一、关于MySQL的索引结构:B+Tree
MySQL数据库索引一般是B+树。
B+树中的B代表平衡(balance),而不是二叉(binary)。
B+树是由二叉查找树、平衡二叉树(AVLTree)和平衡多路查找树(B-Tree)逐步优化而来的。
二叉查找树:
1.所有非叶子结点至多拥有两个儿子(Left和Right);
2.每个结点存储一个数据;
3.非叶子结点的左指针指向小于其关键字的子树,右指针指向大于其关键字的子树;
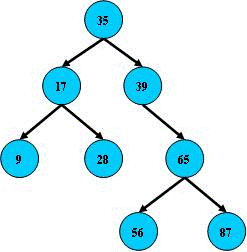
查找,从根结点开始,如果目标值与结点的值相等,即找到;如果目标值比结点值小,就去左子树找;如果比结点值大,就去右子树找;如果左儿子或右儿子的指针为空,则目标值不存在;
二叉查找树插入与删除结点比连续内存空间的二分查找有更高的性能,因为不需要移动大段的内存数据,甚至通常是常数开销;
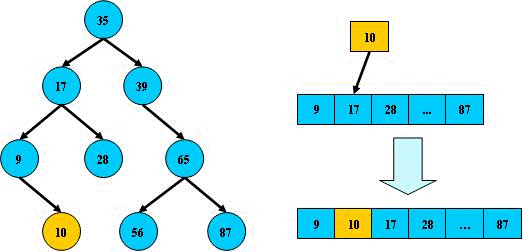
对于查找,找到高度为h的节点,需要的比较次数为h。所以同一组数据构成的树,高度越低,平均查找次数越小。
1x1+2x2+3x3=14 < 1+2+3+4+5+6=21
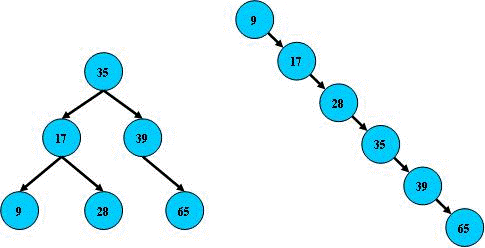
如果二叉查找树的所有非叶子结点的左右子树结点数目均保持差不多(平衡),那么它的查找性能逼近二分查找。
平衡二叉树(AVLTree)
平衡二叉树(AVL树)即在符合二叉查找树的条件下,还满足任何节点的两个子树的高度差不超过1。
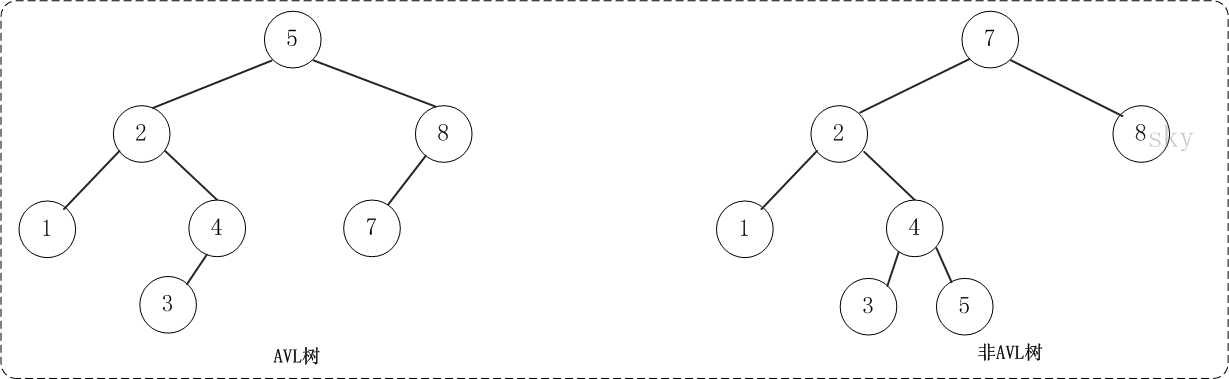
在经过多次插入与删除后二叉查找树可能会失去平衡,因此若想二叉树的查询效率尽可能高,需要把二叉树重新调整到平衡。
平衡多路查找树(B-Tree)
B-Tree是一种多路搜索树(并不是二叉的,M叉,M>2):
1.所有结点至多拥有M个儿子;
2.除根结点以外的非叶子结点,至少含有Ceil(M/2)个儿子
3.每个结点内数据与指向子树的指针相互间隔,并保持次序 ;
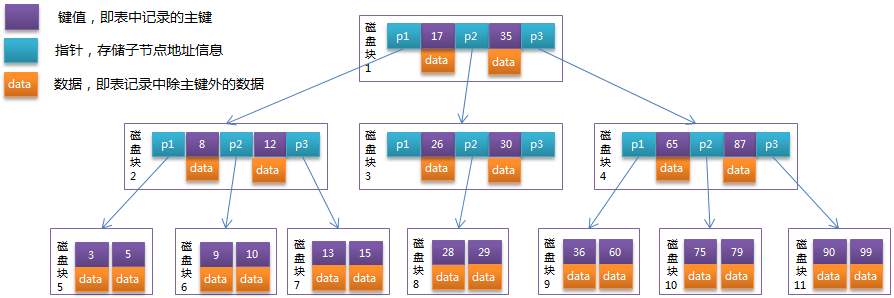
相比二叉树,B-Tree一个节点放多个数据,同一组数据构成的B-Tree比二叉树节点更少,树高更低,查找需要IO次数更少。
B-Tree的性能总是等价于二分查找(与M值无关),没有二叉树的平衡问题;但是由于M/2的限制,在插入结点时,如果结点已满,需要将结点分裂为两个各占M/2的结点;删除结点时,需将两个不足M/2的兄弟结点合并;
B+Tree
在B-Tree的基础上:
1.非叶子节点只存储键值,不存数据,数据统一挂在叶子节点;
2.非叶子结点的子树指针与键值个数相等;
3.节点内当前数据<=子树下挂的数据<节点内下一个数据;
4.叶子节点的数据有指针相连,形成链表;
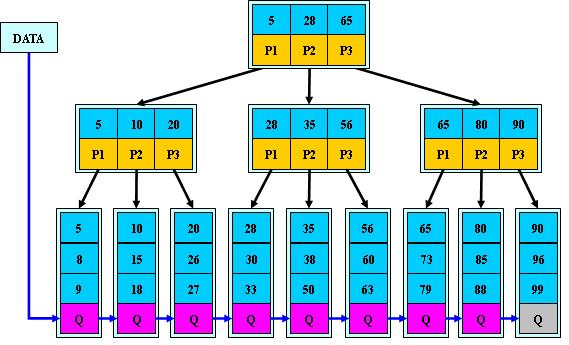
相比B-Tree,B+Tree节点只存键值不存数据,一个节点包含的键值可以更多,那么意味着可以支持更多的数据在较低的树高下建起索引。
MySQL用一个页存储一个索引节点。InnoDB存储引擎中页的大小默认16KB,一般表的主键类型为INT(4字节)或BIGINT(8字节),指针类型一般4或8个字节,也就是说一个页的IO(一个节点)中大概可以存储16KB/(8B+8B)=1K个键值。InnoDB将根节点常驻内存,那么一个深度为4的B+Tree索引可以维护10^3 * 10^3 * 10^3 = 10亿 条记录,最坏只需要3次IO。
二、InnoDB 与MyISAM索引对比
MyISM和InnoDB索引都是用B+树实现的,但在索引关联数据的方式上有所不同。
MyISAM

