

jsoup 源码分析
jsoup 使用于从html 抽取出符合规则的标签,字符串,使用也非常简单。主要是两个函数,
Document parse = Jsoup.parse(apiResult);
Elements eles = body.select("#search_book_list li");
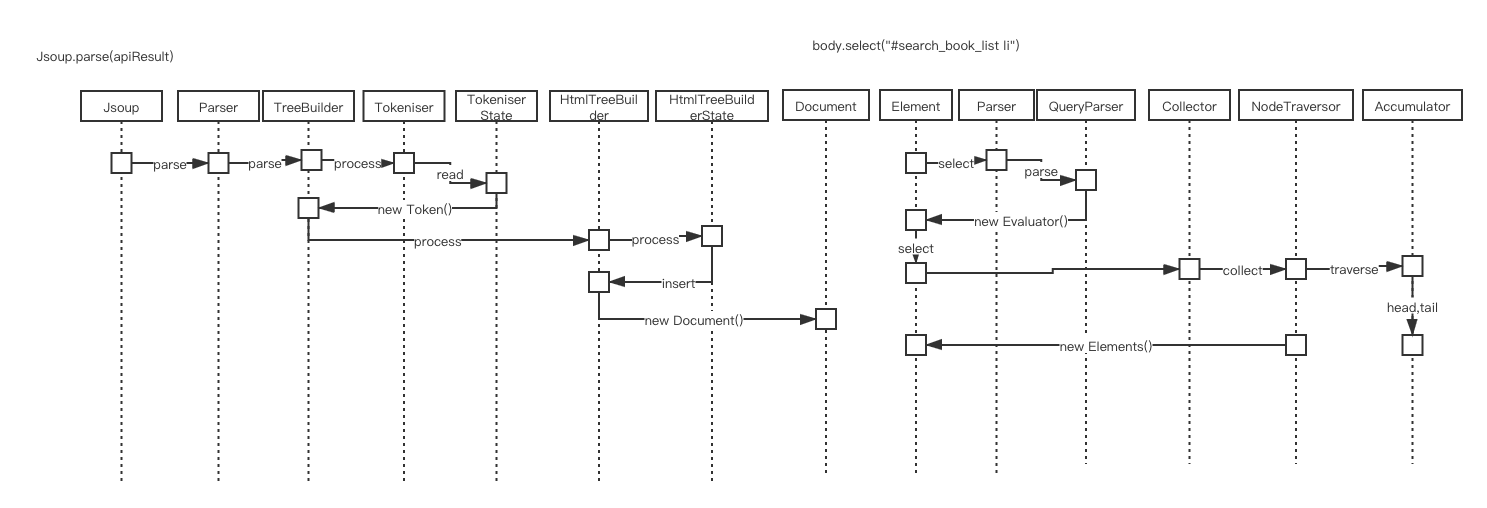
有图有真相。
下面来分析下这两个函数:
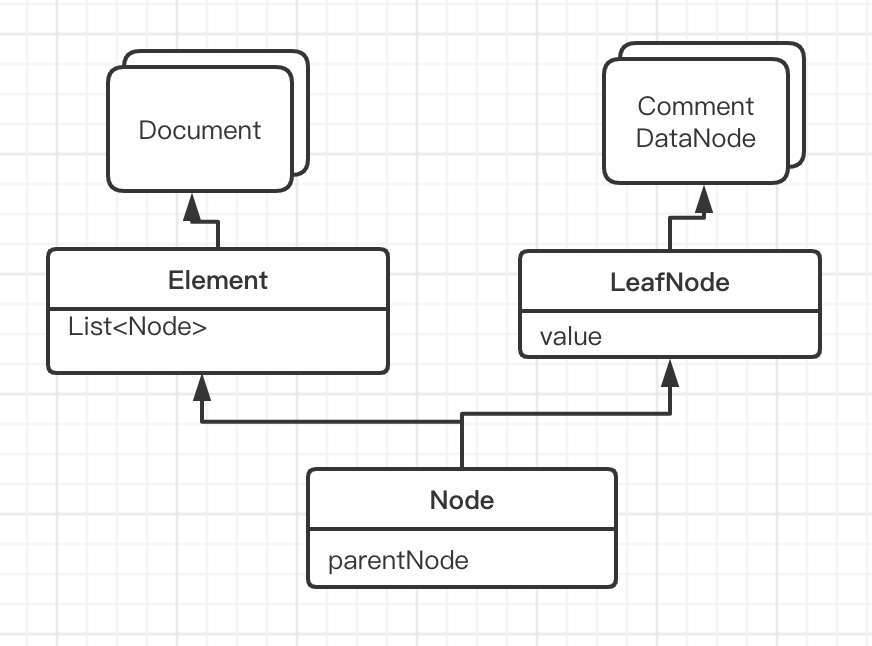
1。 Jsoup.read( " html "), 是把html 字符串解析成 Element 对象,形成一棵Element 树,我们在Element 中可以看到 List<Node>, 以及parentNode, 这是构成树的基本元素。下面分析下形成树的过程,用到了 Parser, HtmlTreeBuilder ,HtmlTreeBuilderState, Token, Tokenier . 其中 HtmlTreeBuilder 是解析字符串形成树的入口 .
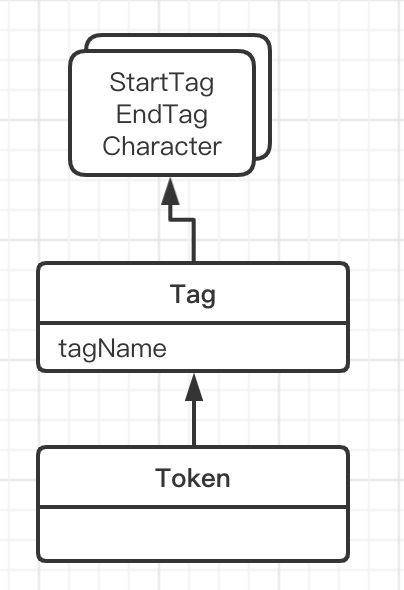
Token 可以理解为一个个字符,(StartTag,EndTag,Comment,) , Tokenier 分析当前Token的不同类型。
HtmlTreeBuilderState 实例如(Initial, BeforeHead, InHead,BeforeBody,InBody ),根椐Token不同,形成不同的Node对象,并播入到Elements中
Jsoup.read() --> Parser.parse () --> TreeBuilder.parse --> HtmlTreeBuilder.runParser()
tokeniser.read()--> Tokensier.read() -- > TokeniserState.read()
HtmlTreeBuilder.process() --> HtmlTreeBuilderState.process() --> BeforeHead, BeforeBody. process -- > HtmlTreeBuilder.insert()

