记录一次缓存引起的线上BUG
背景
有一个需求大概是这样的,为了提高推荐系统的性能,需要本来从A服务获取的帖子信息,改为从Redis里面重新读取
Redis里面没有存帖子的所有信息,只存储了推荐系统必要的字段
大概是这样的:
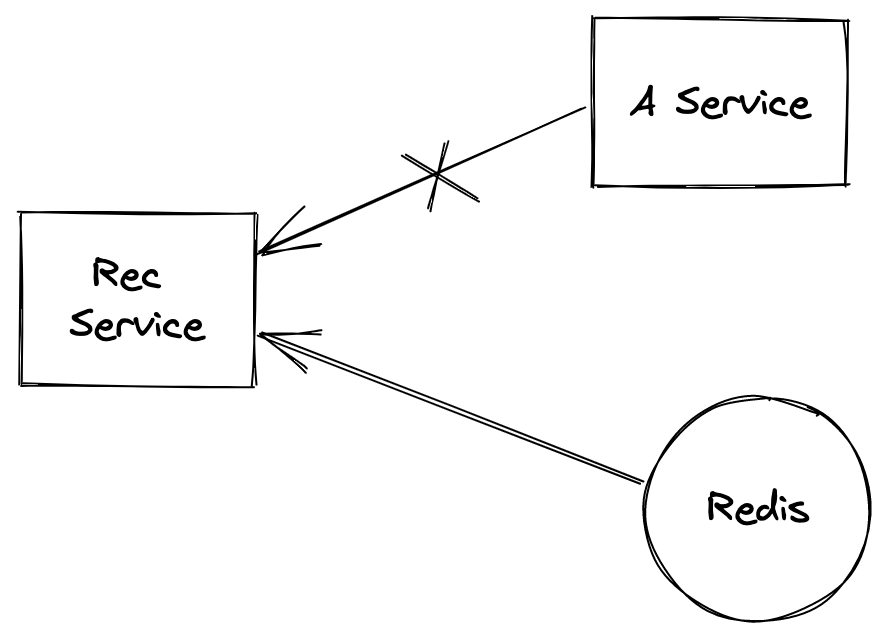
至于Redis如何批量和实时维护数据我们不用管,只要还能从Redis读到之前的帖子信息即可
实现
这个实现起来不难,只要根据帖子ID读取Redis的数据,然后原样转为帖子实体即可
问题
帖子信息不全
这是在沙箱环境遇到的问题,Redis存储的帖子信息不够全,虽然对推荐系统是足够的,但对下游的返回结果不够使用
解决方法
在返回之前,重新调用A服务获取帖子信息,覆盖原来的帖子。
为什么不直接调用A服务呢,因为返回结果的时机帖子数量比较少,一般在10条之内,而召回要查询的帖子可能是几百上千条。
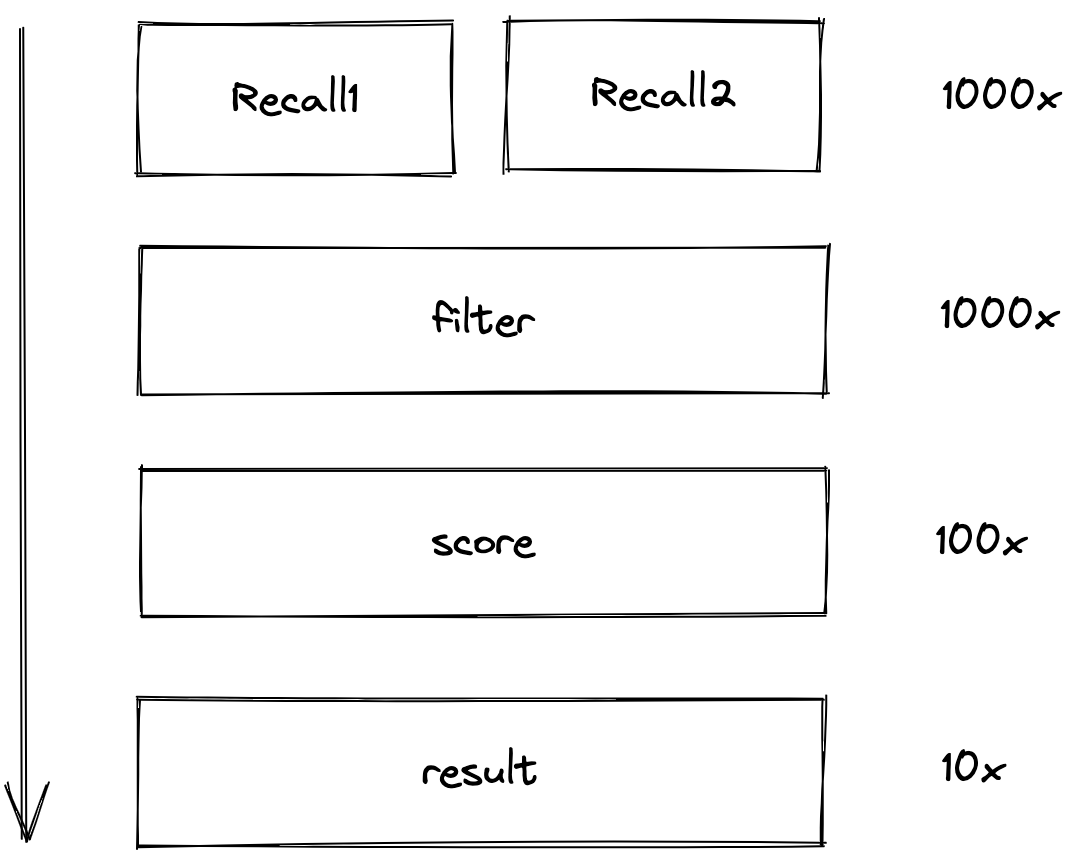