InnoDB

我们发现:
MyISAM表有3个文件:
- .frm:表结构文件
- .MYI:索引文件(MyISAM Index)
- .MYD:数据文件(MyISAM Data)
InnoDB表有2个文件:
- .frm:表结构文件
- .ibd:索引和数据文件(InnoDB Data)
对于MyISAM:
MyISAM索引和数据记录是分离的。主键索引和辅助索引都是通过索引找到数据记录的地址,再去这个地址取到数据记录。索引排序相邻的数据,存储很可能不在一块,即非聚簇索引。
MyISAM的主键索引:从主键找到数据记录的地址
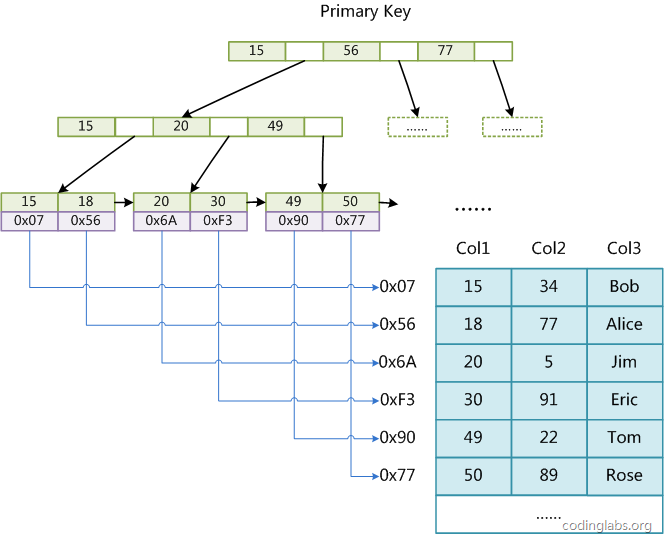
MyISAM的辅助索引:从索引字段找到数据记录的地址

