spark 执行报错 java.io.EOFException: Premature EOF from inputStream
使用spark2.4跟spark2.3 做替代公司现有的hive选项。
跑个别任务spark有以下错误
java.io.EOFException: Premature EOF from inputStream at com.hadoop.compression.lzo.LzopInputStream.readFully(LzopInputStream.java:74) at com.hadoop.compression.lzo.LzopInputStream.readHeader(LzopInputStream.java:115) at com.hadoop.compression.lzo.LzopInputStream.<init>(LzopInputStream.java:54) at com.hadoop.compression.lzo.LzopCodec.createInputStream(LzopCodec.java:112) at org.apache.hadoop.mapred.LineRecordReader.<init>(LineRecordReader.java:129) at org.apache.hadoop.mapred.TextInputFormat.getRecordReader(TextInputFormat.java:67) at org.apache.spark.rdd.HadoopRDD$$anon$1.liftedTree1$1(HadoopRDD.scala:269) at org.apache.spark.rdd.HadoopRDD$$anon$1.<init>(HadoopRDD.scala:268) at org.apache.spark.rdd.HadoopRDD.compute(HadoopRDD.scala:226) at org.apache.spark.rdd.HadoopRDD.compute(HadoopRDD.scala:97) at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:330) at org.apache.spark.rdd.RDD.iterator(RDD.scala:294) at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52) at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:330) at org.apache.spark.rdd.RDD.iterator(RDD.scala:294) at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52) at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:330) at org.apache.spark.rdd.RDD.iterator(RDD.scala:294) at org.apache.spark.rdd.UnionRDD.compute(UnionRDD.scala:105) at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:330) at org.apache.spark.rdd.RDD.iterator(RDD.scala:294) at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52) at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:330) at org.apache.spark.rdd.RDD.iterator(RDD.scala:294) at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52) at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:330) at org.apache.spark.rdd.RDD.iterator(RDD.scala:294) at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52) at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:330) at org.apache.spark.rdd.RDD.iterator(RDD.scala:294) at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:99) at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:55) at org.apache.spark.scheduler.Task.run(Task.scala:123) at org.apache.spark.executor.Executor$TaskRunner$$anonfun$10.apply(Executor.scala:408) at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1360) at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:414) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748)
排查原因 发现是读取0 size 大小的文件时出错
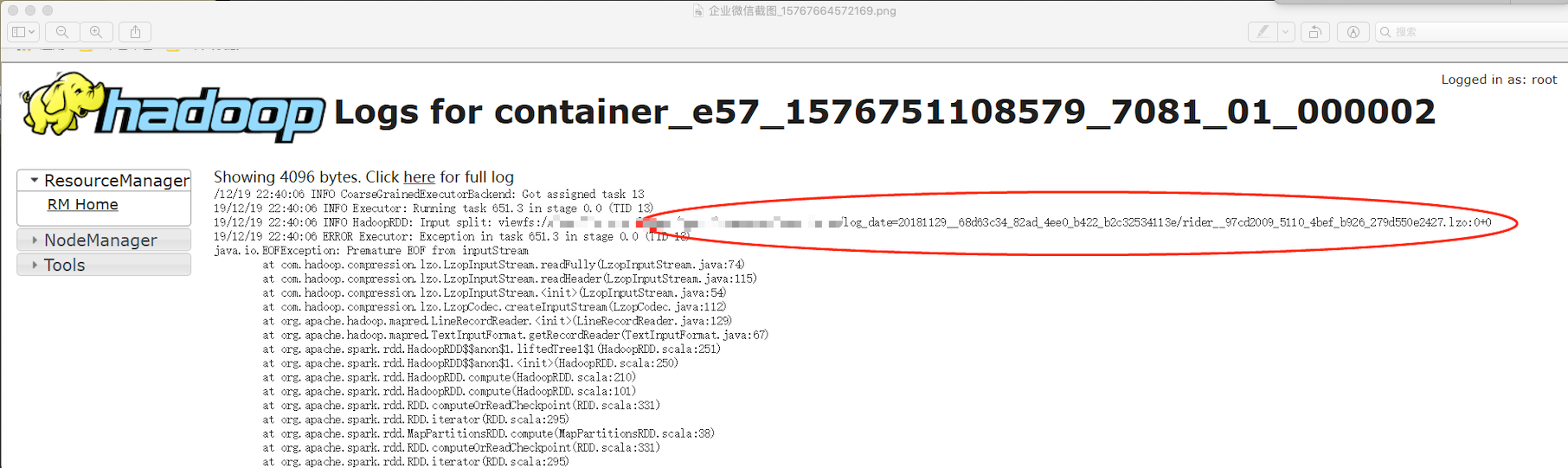
并没有发现spark官方有修复该bug
手动修改代码 过滤掉这种文件
在 HadoopRDD.scala 类相应位置修改如图即可
// We get our input bytes from thread-local Hadoop FileSystem statistics. // If we do a coalesce, however, we are likely to compute multiple partitions in the same // task and in the same thread, in which case we need to avoid override values written by // previous partitions (SPARK-13071). private def updateBytesRead(): Unit = { getBytesReadCallback.foreach { getBytesRead => inputMetrics.setBytesRead(existingBytesRead + getBytesRead()) } } private var reader: RecordReader[K, V] = null private val inputFormat = getInputFormat(jobConf) HadoopRDD.addLocalConfiguration( new SimpleDateFormat("yyyyMMddHHmmss", Locale.US).format(createTime), context.stageId, theSplit.index, context.attemptNumber, jobConf) reader = try { if (split.inputSplit.value.getLength != 0) { //文件大小不为零 采取读取 inputFormat.getRecordReader(split.inputSplit.value, jobConf, Reporter.NULL) } else { logWarning(s"Skipped the file size 0 file: ${split.inputSplit}") finished = true //大小为0 即结束 跳过 null } } catch { case e: FileNotFoundException if ignoreMissingFiles => logWarning(s"Skipped missing file: ${split.inputSplit}", e) finished = true null // Throw FileNotFoundException even if `ignoreCorruptFiles` is true case e: FileNotFoundException if !ignoreMissingFiles => throw e case e: IOException if ignoreCorruptFiles => logWarning(s"Skipped the rest content in the corrupted file: ${split.inputSplit}", e) finished = true null } // Register an on-task-completion callback to close the input stream. context.addTaskCompletionListener[Unit] { context => // Update the bytes read before closing is to make sure lingering bytesRead statistics in // this thread get correctly added. updateBytesRead() closeIfNeeded() }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号