


Elasticsearch分词
分词器介绍
Elasticsearch作为全文检索服务是需要将输入的搜索关键字,也就是字符串进行一定规则的拆分,而拆分搜索关键字为一个个词,这部分功能是有ES的分词器来完成的。分词器(analyzer) 接受一个字符串作为输入,将这个字符串拆分成独立的词或 语汇单元(token)(可能会丢弃一些标点符号等字符),然后输出一个 语汇单元流(token stream) 。ES内部也集成了分词器。
ES中文分词器有常见四种
1. Standard:ES默认的分词器,将词汇单元转换为小写形式,并且去除停用词(在信息检索中,为节省存储空间和提高搜索效率,在处理自然语言数据或文本之前或之后会自动过滤掉某些字或词)、标点符号,支持中文(单字切分)。
2. Simple:通过非字母字符来分割文本信息,然后将词汇单元统一转换为小写形式,会去除掉数字类型的字符。
3. Whitespace:仅仅是去除空格、不支持中文,对分割的词汇单元不做标准化的处理,也不会将字符转换成小写。
4. language:特定语言分词器,但是不支持中文。
IKAnalyzer分词器的安装及使用
我们先使用Kibana来查看分词点效果。
POST _analyze { "analyzer": "standard", #指定分词方式 "text":"hello 中国" }