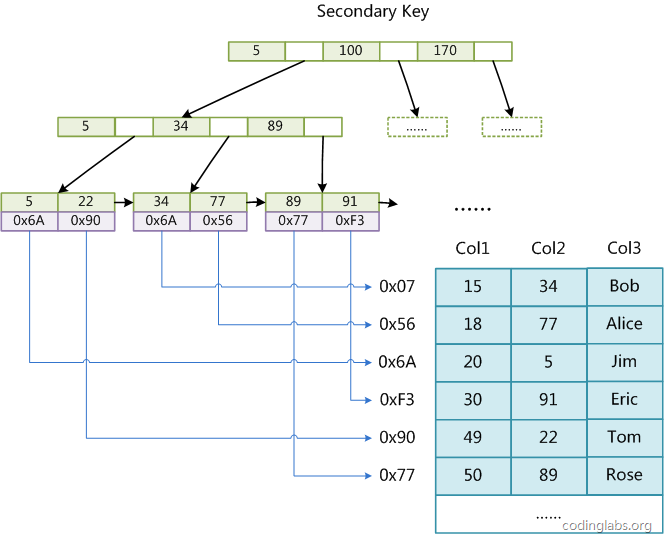
对于InnoDB:
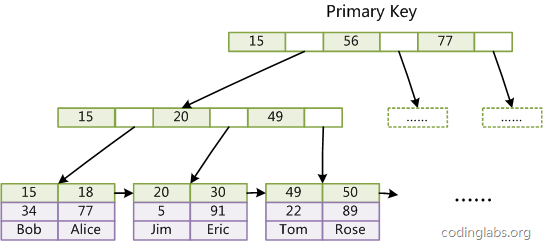
InnoDB的数据记录是挂在主键索引叶子节点的,索引 和 数据记录 在一块。
通过主键索引,可用直接根据主键找到数据记录。
索引排在一块的数据,物理存储地址也在一块,即聚簇索引。
InnoDB的主键索引:以主键索引到数据记录
InnoDB的辅助索引:从索引字段找到主键
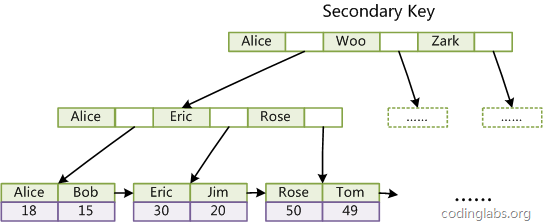
辅助索引是以建索引的字段为关键字找到主键,再通过主键索引根据主键找到数据记录。
https://dev.mysql.com/doc/refman/5.7/en/innodb-index-types.html
三、如何用到索引
几个例子:

1、select * from rc_att_workdate where d_group=110 and uid=5333 and work_day='2019-05-06';

2、select * from rc_att_workdate where work_day='2019-05-06' and d_group=110 and uid=5333;

结论一:顺序无影响。

3、select * from rc_att_workdate where d_group=110 and `sensorid`=0 and work_day='2019-05-06';

4、select * from rc_att_workdate where d_group=110 and `sensorid`=0 and checkin_time='08:30';

5、select * from rc_att_workdate where d_group=110 and work_day='2019-05-06';

6、select * from rc_att_workdate where `sensorid`=0 and work_day='2019-05-06';

结论二:最左前缀:某个索引中从左到右连续的几个字段。
B+Tree的联合索引结构
按索引字段依次排序。
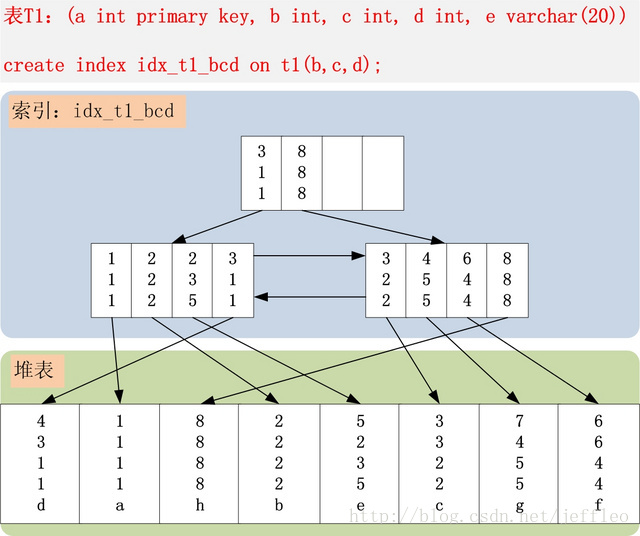
where条件提取:http://hedengcheng.com/?p=577
参考:
http://hedengcheng.com/?p=577
http://codinglabs.org
http://blog.csdn.net/jeffleo

