hive2.3 任务因一个map导致进程oom挂掉的排查
sql 部分如下
select '20200607' as log_date, COUNT(distinct if(event_id='app.onepass-login.0.0.pv' AND (get_json_object(extended_fields,'$.refer_click') in ('main.homepage.avatar-nologin.all.click')) ,buvid,null)) as aaa, xxxx
xxxx FROM xxx.hongcan_onepass_appctr_d WHERE log_date='20200607' and (app_id=1 AND platform=1) GROUP BY log_date
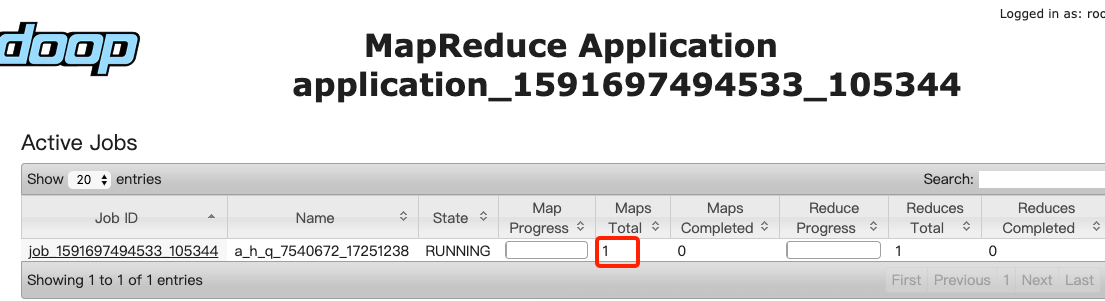
查询表分区的大小为167m ,hdfs块大小128m。
然而任务运行起来只有一个map,运行失败,看下日志很明显的内存溢出。

为了排查,只能看hive源码了
运行任务部分日志如下
Query ID = hdfs_20200610165438_c314dfd5-c046-46c5-9a25-0a467be937a6 Total jobs = 1 Launching Job 1 out of 1 Number of reduce tasks not specified. Estimated from input data size: 1 In order to change the average load for a reducer (in bytes): set hive.exec.reducers.bytes.per.reducer=<number> In order to limit the maximum number of reducers: set hive.exec.reducers.max=<number> In order to set a constant number of reducers: set mapreduce.job.reduces=<number> 20/06/10 16:56:02 INFO Configuration.deprecation: mapred.submit.replication