

HDFS理论及安装部署
一、hadoop简介
1、hadoop的初衷是为了解决Nutch的海量数据爬取和存储的需要,HDFS来源于google的GFS,MapReduce来源于Google的MapReduce,HBase来源于Google的BigTable.hadoop后被引入Apache基金会.
2、hadoop两大核心设计是HDFS和MapReduce,HDFS是分布式存储系统,提供高可靠性、高扩展性、高吞吐率的数据存储服务;MapReduce是分布式计算框架,具有易于编程、高容错性和高扩展性等优点.
3、hadoop和传统数据库相比存储的数据更大,且为半结构化和非结构化数据,基于数据挖掘和数据预测性分析更有意义,hadoop又快又好维护又廉价.
4、hadoop版本几条线并行分0.x,1.x,2.x,0.23增加用户认证管理(通过密码访问hadoop),2.x加NN HA,企业目前用2.x.
二、HDFS简介
1、HDFS优缺点
优点:
高容错性:数据自动保存多个副本,副本丢失后,自动恢复,可靠性同时也实现了加快处理速度,A节点负载高,可读取B节点
适合批处理:移动计算而非数据,数据位置暴漏给计算框架
适合大数据处理:甚至PB级数据,百万规模以上文件数量,10k+节点
可构建在廉价机器上:通过多副本提高可靠性,提供容错和恢复机制
缺点:
低延迟数据访问:比如订单是不适合存储HDFS中的,要求数据毫秒级就要查出来
小文件存取:不适合大量的小文件存储,如真有这种需求的话,要对小文件进行压缩
并发写入、文件随机修改:不适合修改,实际中网盘、云盘内容是不允许修改的,只能删了从新上传,他们都是hadoop做的
2、HDFS架构

1>HDFS中的存储单元(block),一个文件会被切分成若干个固定大小的block(块默认是64MB,可配置,若不足64MB,则单独一个块),存储在不同节点上,默认每个block有三个副本(副本越多,磁盘利用率越低),block大小和副本数通过Client端上传文件时设置,文件上传成功后副本数可变,block size不可变.如一个200M文件会被切成4块,存在不同节点,如挂了一台机器后,会自动在复制副本,恢复到正常状态,只要三个机器不同时挂,数据不会丢失.
2、HDFS包含3种节点,NameNode(NN),secondary NameNode(SNN),DataNode(DN).
NN节点功能
接收客户端的读写请求,NN中保存文件的metadata数据(元数据是最重要的,元数据丢失的话,dateNode都是垃圾数据)包括除文件内容外的文件信息;文件包含哪些block;Block保存在哪个DN上(由DN启动时上报,因为这个可能随时变化),NN中的metadata信息在启动后会加载到内存,metadata存储在磁盘的文件名为fsimage,block的位置信息不会保存到fsimage,edits记录对metadata的操作日志.比如有一个插入文件的操作,hadoop不会直接修改fsimage,而是记录到edits日志记录文件中,但是NN内存中的数据是实时修改的.隔断时间后会合并edits和fsimage,生成新的fsimage,edits的机制和关系型数据库事务的预提交是一样的机制.
SNN节点功能
它的主要工作是帮助NN合并edits log,减少NN启动时间,另一方面合并会有大量的IO操作,但是NN最主要的作用是接收用户的读写服务的,所以大量的资源不能用来干这个.SNN它不是NN的备份,但可以做一部分的元数据备份,不是实时备份(不是热备).
SNN合并流程
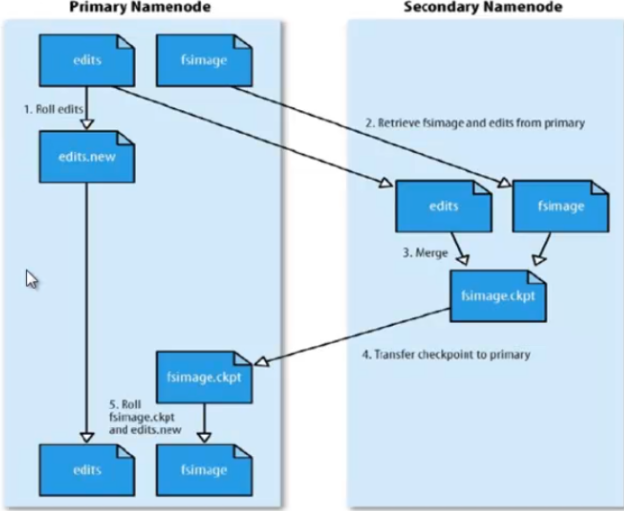
满足合并时机后(合并时机:配置设置时间间隔fs.checkpoint.period,默认3600秒;或者配置edit log大小,最大64M),SNN会拷贝NN的edits日志记录文件和fsimage元数据文件到SNN中,可能会跨网络拷贝,这时同时NN会创建一个新的edits文件来记录用户的读写请求操作,然后SNN就会进行合并为一个新的fsimage文件,然后SNN会把这个文件推送给NN,最后NN会用新的fsimage替换旧的fsimage,然后如此反复…
面试题:
1、SNN的作用?
当NameNode启动的时候,首先装载fsimage文件,然后再应用edits文件,最后还会将最新的目录树信息到新的fsimage文件中,然后启用新的edits文件.整个流程是没有问题的,但有个小瑕疵,就是如果NameNode在启动后发生的改变过多,会导致edit文件变得非常大,大得程度与NameNode的更新频率有关系.那么在下一次NameNode启动的过程中,读取了fsimage文件后,会应用这个无比大的edits文件,导致启动时间变长,并且不可能控,可能需要启动几个小时也说不定.NameNode的edits文件过大的问题,也就是SecondeNameNode要解决的主要问题.
2、如果NN挂掉(硬盘坏掉)后,数据还能不能找回?
如果SNN和NN在同一台机器无法找回,所以NN和SNN最好不在一台机器.
DN节点功能
存储数据;启动DN线程的时候向NN汇报block信息;通过向NN发送心跳保持与其联系(3秒1次),如果NN10分钟没有收到DN心跳,则认为其lost,并copy其上的block到其它DN.
ps:面试题:block的副本放置策略
第一个副本:放置在上传文件的DN;如果是集群外提交,则随机挑选一台磁盘不太满,cpu不太忙的节点.第二个副本:放置在于第一个副本不同的机架的节点上.第三个副本:与第二个副本相同的机架节点(一个机架电源相同,保证安全的同时提高速度).
3、HDFS读写流程

