


面试题100
1.1 请解释关系型数据库概念及主要特点?
概念:采用了关系型模型来组织数据的数据库。
1)关系型数据库在存储数据时实际就是采用的一张二维表
2)市场占有量较大的是MySQL和oracle数据库,而互联网场景最常用的是MySQL数据库。
3)它通过SQL结构化查询语言来存取、管理关系型数据库的数据。
4)关系型数据库在保持数据安全和数据一致性方面很强,遵循ACID理论
& 关系:可以理解为一张二维表,每个关系都具有一个关系名,就是通常说的表名。
& 元组:可以理解为二维表中的一行,在数据库中经常被称为记录。
& 属性:可以理解为二维表中的一列,在数据库中经常被称为字段。
& 域:属性的取值范围,也就是数据库中某一列的取值限制。
& 关键字:一组可以唯一标识元组的属性。数据库中常称为主键,由一个或多个列组成。
& 关系模式:指对关系的描述,其格式为,关系名(属性1,属性2,…,属性N)。在数据库中通常称为表结构。
主要特点:使用方便,易于维护,容易理解
1.2 请说出关系型数据库的典型产品、特点及应用场景?
Oracle数据库:其产品支持最广泛的操作系统平台。目前Oracle关系数据库产品的市场占有率数一数二。
版本升级:Oracle8i,Oracle9i,Oracle1Og,Oracle11g,Oracle12c。
应用场景:传统大企业,大公司,政府,金融,证券等等。
MySQL数据库:是一个中小型关系型数据库管理系统
1)MySQL性能卓越,服务稳定,很少出现异常宕机。
2)MySQL开放源代码且无版权制约,自主性及使用成本低。
3)MySQL历史悠久,社区及用户非常活跃,遇到问题,可以寻求帮助。
4)MySQL软件体积小,安装使用简单,并且易于维护,安装及维护成本低。
5)MySQL品牌口碑效应,使得企业无需考虑就直接用之,LAMP, LEMP流行架构。
6)MySQL支持多种操作系统,提供多种API接口,支持多种开发语言,特别对流行的PHP语言有很好的支持。
其发布的MySQL版本采用双授权政策,和大多数开源产品的路线一样,分为社区版和商业版,而这两个版本又各自分四个版本依次发布,这四个版本为:Alpha版、Beta版、RC版和GA版本。
MySQL在发展到5.1系列版本之后,重新规划为三条产品线。
应用场景:互联网领域,大中小型网站,游戏公司,电商平台等等。
MariaDB数据库:MySQL数据库的一支分支,MariaDB基于事务的Maria存储引擎,替换了MySQL的MylSAM存储引擎,它使用了Percona的XtraDB(InnoDB的变体)。
Microsoft SQL Server:是微软公司开发的大型关系型数据库系统,SQL Server的功能比较全面,效率高,可以作为中型企业或单位的数据库平台。SQL Server可以与Windows操 作系统紧密集成,不论是应用程序开发速度还是系统事务处理运行速度,都能得到较大的 提升。对于在Windows平台上开发的各种企业级信息管理系统来说,不论是C/S(客户机/ 服务器)架构还是B/S(浏览器/服务器)架构,SQL Server都是一个很好的选择。SQL Server的缺点是只能在Windows系统下运行。
主要应用范围:部分企业电商(央视购物),使用windows服务器平台的企业。
Access 数据库:
主要特点 如下:
1)完善地管理各种数据库对象,具有强大的数据组织、用户管理、安全检查等功能。
2)强大的数据处理功能,在一个工作组级别的网络环境中,使用Access开发的多用户数据库管理系统具有传统的XBASE(DBASE、FoxBASE的统称)数据库系统所无法实现的客户服务器(Cient/Server)结构和相应的数据库安全机制,Access具备了许多先进的大型数据库管理系统所具备的特征,如事务处理/出错回滚能力等。
3)可以方便地生成各种数据对象,利用存储的数据建立窗体和报表,可视性好。
4)作为Office套件的一部分,可以与Office集成,实现无缝连接。
5)能够利用Web检索和发布数据,实现与Internet的连接。Acess主要适用于中小型应用系统,或作为客户机/服务器系统中的客户端数据库。
早期应用领域:小型程序系统asp+access系统,留言板,校友录等。
1.3 请解释非关系型数据库概念及主要特点?
1)NOSQL数据库不是否定关系型数据库,而是作为关系数据库的一个重要补充。
2)NOSQL数据库为了灵活及高性能、高并发而生,忽略影响高性能、高并发的功能。
3)在NOSQL数据库领域,当今的最典型产品为Redis(持久化缓存)、Mongodb、Memcached纯内存等。
4)NOSQL数据库没有标准的查询语言(SQL),通常使用REST式的数据接口或者查询API。
1.4 非关系型数据库的典型产品、特点及应用场景?
