
【Redis】Redis缓存穿透解决方案之布隆过滤器
引出布隆过滤器(Bloom-Filter)
在海量数据面前如何去过滤,及查找数据。下面有几个问题:
1. 总共有50亿个电话号码,现在已经知道10万个号码,如何在这100亿个电话号码中去快速判断这些10万个号码是否存在?
2. 垃圾邮件过滤。
3.wps文字处理软件错误单词的检测。
4. 网络爬虫重复URL检测。
5. Hbase行过滤器。
上面的问题都有一些特点,数据量很大,并且要在海量数据中查找其中几条或者部分数据。看看常规的解决方法及问题:
1. 所有数据放在数据库,通过数据库查询,但是实现快速查询有点困难。
2. 数据全部放在集合里,数据所占空间:50亿 * 8字节 = 大约40G,内存浪费而且数据量更大内存空间不一定够。
3. Redis的hyperloglog,查询不够准确。
当数据量较小,内存又足够大时,使用hashMap或者hashSet等结构就好了。但是如果当这些数据量很大,数十亿甚至更多,内存装不下且数据库检索又极慢的情况,在1970年伯顿.布隆就提出了可以用很小的空间来解决上面那些类似问题。
布隆过滤器基本原理
实现原理:
用一个很长的二进制向量( 也可以理解成bit数组)和若干个哈希函数,这些哈希函数通过计算你要找到的值是否映射在这个二进制向量中。
布隆过滤器初始化的时候bit数组里的值都是0.
当我们将一个元素加入布隆过滤器中的时候,会进行如下操作:
1. 使用布隆过滤器中的哈希函数对元素值进行计算,得到哈希值(也就是bit数组中的索引位置,有多少个个哈希函数就会得到多少个哈希值)。
2. 根据得到的哈希值,在bit数组中把这些哈希值对应下标的值都置为 1。
当我们判断一个元素是否存在于布隆过滤器的时候,会进行如下操作:
1. 对给定元素再次进行相同的哈希计算;
2. 得到值之后判断位数组中的每个元素是否都为 1,如果值都为 1,那么说明这个值在布隆过滤器中,如果存在一个值不为 1,说明该元素不在布隆过滤器中。
下图就是查询一个手机号是否在布隆过滤器中示意图。
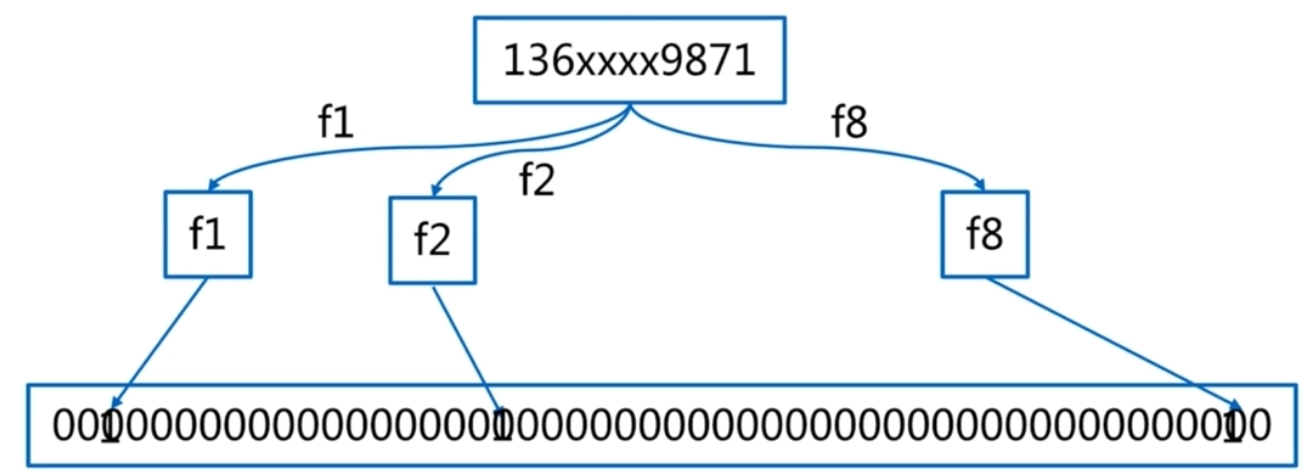
布隆过滤器的误差率
布隆过滤器是有一定的误差率的。虽然布隆过滤器是一种空间效率占用极少和查询时间极快的算法,但是需要业务可以忍受一个判断失误率。
Redis布隆过滤器


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现
· 25岁的心里话