pl/sql
0.紧挨左部导航栏的上部,黑色倒三角,选中:My Object 就是选中当前用户的对象;
1.Recent objects 最近操作过的对象
2.Recycle bin 回收站
3.Function(null) 定义的函数
4.Procedurces(有多个存储过程) 存储过程
5.Packages(null)
6.Packages bodies(null)
7.Types(null)
8.Types Bodies(null)
9.Tiggers(null)
10.Java Recorse(null)
11.Jobs(有定时器) 定时器 定时跑存储过程,存储过程可以进行同步表,比如岗位变动之后,与本岗位相关的个人事件也会随之改变
创建定时器的过程:11.1打开PLSQL,展开左侧工具上的DBMS_JOBS(或者Jobs)定时器文件夹。通过plsql查看tables、views等文件夹,找到定时器对应的DBMS_Jobs文件夹。
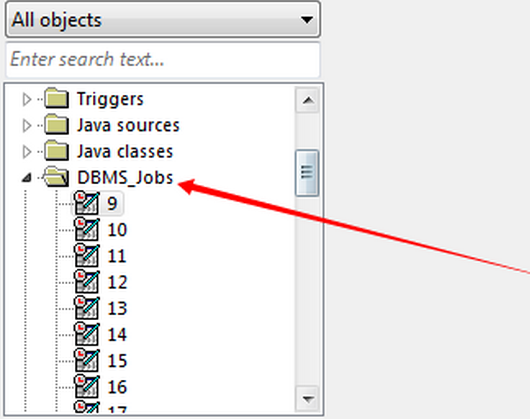
11.2新建定时器job。在文件夹或者在已有的定时器上右键 new... 创建一个新的job(定时器)
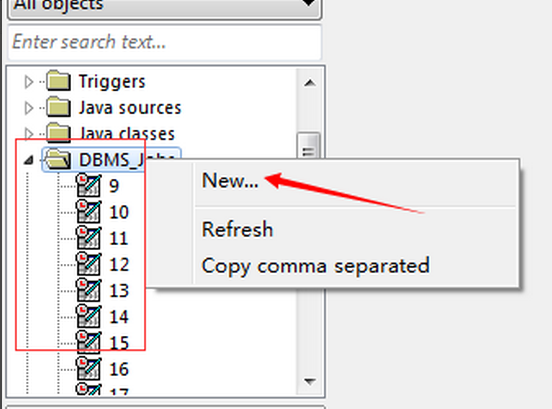
11.3输入红色选中的必输参数。What里面是一些存储过程,可以是一个或者多个。多个之间用分号“;”隔开,可以数据一下注释说明,格式“/*存过说明*/。点击应用即可保存。点击View SQL可以查看job对应的sql脚本
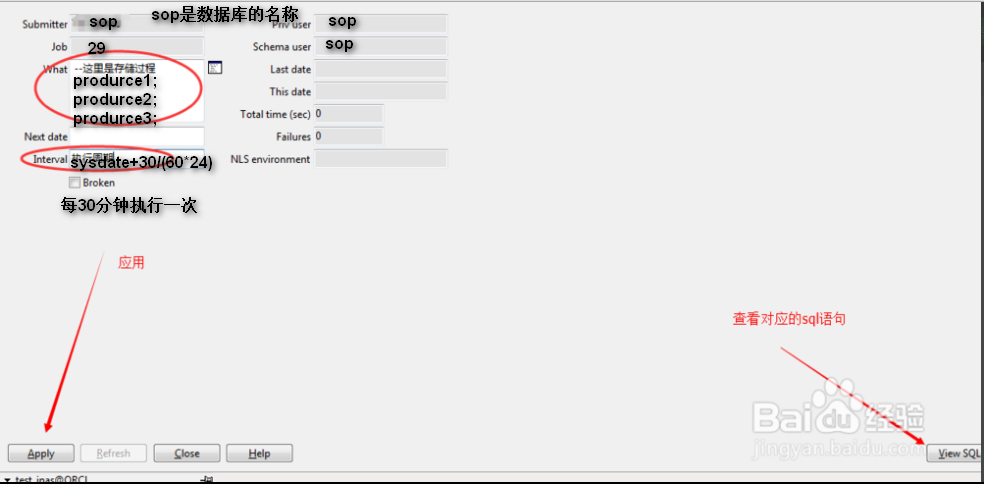
点击View Sql:
declare jobno number; --系统会自动分配一个jobno的定时任务号,例如上面是:29
begin
dbms_job.submit(job=> jobno, --是把job赋值为jobno,job名称 如果我们定义好了定时器名称可以这样:job=>:job
what=>'produrce1;
produrce2;
produrce3;', --what赋值 这里是job绑定的存储过程 ****注意:这里引号中的存储过程名后面要加上分号。
next_date=>sysdate, --next_date赋值 这里是下次定时任务运行时的时间 sysdate是系统时间 也就是立即执行
--我们也可以自己制定时间 2018-10-20 12:00:00 也就是在12点的时候,执行该定时器
