

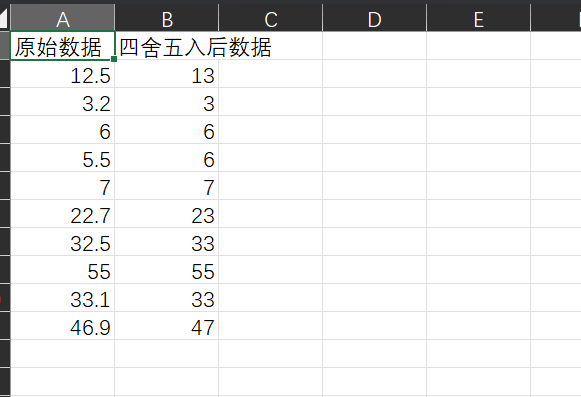
1 with open('data6.csv','r',encoding='gbk') as f: 2 data1 = f.read().split('\n') 3 del data1[0] 4 print('原始数据:') 5 print(data1) 6 7 for i in range(len(data1)): 8 data1[i] = float(data1[i]) 9 data2 = [] 10 for i in range(len(data1)): 11 data2.append(int(data1[i]+0.5)) 12 print('四舍五入后数据:') 13 print(data2) 14 15 title = ['原始数据','四舍五入后数据'] 16 info = [] 17 for i in range(len(data1)): 18 info.append([str(data1[i]),str(data2[i])]) 19 with open('data6_processed.csv','w',encoding='gbk') as f: 20 f.write(','.join(title)+'\n') 21 for item in info: 22 f.write(','.join(item)+'\n')

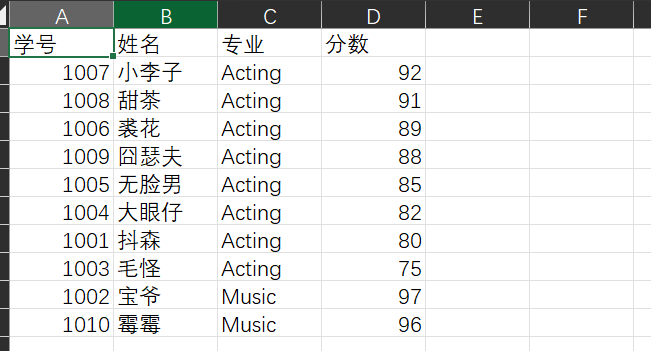
1 with open('data7.csv','r',encoding = 'gbk') as f: 2 data = f.readlines() 3 data_t = ['学号','姓名','专业','分数'] 4 data1 = [i.strip('\n').split(',') for i in data] 5 data1.remove(data1[0]) 6 7 data2=sorted(data1,key=lambda x:(x[2],-int(x[3]))) 8 with open('data7_processed.csv','w',encoding = 'gbk') as f: 9 f.write(','.join(data_t) + '\n') 10 for item in data2: 11 f.write(','.join(item) + '\n') 12 13 print(f'{"学号":10s}{"姓名":10s}{"专业":10s}{"分数":10s}') 14 for a,b,c,d in data2: 15 print('{:<10s}{:<10s}{:<10s}{:<10}'.format(a,b,c,d))

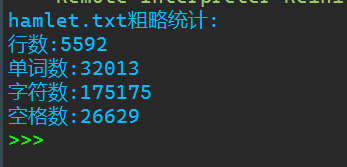
1 with open('hamlet.txt','r') as f: 2 data = f.read() 3 print('hamlet.txt粗略统计:') 4 data1 = data.splitlines() 5 print(f'行数:{len(data1)}') 6 print(f'单词数:{len(data.split())}') 7 print(f'字符数:{len(data)}') 8 k = data.count(' ') 9 print(f'空格数:{k}') 10 11 data2=[] 12 for i in range(len(data1)): 13 data2.append(f'{i+1} '+ data1[i] + '\n') 14 with open('hamlet_with_line_number.txt','w') as f: 15 f.writelines(data2)

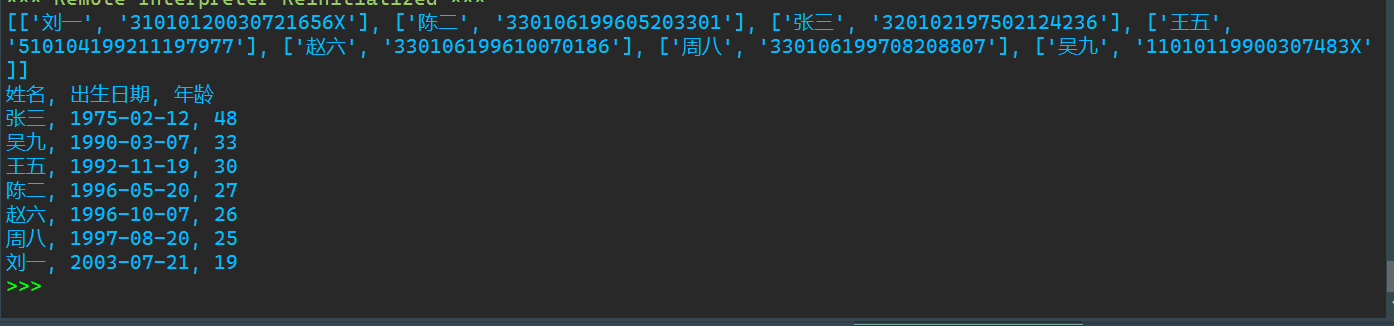
1 import datetime 2 3 4 def is_valid(x): 5 if len(x) == 18 and x[:-1].isdigit() and (x[-1].isdigit() or x[-1] == 'X'): 6 return True 7 else: 8 return False 9 10 11 with open('data9_id.txt', 'r', encoding='utf-8') as f: 12 data0 = f.readlines() 13 title = data0.pop(0) 14 15 data0 = [i.strip('\n').split(',') for i in data0] 16 17 data1 = [] 18 for i in data0: 19 if is_valid(i[1]): 20 data1.append(i) 21 print(data1) 22 23 t = datetime.datetime.now() 24 y = t.strftime('%Y%m%d') 25 for i in data1: 26 age = str(int(y)-int(i[1][6:14])) 27 i.append(age[:2]) 28 i[1] = i[1][6:10] + '-' + i[1][10:12] + '-' + i[1][12:14] 29 data2 = sorted(data1, key=lambda x: -int(x[2])) 30 31 print('姓名, 出生日期, 年龄') 32 for i in data2: 33 print(', '.join(i))

1 with open('data10_stu.txt','r',encoding='utf-8') as f: 2 data = f.readlines() 3 print('{:*^40}'.format('抽点开始')) 4 n = int(input('输入随机抽点人数:')) 5 import random 6 sum1 = 0 7 x = [] 8 x2 = '' 9 counts = 0 10 while counts < n: 11 new = random.randint(0, len(data) - 1) 12 if new in x: 13 new = random.randint(0, len(data) - 1) 14 else: 15 counts +=1 16 x.append(new) 17 for i in range(n): 18 print(data[x[i]]) 19 x2 += data[x[i]] 20 sum1 += n 21 with open('20230602.txt','w',encoding='utf-8') as f: 22 f.writelines(x2)