通过这样修改,沙箱测试也顺利通过
上线后帖子信息仍然不全?
本以为这样就没事,结果上线灰度的过程中,下游服务开始报警,和相关同学确认之后说还是在沙箱环境中碰到那个错
此时我懵了,这个不是已经重新获取了帖子信息吗

拼命在核对代码,这个从Redis的帖子信息是怎么绕过重新从A服务获取信息的
通过报警的数量来看,不是必然出现的
怀疑以下原因:
- 环境问题,因为沙箱没问题,线上有问题,可能是配置不同或者环境变量
- 并发问题,沙箱测试肯定没有并发,是不是线上并发请求导致哪个变量有问题
- 异常逻辑,是不是有些请求没做正常逻辑,走了异常逻辑导致提前返回
通过线上灰度和各种log不停调试了两天排除了上述问题和代码逻辑的问题,此时已经接近绝望
曙光
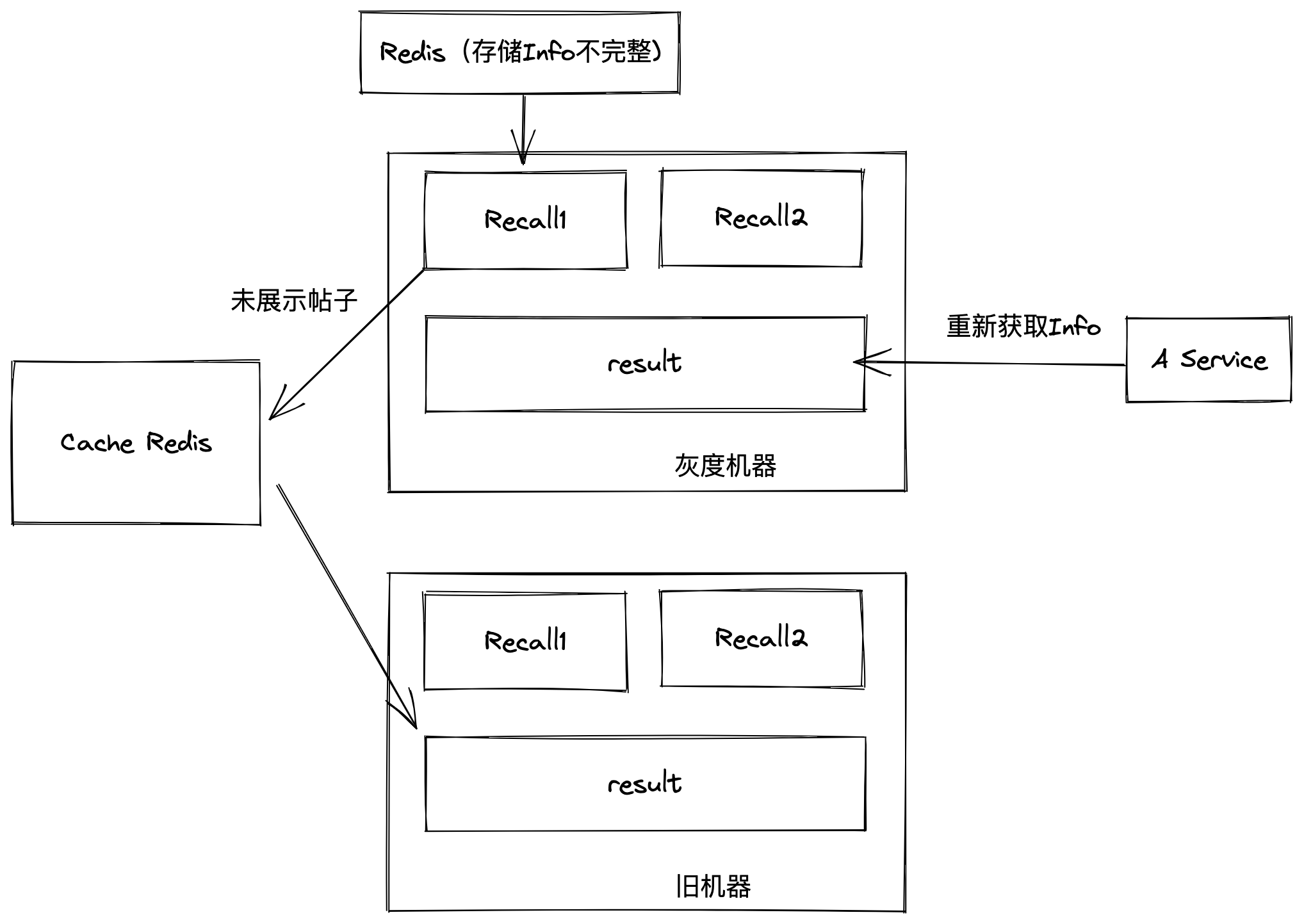
有一点一直能确定,就是从Redis获取的帖子信息返回给了下游,但它是怎么漏出去呢?
突然想到会不会不是灰度的机器返回出去的,而是旧版本的机器返回出去的。
因为我们会对召回回来但是未被使用的帖子做缓存,也就是说,灰度机器召回的不完整帖子通过缓存被旧机器返回回去了
总结
在上线过程中,新版本机器产生的脏数据通过缓存Rdis被旧版本机器使用了,而旧版本机器没有对脏数据进行处理导致出现的问题
之所以记录这个问题,是因为这个问题花费了我很多时间,现在看起来简单,但当时却很难发现,所以希望能给看到的同学一些启发
追加
除了数据产生的线上问题之外,之前还碰到过一个不容易发现的线上BUG, 就是全局变量,具体表现为: 线上刚开始表现是正常的,当这个全局变量被改变之后,然后就不正常了,也是一个不太容易发现的问题
本文来自博客园,作者:songtianer,转载请注明原文链接:https://www.cnblogs.com/songjiyang/p/16615232.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号