read是并发读取

只写了一份block,然后由DN产生线程去往其他DN上复制block副本,速度快.
4、HDFS文件权限和认证
权限和linux类似,如果linux用户wangwei使用hadoop命令创建一个文件,那么这个文件在HDFS中owner就是wangwei;HDFS不做密码的认证,这样的好处是速度快,不然每次读写都要验密码,HDFS存的数据一般都是安全性不是很高的数据.HDFS理论结束.
三、HDFS安装部署
1、下载编译好的hadoop并解压:tar -xzf hadooop-2.7.3.tar.gz.
2、安装jdk并设置JAVA_HOME
1>第一种,这种方式关闭终端后就失效了
linux-02:~ # declare -x JAVA_HOME="/usr/local/jdk1.7.0_03/bin/" linux-02:~ # export PATH=$JAVA_HOME:$PATH
2>第二种,永久方式
vim /etc/profile,增加以下内容:
export JAVA_HOME=/usr/local/jdk1.7.0_03/
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
保存profile文件,并执行source /etc/profile让设置立即生效.同时要在conf/hadoop-env.sh中配置jdk.
3、免密码登录配置(现在打算用三个节点来部署hadoop)
1> 在node1上执行ssh node2不需要密码即可登录node2就是免密码登录.
2> 为什么需要免密码登录?HDFS能做到在任何一个机器上敲命令启动HDFS,那么它就能启动所有节点的所有的Java进程(每个节点实际就是一个java 进程),也就是启动整个集群,其实就是远程登录到其他机器上去启动那些节点.如 start-all.sh命令.它其实只是为了一个方便,不然需要逐个启 动节点.
3>要在Node1上敲start-all.sh启动集群,就需要做node1到node2,node3的免密码登录.首先在各个节点的/etc/hosts里面添加node1,node2,node3主机名和iP映射
192.168.144.11 node1 192.168.144.12 node2 192.168.144.13 node3
然后各个节点生成公钥和私钥,公钥放入本地认证,先完成本地的免密码登录
$ ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa $ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys $ chmod 0600 ~/.ssh/authorized_keys
最后复制node1的id_dsa.pub到node2和node3,然后分别追加到各自的本地认证中,直接复制粘贴内容有问题.
[root@node1 ~]# scp ~/.ssh/id_dsa.pub root@node2:~ [root@node1 ~]# scp ~/.ssh/id_dsa.pub root@node3:~ [root@node2 ~]# cat id_dsa.pub >> ~/.ssh/authorized_keys [root@node3 ~]# cat id_dsa.pub >> ~/.ssh/authorized_keys
4、配置node1节点conf/core-site.xml

<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<!--配置NN在哪台机器以及它的端口,也可说是HDFS的入口 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://node1:9000</value>
</property>
<!-- HDFS工作目录的设置,默认是linux的/temp,每次linux重启会清空,hadoop中的数据会全部丢失.-->
<!-- 其它一些目录是以这个临时目录为基本目录的,如dfs.name.dir和dfs.name.edits.dir等-->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop-2.7.3</value>
</property>
</configuration>
5、node1节点上conf/slaves配置DN,conf/masters 配置SNN(尽量和NN不要在一个节点),NN已经在core.site.xml中配置.
<!--配置主机名或ip --> [root@node1 conf]# vim masters node2 [root@node1 conf]# vim slaves node2 node3
6、把node1/conf下所有的配置文件复制到node2,node3.
[root@node1 conf]# scp ./* root@node2: ~/hadoop-1.2.1/conf/ [root@node1 conf]# scp ./* root@node3: ~/hadoop-1.2.1/conf/
7、bin目录下格式化NN并启动
./hadoop namenode -format //只需一次即可 ./start-dfs.sh //启动HDFS
启动成功后 通过jps命令查看java进程(需要安装jdk并且在/etc/profile中配置好JAVA_HOME),这时NN的日志提示,全部启动成功,但是去node2,node3通过jps查看Java进程但发现没有启动成功,这是防火墙的原因,在NN执行:service iptables stop关掉防火墙,stop掉hdfs重新启动,就可通过浏览器http://node1:50070可以访问HDFS管理页面.