NoSQL数据库的分类:
|
分类 |
数据模型 |
优点 |
缺点 |
典型应用场景 |
|
键值(key-value)存储数据库 |
key指向Value的键值对,通常用hash表来实现 |
查找速度快 |
数据无结构化(通常只被当作字符串或者二进制数据) |
内容缓存,主要用于处理数据的高访问负载,也用于一些日志系统 |
|
列存储数据库 |
以列簇式存储,将同一列数据存在一起 |
查找速度快,可扩展性强,更容易进行分布式扩展 |
功能相对局限 |
分布式的文件系统 |
|
文档性数据库 |
key-value对应的键值对,value为结构化数据 |
数据结构要求不严格,表结构可变(不需要像关系型数据库一样预先定义表结构) |
查询性能不高,而且缺乏统一的查询语法 |
web应用 |
|
图形(Graph)数据库 |
图结构 |
利用图结构相关算法(如最短路径寻址,N度关系查找等) |
很多时候需要对整个图做计算才能得出需要的信息,而且这种结构不太好做分布式的集群方案 |
社交网络,推荐系统等 |
- 键值(Key-Value)存储数据库
这一类数据库主要会使用到哈希表,在这个表中有一个特定的键和一个指针指向特定的数据。Key/value模型对于IT系统来说优势在于简单、易部署。但是如果DBA只对部分值进行查询或更新的时候,Key/value就显得效率低下了。
TokyoCabinet/Tyrant Redis Voldemort OracleBDB
- 列存储数据库
这部分数据库通常是用来应对分布式存储的海量数据。键仍然存在,但是它们的特点是指向了多个列。这些列是由列家族来安排的。
Cassandra HBase Riak
- 文档型数据库
文档型数据库的灵感来自于Lotus Notes办公软件,它同第一种键值存储相类似。该类型的数据模型是版本化的文档,半结构化的文档以特定的格式存储,比如JSON。文档型数据库可以看作是键值数据库的升级版,允许之间嵌套键值。而且文档型数据库比键值数据库的查询效率更高。
CouchDB MongoDB SequoiaDB
- 图形(Graph)数据库
图形结构的数据库同其它行列以及刚性结构的SQL数据库不同,它是使用灵活的图形模型,并且能够扩展到多个服务器上。NoSQL数据库没有标准的查询语言(SQL),因此进行数据库查询需要制定数据模型。许多NoSQL数据库都有REST式的数据接口或者查询API。
Neo4J InfoGrid InfiniteGraph
适用场景:
Redis:
& 数据变化较少,执行预定义查询,进行数据统计的应用程序
& 需要提供数据版本支持的应用程序
& 例如:股票价格、数据分析、实时数据搜集、实时通讯、分布式缓存
MongoDB:
& 需要动态查询支持
& 需要使用索引而不是 map/reduce功能
& 需要对大数据库有性能要求
& 需要使用 CouchDB但因为数据改变太频繁而占满内存
Neo4j:
& 适用于图形一类数据
& 社会关系,公共交通网络,地图及网络拓谱
1.5 SQL语句分类代表性关键字
DDL 数据定义语言 管理库和表 create,drop,alter等.
DCL 数据控制语言 用户管理授权 grant,revoke,commit;rollback.
DMC 数据操作语言 针对表里的数据 insert,delete,update,select
1.6 char(4)和varchar(4)的差别
char:定长字符串类型,当存储时,总是用空格填满右边到指定的长度,最大可存储 1<=M字节<=255
varchar:变长字符串类型,最大可存储1<=M字节<=255
char(4)读取的速度要比varchar(4)较快 ,因为它不需要进行计算
1.7 创建一个utf8字符集的数据库oldboy
create database oldboy character set utf8 collate utf8_general_ci;
1.8 授权oldboy用户从172.16.1.0/24访问数据库
grant all on *.* to oldboy@'172.16.1.0/255.255.255.0' identified by 'oldboy123';
1.9 什么是MySQL多实例,如何配置MySQL多实例
1) mysql多实例,简单理解就是在一台服务器上,mysql服务开启多个不同的端口(如3306、3307),运行多个服务进程。这些 mysql 服务进程通过不同的 socket来监听不同的数据端口,进而互不干涉的提供各自的服务
2) 配置mysql多实例
3) 在一台服务器上安装一套MySQL程序,起多个不同的端口,通过不同的端口来提供服务,这就是MySQL多实例。多实例有两种配置方法,按照官方的说法,是用一个配置文件,mysqld_multi模块进行配置,我在工作中喜欢用多个配置文件,多个启动文件进行配置,主要的区别就是在配置文件里server_id的区别,端口的区别,路径的区别(sock路径的不同、数据文件的不同),然后初始化的时候指定不同的配置文件初始化不同的数据库文件,然后通过不同的启动程序就可以启动MySQL了
查看系统环境:
|
1
2
3
|
[root@db01 ~]# cat /etc/redhat-releaseCentOS release 6.8 (Final) |
安装依赖包
|
1
2
3
|
yum install ncurses-devel libaio-devel -yrpm -qa ncurses-devel libaio-devel |
安装cmake
|
1
2
3
|
yum install cmake -yrpm -qa cmake |
设置用户
|
1
2
3
|
useradd -s /sbin/nologin -M mysqlid mysql |
编译安装完mysql之后,以端口为区分创建多实例库目录,编写实例文件及启动脚本
基本配置如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
[root@db02 /]# tree /data/data├── 3306│?? ├── my.cnf│?? └── mysql└── 3307 ├── my.cnf └── mysql2 directories, 4 filesmkdir /data/{3306,3307}/data -pchown -R mysql.mysql /data/find /data -name mysql|xargs chmod 700find /data -name mysql|xargs ls -lcd /application/mysql/scripts./mysql_install_db --defaults-file=/data/3306/my.cnf --basedir=/application/mysql/ --datadir=/data/3306/data --user=mysql./mysql_install_db --defaults-file=/data/3307/my.cnf --basedir=/application/mysql/ --datadir=/data/3307/data --user=mysqlecho 'export PATH=/application/mysql/bin:$PATH' >>/etc/profilesource /etc/profile/data/3306/mysql start/data/3307/mysql startnetstat -lntup|grep 330 |
1.10 加强MySQL安全
& 不设置外网ip
& 为root用户设置比较复制的密码
& 删除无用的mysql库内的用户账号,只保留root@localhost以及root@127.0.0.1
& 删除默认的test数据库
& 增加用户的时候,授权的权限尽量最小,允许访问的主机范围最小化
& 登录命令行操作不携带密码,而是回车后输入密码
1.11 mysql密码忘了如何找回
单实例找回密码:
停止已启动的mysql服务,然后--skip-grant-tables跳过授权表信息,修改密码
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