使用POST方式向ES发起分词请求,下图使用的是Standard分词方式,他可以支持中英文。
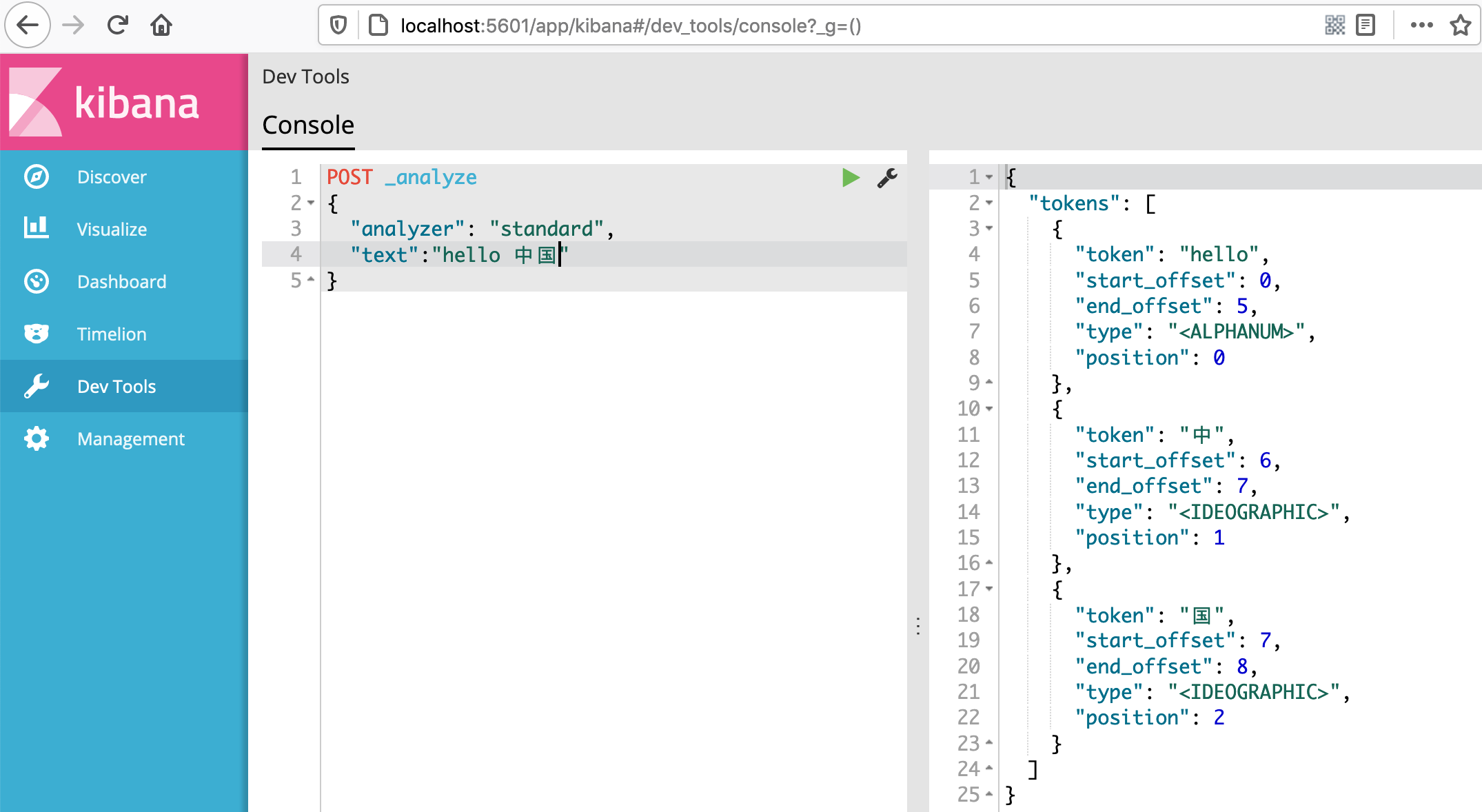
上面结果看到将中文的部分按照单个字为最小词元来拆分,这个分词效果并不好,所以我们使用ES中一个分词器iK分词器,这个分词器是目前支持中文比较好的第三方分词器插件。
ik分词器ES插件地址github地址:https://github.com/medcl/elasticsearch-analysis-ik
下载安装
