Elasticsearch面试题汇总
1. 什么是搜索引擎
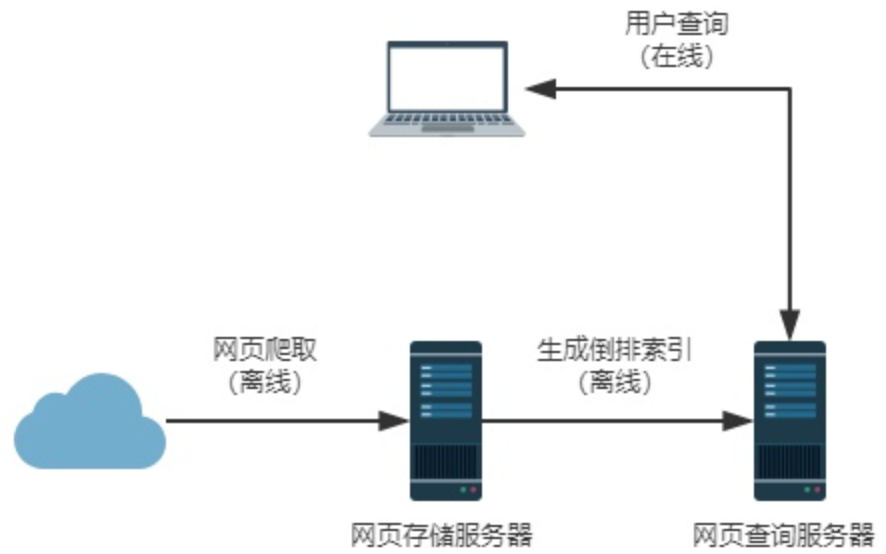
搜索引擎(Search Engines)是一个对互联网上的信息资源根据用户需求与一定的算法,运用特定策略从互联网进行搜集整理(网页爬虫程序来执行搜集任务),然后供你查询的系统,它包括信息搜集、信息整理和用户查询三部分。
下图是搜索引擎简单工作原理图
2. 什么是lucene?
Lucene是java语言开发的一个全文检索引擎工具包,通过lucene可以让程序员快速开发一个全文检索功能。
3. 正排索引和倒排索引
正排索引(forward index)是从文档角度来找其中的单词,表示每个文档(用文档ID标识)都含有哪些单词,以及每个单词出现了多少次(词频)及其出现位置(相对于文档首部的偏移量)。所以每次搜索都是遍历所有文章。
倒排索引(inverted index)也可以叫做反向索引,是关键词到文档的映射(关键词-->文档),根据关键词能找到它在哪些文档里出现过,以及出现的位置,频率等信息。
ES为什么使用倒排索引
ES底层使用的是Lucene的倒排索引技术。
倒排索引的优点:
1)查询速度快,不会因为查询内容的增加,而导致查询速度变慢。
2)索引文件会占用磁盘空间,用空间来换时间。
4. 为啥搜索引擎不使用Mysql
1)数据库Like模糊搜索是典型的顺序扫描方法,数据量大就搜索得特别慢,数据量大了性能很差,最重要的是无法进行分词检索。
2)目前各大DBMS的全文索引支持性还不是很好。以MySQL为例子:MySQL不支持中文全文检索,虽然支持英文的全文检索但表的存储引擎要是MyISAM,默认存储引擎InnoDB不支持全文索引(MYSQL5.6以上的InnoDB支持全文索引),而且不支持中文分词,需要自行扩展。
3)DBMS数据库适合结构化数据的精确查询,而不适合半结构化、非结构化数据的模糊查询及灵活搜索(特别是数据量大时),无法提供想要的实时性。
4)DBMS数据库不适合存储非结构化数据。
5. 什么是全文索引
一、生活中的数据总体分为:
结构化数据:指具有固定格式或有限长度的数据,如数据库,元数据等。
非结构化数据:指没有固定格式或不定长的数据,如邮件,word文档等,非结构化数据还有一种叫法:全文数据。
二、按数据的分类,搜索也分为两种: 对结构化数据的搜索: 如对数据库的搜索:SQL语句。 再如windows的搜索:文件名,类型,修改时间。 对非结构化数据的搜索: 如windows对文件内容的搜索。 Linux下得grep命令。 再如Google和百度可以搜素大量内容数据。 对于非结构化的数据搜索也叫做对全文数据的搜索。
三、对全文数据的搜索还可以分为两种 1、顺序扫描:如要找内容包含某个字符串的文件,会一个文档一个文档的从头到尾的找,如 Like查找 。 2、索引扫描:把非结构化的数据中的内容提取出来一部分重新组织,让它变的有结构化,这部分我们提取出来的数据就叫做索引.
全文检索分两个过程:
索引创建(Indexer):将现实世界中所有的结构化和非结构化数据提取信息,创建索引的过程。
搜索索引(Search):就是得到用户的查询请求,搜索创建的索引,然后返回结果的过程。
6. 描述一下Elasticsearch搜索的流程
1. 搜索被执行成一个两阶段过程,我们称之为 Query Then Fetch;
2. 在初始查询阶段时,查询会广播到索引中每一个分片拷贝(主分片或者副本分片)。每个分片在本地执行搜索并构建一个匹配文档的大小为 from + size 的优先队列。
在搜索的时候是会查询 Filesystem Cache 的,但是有部分数据还在 MemoryBuffer,所以搜索是近实时的。
3. 每个分片返回各自优先队列中 所有文档的 ID 和排序值 给协调节点,它合并这些值到自己的优先队列中来产生一个全局排序后的结果列表。
4. 接下来就是 取回阶段,协调节点辨别出哪些文档需要被取回并向相关的分片提交多个 GET 请求。每个分片加载并 丰 富 文档,如果有需要的话,接着返回文档给协调节点。一旦所有的文档都被取回了,协调节点返回结果给客户端。
5. Query Then Fetch 的搜索类型在文档相关性打分的时候参考的是本分片的数据,这样在文档数量较少的时候可能不够准确,DFS Query Then Fetch 增加了一个预查询的处理,询问 Term 和 Document frequency,这个评分更准确,但是性能会变差。