mysqld_safe --skip-grant-tables --user=mysql &mysql 登录update 修改密码flush privileges; 多实例找回密码:/data/3306/mysql stopmysql_safe --defaults-file=/data/3306/my.cnf --skip-grant-tables &myaql -S /data/3306/mysql.sockupdate mysql.user set password=PASSWORD('oldboy123') where user='root' and host='localhost';flush privileges;退出cd /data/3306vim mysqlmysql_pwd="oldboy123"/data/3306/mysql startmysql -uroot -poldboy123 -S |
1.12 delete和truncate删除数据的区别
delete from test:逻辑删除 语句删除 一行一行的删
truncate table test 直接删物理文件
前者慢后者快
1.13 mysql sleep线程过多如何解决
1、配置文件里修改:
[mysqld]
interactive_timeout = 120 此参数设置后wait_timeout自动生效。
wait_timeout = 120
2、其他方法:
1.PHP程序中,不使用持久链接,即使用mysql_connect而不是pconnect(JAVA调整连接池)。
2.PHP程序执行完毕,应该显式调用mysql_close。
3.逐步分析MySQL的SQL查询及慢查询日志,找到查询过慢的SQL,优化之。
mysql -e "show full processlist"|egrep -vi "sleep"
然后多执行几次看看同样的语句是否存在,如果存在的话,我会认为他会有慢的嫌疑,这个是抓慢查询的方法之一,就是临时紧急情况下去抓,第二种情况下 我们会在配置文件里配置三个参数,超过若干秒的查询,不走索引的查询,增加慢查询日志,每天把慢查询日志进行收集,然后通过写脚本的命令来进行切割,mysqladmin来进行切割,切割完了使用mysqlsla工具进行分析,分析完每天早晨8点,通过定时任务的方式,分析,分析完发给DBA或领导,
1.14 sort_buffer_size参数作用?如何在线修改生效
http://www.cnblogs.com/zengkefu/p/5600185.html
需要排序 会话 的缓存大小,是针对每一个connection的,这个值也不会越大越好,默认大小是256kb,过大的配置会消耗更多的内存
set global sort_buffer_size = 256;
1.15 在线清理MySQL binlog
一、没有主从同步的情况下清理日志
mysql -uroot -p123456 -e 'PURGE MASTER LOGS BEFORE DATE_SUB( NOW( ),INTERVAL 5 DAY)';
#mysql 定时清理5天前的binlog
mysql -u root -p #进入mysql 控制台
reset master; #重置binlog
二、MySQL主从同步下安全清理binlog日志
1、mysql -u root -p #进入从服务器mysql控制台
show slave status\G; #检查从服务器正在读取哪个日志,有多个从服务器,选择时间最早的一个做为目标日志。
2、进入主服务器mysql控制台
show master log; #获得主服务器上的一系列日志
PURGE MASTER LOGS TO 'binlog.000058'; #删除binlog.000005之前的,不包括binlog.000058
PURGE MASTER LOGS BEFORE '2016-06-22 13:00:00'; #清除2016-06-22 13:00:00前binlog日志
PURGE MASTER LOGS BEFORE DATE_SUB( NOW( ), INTERVAL 3 DAY); #清除3天前binlog日志
三、设置自动清理MySQL binlog日志
vi /etc/my.cnf #编辑配置
expire_logs_days = 15 #自动删除15天前的日志。默认值为0,表示从不删除。
log-bin=mysql-bin #注释掉之后,会关闭binlog日志
binlog_format=mixed #注释掉之后,会关闭binlog日志
:wq! #保存退出
1.16 BInlog工作模式有哪些?各有什么特点,企业如何选择
一,模式1 Row Level:日志中会记录成每一行数据被修改的形式,然后在slave端再对相同的数据进行修改。
优点:
row level模式下,bin-log中可以不记录执行的sql语句的上下文相关的信息,仅仅只需要记录那一条记录被修改了,修改成什么样了。所以row level的日志内容会非常清楚的记录下每一行数据修改的细节。且不会出现某些特定情况下的存储过程,或function,以及 trigger的调用和触发无法被正确复制的问题。
缺点:
row level模式下,所有的执行的语句当记录到日志中的时候,都将以每行记录的修改来记录,这样可能会产生大量的日志内容,比如有这样一条update语句:update product set owner_member_id = ‘b’ where owner_member_id = ‘a’,执行之后,日志中记录的不是这条update语句所对应额事件(MySQL以事件的形式来记录bin-log日志),而是这条语句所更新的每一条记录的变化情况,这样就记录成很多条记录被更新的很多个事件。自然,bin-log日志的量就会很大。尤其是当执行alter table之类的语句的时候,产生的日志量是惊人的。因为MySQL对于alter table之类的表结构变更语句的处理方式是整个表的每一条记录都需要变动,实际上就是重建了整个表。那么该表的每一条记录都会被记录到日志中
二,模式2 Statement Level:每一条会修改数据的sql都会记录到 master的bin-log中。slave在复制的时候sql进程会解析成和原来master端执行过的相同的sql来再次执行。
优点:
statement level下的优点首先就是解决了row level下的缺点,不需要记录每一行数据的变化,减少bin-log日志量,节约IO,提高性能。因为他只需要记录在Master上所执行的语句的细节,以及执行语句时候的上下文的信息。
缺点:
由于他是记录的执行语句,所以,为了让这些语句在slave端也能正确执行,那么他还必须记录每条语句在执行的时候的一些相关信息,也就是上下文信息,以保证所有语句在slave端杯执行的时候能够得到和在master端执行时候相同的结果。另外就是,由于MySQL现在发展比较快,很多的新功能不断的加入,使MySQL得复制遇到了不小的挑战,自然复制的时候涉及到越复杂的内容,bug也就越容易出现。在statement level下,目前已经发现的就有不少情况会造成MySQL的复制出现问题,主要是修改数据的时候使用了某些特定的函数或者功能的时候会出现,比如:sleep()函数在有些版本中就不能真确复制,在存储过程中使用了last_insert_id()函数,可能会使slave和master上得到不一致的id等等。由于row level是基于每一行来记录的变化,所以不会出现类似的问题。
三,模式3 Mixed
Mixed模式,可以理解为是前两种模式的结合。
Mixed模式下,MySQL会根据执行的每一条具体的sql语句来区分对待记录的日志形式,也就是在Statement和Row之间选择一种。
新版本中的Statment level还是和以前一样,仅仅记录执行的语句。而新版本的MySQL中队row level模式也被做了优化,并不是所有的修改都会以row level来记录,像遇到表结构变更的时候就会以statement模式来记录,如果sql语句确实就是update或者delete等修改数据的语句,那么还是会记录所有行的变更。
