
计算机字符与编码
ASCII码
1. 使用7个bits就可以完全表示ASCII(American Standard Code for Information Interchange)码(包含95个可打印的字符,33个不可打印的字符,比如一些控制字符), 33+95=128 = 2的7次方,最高位表示定位符。
ASCII包含了所有了所有的大小写英文字母和数字,还有键盘符号。
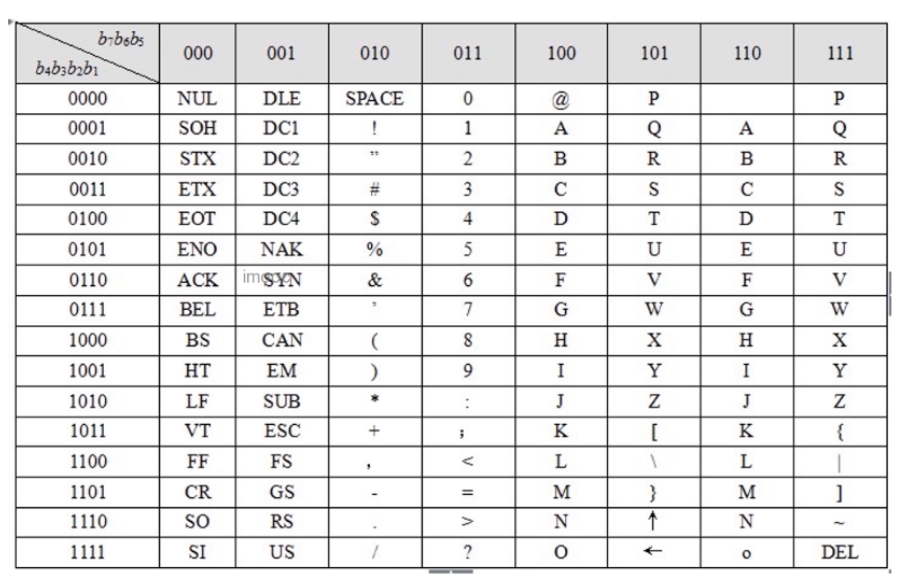
2. ASCII码很多国家的应用和符号是无法表示的,比如很多数学符号。
Extended ASCII码 (扩展ASCII码)
第一次对ASCII码扩充,7bits -> 9bits 128变成256
拓展的128多字符
字符编码集的国际化
1.欧洲,中东,东亚,拉丁美洲等国家语言的多样性。
2.语言体系不一样,并且不以有限字符组合的语言,比如英文每个单子都是由a-z组成的,但是中文除了偏旁,每个字都是独立的。而且以中国,日本,韩国风语言最为复杂。
中文编码集
GB2312(国标2312): 1980年发明出来的,全称是《信息交换用汉字编码字符集-基本集》,简称国标2312。一共收录了7445个字符。包括了6763个汉字和682个其他符号。
不过GB2312也是有问题的,不符合国际标准,后来又推出了GBK《汉字内码扩展规范》,GBK向下兼容GB2312,向上支持国际ISO标准。收录了21003个汉字,支持全部中日韩字符。
GB 2312-1980
又简称为GB 2312或GB 2312-80,由中国国家标准总局1980年发布,当年5月1日开始实施的一套国家标准。GB为国标(国家标准)拼音首字母。GB 2312将ASCII里本来就有的数字、标点、字母都统统重新编了两个字节长的编码,这就是常说的”全角”字符,而原来在127号以下的那些就叫”半角”字符。GB2312编码适用于汉字处理、汉字通信等系统之间的信息交换,通行于中国大陆;新加坡等地也采用此编码。
GBK
GBK中英文都用两个字节来表示,兼容GB2312,加入对繁体字的支持。K为扩展的Kuo首字母。windows用CP936来实现对GBK字符集的编解码。因此有些地方charset=windows-936就是指GBK。
BIG5
与GB2312有冲突。繁体字符集。Big->大写。BIG5是使用繁体中文(正体中文)社区中最常用的电脑汉字字符集标准,共收录13,060个汉字。BIG5虽普及于台湾、香港与澳门等繁体中文通行区,但长期以来并非当地的国家标准,而只是业界标准。
UTF-8
UTF-8(Universal Transformation Format)使用可变长的编码,例如 ASCII 部分仍然使用一个字节,中文用两个字节。也因为如此,它没有实现所有的 Unicode 的字符,它只实现了Unicode的Plane 0(Unicode共有16个Plane。Plane 0又称为BMP,Basic Multilingual Plane)。
UTF-8的最小编码单位为一个字节。一个字节的前1-3个bit为描述性部分,后面为实际序号部分。其编码规则如下:
- 如果字节以0开头,则代表当前字符为单字节字符。
- 如果字节以110开头,则代表当前字符为双字节字符。其第二个字节以10开头。
- 如果字节以1110开头,则代表当前字符为三字节字符。其第二、第三个字节以10开头。
- 如果字节以10开头,则代表当前字节为多字节字符(即上面那两点)的第二或第三个字节。
UTF-8编码字符理论上可以最多到6个字节长
UTF-8与中文:
- GB13000.1-1993 的字符集包含 20902 个汉字。Unicode 标准目前在基本平面上与 GB 13000 保持一致。采纳 UTF-16 方案作为未来实现 01H 到 0FH 共15个辅助平面的方式。其它方面与 GB 13000 基本一致。
- UTF-8 与 GBK 的互相转换是通过查表来实现的。UTF-8 只是 Unicode 的一种实现,当它要转码时,要转换成 Unicode 码,查 Unicode 表。
关于查表,我去看了 Unicode 表,只有该字符集编码和对应的中文,并没有其他编码的码值。只有这样可是没办法转换的啊,因为计算机只能识别0和1。
于是我推测了一下:编码字符集存储在数据库。在数据库中,一个字符同时存储了几种编码方式所对应的码。在从 编码A 转换为 编码B 的时候,先在数据库中根据 编码A 寻找对应的字符,接着读取其在 B 中的编码。
UTF-8 的缺陷是无法表示 Plane 0 外的字符。而UTF-16可以应对这种情况。
Unicode
GB2312在中国使用是没问题的,但是如果跨国就有问题,比如中国人开发一个中文网站,外国人去访问,如果他们电脑没安装GBK编码或者GB2312,在他们电脑上显示会变成乱码。
所以这里就有了兼容全球的字符集Unicode。
Unicode:统一码,万国码,单一码。
Unicode定义了世界通用的符号集,它规定了符号的二进制代码,用UTF-*实现了编码,比如UTF-8,常见的UTF-8以字节为单位对Unicode进行编码。中国Windows系统默认使用GBK,但是编程推荐使用UTF-8。

