


MySQL里使用正则表达式
背景
随着使用匹配、比较和通配操作符寻找数据,这样可以满足基本的过滤。但是随着业务的复杂度增加,就需要使用正则表达式满足这些要求。正则表达式的作用就是匹配文本,用一个正则表达式的模式与一个文本串比较。MySQL的where子句对正则表达式提供了初步支持,,允许使用指定正则表达式,过滤select检索出的数据。
正则表达式关键字是 regexp
这个文章的练习的表为

语句为
create table regexp_test
(
name varchar(20) null,
price decimal(7, 3) null,
remark varchar(200) null
)
comment '正则表达式练习表';
INSERT INTO learn.regexp_test (name, price, remark) VALUES ('apple', 2.000, '苹果说明');
INSERT INTO learn.regexp_test (name, price, remark) VALUES ('pear', 3624.215, '223344@qq.com');
INSERT INTO learn.regexp_test (name, price, remark) VALUES ('banana', 5555.653, '13612364589');
INSERT INTO learn.regexp_test (name, price, remark) VALUES ('Orange', 3412.000, '12345.31');
INSERT INTO learn.regexp_test (name, price, remark) VALUES ('strawberry', 3125.400, 'nothing');
用法
基本字符匹配
比如 匹配价格含有555的产品信息
select * from regexp_test where price regexp '555';查询结果:
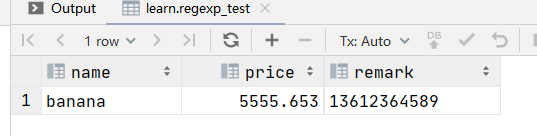
从这个效果来看 price regexp '555' 类似与 price like '%555%'。但是如果我们查询价格为整数也就是价格的小数部分为0的产品信息时,用正则表达式则会更容易地实现
select * from regexp_test where price regexp '.000';查询结果:

进行与or操作符作用的匹配
使用正则表达式可以匹配两个或者多个子串的匹配,子串之间要用符号竖线 "|"
比如匹配价格含有555或者价格为整数的产品信息
select * from regexp_test where price regexp '555|.000';查询结果为:

匹配任何单一字符
有些时候我们需要匹配单一字符,匹配某些特定的字符,这时就用到了一组中括号"[ ]",中括号中的字符串里的每个字符单独会与中括号旁边的字符串组合成新的字符串,由每个中括号的单独字符组合起来的字符串分别进行正则匹配,结果集会以”或“的形式组成。
上面的一段解释肯定不好理解,举个例子,我要匹配name中含有"ang"或"ana",用正则表达式来写的话就是 name regexp 'an[ag]' 等价于 name regexp 'ang|ana' ,前一种写法相当于将要匹配的多个子串的共性抽取出来,不同的地方用中括号"[ ]"括起来。
select * from regexp_test where name regexp 'an[ag]';查询结果为

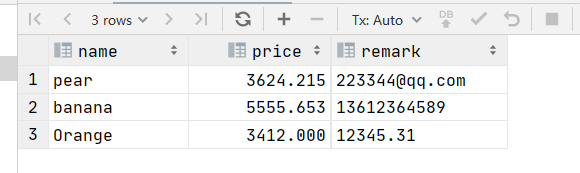
中括号不仅可以放在文本的后面,也可以放在其前面,例如
select * from regexp_test where remark regexp '[12]23';那它的查询结果就变成了:
匹配范围
中括号中的集合可以匹配一个或多个字符,但一些存在一定规律的情况是可以简化的,使用符号时英文的横线"-",比如 匹配数字0到5 ,那么写成的方式就是[012345],但是我们可以用匹配范围的方式进行简化,那么就写成了'[0-5]',同理,[a-z]就是匹配任意字母字符。
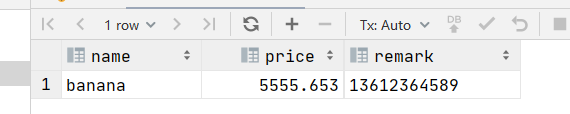
例如,匹配表中name字段a到c与an组成的产品信息
select * from regexp_test where name regexp '[a-c]an';那么结果就是:
匹配特殊字符
一些情况下,我们需要匹配一些字符,如点'.','[]','-'等等,如果要匹配这样的字符要怎么办呢,如果直接匹配的话,就会出现异常情况
比如:查询remark字段中含有点'.'的产品信息,如果直接匹配的话。
select * from regexp_test where remark regexp '.';那查询结果就是

