🍖文件处理三剑客:sed awk grep
引入
🌀我们都知道,在Linux中一切皆文件,比如配置文件,日志文件,启动文件等等
🌀如果我们相对这些文件进行一些编辑查询等操作时,我们可能会想到一些vi,vim,cat,more等命令
🌀但是这些命令效率不高,而在linux中有三种工具:顶配awk,中配sed,标配grep
🌀使用这些工具,我们能够在达到同样效果的前提下节省大量的重复性工作,提高效率
🌀文件内容可以是来自文件,也可以直接来自键盘或者管道等标准输入,最后的结果默认情况下是显示到终端的屏幕上,但是也可以输出到文件中
🌀编辑文件也是这样,以前我们修改一个配置文件,需要移动光标到某一行,然后添加点文字,然后又移动光标到另一行,注释点东西.......可能修改一个配置文件下来需要花费数十分钟,还有可能改错了配置文件,又得返工
🌀这还是一个配置文件,如果数十个数百个呢?因此当你学会了sed命令,你会发现利用它处理文件中的一系列修改是很有用的
🌀只要想到在大约100多个文件中,处理20个不同的编辑操作可以在几分钟之内完成,你就会知道sed的强大了✅
🔵天然支持管道
一.文本处理之sed
1.什么是sed
- sed 被称为流式编辑器
- 主要擅长对文件的编辑操作
- 用法 : 事先制定好编辑文件的规则, 然后让sed自动完成对文件的整体编辑
2.为什么用sed (与vim对比)
- 处理多个文件时
"sed"可以把处理文件的规则事先写好,然后用同一套规则编辑多个文件
🔴而"vim"只能一个一个编辑
- 处理大文件时
"sed"处理文件一次只处理一行, 即同一时间内存中只有文件的一行内容,
无论文件多大, 都不会对内存造成过大的压力
🔴而"vim"是将文件所有内容一次性读入内存
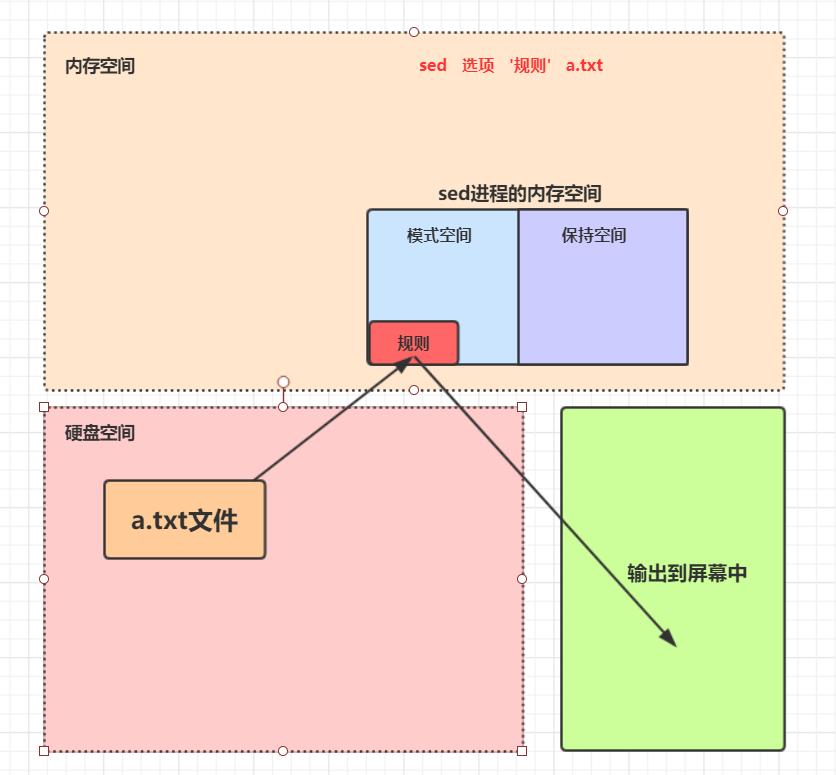
3.sed的工作原理
- sed 读取一行, 首先将这行放入到缓存中
- 然后对其进行规则处理
- 处理完成后才将缓存区的内容发送到终端屏幕
- 存储 sed 读取到的内容的缓存区空间称之为 : 模式空间
4.怎么用sed
-
语法结构
sed [选项] '[规则]' [文件] #规则建议用单引号操作
sed [选项] '[定位 命令]' [文件]
-
常用选项
| 选项 | 功能 |
|---|---|
| -n | 取消默认输出 |
| -i | 直接修改文件内容 (规则处理的结果 + 默认输出的结果) 覆盖入文件, 而不是输出 |
ps : 如果不使用 -i 选项 sed 软件只是修改在内存中的数据,并不会影响磁盘上的文件
-
规则 (定位 + 命令)
- 行号定位
⛅不填定位默认匹配所有行 sed '1p' a.txt #打印第一行(这里是定位了第一行) sed '1,3p' a.txt #定位了 1~3 行 sed '1p;3p' a.txt #定位了第一行和第三行(命令与命令用";"隔开)- 正则定位
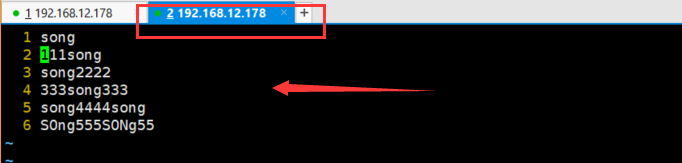
sed '/^song/p' a.txt #匹配以"song"开头的行并打印 sed '/song$/p' a.txt #匹配以"song"结尾的行并打印 sed '/^song$/p' a.txt #只匹配"song"并打印命令 -
常用命令
| 命令 | 功能 |
|---|---|
| p | 打印模式空间的内容 |
| d | 删除指定的行 |
| i | 插入, 在指定行前面添加一行或者多行 |
| s///gi | 替换字符 |
5.应用示例
- sed '2p' a.txt
定位第二行并打印
运行的效果是 "默认输出" + "规则 p 输出"