企业选择:
1、互联网公司,使用MySQL的功能相对少(存储过程、触发器、函数)。
选择默认的语句模式,Statement Level(默认)。
2、公司如果用到使用MySQL的特殊功能(存储过程、触发器、函数)。
则选择Mixed模式。
3、公司如果用到使用MySQL的特殊功能(存储过程、触发器、函数),又希望数据最大化一致,此时最好Row level模式。
1.17 误操作执行了drop库SQL语句,如何完整恢复
1)首先前提工作要准备充分了(提前备份了)
解压之后
sed -n "22p" 包名 查看binlog的位置
2)在利用binlog
|
1
2
3
|
grep -i drop bin.sqlsed -i '/^drop.*/d' bin.sql |
1.18 MySQLdump备份使用了-A -B 参数,如何实现恢复单表
(个人理解)
1、使用source命令(工作量感觉巨大)
#进入mysql数据库控制台,
mysql -u root -p
mysql>use 数据库
mysql>set names utf8; (先确认编码,如果不设置可能会出现乱码,注意不是UTF-8)
#然后使用source命令,后面参数为脚本文件(如这里用到的.sql)
mysql>source d:\wcnc_db.sql
2、找一台测试服务器,把备份好的数据,进行导入,然后进行调整,得到自己想要的数据,再次备份,最后进行数据恢复;
(正确答案)这就是有经验与没经验的区别
|
1
|
使用mysqlbinlog -d导出要恢复的单表,然后使用导入到数据库即可 |
1.19 详述mysql主从复制原理及配置主从的完整步骤。
原理:
MySQL 复制基于主服务器在二进制日志中跟踪所有对数据库的更改(更新、删除等等)。每个从服务器从主服务器接收主服务器已经记录到其二进制日志的保存的更新,以便从服务器可以对其数据拷贝执行相同的更新。
MySQL 使用3个线程来执行复制功能,其中1个在主服务器上,另两个在从服务器上。当发出START SLAVE时,从服务器创建一个I/O线程,以连接主服务器并让它发送记录在其二进制日志中的语句。
主服务器创建一个线程将二进制日志中的内容发送到从服务器。该线程可以识别为主服务器上SHOW PROCESSLIST的输出中的Binlog Dump线程。
从服务器I/O线程读取主服务器Binlog Dump线程发送的内容并将该数据拷贝到从服务器数据目录中的本地文件中,即中继日志。
第3个线程是SQL线程,是从服务器创建用于读取中继日志并执行日志中包含的更新。
有多个从服务器的主服务器创建为每个当前连接的从服务器创建一个线程;每个从服务器有自己的I/O和SQL线程。
1. 复制主线程的状态
Sending binlog event to slave
二进制日志由各种事件组成,一个事件通常为一个更新加一些其它信息。线程已经从二进制日志读取了一个事件并且正将它发送到从服务器。
Finished reading one binlog; switching to next binlog
线程已经读完二进制日志文件并且正打开下一个要发送到从服务器的日志文件。
Has sent all binlog to slave; waiting for binlog to be updated
线程已经从二进制日志读取所有主要的更新并已经发送到了从服务器。线程现在正空闲,等待由主服务器上新的更新导致的出现在二进制日志中的新事件。
Waiting to finalize termination
线程停止时发生的一个很简单的状态。
2. 复制从I/O线程状态
Connecting to master
线程正试图连接主服务器。
Checking master version
建立同主服务器之间的连接后立即临时出现的状态。
Registering slave on master
建立同主服务器之间的连接后立即临时出现的状态。
Requesting binlog dump
建立同主服务器之间的连接后立即临时出现的状态。线程向主服务器发送一条请求,索取从请求的二进制日志文件名和位置开始的二进制日志的内容。
Waiting to reconnect after a failed binlog dump request
如果二进制日志转储请求失败(由于没有连接),线程进入睡眠状态,然后定期尝试重新连接。可以使用–master-connect-retry选项指定重试之间的间隔。
Reconnecting after a failed binlog dump request
线程正尝试重新连接主服务器。
Waiting for master to send event
线程已经连接上主服务器,正等待二进制日志事件到达。如果主服务器正空闲,会持续较长的时间。如果等待持续slave_read_timeout秒,则发生超时。此时,线程认为连接被中断并企图重新连接。
Queueing master event to the relay log
线程已经读取一个事件,正将它复制到中继日志供SQL线程来处理。
Waiting to reconnect after a failed master event read
读取时(由于没有连接)出现错误。线程企图重新连接前将睡眠master-connect-retry秒。
Reconnecting after a failed master event read
线程正尝试重新连接主服务器。当连接重新建立后,状态变为Waiting for master to send event。
Waiting for the slave SQL thread to free enough relay log space
正使用一个非零relay_log_space_limit值,中继日志已经增长到其组合大小超过该值。I/O线程正等待直到SQL线程处理中继日志内容并删除部分中继日志文件来释放足够的空间。
Waiting for slave mutex on exit
线程停止时发生的一个很简单的状态。
3. 复制从SQL线程状态
Reading event from the relay log
线程已经从中继日志读取一个事件,可以对事件进行处理了。
Has read all relay log; waiting for the slave I/O thread to update it
线程已经处理了中继日志文件中的所有事件,现在正等待I/O线程将新事件写入中继日志。
Waiting for slave mutex on exit
线程停止时发生的一个很简单的状态。
1.20 如何开启从库的binlog功能
在my.cnf中加入
[mysqld]
log-slave-updates = 1
log-bin(5.6版本)
1.21 mysql如何实现双向互为主从复制,并说明应用场景
优点:
1. mysql的主从复制的主要优点是同步"备份", 在从机上的数据库就相当于一个(基本实时)备份库.
2. 在主从复制基础上, 通过mysqlproxy可以做到读写分离, 由从机分担一些查询压力.
3. 做一个双向的主从复制, 两台机器互相为主机从机, 这样, 在任何一个机器的库中写入, 都会"实时"同步到另一台机器, 双向的优点在于当一台主机发生故障时, 另一台主机可以快速的切换过来继续服务.
步骤:
- 在两台机器上添加一个用于从机访问的帐号, 赋予REPLICATION SLAVE权限.
- 配置服务器编号, 开启bin-log
- 使server-id和log-bin的配置修改生效:
- 将两台数据库服务器的mysql都锁定
- 分别重新打开一个mysql控台台, 配置主机
- 开启同步
- http://www.cnblogs.com/CHEUNGKAMING/p/4378522.html
1.22 mysql如何实现级联同步,并说明应用场景
B同步A,C同步B
A←B←C
1.23 MySQL主从复制故障如何解决?
在[mysqld]下面加入下面这行
binlog_format=mixed
http://storysky.blog.51cto.com/628458/259280/
1.24 如何监控主从复制是否故障?