从这个Releases点击进去,找到适合当前适合ES的版本。
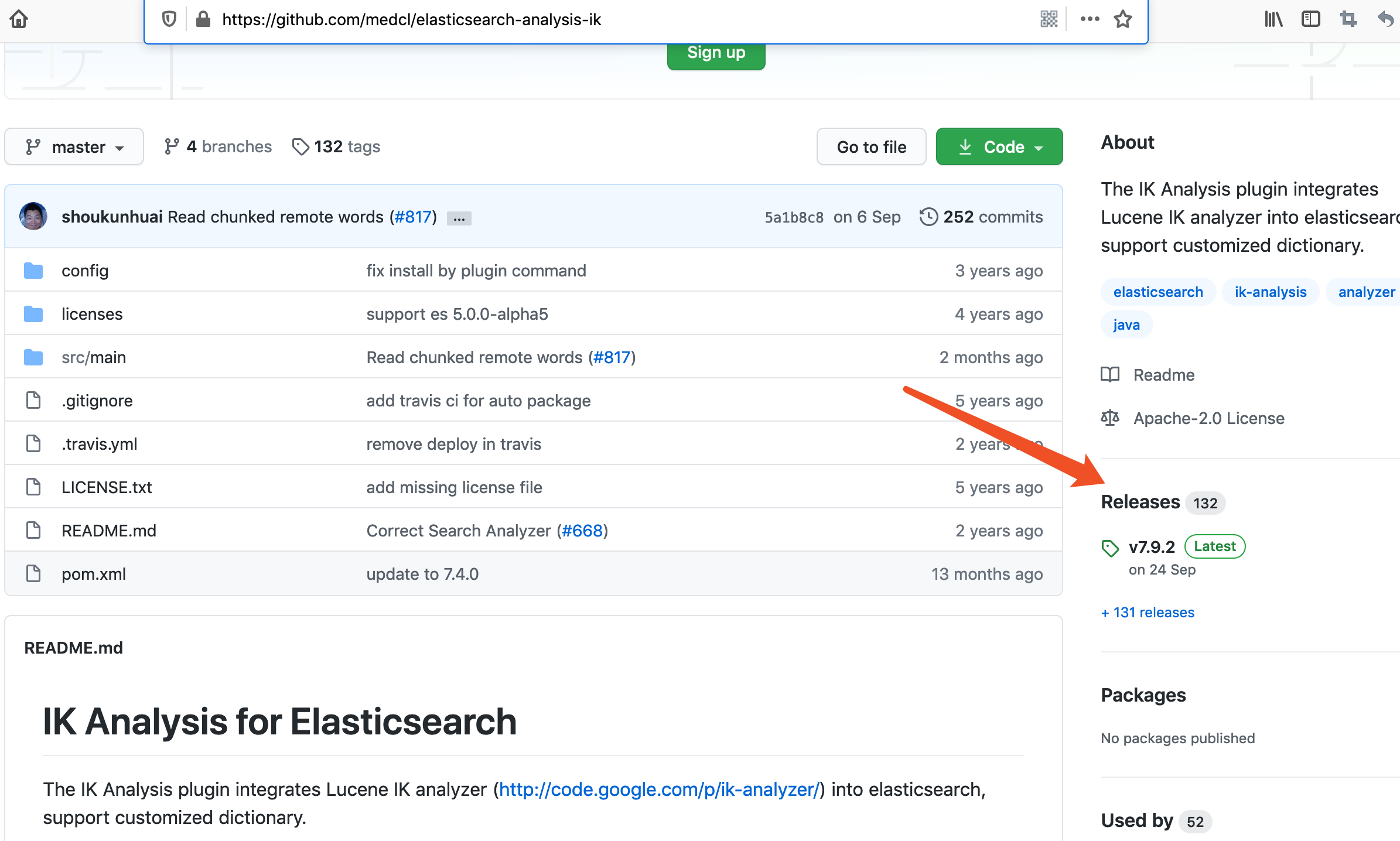
我当前本地安装的ES版本是5.2.2,所以我下载就是5.2.2这个版本
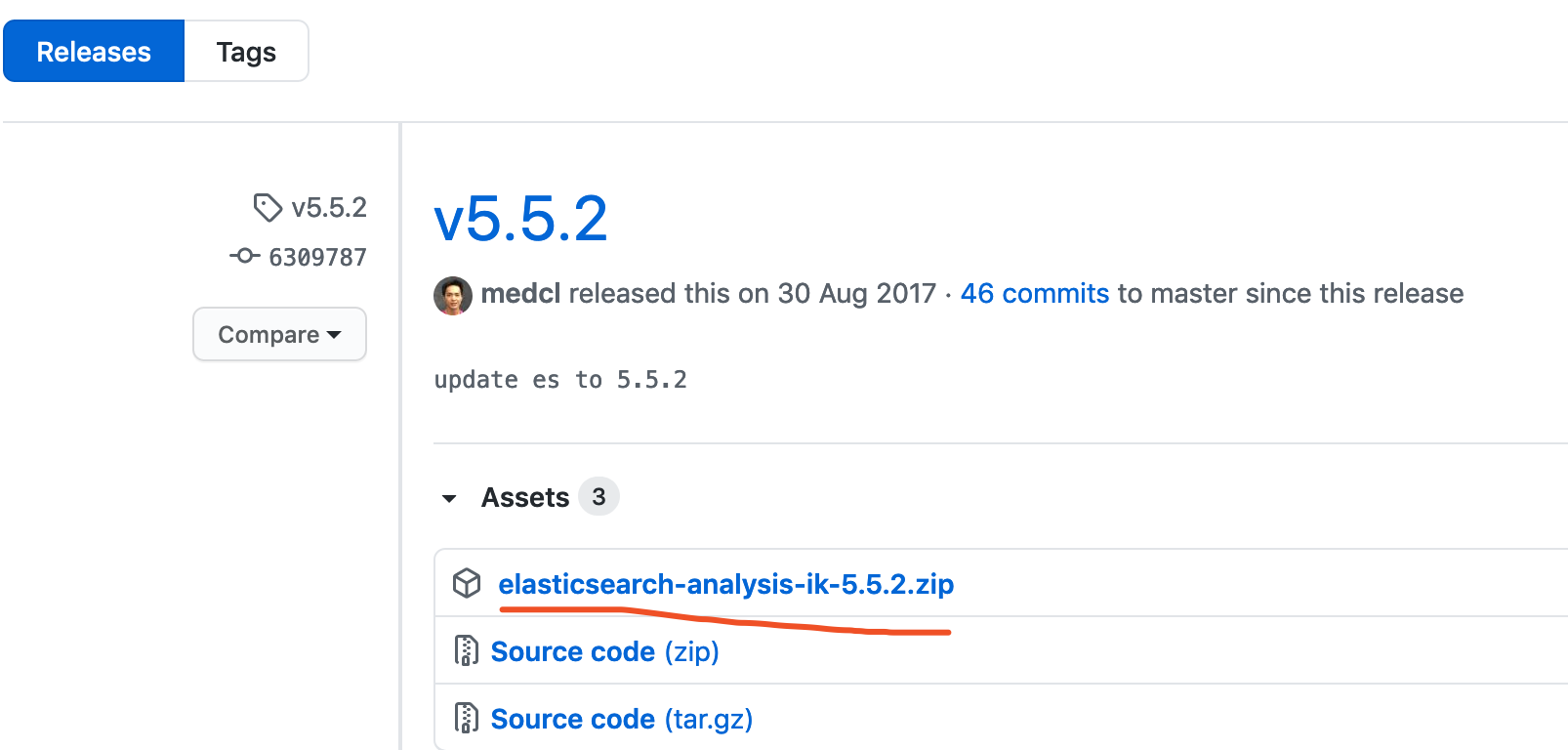
安装过程
1. 下载
wget -c https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v5.5.2/elasticsearch-analysis-ik-5.5.2.zip #使用断点续传 2. 