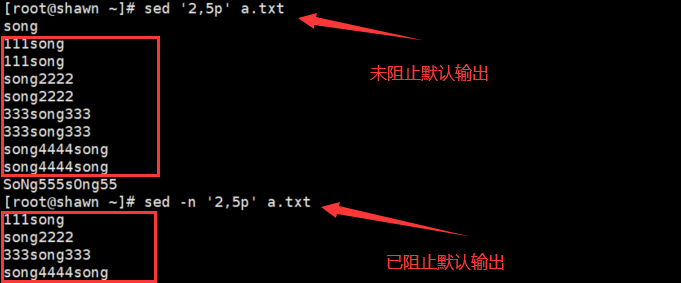
- 加入 "-n" 选项来阻止默认输出
可能你只想显示你定位的那行运行命令的结果
这是你就可以用到 "-n" 选项了

- sed '2,5p' a.txt
定位 2~5 行并打印
- sed "3d;5d;7d" a.txt
定位 3, 5 ,7行并删除
注意:每一个命令需要用 ";" 隔开

- 加入 "-i" 选项让修改内容写入文件
以上操作没有加入 "-i" 选项, 其实并没有写入到文件里面
只是将处理结果输出到屏幕上了 (适合调试的时候)
想将命令结果写入文件需要用到 "-i" 选项