必要条件:
& Slave_IO_Running: Yes,这个是I/O线程状态,I/O线程负责从库去主库读取binlog日志,并写入从库的中继日志中,状态为Yes表示I/O线程工作正常。
& Slave_SQL_Running: Yes,这个是SQL线程状态,SQL线程负责读取中继日志(relay-log)中的数据并转换为SQL语句应用到从数据库中,状态为Yes表示I/O线程工作正常。
& Seconds_Behind_Master: 0,这个是在复制过程中,从库比主库延迟的秒数,这个参数很重要,但企业里更准确地判断主从延迟的方法为:在主库时间戳,然后从库读取时间戳和当前数据库时间的进行比较,从而认定是否延迟。
其他略
1.25 MySQL数据库如何实现读写分离
1)程序修改mysql操作
2)amoeda
3)mysqlproxy
1.26 生产一主多从从库宕机,如何手工恢复
把备份好的数据导入
1.27 生产一主多从主库宕机,如何手工恢复?
利用从库的备份进行全量恢复,利用本地的binlog进行增量恢复
1.28 工作中遇到哪些数据库故障,请描述2个例子?
1)授权不规范
gei用户授权了all权限,导致开发通过该用户自行更改了表结构 解决:对比表结构(生产数据和备份的数据)把字段改回去
2)工作中MySQL从库停止复制故障
stop slave; #<==临时停止同步开关。
set global sql_slave_skip_counter =1 ; #<==将同步指针向下移动一个,如果多次不同步,可以重复操作。
start slave;
1.29 MySQL出现复制延迟有哪些原因?如何解决?
问题一:一个主库的从库太多,导致复制延迟。
建议从库数量3~5个为宜,要复制的从节点数量过多,会导致复制延迟。
问题二:从库硬件比主库差,导致复制延迟。
查看master和slave的系统配置,可能会因为机器配置的问题,包括磁盘IO、CPU、内存等各方面因素造成复制的延迟,一般发生在高并发大数据量写入场景。
问题三:慢SQL语句过多。
假如一条SQL语句,执行时间是20秒,那么从执行完毕,到从库上能查到数据也至少是20秒,这样就延迟20秒了。
SQL语句的优化一般要作为常规工作不断的监控和优化,如果是单个SQL的写入时间长,可以修改后分多次写入。通过查看慢查询日志或show full processlist命令找出执行时间长的查询语句或者大的事务。
问题四:主从复制的设计问题。
例如,主从复制单线程,如果主库写并发太大,来不及传送到从库就会导致延迟。更高版本的MySQL可以支持多线程复制,门户网站则会自己开发多线程同步功能。
问题五:主从库之间的网络延迟。
主从库的网卡、网线、连接的交换机等网络设备都可能成为复制的瓶颈,导致复制延迟,另外,跨公司主从复制很容易导致主从复制延迟。
问题六:主库读写压力大,导致复制延迟。
主库硬件要搞好一点,架构的前端要加buffer以及缓存层。
1.30 给出企业生产大型MySQL集群架构可行备份方案?
M(VIP)------------------S1 对外提供服务
--------------------S2 对外提供服务
--------------------S3 对外提供服务
--------------------S4 #内网、开发、财务
--------------------S5 #备份
--------------------S6 #延迟复制
M(S1)(VIP)
--------------------S2 对外提供服务
--------------------S3 对外提供服务
--------------------S4 #内网、开发、财务
--------------------S5 #备份
--------------------S6 #延迟复制
M宕机之前要尽可能先选好哪台机器做主:
(一)事先选主
n 首选半同步的S1(S1和M是实时同步的),啥都不干,干等。
u 同步:
u 半同步:S1是半同步数据库,当前的数据库S1是同步的。
u 异步:主从复制是异步的。
n 事先指定好一个S1,什么都不干(百度某个部门)。
n 主库宕机现选(数据接近主库的),比对binlog日志(master.info),文件对应数字最大,pos位置点最大。
& 不选主的危害:还得做角色转换的工作
& 每一台从库都不能设置read-only=1,不能授权连接用户select了。
& 每台机器都必须开启binlog。
& 如何提前配好选好的主?
解答:可以双主,实现角色对等,方便接管。
(二)主库宕机角色切换:
主库宕机,切换从库,确保为主的从库要尽量和主的数据保持一致。
2、主库宕机要对数据库进行数据保全
n 如果SSH连上宕机的主库服务器
u 将宕机主库的binlog补全到指定的要提升主库的从库S1以及所有的从库。
u master.info和主库最新的binlog位置比对。
u 其他从库也可以比对relay-log。
n 如果不能SSH连上宕机的主库服务器。
u 可能会丢失数据(从库master.info和主库宕机最新的binlog位置差值)。
n 临时补救:
u 以最全的从库S1为主库,然后把这个从库的中继日志数据补全到其他所有从库。
n 企业里补救措施:
1、半同步复制。
2、Web程序把数据同时双写到两台服务器(例如:1分钟)*****
3、可以把binlog实时发到binlog服务器解决主宕机binlog丢失问题。
4、主库做UPS不间断,RAID。保证不宕机。
(三)角色切换(角色切换以及主从复制)
先在S1配置好VIP
a.从库S1提升主库(主主直接切VIP)。
1)修改从库配置文件(去掉read-only、开启binlog、授权连接账号增删改查)
2)rm -f master.info relay_log*
3)登录从库S1,reset master。
4)重启S1。
b.其它从库和新的主库(S1)实现主从复制
登录新主库show master status,master.info
在所有从库上change master to ....
d.实现后的结果
(四)程序连接文件(VIP)
如果事先解析的就是VIP,就不用改
/etc/hosts
172.16.1.53 db01_w.etiantian.org
172.16.1.53 db01.etiantian.org
如果软件实现了读写分离,需要改读写分离的软件
写就发给了S1,读发给了其它的从库。
(五)修复损坏的主库,修好了做从库,尽量不要切回
条件:作为太子的从库要把主库硬件要好,不能差。
1.31 什么是数据库事务,事务有哪些特性?企业如何选择?
数据库事务就是指逻辑上的一组SQL语句操作,组成这组操作的各个SQL语句,执行时要么全
成功要么全失败。
特性:
& 原子性(Atomicity)
事务是一个不可分割的单位,事务中的所有SQL等操作要么都发生,要么都不发生
& 一致性(Cinsistency)
事务发生前和发生后,数据的完整性必须保持一致
& 隔离性(Isolation)
当并发访问数据库是,一个正在执行的事务在执行完毕前,对于其它的回话是不可见的,多个并发事务之间的数据是相互隔离的。
& 持久性(Durability)
一个事务一旦被提交,它对数据库中的数据改变就是永久性的,如果出现了错误,事务也不允许撤销,只能通过“补偿性事务”
1.32 请解释全备、增备、冷备、热备概念及企业实际经营?