这是在TreeBuilder 中关键的过程, tokeniser 把token 一个个读出来,process 根椐token不同类型 解析形成Node, 插入到Document 中,形成树结构。
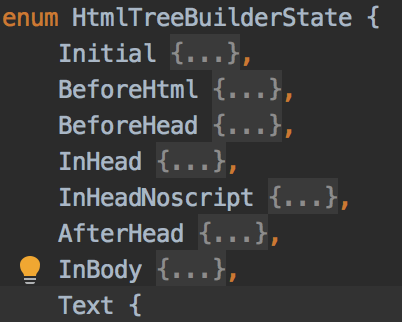
这里HtmlTreeBuilderState 用enum结构。
2。 Document.parse(" #id") : 这里面分两部,先把#id 字符串解析,形成Evaluator, 然后遍历Document 对象,把符合条件的Element 对象拿出来,形成List<Element> 返回。 这里用到了Selector, QueryParser, Evaluator, TokenQueue( 第一步), NodeVisitor,NodeTraversor(第二步).

从这可以看出这两步走,QueryParser.parse() 解析形成Evaluator, select() 遍历从root 中找出Element 。
Evaluator 有很多子类, 其中比较熟悉的 idEvaluator,classEvaluator,TagEvaluator 分别是表示找id, class ,tag 。 CombiningEvaluator 是表示And, or 连接对象。
这是在QueryParser 中, tq 分析形成Evaluator 的过程:

第二步查找:
NodeTraversor 是遍历整个root 对象,借助NodeVisitor 来实现。
NodeVisitor 有两个方法,head, tail .
可以看出Traversor 是深度优先遍历算法。


