【死磕ES】四、基本操作
ES集群基本操作
1、集群状态分类
查看集群健康状态
GET _cluster/health
***
{
"cluster_name" : "elasticsearch",
"status" : "green",//green:健康,yellow:有不可用的节点,red:集群不可用
"timed_out" : false,
"number_of_nodes" : 1,//节点数
"number_of_data_nodes" : 1,//数据节点数
"active_primary_shards" : 3,//活跃的主分片
"active_shards" : 3,//总分片数
"relocating_shards" : 0,//?
"initializing_shards" : 0,//?
"unassigned_shards" : 0,//?
"delayed_unassigned_shards" : 0,//?
"number_of_pending_tasks" : 0,//?
"number_of_in_flight_fetch" : 0,//?
"task_max_waiting_in_queue_millis" : 0,//?
"active_shards_percent_as_number" : 100.0//?
}
***
查看集群状态,并显示列名
GET _cat/nodes?v
***
ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name
127.0.0.1 13 69 2 dilm * 3RZNX97CW39V6PU
heap.percent:?
ram.percent:?
***
查看分片
GET _cat/shards
cat命令集合
***
/_cat/allocation #查看单节点的shard分配整体情况
/_cat/shards #查看各shard的详细情况
/_cat/shards/{index} #查看指定分片的详细情况
/_cat/master #查看master节点信息
/_cat/nodes #查看所有节点信息
/_cat/indices #查看集群中所有index的详细信息
/_cat/indices/{index} #查看集群中指定index的详细信息
/_cat/segments #查看各index的segment详细信息,包括segment名, 所属shard, 内存(磁盘)占用大小, 是否刷盘
/_cat/segments/{index}#查看指定index的segment详细信息
/_cat/count #查看当前集群的doc数量
/_cat/count/{index} #查看指定索引的doc数量
/_cat/recovery #查看集群内每个shard的recovery过程.调整replica。
/_cat/recovery/{index}#查看指定索引shard的recovery过程
/_cat/health #查看集群当前状态:红、黄、绿
/_cat/pending_tasks #查看当前集群的pending task
/_cat/aliases #查看集群中所有alias信息,路由配置等
/_cat/aliases/{alias} #查看指定索引的alias信息
/_cat/thread_pool #查看集群各节点内部不同类型的threadpool的统计信息,
/_cat/plugins #查看集群各个节点上的plugin信息
/_cat/fielddata #查看当前集群各个节点的fielddata内存使用情况
/_cat/fielddata/{fields} #查看指定field的内存使用情况,里面传field属性对应的值
/_cat/nodeattrs #查看单节点的自定义属性
/_cat/repositories #输出集群中注册快照存储库
/_cat/templates #输出当前正在存在的模板信息
***
2、集群状态监控
1)集群状态
2)集群统计
3)集群任务管理
4)节点信息
5)活跃线程信息
3、集群备份
ES索引基本操作
- 显示所有索引:GET _cat/indices
- 匹配带有关键字的索引:GET /_cat/indices/*_mp*
1、创建一个索引
1)创建也给索引并指定类型
PUT /test2
{
"mappings": {
"properties": {
"name": {
"type": "text"
},
"age": {
"type": "long"
},
"birthday": {
"type": "date"
}
}
}
}
2)_create方式创建索引
PUT songjn_index/_create/1
{"name":"songjn","age":"17"}
3)_doc方式创建索引
PUT songjn_index/_doc/1
{"name":"songjn","age":"18"}
说明:创建有两种方式
①如果创建的过程没有指定索引Field的类型,就会分配固定类型
②_create:当利用_create关键字进行文档创建的时候,如果该文档存在同一ID则报错
③_doc:当利用_doc关键字进行文档创建的时候,如果该文档存在则进行删除并新增,版本号+1
2、get一个索引规则
GET songjn_index
