

前端如何实现大文件上传
在开发过程中,经常会遇到一些较大文件上传,如果只使用一次请求去上传文件,一旦这次请求中出现什么问题,那么无论这次上传了多少文件,都会失去效果,用户则需要重新上传所有资源。所以就想到一种方式,将一个大文件分成多个小文件,这样通过多个请求实现大文件上传。
接下来我们就来看看具体是怎么实现的~
<input type="file" id="update-btn">
<script>
const updateInput = document.querySelector('#update-btn')
updateInput.onchange = () => {
const file = updateInput.files[0]
if(!file){
return
}
// 通过file的slice 方法可以将文件进行分割,第一个参数是从哪个字节开始,第二个参数是到哪个字节结束
const chunk = file.slice(0,2000)
}
</script>
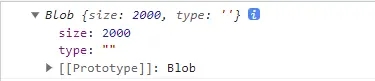
这时,我们知道了如何将大文件进行切片,那么我们就创建个函数用于对文件进行切片
const updateInput = document.querySelector('#update-btn')
updateInput.onchange = () => {
const file = updateInput.files[0]
if(!file){
return
}
const chunkList = chunkFileFun(file, 1*1024*1024)
}
/**
* @description: 文件分片函数
* @param {
* file: 需要分片的文件,
* size: 文件按照每片多大去分片
* }
* @return: [] 文件分片后的数组
*/
const chunkFileFun = ( file, size ) => {
const result = []
for (let i = 0; i < file.size; i += size) {
result.push(file.slice( i, i + size))
}
return result
}
这时候我们可以看控制台,我们已经获取到了分片的数组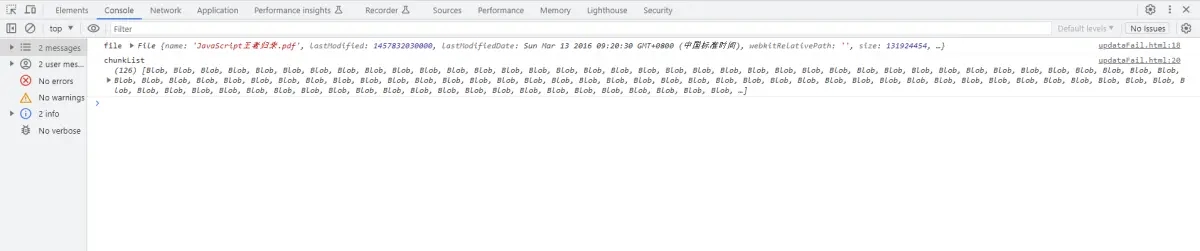
这样就结束了吗?并没有~ 如果我们再上传到一半的时候失败了,我们并希望下次上传文件重新上传,我们希望通过和服务器交互知道我们上次上传文件上传到哪里,我们从没有上传的切片继续上传就好了,那么这个东西我们应该如何实现呢?
我在这里使用的是spark-md5这个插件生成一个固定的hash值。大家也可以使用其他方式生成固定的hash值,我们上传的时候通过这个hash值,和服务端交互确认我们上传的是哪个文件上传到哪里,这样就可以解决我们的问题了
<script type="text/javascript" src="./spark-md5.min.js"></script>
<input type="file" id="update-btn">
<script>
const updateInput = document.querySelector('#update-btn')
updateInput.onchange = async () => {
const file = updateInput.files[0]
if (!file) {
return
}
console.log('file', file)
const chunkList = chunkFileFun(file, 1 * 1024 * 1024)
console.log('chunkList', chunkList)
const hash = await getHash(chunkList)
}
/**
* @description: 获取文件hash
* @param {file: 文件}
* @return: hash
*/
const getHash = (chunkList) => {
const spark = new SparkMD5()
return new Promise(resolve => {
const chunkHash = (i) => {
if (i >= chunkList.length) {
resolve(spark.end())
return
}
const blob = chunkList[i]
const read = new FileReader()
read.onload = e => {
// 读取到的字节数量
const byte = e.target.result
spark.append(byte)
chunkHash(i + 1)
}
read.readAsArrayBuffer(blob)
}
chunkHash(0)
})
}
/**
* @description: 文件分片函数
* @param {
* file: 需要分片的文件,
* size: 文件按照每片多大去分片
* }
* @return: [] 文件分片后的数组
*/
const chunkFileFun = (file, size) => {
const result = []
for (let i = 0; i < file.size; i += size) {
result.push(file.slice(i, i + size))
}
return result
}
</script>
在这个计算hash过程中需要读取整个文件的内容,这个过程时间会很长,我们一般不会在主线程做这个事,以免页面卡死,我们可以通过web worker,开辟另外一个线程去做这个事情。参考文章:http://blog.ncmem.com/wordpress/2023/10/10/%e5%89%8d%e7%ab%af%e5%a6%82%e4%bd%95%e5%ae%9e%e7%8e%b0%e5%a4%a7%e6%96%87%e4%bb%b6%e4%b8%8a%e4%bc%a0/
欢迎入群一起讨论


 浙公网安备 33010602011771号
浙公网安备 33010602011771号