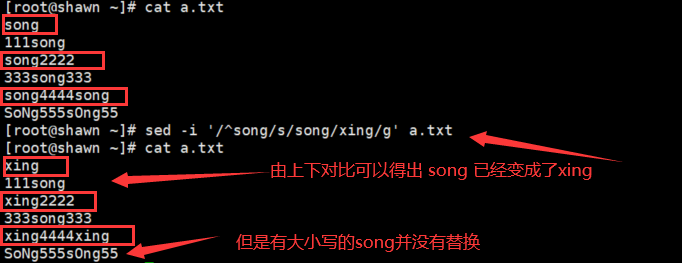
- sed -i '/^song/s/song/xing/g' a.txt
匹配以 "song" 开头的行, 然后把 "song" 替换成 "xing"
"-i" 将结果写入文件
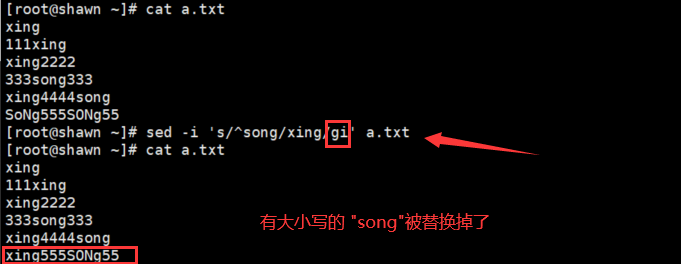
- 加入 "i" 选项不区分大小写替换
sed -i 's/^song/xing/gi' a.txt
在 "g" 的后面加了 "i"
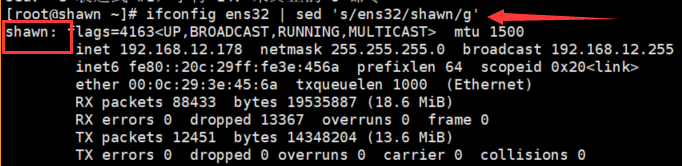
- ifconfig ens32 | sed 's/ens32/shawn/g'
将 'ens32' 网卡信息放入管道
然后 "sed" 从管道中拿出结果进行下一步操作(这里事替换掉网卡名字)
- 取反操作 "!"
sed -n '1,3!p' a.txt #取除了1~3的行

二.文件处理之awk
1.AWK
- 主要擅长处理有规律的文本, 主要用于一些格式化处理
- awk不仅仅是 linux系统中的一个命令,而且是一种编程语言,可以用来处理数据和生成报告(excel)
- 处理的数据可以是一个或多个文件,可以是来自标准输入,也可以通过管道获取标准输入
- awk可以在命令行上直接编辑命令进行操作,也可以编写成awk程序来进行更为复杂的运用。
2.用法
-
语法结构
awk [选项] '[规则]' [文件路径]
awk [选项] '[定位{命令}]' [文件路径]
-
awk选项
-F[指定分隔符]
-F: #以冒号分隔
-F" " #以空格分隔
-F #没写默认以空格分隔
-
规则 (定位 + 命令)
- 行号定位
⛅"NR"代表行 ⛅"NF"代表最后一段的段号 ⛅"$1"代表分隔的第一段,2,3...类似 ⛅"$0"代表着整行(所有段) awk -F: 'NR == 3{print $1,$3}' b.txt #以":"分隔每行,并选择打印第三行的1和3段 awk -F: 'NR >= 3 && NR <= 8{print $1,$3}' b.txt #大于3并且小于8的行的1和3段 awk -F: 'NR <= 3 || NR >= 8{print $1,$3}' b.txt #小于3或者大于8的行的1和3段 awk -F: 'NR == 3 || NR == 8{print $1,$3}' b.txt #第 3 行和第 8 行的1和3 段- 正则定位
"$0"代表着整行(所有段) awk -F: '/^root/{print $0}' b.txt #匹配以root开头的行,然后打印整行 awk -F: '/bash$/{print $1,$2}' b.txt #匹配以bash结尾的行,然后打印1,2duan -
命令
$0 #输出整条记录
$NF #输出最后一个字段
$(NF-1) #倒数第二个
.....
...
..类推
3.应用示例
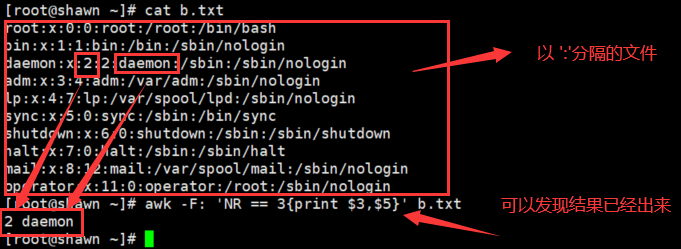
- awk -F: 'NR == 3{print $1,$5}' b.txt
以 ":" 做分隔符匹配文件的第 3 行, 然后打印 1 和 5 段
- awk -F: 'NR >= 3 && NR <= 8{print $0}' b.txt
匹配 3 到 8 行并打印整行