全备:把数据库中所有的数据(或某个库的全部数据)进行备份 跟命令scp的原理类似(个人理解)
增备:在原有的数据的基础上增加没有的数据内容 跟raync的命令原理类似(个人理解)
冷备:备份时把服务停用(不可读 不可写)
热备:备份时(可读 可写)
1.33 MySQL的SQL语句如何优化
1、建立索引,包括条件列,连接列,外键列等
2、让where中的列顺序与符合索引的列顺序一致
3、尽量不要select *,而只列出自己需要的字段列表
4、减少子查询的层数
5、在子查询的过程中进行数据筛选
6、对大数据表删除时,用truncate table代替delete
1.34 企业生产MySQL集群架构如何设计备份方案?
1)逻辑备份的特点 应用场景:不大于30G
2)物理备份的特点
1.35 开发有一堆数据发给DBA执行,DBA执行需要注意什么?
(个人理解)
1)开发以打包邮件的形式发送给DBA
2)DBA收到之后先解压
3)大致查看SQL语句
4)执行时查看执行的过程
1.36 如何调整生产线中MySQL数据库的字符集
& 对于已有的数据库想修改字符集不能直接用‘alter database character set *’或‘alter table tablename character set *’,这两个命令都没有更新已有记录的字符集,而只是对新创建的表或者记录生效。
& 生产线中需要调整MySQL数据库的字符集:需要先将数据导出,经过修改字符集后重新导入后才可完成
1.37 请描述MySQL里中文乱码原理,如何防止乱码?
原理:字符集环境不统一导致中文乱码。 (个人理解)
防止乱码:
1、尽量不在MySQL命令行直接插入数据
2、可在MySQL命令行中用source执行sql文件
3、命令方式导入数据mysql –uroot –poldboy123 oldboy <test.sql
4、Sql文件的格式用utf8没有签名
5、Sql文件里set names utf8,或mysql –uroot –poldboy oldboy –default-character-set=utf8 <test.sql
6、建议中英文环境选择utf8
1.38 企业生产MySQL如何优化
常用客户端工具,mysqlfront , navicat , sql yog ...
根据功能选择表类型 innodb myisam
根据查询需求 创建表索引
程序查询 查询需要的字段
数据量大 ,分库分表,水平垂直拆分.
(个人理解)
优化sql语句,如果是数据库慢了,我们会登录到数据库上面去,show proact list;或者是show procter list;但是我习惯在web服务器mysql -e show procter list 去把skip进程给grep -v掉,然后多执行几次看看同样的语句是否存在,如果存在的话,我会认为他会有慢的嫌疑,这个是抓慢查询的方法之一,就是临时紧急情况下去抓,第二种情况下 我们会在配置文件里配置三个参数,超过若干秒的查询,不走索引的查询,增加慢查询日志,每天把慢查询日志进行收集,然后通过写脚本的命令来进行切割,mysqladmin flas来进行切割,切割完了使用mysql soa工具进行分析,分析完每天早晨8点,通过定时任务的方式,分析,分析完发给DBA或领导,临时抓sql语句的方法sor,定期的分析记录慢查询日志的方式,抓到慢查询了,我们要进行优化,优化最基本的就是创建索引,如何知道创建合适的索引,我们会使用explain这个命令,加在慢查询语句的前面,同时加上参数sqlnocash\G,看看它是不是走索引,其中有一个pospkey和key,key是真正的没有走索引,没有走索引的话,我们会针对where和条件的列设置索引,alter create创建索引
1.39 MySQL高可用方案有哪些,各自特点,企业如何选择
1.40 如何分表分库备份及批量恢复(口述脚本实现过程)?
mysqldump备份时加上-B参数,不全备,指定库或表进行备份,恢复时指定可指定多个库进行恢复
1.41 如何批量更改数据库表的引擎?
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
SET @DATABASE_NAME = 'name_of_your_db';SELECT CONCAT('ALTER TABLE `', table_name, '` ENGINE=InnoDB;') AS sql_statementsFROM information_schema.tables AS tbWHERE table_schema = @DATABASE_NAMEAND `ENGINE` = 'MyISAM'AND `TABLE_TYPE` = 'BASE TABLE'ORDER BY table_name DESC; |
1.42 如何批量更改数据库的字符集?
(个人理解)
1) 把需要更改字符集的数据库导出sed进行修改字符集
2) 再次导入
1.43 网站打开慢,请给出排查方法,如是数据库慢导致,如何排查并解决,请分析并举例?
首先查询sql语句,如果是数据库慢了,我们会登录到数据库上面去,show proact list;或者是show procter list;但是我习惯在web服务器mysql -e show procter list 去把skip进程给grep -v掉,然后多执行几次看看同样的语句是否存在,如果存在的话,我会认为他会有慢的嫌疑,这个是抓慢查询的方法之一,就是临时紧急情况下去抓,第二种情况下 我们会在配置文件里配置三个参数,超过若干秒的查询,不走索引的查询,增加慢查询日志,每天把慢查询日志进行收集,然后通过写脚本的命令来进行切割,mysqladmin flas来进行切割,切割完了使用mysqlsla工具进行分析,分析完每天早晨8点,通过定时任务的方式,分析,分析完发给DBA或领导,临时抓sql语句的方法sor,定期的分析记录慢查询日志的方式,抓到慢查询了,我们要进行优化,优化最基本的就是创建索引,如何知道创建合适的索引,我们会使用explain这个命令,加在慢查询语句的前面,同时加上参数sqlnocash\G,看看它是不是走索引,其中有一个pospkey和key,key是真正的没有走索引,没有走索引的话,我们会针对where和条件的列设置索引,alter create创建索引
1.44 xtranbackup的工作原理?
