator.comparingInt(Person::getAge)))
)
);
System.out.println(resultMap111.toString());//{女=Optional[Person{name='lisi', sex='女', age=13}], 男=Optional[Person{name='zhangsan', sex='男', age=15}]}
//12.collect(Collectors.groupingBy(Person::getSex,
// Collectors.reducing(0,Person::getAge,(x,y)->x+y)
// )
// )
//对person流按照性别进行分组,并统计每一组人员年龄和
Stream<Person> stringStream121 = Stream.of(
new Person("zhangsan", "男", 10),
new Person("lisi", "女", 11),
new Person("zhangsan", "男", 15),
new Person("zhaoliu", "男", 12),
new Person("lisi", "女", 13)
);
Map<String, Integer> resultMap121 = stringStream121.collect(
Collectors.groupingBy(Person::getSex,
Collectors.reducing(0,Person::getAge,(x,y)->x+y)
)
);
/*上面这段如果不使用reducing,还可以用下面这中方式完成
Map<String, Integer> resultMap121 = stringStream121.collect(
Collectors.groupingBy(Person::getSex, Collectors.summingInt(Person::getAge))
);*/
System.out.println(resultMap121.toString());//{女=24, 男=37}
//12.collect(Collectors.groupingBy(Person::getName, TreeMap::new, Collectors.toList()))
// 对person流按照name进行分组,结果转成TreeMap,key是name,value是这个组的对象列表
//groupingBy的第一个参数就是获取分组的属性,第二个参数指定返回类型,第三个是把每个分组里面的对象元素转成一个列表
Stream<Person> stringStream11 = Stream.of(
new Person("zhangsan", "男", 10),
new Person("lisi", "女", 11),
new Person("zhangsan", "男", 15),
new Person("lisi", "男", 12),
new Person("xiaoming", "女", 13)
);
TreeMap<String, List<Person>> listMap2 = stringStream11.collect(
Collectors.groupingBy(Person::getName, TreeMap::new, Collectors.toList())
);
System.out.println(listMap2.toString());//{lisi=[Person{name='lisi', sex='女', age=11}, Person{name='lisi', sex='男', age=12}], xiaoming=[Person{name='xiaoming', sex='女', age=13}], zhangsan=[Person{name='zhangsan', sex='男', age=10}, Person{name='zhangsan', sex='男', age=15}]}
//13.collect(Collectors.collectingAndThen(
// Collectors.toCollection(() -> new TreeSet<>(Comparator.comparing(Person::getName))),
// ArrayList::new))
//对Person流先通过TreeSet去重,去重的比较属性是name,然后在把这个TreeSet中的元素转换成ArrayList
Stream<Person> stringStream12 = Stream.of(
new Person("lisi", "女", 11),
new Person("lisi", "女", 11),
new Person("zhangsan", "男", 15),
new Person("zhangsan", "男", 15),
new Person("xiaoming", "女", 13)
);
List<Person> list = stringStream12.collect(Collectors.collectingAndThen(
Collectors.toCollection(() -> new TreeSet<>(Comparator.comparing(Person::getName))),
ArrayList::new));//这里的ArrayList::new等同于pset->new ArrayList(pset),是把前面生成的TreeSet赋值给ArrayList构造函数
System.out.println(list);//[Person{name='lisi', sex='女', age=11}, Person{name='xiaoming', sex='女', age=13}, Person{name='zhangsan', sex='男', age=15}]
//14.collect(Collectors.groupingBy(Person::getName, Collectors.summingInt(Person::getAge)))
// 对person流按照姓名进行分组,并对每一个组内的人员的年龄求和
Stream<Person> stringStream13 = Stream.of(
new Person("zhangsan", "男", 10),
new Person("zhangsan", "女", 11),
new Person("lisi", "男", 15),
new Person("zhaoliu", "男", 12),
new Person("lisi", "女", 13)
);
Map<String, Integer> resultMap2 = stringStream13.collect(Collectors.groupingBy(Person::getName, Collectors.summingInt(Person::getAge)));