- awk -F: 'NR == 1 || NR == 3{print $NF}' b.txt
匹配 1 和 3 行,并打印最后一段

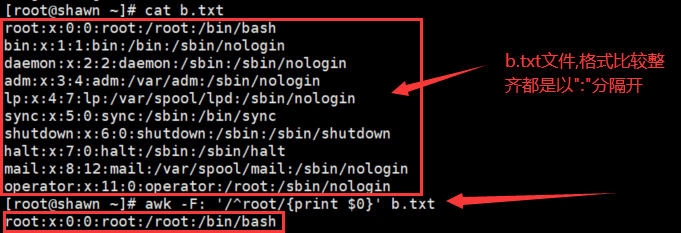
- awk -F: '/^root/{print $0}' b.txt
匹配以"root"开头的整段
- awk -F: '/bash$/{print $(NF-2)}' b.txt
匹配以 "bash" 结尾的行,打印倒数第 3 段

三.文件处理之grep
1.grep作用
- 过滤文本内容
2.用法
-
语法
grep [选项] ['过滤规则'] [文件]
-
常用选项
| 选项 | 功能 |
|---|---|
| -n | 显示行号 |
| -i | 忽略大小写 |
| -l | 过滤的文件只要有匹配字符就会返回文件名 |
| -r | 目录下带有关键字的文件 |
-
常用规则
| 符号 | 描述 |
|---|---|
| ^ | 匹配以某个字符开头的行 |
| $ | 匹配以某个字符结尾的行 |
3.应用示例
- grep -n 'song' a.txt
在"a.txt"中搜索"song",并且会显示行号

- grep -in '^song' a.txtgre
不区分大小写查找以"song"为开头的行

- grep -r 'song' /root
显示目录下带有关键字的文件
一般与"-l"连用

- grep -rl 'song' /root
返回"root"目录下含有"song"的文件名

4.grep通过管道过滤进程信息
- 在一个终端上打开一个vim进程
-
通过 ps aux | grep '[v]im' 过滤 "vim" 进程
-
通过 kill -9 24762(进程号杀死它)

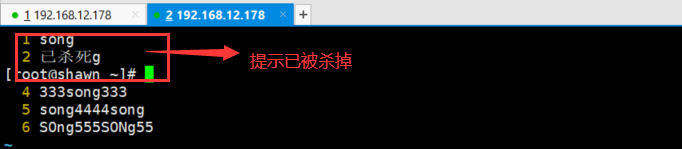
5.Windows下杀进程
- ctrl + alt + delete 调用任务管理器, 右击任务终止
- 以管理员身份进入 cmd 解释器
- tasklist 显示当前进程, PID是进程号
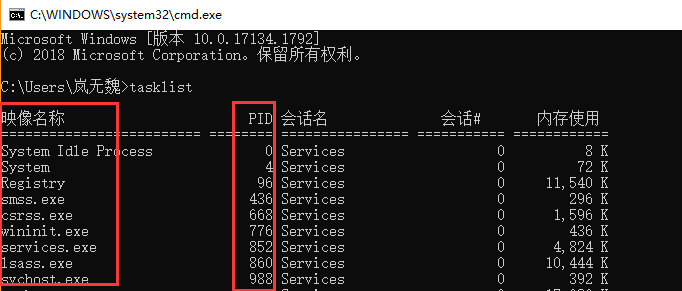
- 使用 tasklist | findstr "WeChat.exe" 通过查找进程名来找到 PID
- 使用 taskkill /F /PID 9900 通过PID号来终止进程


 浙公网安备 33010602011771号
浙公网安备 33010602011771号