官方原理
在InnoDB内部会维护一个redo日志文件,我们也可以叫做事务日志文件。事务日志会存储每一个InnoDB表数据的记录修改。当InnoDB启动时,InnoDB会检查数据文件和事务日志,并执行两个步骤:它应用(前滚)已经提交的事务日志到数据文件,并将修改过但没有提交的数据进行回滚操作。
http://sofar.blog.51cto.com/353572/1313649
1 xtrabackup只能备份innodb和xtradb两种引擎的表,而不能备份myisam引擎的表;
1.45 误执行drop数据,如何通过xtranbackup恢复?
完全备份集的恢复。
& 在InnoDB表的备份或者更直接的说ibd数据文件复制的过程中,数据库处于不一致的状态,所以要将xtraback_logfile中尚未提交的事务进行回滚,以及将已经提交的事务进行前滚,使各个数据文件处于一个一致性状态,这个过程叫做“准备(prepare)”
& 如果你是在一个从库上执行的备份,那说明你没有东西需要回滚,只是简单的apply redo log就可以了。另外在prepare过程中可以使用参数--use-memory增大使用系统内存量从而提高恢复速度。
& 之后,我们就可以根据backup-my.cnf中的配置把数据文件复制回对应的目录了,当然你也可以自己复制回去,但innobackupex都会帮我们完成。在这里,对于InnoDB表来说是完成“后准备”动作,我们称之为“恢复(recovery)”,而对于MyISAM表来说由于备份时是采用锁表方式复制的,所以此时只是简单的复制回来,不需要apply log,这个我们称之为“还原(restore)”。
增量备份的恢复过程:
& 恢复过程需要使用完全备份集和各个增量备份集,各个备份集的恢复与前面说的一样(前滚和回滚),之后各个增量备份集的redo log都会应用到完全备份集中;
& 对于完全备机集之后产生的新表,要有特殊处理方式,以便恢复后不丢表;
& 要以完全备份集为基础,然后按顺序应用各个增量备份集。
1.46 如何做主从数据一致性校验?
pt-table-checksum是一个在线验证主从数据一致性的工具,主要用于以下场景:
1. 数据迁移前后,进行数据一致性检查
2. 当主从复制出现问题,待修复完成后,对主从数据进行一致性检查
3. 把从库当成主库,进行数据更新,产生了"脏数据"
4. 定期校验
http://blog.chinaunix.net/uid-16844903-id-3360228.html
1.47 如何监控MySQL的增删改查次数?
1.48 MySQL索引的种类及工作原理
一、普通索引 这是最基本的索引,它没有任何限制。 ...
二、唯一索引 它与前面的普通索引类似,不同的就是:索引列的值必须唯 一...
三、主键索引 它是一种特殊的唯一索引,不允许有空值。
1.49 请描述MySQL不同引擎锁的机制
1.50 请描述innoDB支持的四种事务隔离级别名称及特点
1.51 如何自定义脚本启动MySQL(说出关键命令)
|
1
|
mysqld_safe --defaults-file=/data/${port}/my.cnf --pid-file=$mysqld_pid_file_path |
1.52 如何自定义脚本平滑关闭MySQL(说出关键命令)
|
1
2
3
4
5
|
read mysqld_pid < "$mysqld_pid_file_path" #pid的文件kill -HUP $mysqld_pid && log_success_msg "Reloading service MySQL"touch "$mysqld_pid_file_path" |
1.53 开启MySQL服务
1)单实例
/etc/init.d/mysqld start
3) 多实例
/data/端口/myql start
1.54 检测端口是否运行
1、ps -ef|grep mysqld 2、lsof -i:3306
1.55 为MySQL设置密码或者修改密码

初始化设置密码: mysqladmin -uroot password oldboy123 修改密码: mysqladmin -uroot -poldboy123 password 123456
1.56 登陆MySQL数据库
单实例:
mysql -uroot -poldboy123
多实例:
mysql -uroot –poldboy123 –S /data/3306/mysql.sock
1.57 查看当前数据库的字符集
mysql> show variables like "character_set_%";
1.58 查看当前数据库的版本

1.59 查看当前登陆的用户

1.60 查看的用户oldboy拥有哪些权限

1.61 创建GBK字符集的数据库oldboy,并查看已建库完整语句
mysql> create database oldboy character set gbk collate gbk_chinese_ci; mysql> show create database oldboy\G
1.62 创建用户oldboy,使之可以管理数据库oldboy
mysql> grant all on oldboy.* to 'oldboy'@'localhost' identified by 'oldboy123'; 创建带授权
1.63 查看创建的用户oldboy拥有哪些权限
mysql> show grants for oldboy@'localhost'\G *************************** 1. row *************************** Grants for oldboy@localhost: GRANT USAGE ON *.* TO 'oldboy'@'localhost' IDENTIFIED BY PASSWORD '*FE28814B4A8B3309DAC6ED7D3237ADED6DA1E515' *************************** 2. row *************************** Grants for oldboy@localhost: GRANT ALL PRIVILEGES ON `oldboy`.* TO 'oldboy'@'localhost' 2 rows in set (0.00 sec)
1.64 查看当前数据库里有哪些用户
mysql> select user,host from mysql.user;
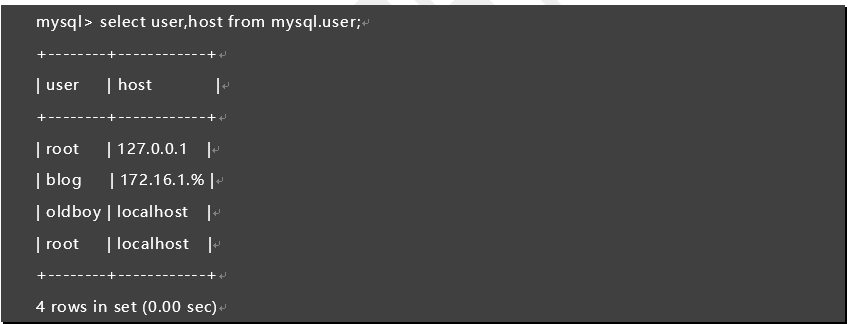
1.65 进入oldboy数据库
mysql> use oldboy; Database changed
1.66 创建innodb GBK表test,字段id和name varchar(16)