is deprecated. Instead, use mapreduce.client.submit.file.replication 20/06/10 16:56:14 WARN mapreduce.JobResourceUploader: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this. 20/06/10 16:56:33 INFO input.FileInputFormat: Total input files to process : 1 20/06/10 16:56:41 INFO lzo.GPLNativeCodeLoader: Loaded native gpl library from the embedded binaries 20/06/10 16:56:41 INFO lzo.LzoCodec: Successfully loaded & initialized native-lzo library [hadoop-lzo rev Unknown build revisionscripts/get_build_revision.sh: 21: scripts/get_build_revision.sh: [[: not found ] ERROR: transport error 202: recv error: Connection timed out 20/06/10 17:24:22 INFO input.CombineFileInputFormat: DEBUG: Terminated node allocation with : CompletedNodes: 2, size left: 0 20/06/10 17:24:23 INFO mapreduce.JobSubmitter: number of splits:1 20/06/10 17:24:23 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1591697494533_103857 20/06/10 17:24:24 INFO impl.YarnClientImpl: Submitted application application_1591697494533_103857 20/06/10 17:24:24 INFO mapreduce.Job: The url to track the job: http://xxx:8088/proxy/application_1591697494533_103857/ Starting Job = job_1591697494533_103857, Tracking URL = http://xxx:8088/proxy/application_1591697494533_103857/ Kill Command = /data/service/hadoop/bin/hadoop job -kill job_1591697494533_103857 Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1 20/06/10 17:24:32 WARN mapreduce.Counters: Group org.apache.hadoop.mapred.Task$Counter is deprecated. Use org.apache.hadoop.mapreduce.TaskCounter instead 2020-06-10 17:24:32,431 Stage-1 map = 0%, reduce = 0%
JobSubmitter 类
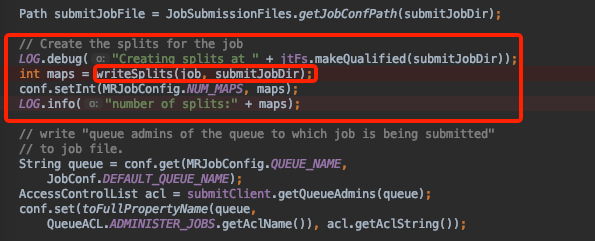
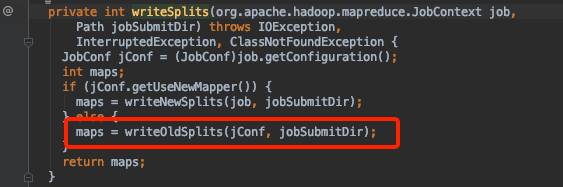
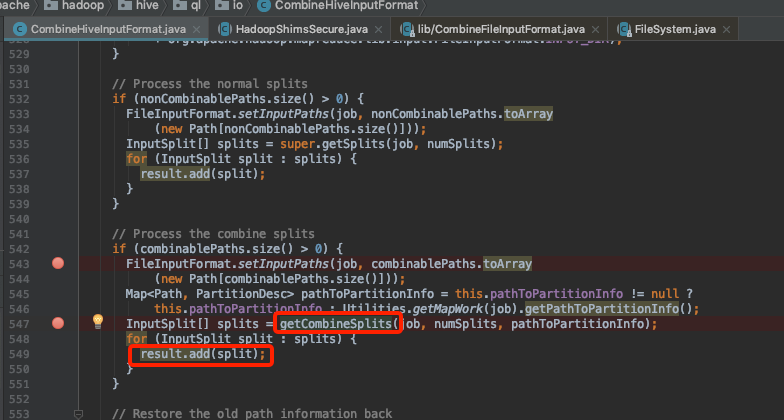
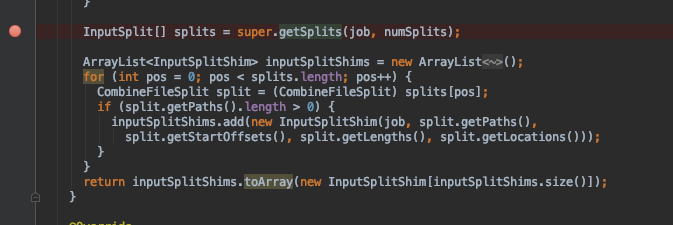
返回的inputSplitShims Array大小就是map个数
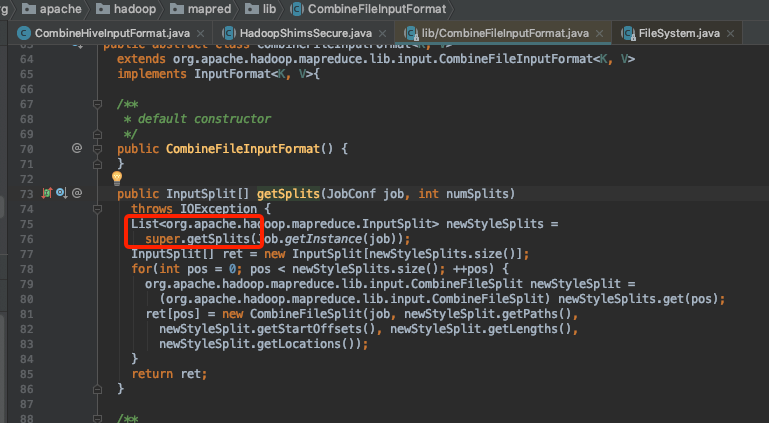
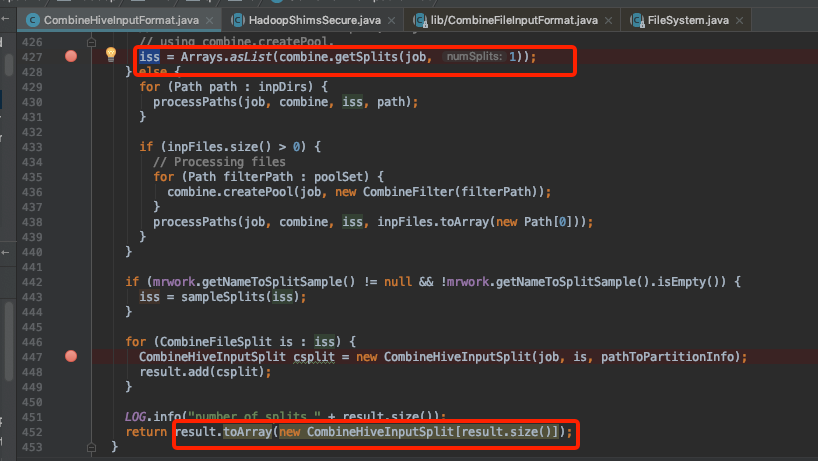
注意观察maxSize怎么来的
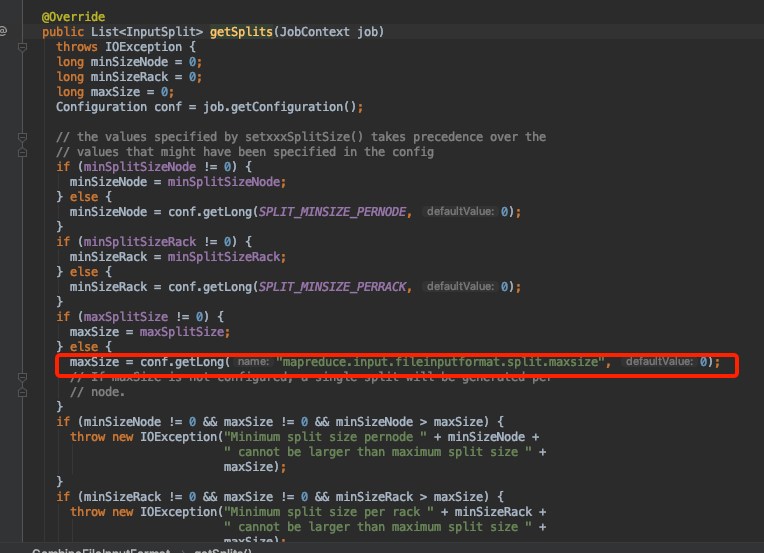
传递maxSize
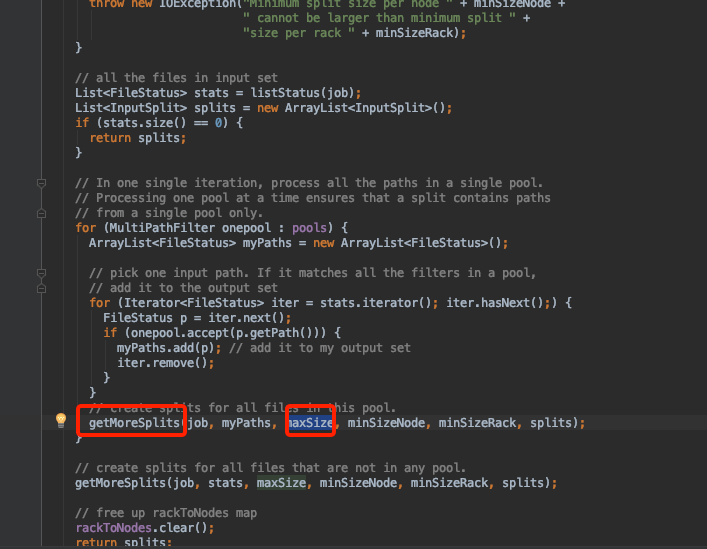
这里的blockToNodes就是切分后文件块的集合