解压unzip elasticsearch-analysis-ik-5.2.2.zip -d /usr/local/src/elasticsearch-5.5.2/plugins/ik #在ES插件目录下创建ik目录 并将ik插件解压在ik目录下 3. 查看解压后目录内容 commons-codec-1.9.jar commons-logging-1.2.jar config elasticsearch-analysis-ik-5.2.2.jar httpclient-4.5.2.jar httpcore-4.4.4.jar plugin-descriptor.properties
解压的目录如果错误会提示类似下面这种错误
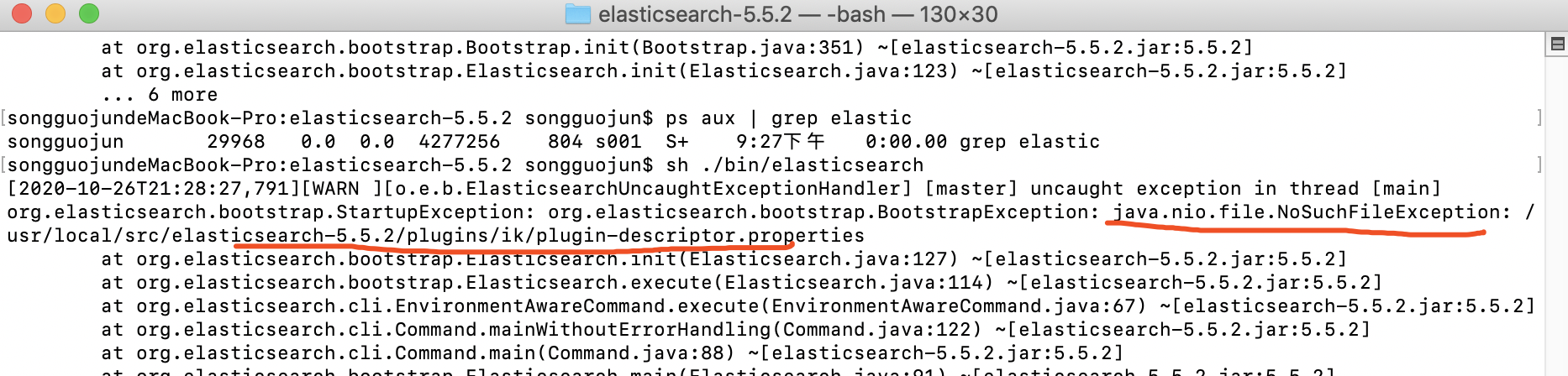
下载并解压好之后,我们需要重启ES才能使插件生效。
IKAnalyzer分词器默认提供了两种分词器,ik_syno 和 ik_syno_smart 这两个。
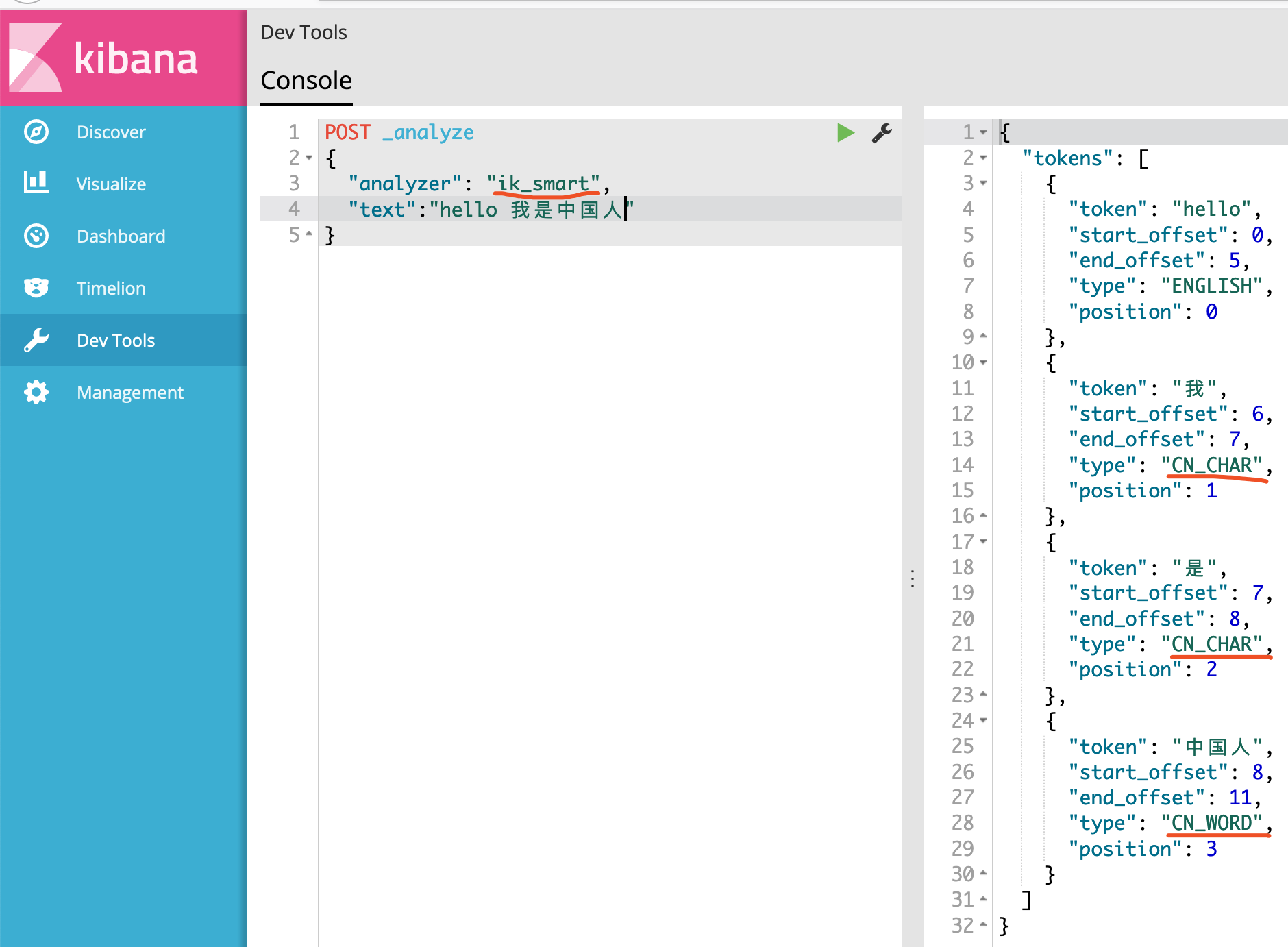
上图使用了ik_smart分词器的结果可以说明已经识别了中文。
再看看ik_max_word的分词效果。
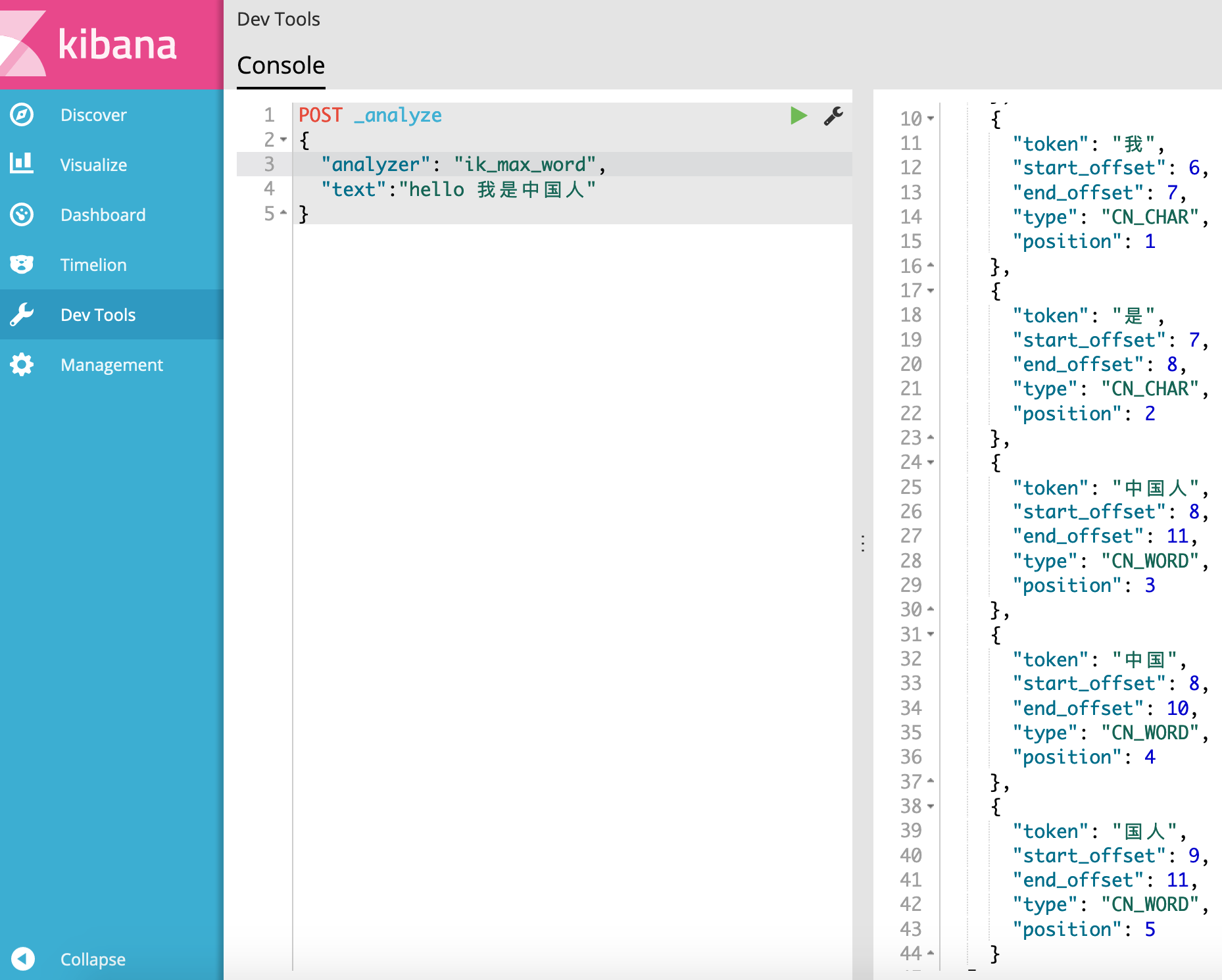