这样的结果肯定是有问题的,如果要解决就需要使用转义字符双斜杠"\\"。那么新的sql就是:
select * from regexp_test where remark regexp '\\.';
很多正则表达式都是使用单个斜杠转义特殊字符,但MySQL要求两个反斜杠,因为MySQL自己要解释一个,正则表达式库解释另一个
两个反斜杠\\也用来引用元字符,元字符就是具有特殊含义的字符
| 元字符 | |
| \\f | 换页 |
| \\n | 换行 |
| \\r | 回车 |
| \\t | 制表 |
| \\v | 纵向制表 |
匹配字符类
在MySQL中,可以使用预定义的字符集,称之为字符类。他们是有一些特定含义。
| 表 | 说明 |
| [:alnum:] | 任意字母和数字(同a-z A-Z 0-9) |
| [:alpha:] | 任意字符(a-z A-Z) |
| [:blank:] | 空格或制表符(同[\\t]) |
| [:cncrl:] | ASCII控制字符(ASCII0到31和127) |
| [:digit:] | 任意数字(同[0-9]) |
| [:graph:] | 与[:print:]相同,但不包括空格 |
| [:lower:] | 任意小写字母(同[a-z]) |
| [:print:] | 任意可打印字符 |
| [:punct:] | 既不在[:alnum:]又不在[:cntrl:]中的任意字符 |
| [:space:] | 包括空格在内的任意空白字符(同 \\f \\n \\r \\t \\v) |
| [:upper:] | 任意大写字母 |
| [:xdigit:] | 任意十六进制数字(同 a-f A-F 0-9) |
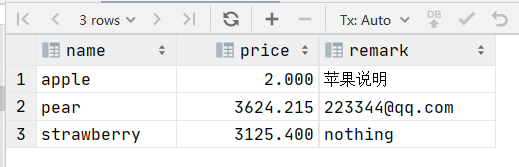
例如匹配产品表中的remark字段为任意字符的产品信息
select * from regexp_test where remark regexp '[:alpha:]';结果为:
匹配多个实例
很多时候也要面临要统计区分限制某些字符出现的次数,对数目有更强的控制。就用到了一类重复元字符。
| 元字符 | 说明 |
| * | 0个或多个匹配 |
| + | 1个或多个匹配(等于{1,}) |
| ? | 0或1个的匹配(等于{0,1}) |
| {n} | 指定数目的匹配 |
| {n,} | 不少于指定数目的匹配 |
| {n,m} | 匹配数目的范围(m不超过255) |
例如查询产品信息表中remark字段中23次数不少于2次的信息有:
select * from regexp_test where remark regexp '23{2,}';结果为:

定位符
定位符顾名思义就是确定位置的符号,有时需要确定文本出现的位置,就用到了这些定位符,有^ 文本的开始,$文本的结尾,[[:<:]]词的开始,[[:>:]]词的结束这几个
例如查找表中名称以a为开头的产品信息
select * from regexp_test where name regexp '^a';查询结果为:

在sql中单独验证正则表达式,可以不依靠建表,regexp会进行检查,如果返回0就代表没有匹配,如果返回1则代表匹配了语法为:
例如检查hello中是否含有数字
select 'hello' regexp '[0-9]';
比如查询remark为邮箱的sql,这个位置写的有些简略,忽略了名称为中文的情况
select * from regexp_test where remark regexp '[a-z0-9]@[a-z0-9]+\\.';

【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步