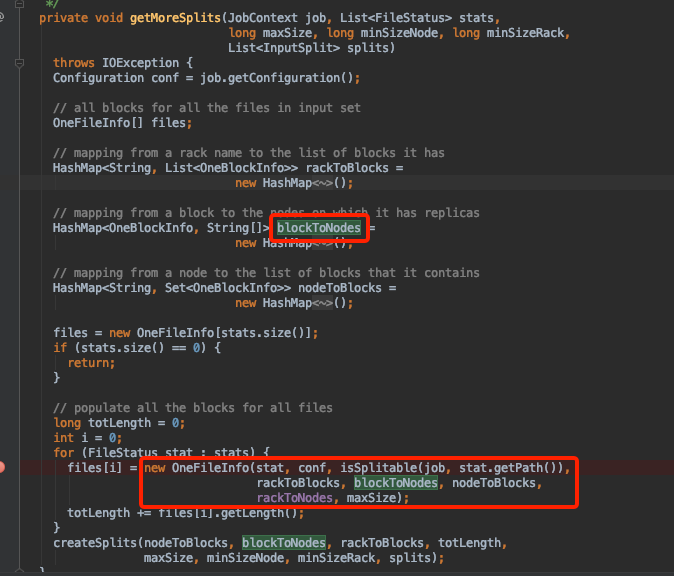
重点来了
这里的maxSize 就是mapreduce.input.fileinputformat.split.maxsize设置的大小,表示单个map最大size。文件超过就被切分。
源码中有一段介绍 hadoop2.x 使用mapreduce.input.fileinputformat.split.maxsize 控制切分文件的数量
/** * The desired number of input splits produced for each partition. When the * input files are large and few, we want to split them into many splits, * so as to increase the parallelizm of loading the splits. Try also two * other parameters, mapred.min.split.size and mapred.max.split.size for * hadoop 1.x, or mapreduce.input.fileinputformat.split.minsize and * mapreduce.input.fileinputformat.split.maxsize in hadoop 2.x to * control the number of input splits. */
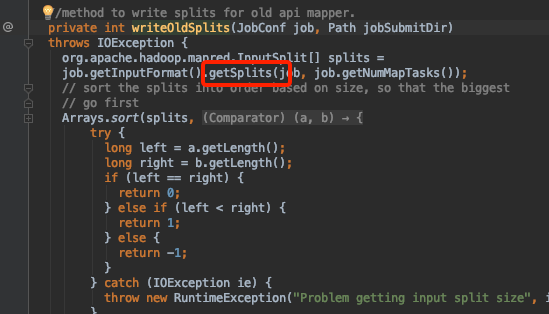
left 为文件的size,这里是167m
原因也明了了,我们的配置该参数为256m ,文件大小167m。myLength = Math.min(maxSize, left);
直接一撸到底,一个块返回。
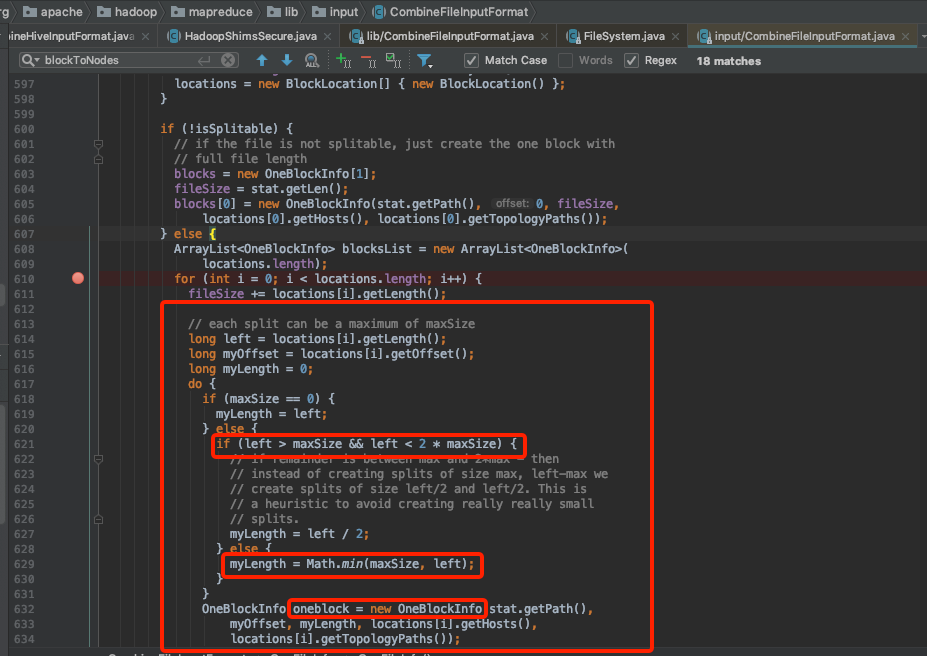
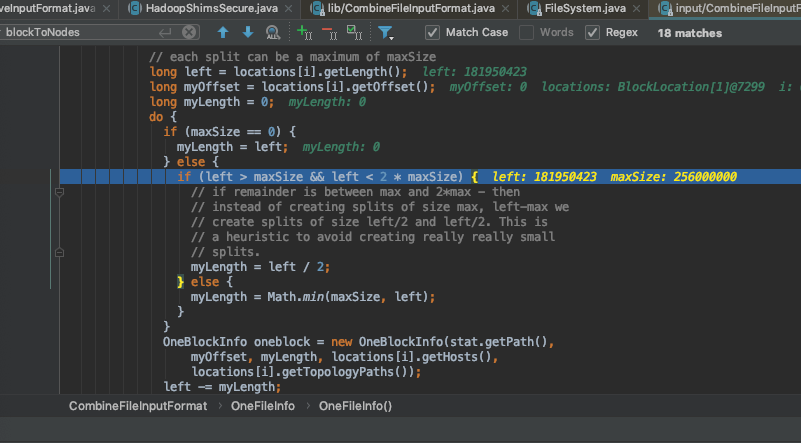

本次帮用户修改mapreduce.input.fileinputformat.split.maxsize=100000,将map提升为多个解决了问题

 浙公网安备 33010602011771号
浙公网安备 33010602011771号