发现使用了ik_max_word分词的结果比ik_smart分词要多。
通过使用了IKAnalyzer分词器,我们发现它能够更能智能的识别中文,这是因为IKAnalyzer分词器内置了很多中文字典,提供给ES使用。这些字典位于IKAnalyzer分词器config目录中,文件后缀是dic的。
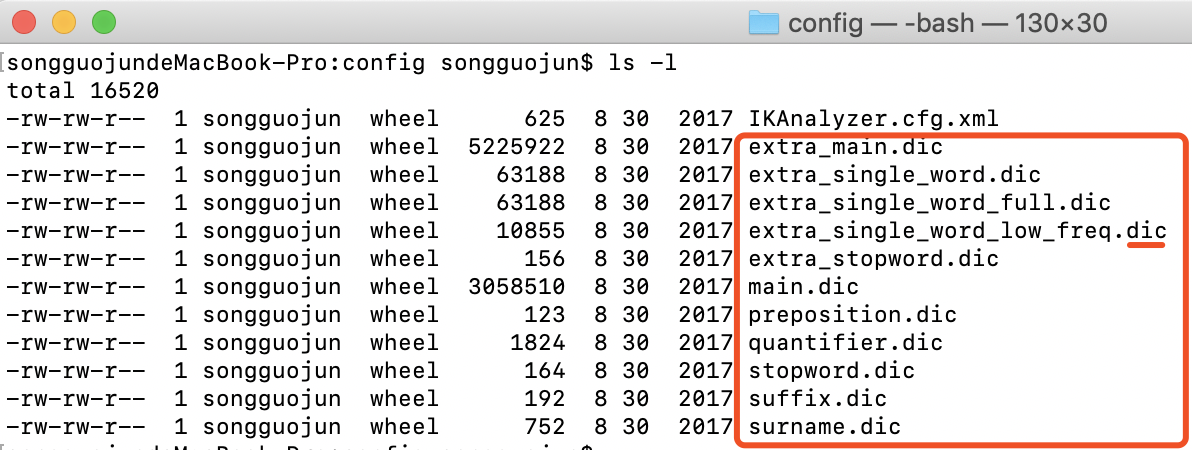
查看main.dic文件里的内容,里面的每一行文字都是分词器预先内置好的最小的词元,
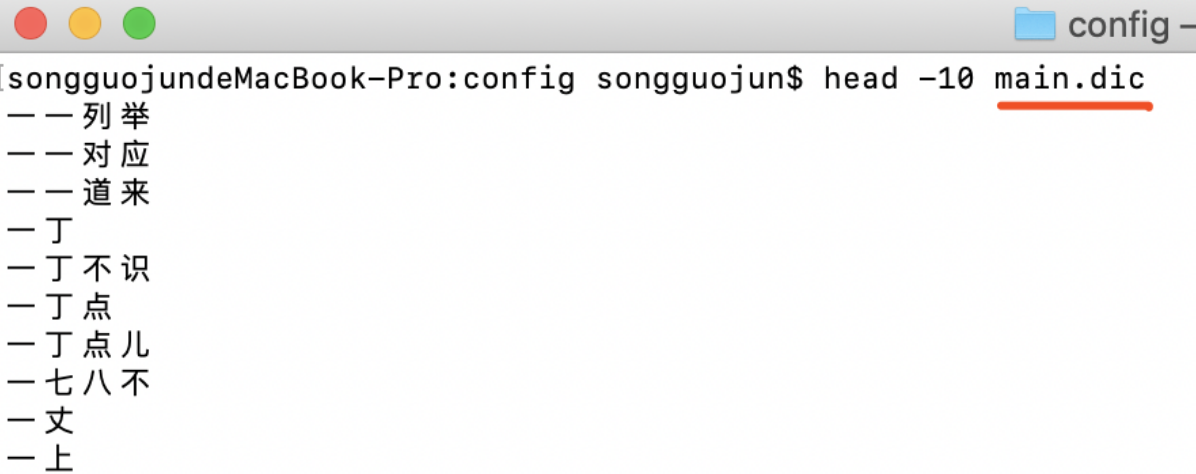
如果我们想要自定义自己的词元就可以添加在里面。