System.out.println(resultMap2.toString());//{lisi=28, zhaoliu=12, zhangsan=21}
//15.collect(Collectors.groupingBy(Person::getName, Collectors.averagingInt(Person::getAge)))
// 对person流按照姓名进行分组,并对每一个组内的人员的年龄求平均值
Stream<Person> stringStream14 = Stream.of(
new Person("zhangsan", "男", 10),
new Person("zhangsan", "女", 11),
new Person("lisi", "男", 15),
new Person("zhaoliu", "男", 12),
new Person("lisi", "女", 13)
);
Map<String, Double> resultMap3 = stringStream14.collect(Collectors.groupingBy(Person::getName, Collectors.averagingInt(Person::getAge)));
System.out.println(resultMap3.toString());//{lisi=14.0, zhaoliu=12.0, zhangsan=10.5}
//16.parallel().collect(
// Collectors.groupingByConcurrent(Person::getSex, Collectors.summingInt(Person::getAge))
// )
//使用并行流,把人员按照性别分组,计算每一组中的年龄和,返回的类型是ConcurrentMap,保证线程安全
Stream<Person> stringStream16 = Stream.of(
new Person("zhangsan", "男", 10),
new Person("zhangsan", "女", 11),
new Person("lisi", "男", 15),
new Person("zhaoliu", "男", 12),
new Person("zhaoliu", "男", 16),
new Person("zhaoliu", "男", 17),
new Person("lisi", "女", 13));
ConcurrentMap<String, Integer> resultMap4 = stringStream16.parallel().collect(
Collectors.groupingByConcurrent(Person::getSex, Collectors.summingInt(Person::getAge))
);
System.out.println(resultMap4.toString());//{女=24, 男=70}
//17.collect(Collectors.partitioningBy(p -> p.getAge() > 12))
//把流中元素根据年龄是否大于12分成两组,保存在Map中,key是true或者false,value是对象列表
Stream<Person> stringStream17 = Stream.of(
new Person("zhangsan", "女", 11),
new Person("wangwu", "男", 10),
new Person("lisi", "男", 15),
new Person("zhaoliu", "女", 13));
Map<Boolean, List<Person>> resultMap5 = stringStream17.collect(Collectors.partitioningBy(p -> p.getAge() > 12));
System.out.println(resultMap5.toString());//{false=[Person{name='zhangsan', sex='女', age=11}], true=[Person{name='lisi', sex='男', age=15}, Person{name='lisi', sex='女', age=13}]}
//18.collect(Collectors.partitioningBy(p -> p.getAge() > 12,Collectors.summingInt(Person::getAge)))
//把流中元素根据年龄是否大于12分成两组,保存在Map中,key是true或者false,每一组的年龄的和
Stream<Person> stringStream18 = Stream.of(
new Person("zhangsan", "女", 11),
new Person("wangwu", "男", 10),
new Person("lisi", "男", 15),
new Person("zhaoliu", "女", 13));
Map<Boolean, Integer> resultMap6 = stringStream18.collect(Collectors.partitioningBy(p -> p.getAge() > 12,Collectors.summingInt(Person::getAge)));
System.out.println(resultMap6.toString());//{false=21, true=28}
//19.Collectors.toMap:有两个参数的toMap方法,流中对象的key是不允许存在相同的,否则报错
//toMap的第二个参数需要创建一个列表,并且key对应的元素对象放入列表
Stream<Person> stringStream19 = Stream.of(
new Person("zhangsan", "女", 11),
new Person("zhaoliu", "女", 13));
Map<String, List<Person>> resultMap7 = stringStream19.collect(Collectors.toMap(Person::getName, p -> {
List<Person> personList = new ArrayList<>();
personList.add(p);
return personList;
}));
System.out.println(resultMap7.toString());//{zhaoliu=[Person{name='zhaoliu', sex='女', age=13}], zhangsan=[Person{name='zhangsan', sex='女', age=11}]}
//20.Collectors.toMap:有两个参数的toMap方法,流中对象的key是不允许存在相同的,否则报错