mysql> create table test( id int(4), name varchar(16) ) ENGINE=innodb default charset=gbk; gbk'字符集
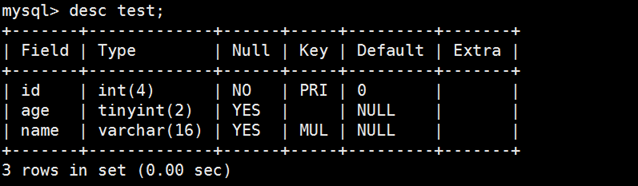
1.67 查看建表结构及表结构的SQL语句
mysql> desc test;

1.68 插入一条数据‘1,oldboy’
mysql> select * from test; Empty set (0.00 sec) mysql> insert into test values(1,'oldboy'); mysql> select * from test;

1.69 再批量插入2行数据,‘2,老男孩’,‘3,oldboyedu’
mysql> insert into test values(2,'老男孩'),(3,'oldboyedu');

1.70 查询名字为oldboy的记录
mysql> select * from test where name='oldboy';

1.71 把数据id等于1的名字oldboy更改为oldgirl。
mysql> update test set name='oldgirl' where id=1;
1.72 在字段name前插入age字段,类型tinyint(2)。
mysql> alter table test add age tinyint(2) after id;

1.73 不退出数据库备份oldboy数据库。
mysql> system mysqldump -uroot -poldboy123 -B oldboy >/opt/oldboy.sql
1.74 删除test表中的所有数据,并查看。
mysql> delete from test; mysql> truncate table test; mysql> select * from test;

1.75 删除表test和oldboy数据库并查看。
(个人理解)删除oldboy库test表也就删除了 但题目要求 就跟着题目要求来
mysql> drop table test; mysql> show tables; mysql> drop database oldboy; mysql> show databases;
1.76 不退出数据库恢复以上删除的数据。
mysql> system mysql </opt/oldboy.sql
1.77 在把id列设置为主键,在Name字段上创建普通索引。
mysql> alter table test add primary key(id); mysql> create index index_name on test(name); 或者 alter table test add index index_name(name)
1.78 在字段name后插入手机号字段(shouji),类型char(11)。
mysql> alter table test add shouji char(11);
1.79 所有字段上插入2条记录(自行设定数据)。
mysql> insert into test values(4,24,'xjc','18796965487'),(5,18,'oldboy','13556897512');
1.80 查询手机号以135开头的,名字为oldboy的记录(提前插入)。
mysql> select * from test where name='oldboy' and shouji like "135%";

1.81 收回oldboy用户的select权限。
mysql> revoke select on oldboy.* from 'oldboy'@'localhost';
1.82 删除oldboy用户。
mysql> drop user 'oldboy'@'localhost';
1.83 删除oldboy数据库。
mysql> drop database oldboy;
1.84 使用mysqladmin关闭数据库。
[root@db02 ~]# mysqladmin -uroot -poldboy123 shutdown [root@db02 ~]# netstat -lntup|grep mysql
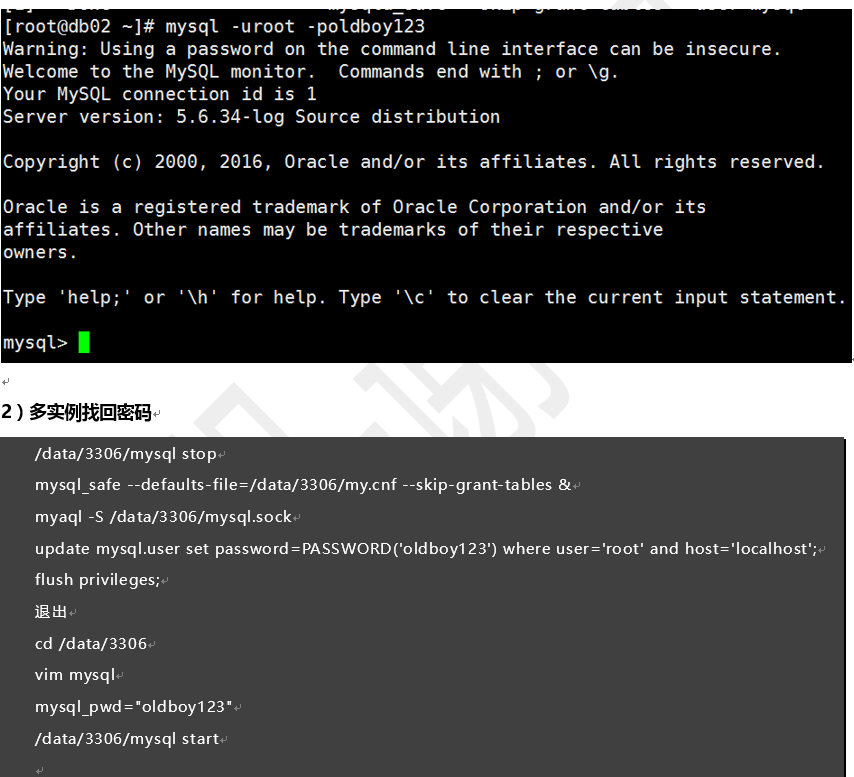
1.85 MySQL密码丢了,请找回?
1)单实例找回密码
[root@db02 ~]# mysqld_safe --skip-grant-tables --user=mysql &
[root@db02 ~]# mysql
mysql> update mysql.user set password=password('oldboy123') where user='root' and host='localhost';
[root@db02 ~]# /etc/init.d/mysqld restart
[root@db02 ~]# mysql -uroot -poldboy123
2)多实例找回密码
/data/3306/mysql stop
mysql_safe --defaults-file=/data/3306/my.cnf --skip-grant-tables &
myaql -S /data/3306/mysql.sock
update mysql.user set password=PASSWORD('oldboy123') where user='root' and host='localhost';
flush privileges;
退出
cd /data/3306
vim mysql
mysql_pwd="oldboy123"
/data/3306/mysql start
mysql -uroot -poldboy123 -S

1.86 查看创建的索引及索引类型等信息
mysql> system mysql </opt/oldboy.sql mysql> use oldboy; show index from test\G
1.87 查询上述语句的执行计划(是否使用联合索引)
explain select * from test where name='oldboy' and shouji like '135%'\G
1.88 把test表的引擎改为myisam
show create table test\G alter table test ENGINE=MYISAM; show create table test\G
1.89 对name列的前6个字符以及手机列的前8个字符组建联合索引
alter table test add index index_name_shouji(name(6),shouji(8)); show index from test\G

