
Java线程池ThreadLocal
先看一段代码
public class ThreadDemo extends Thread{ private String name; public ThreadDemo(String name) { this.name = name; } @Override public void run() { System.out.println(name); } public static void main(String[] args) { new ThreadDemo("i am song1").run(); new ThreadDemo("i am song2").start(); } }
执行的结果

有个问题,上面这两行代码有什么区别?
start()方法来启动线程是真正实现了多线程运行,这时无需等待run方法体代码执行完毕。run()是属于方法级别的调用,其实就相当于是调用了一个普通函数而已,直接待用run()方法必须等待run()方法执行完毕才能执行下面的代码,所以执行路径还是只有一条,根本就没有线程的特征,所以在多线程执行时要使用start()方法而不是run()方法。
如何证明呢?

我们打了断点然后debug之后,可以看到在执行代码第9行和第13行当前线程名都是main@1,线程的状态是RUNNABLE,也就是说当前创建的run方法和调用执行的run方法这两个方法只有一个线程。
下面我们注释run方法,打开start方法在去debug查看

执行到第14行时候看到线程是main@1,只有一个主线程,但是当执行到第9行时候,看到此时线程的名字是Thread-0@471。
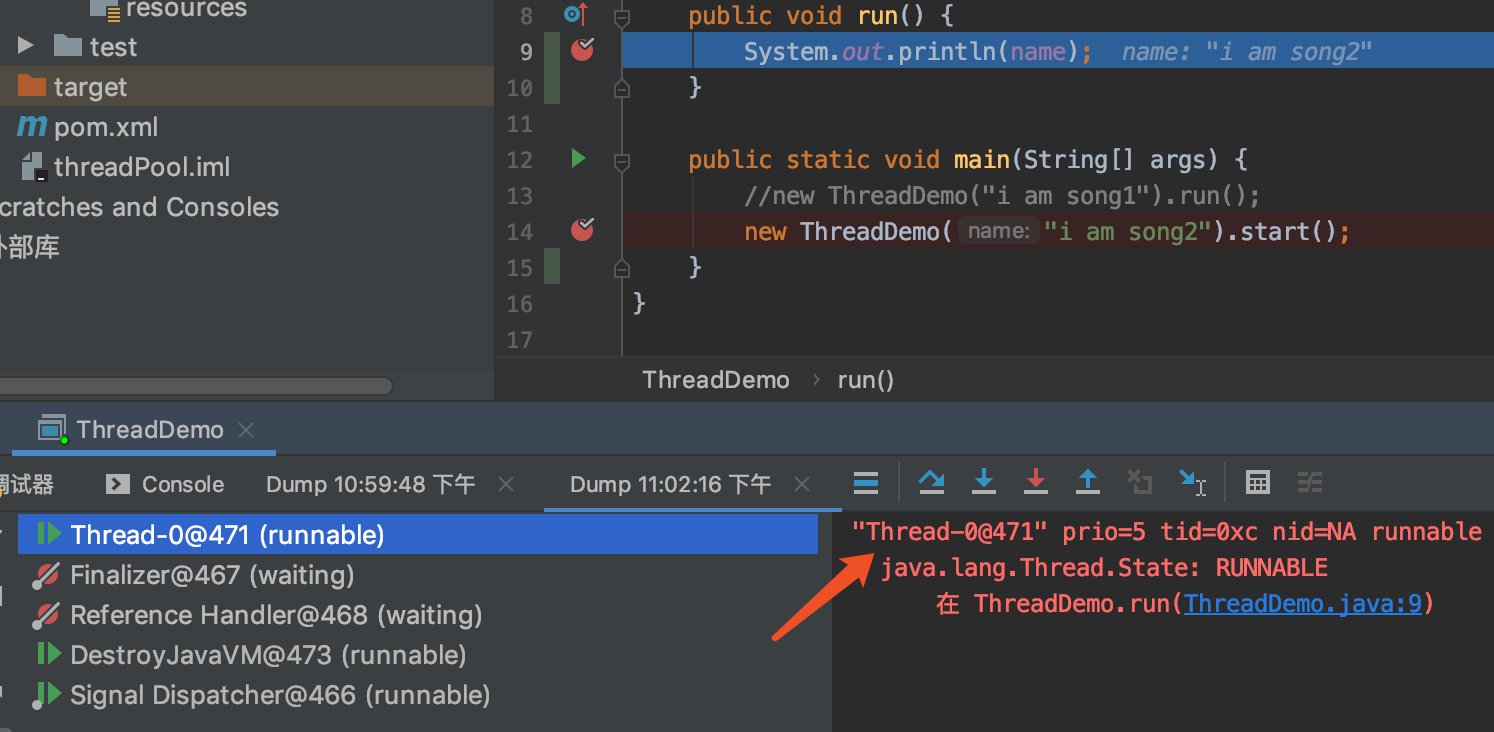
也就是说当使用start方法时候,除了有main线程还有Thread-0编号线程。
通过上面的例子,可以发现方法级别调用的的run方法和start方法本质上线程的个数不一样,run方法之始至终只有一个主线程执行,这个主线程会运行main方法,也会运行run方法,而多线程的start方法调用会有两个线程。
这个和我们下面要说的线程池有很大的关系。
下面在看两段代码:
1. 使用普通的线程:代码循环体中每次循环会创建一个线程,然后向list集合中添加一个随机数,然后计算出总的运行时间和大小。
import java.util.ArrayList; import java.util.List; import java.util.Random; public class ThreadTest { public static void main(String[] args) throws InterruptedException { Long start = System.currentTimeMillis(); final Random random = new Random(); final List<Integer> list = new ArrayList<Integer>(); for (int i = 0; i < 100000; i++) { Thread thread = new Thread() { @Override public void run() { list.add(random.nextInt()); } };