3、删除索引
Delete 索引名称
Delete 索引名称1,索引名称2
Delete 索引名称*
Delete _all
注意事项:对数据安全来说,能够使用单个命令来删除所有的数据可能会带来很可怕的后果,所以,为了避免大量删除,
可以在elasticsearch.yml 配置文件中修改 action.destructive_requires_name: true
设置之后只限于使用特定名称来删除索引,使用_all 或者通配符来删除索引无效(上述中说明配置文件中禁止后此方式不能使用)】
4、修改索引
1)索引数据迁移
- reindex
- 第三方工具
2)修改副本数
- 注意:索引一旦创建后,主分片数不能再修改
3)索引压缩
- shrink
ES文档基本操作
1、新增文档
1)单个文档写入
①_create方式创建索引 PUT songjn_index/_create/1 {"name":"songjn","age":"17"} ②_doc方式创建索引 PUT songjn_index/_doc/1 {"name":"songjn","age":"18"} 说明:创建有两种方式 ①如果创建的过程没有指定索引Field的类型,就会分配固定类型 ②_create:当利用_create关键字进行文档创建的时候,如果该文档存在同一ID则报错 ③_doc:当利用_doc关键字进行文档创建的时候,如果该文档存在则进行删除并新增,版本号+1
2)批量写入
Bulk API
- 支持在一次API调用中,对不同索引进行不同的操作
- 支持的操作类型:Index、Create、Update、Delete
- 操作中,单条失败不会影响其他操作
POST _bulk
{"index":{"_index":"songjn_index","_id":"1"}}
{"name":"songjianan"}
{"delete":{"_index":"songjn_index","_id":"4"}}

3)第三方导入
- logstash
- flume
- kafka
2、删除文档
①根据主键删除数据 Delete 索引名称/文档名称/主键编号 ②根据匹配条件删除数据 POST 索引名称/文档名称/_delete_by_query { "query":{ "term":{ "_id":100000100 } } } ③删除所有数据:(注意请求方式是Post,只删除数据,不删除表结构) POST /testindex/testtype/_delete_by_query?pretty { "query": { "match_all": { } } }
3、查询文档
1)单个文档查询
//①根据ID查询 GET songjn_index/_doc/1 //②根据条件匹配 GET bank/_search { "query": { "match": { "age": 30 } } }
2)批量检索
批量读取-mget
GET _mget
{ "docs":[ { "_index":"songjn_index", "_id":"1" }, { "_index":"test2", "_id":"1" } ] }
批量查询-msearch
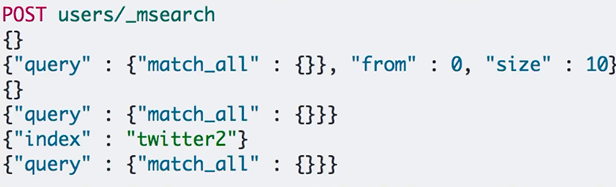
3)分页检索
GET bank/_search { "query": { "match": { "age": 30 } }, "from": 0, "size": 10 }
5)排序
GET bank/_search { "from": 0, "size": 10, "query": { "match": { "age": 30 } }, "sort": [ { "account_number": { "order": "asc" } } ] }
4、修改文档
1)单个文档修改
1)post直接更新
POST songjn_index/_doc/2
{"name":"songjn_haha"}
2)put直接更新
PUT songjn_index/_doc/2
{"name":"songjn_haha","age":"18"}
说明:1)2)更新的时候字段要写全,否则其他属性会被更新成空
3)更新最新语法,可以更新部分字段,不会丢失其他字段的值
POST songjn_index/_update/2
{
"doc": {
"name":"songjn_haha33"
}
}
2)批量修改
Bulk API(同上)
5、高亮显示
GET bank/_search { "query": { "match": { "lastname": "Nieves" } }, "highlight": { "pre_tags": "<span class='key' style='color:red'>", "post_tags": "</span>", "fields": { "lastname": {} } } } ///注意match中的属性需要和高亮中fields属性相同
6、推荐
7、分词
8、同义词
9、调试,profile:显示查询类型等详细信息
GET bank/_search { "query": { "match": { "age": 30 } }, "profile": "true" }
10、常见错误