//toMap的第二个参数直接使用流中的对象作为key所对应的value
Stream<Person> stringStream20 = Stream.of(
new Person("zhangsan", "女", 11),
new Person("zhaoliu", "女", 13));
Map<String, Person> resultMap8 = stringStream20.collect(Collectors.toMap(Person::getName, p -> p));
System.out.println(resultMap8.toString());//{zhaoliu=Person{name='zhaoliu', sex='女', age=13}, zhangsan=Person{name='zhangsan', sex='女', age=11}}
//21.Collectors.toMap:有三个参数的toMap方法,流中对象的key是允许存在相同的,
// 第三个参数表示key重复的处理方式(这里是把重复的key对应的value用新的替换老的)
//toMap的第二个参数直接使用流中的对象作为key所对应的value
Stream<Person> stringStream21 = Stream.of(
new Person("zhangsan", "女", 11),
new Person("zhangsan", "男", 12),
new Person("zhaoliu", "男", 13)
);
Map<String, Person> resultMap9 = stringStream21.collect(
Collectors.toMap(Person::getName,
p -> p,
(oldPerson,newPerson)->newPerson
)
);
System.out.println(resultMap9.toString());//{zhaoliu=[Person{name='zhaoliu', sex='男', age=13}], zhangsan=[Person{name='zhangsan', sex='女', age=11}, Person{name='zhangsan', sex='女', age=11}]}
//22.Collectors.toMap:有三个参数的toMap方法,流中对象的key是允许存在相同的,第三个参数表示key重复的处理方式(这里是把重复的key对应的value放入列表)
//toMap的第二个参数直接使用流中的对象作为key所对应的value
Stream<Person> stringStream22 = Stream.of(
new Person("zhangsan", "女", 11),
new Person("zhangsan", "女", 11),
new Person("zhaoliu", "男", 13)
);
Map<String, List<Person>> resultMap10 = stringStream22.collect(
Collectors.toMap(Person::getName,
p -> {
List<Person> personList = new ArrayList<>();
personList.add(p);
return personList;
},
(oldList,newList)->{
oldList.addAll(newList);
return oldList;
})
);
System.out.println(resultMap10.toString());//{zhaoliu=[Person{name='zhaoliu', sex='男', age=13}], zhangsan=[Person{name='zhangsan', sex='女', age=11}, Person{name='zhangsan', sex='女', age=11}]}
//23.Collectors.toMap:有四个参数的toMap方法,流中对象的key是允许存在相同的,
//toMap的第二个参数直接使用流中的对象作为key所对应的value
//第三个参数表示key重复的处理方式(这里是把重复的key对应的value放入列表)
//第四个参数可以指定一个返回的Map具体类型
Stream<Person> stringStream23 = Stream.of(
new Person("zhangsan", "女", 11),
new Person("zhangsan", "女", 11),
new Person("zhaoliu", "男", 13)
);
Map<String, List<Person>> resultMap11 = stringStream23.collect(
Collectors.toMap(Person::getName,
p -> {
List<Person> personList = new ArrayList<>();
personList.add(p);
return personList;
},
(oldList,newList)->{
oldList.addAll(newList);
return oldList;
},
LinkedHashMap::new
)
);
System.out.println(resultMap11.toString());//{zhangsan=[Person{name='zhangsan', sex='女', age=11}, Person{name='zhangsan', sex='女', age=11}], zhaoliu=[Person{name='zhaoliu', sex='男', age=13}]}
//24.Collectors.summarizingInt((a -> a.getAge()))
//针对Integer类型的元素进行汇总计算
//得到1、元素数量 2、元素的和 3、元素的最大值 4、元素的最小值 5、平均值
Stream<Person> personStream24=Stream.of(
new Person("zhangsan", "女", 11),
new Person("zhangsan", "女", 25),
new Person("zhaoliu", "男", 13)
);
IntSummaryStatistics intSummaryStatistics = personStream24.collect(Collectors.summarizingInt((a -> a.getAge())));
System.out.println(intSummaryStatistics);//IntSummaryStatistics{count=3, sum=49, min=11, average=16.333333, max=25}
}
}



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律