// 启动线程 thread.start();
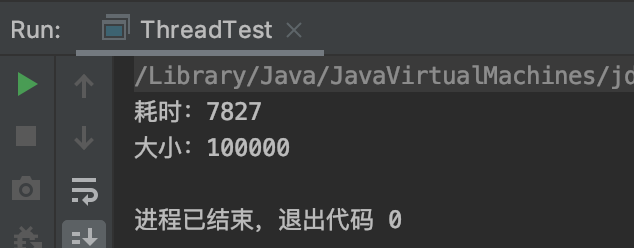
// main主线程一直等待上面所有线程直到执行完成 thread.join(); } System.out.println("耗时:"+(System.currentTimeMillis() - start)); System.out.println("大小:"+list.size()); } }
运行结果
2. 使用线程池的方式:也是循环10w次。
import java.util.ArrayList; import java.util.List; import java.util.Random; import java.util.concurrent.ExecutorService; import java.util.concurrent.Executors; import java.util.concurrent.TimeUnit; public class ThreadPoolTest { public static void main(String[] args) throws InterruptedException { Long start = System.currentTimeMillis(); final Random random = new Random(); final List<Integer> list = new ArrayList<Integer>();
// 使用线程池 Executors是java自带的线程池的工具类 ExecutorService executorService = Executors.newSingleThreadExecutor(); for (int i = 0; i < 100000; i++) { executorService.execute(new Runnable() { public void run() { list.add(random.nextInt()); } }); } executorService.shutdown(); executorService.awaitTermination(1, TimeUnit.DAYS); System.out.println("耗时:"+(System.currentTimeMillis() - start)); System.out.println("大小:"+list.size()); } }
运行结果

对比上面两段代码:
代码1运行的时间比代码2使用线程池的方式运行时间长很多,可以得知使用线程池的方式比使用普通线程的方式效率高很多。使用普通线程的方式性能慢点原因是因为创建线程所需要cpu调度及线程切换所耗费的时间比较多导致。
ThreadLocal是什么
ThreadLocal叫做线程变量,意思是ThreadLocal中填充的变量属于当前线程,该变量对其他线程而言是隔离的。ThreadLocal为变量在每个线程中都创建了一个副本,那么每个线程可以访问自己内部的副本变量。
使用ThreadLocal的场景
1.数据库连接池。
2.基于mybatis的分页插件PageHelper中使用到ThreadLocal。
3.使用ThreadLocal和AOP做线程缓存提高性能,缩短API网关响应时间。