interval=>'sysdate+1/(24*60)' --interval 赋值 这里是定时任务运行时每次的间隔时间 1/(24*60)是说明一分钟 1天除以24*60就是一分钟
);
commit;
end;
/
11.4如果想查看一些脚本,处理通过打开文件夹的方式,也可以使用更方便的sql语句进行查看。
SELECT * FROM dba_jobs;
注意,如果next_date是4000-1-1表示这个脚本已经是停止状态

11.5如果想查询某个存储过程对应的哪个job可以通过dba_jobs表中what字段根据条件查询查看job,what是job做的内容。
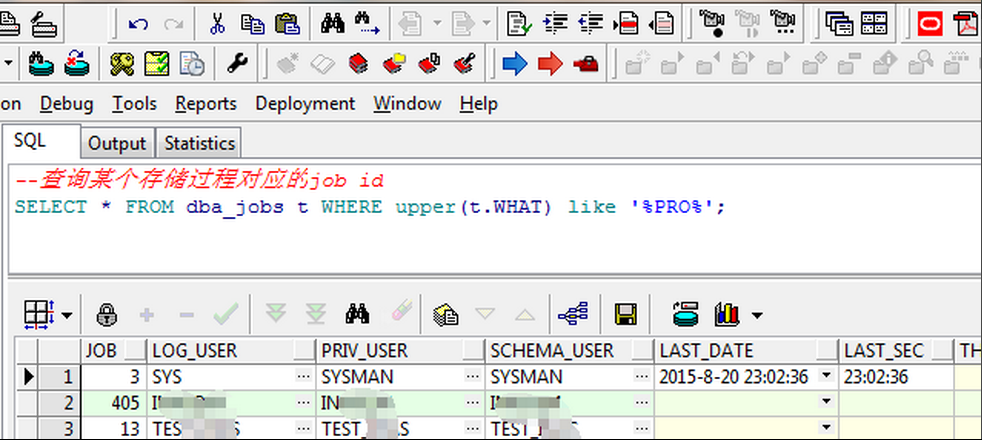
11.6根据查询结果找到对应的job。dba_jobs中的job字段对应的值就和DBMS_Jobs中对应的数字是一致的,可以对信息进行修改更新。
12.Queues(null)
13.Queues tables(null)
14. 高级队列是oracle的一种高级应用,它主要是表和触发器之间的组合而成的一种应用。其主要作用是在各应用系统中进行消息传递。
NOMAXVALUE --不设置最大值
NOCYCLE --一直累加,不循环
CACHE 10; --缓存个数
21.user(不为空,好多个) 用户表空间 这个自己用就知道了 例如我们的库是sop 我们还可以有sop_up
22.profiles (不为空)限制ORACLE用户
23.,roles (不为空,好多个)授予权限或者角色 权限控制
24.synonyms (null)Oracle的同义词(synonyms)从字面上理解就是别名的意思
25.database link 此功能可以在本库中操作其他数据库 可以将不在一个数据库空间里的数据库进行表的数据复制
例如我们现在的数据库是12.99.113.131 另一个数据库的数据库地址是:12.99.113.130
drop database link SOP_LINK;
create database link SOP_LINK ---此功能的名称
connect to SOP
using '12.99.113.130/orcl';
26; tablespace 表空间 例如 我们现在的数据库是sop 我们可以在这里再重新定义一个sop_up
27:cluster 表簇 这个功能还真的没有用过

