记一次CNN模型训练遇到的问题(初训练)
- csv文件读写
读:
filename = "D:\\桌面文件\\大三上\\大三下\\人工智能\\练习赛数据\\test_data.csv" df = pd.read_csv(filename) print(df.info())#简要摘要 information print(df.head())#输出数据前n行,默认为5 print(df.shape[0])
写:(注意这个方式是一行一行写入,newline=''是为了消除csv文件里的空行)
import csv #调用数据保存文件 import pandas as pd #用于数据输出 with open("D:\\桌面文件\\大三上\\大三下\\人工智能\\练习赛数据\\ans.csv","w",newline='') as csvfile: writer = csv.writer(csvfile) writer.writerow(["id","label"]) t=1 for i in Ans: writer.writerow([t,int(i)]) t+=1
- 关于这个tensor转numpy的格式
y.cpu().numpy() ---> y.cpu().detach().numpy()
- 创建一个空的numpy,取每一行最大的数的下标以及往numpy里添加新的元素
Ans = np.empty(0) ans = np.argmax(ans,axis=1) Ans = np.append(Ans,ans)
- 一个是训练模式,一个是预测模式
net.train()
net.eval()
- RuntimeError: Expected object of scalar type Long but got scalar type Float for argument #2 'target'
遇到上面类似的错误的解决方法:
loss = criterion(outputs, labels.long())#损失函数
就在labels后面加上.long(),多次报这个错误后发现,它说是什么类型,直接在label后面加上对应的类型即可。
- Input type (torch.cuda.DoubleTensor) and weight type (torch.cuda.FloatTensor) should be the same
出现上面的错误的时候需要把输入数据的数据类型改一下,模型的数据类型应该不是很好改。
df = df.astype(np.float32)
一般模型为float的数据类型,所以输入的数据类型也要改成float即可。
- 关于tensor的维度转换
l = inputs.shape[0]
inputs = inputs.view(l,1,80,75)
其实还有很多错误,没有写上来,随手便改了,没有记录。
- OMP: Error #15: Initializing libiomp5md.dll, but found libiomp5md.dll already initialized.
import os os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
添加上面两句话即可
- 随机从一段数里选择一部分数
a=np.arange(0,792) #8:2 b=np.random.choice(a,634,replace=False)#训练集下标 c=np.delete(a,b)#验证集下标
- Pytorch中优化器的比较和选择
- 关于模型参数的保存和导入
torch.save(net, 'MNIST.pkl') net = torch.load('MNIST.pkl')
- dropout调优参数,以及所处的位置
调优参数一般是0.0 p=0.3 p=0.5 有的介绍说p=0.5泛化能力最好,dropout缺点就是训练时间过长
Dropout一般放在全连接层防止过拟合,提高模型返回能力,由于卷积层参数较少,很少有放在卷积层后面的情况,卷积层一般使用batch norm。
深度学习的loss能否作为衡量模型性能的指标?
结论是:几乎不能!
对于分类问题来说是有一定相关性但几乎不能。
对于一个分类模型来说更关心的是accuracy等指标(还有哪些能够衡量呢?),但是loss并不能直接代表这些指标
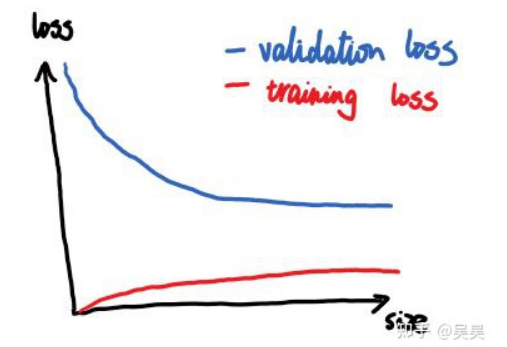
模型泛化能力差,过拟合
Solution:对模型做正则化,使用dropout技巧or扩大训练集

欠拟合
Solution:增大模型规模(加深网络层数)甚至换一个更大的模型是有效的优化策略
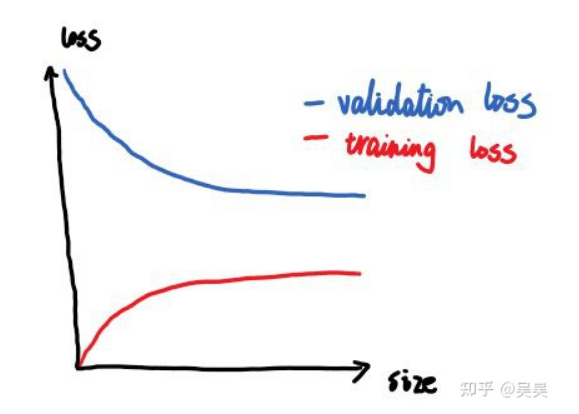
模型垃圾,泛化能力差
直接换一个网络
- ResNet网络遇到的问题
- pytorch如何修改ResNet等网络的输入通道数?
如果不修改的话输入层和输入的数据不匹配就会报错
net = torchvision.models.resnet18(pretrained=False) print(net.conv1) net.conv1 = nn.Conv2d(1, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
打印网络通道数查看状况,然后直接调用这个Conv2d函数修改网络第一层即可
- ResNet如果调用Pytorch自带的而不是自己创建的话需要修改输出线性层的个数
resnet18 = models.resnet18() # 修改全连接层的输出 num_ftrs = resnet18.fc.in_features resnet18.fc = nn.Linear(num_ftrs, 2)
- 突然发现pytorch自带许多经典网络,几乎都不需要自己去搭建
在torchvision.model中,有很多封装好的模型。
可以分为三类


- add_module 添加新的层
# 在最后一层添加线性层,使输出的分类类别是10 net.add_module("add_linear", nn.Linear(1000, 10)) # 在classifier最后一层加线性层 net.classifier.add_module("add_linear", nn.Linear(1000, 10)) # 在avgpool后面添加一层BN层 net.avgpool.add_module("add_BN",nn.BatchNorm2d((25088)))
add_moudle里面有两个参数,第一个参数是改层的命名,没有什么限制,其次是添加的层是什么
- python里的nan和inf的含义以及解决方法
nan(Not a number)通常是无理数,无法表示的数,而inf是超过浮点表示范围的浮点数(其本质仍是浮点数,但是无穷大)
出现的原因:如果迭代在100轮以内,出现nan,一般情况下是因为你的学习率过高,降低学习率需要;一般来说低于现有学习率1-10倍即可。
出现的根本原因:nan的出现一般是inf-inf,从而得到nan,需要数据归一化,这很重要,梯度爆炸使得学习过程难以继续。loss随着每轮的迭代越来越大,最终超过了浮点数表示范围,就变成了nan。
- python数据类型转换
1 单个数据numpy转int,首先numpy.int64和int是完全不一样的!
import numpy as np #定义一个int变量 a=123 print(type(a)) #<class 'int'> #强制类型转换为np.int64 b=np.int64(a) print(type(b)) #<class 'numpy.int64'> #再强制转化成int c=int(b) print(type(c)) #<class 'int'>
强制转换即可
2 多个数据,一个序列数据类型转换 np.astype
arr = arr.astype("float32")
- python查看数据类型
a=np.array([[1.0,2.0,3.0],[4.0,5.0,6.0]]) print(type(a)) print(isinstance(a,float)) a=a.astype(int) print(type(a)) print(isinstance(a,int))
输出是
<class 'numpy.ndarray'> False <class 'numpy.ndarray'> False
- python数组切割操作
hsplit():沿横轴(纵向)拆分原array。可以实现均匀切割或者指定位置切割。(水平切割)
vsplit():沿垂直轴切割原array。同上。(垂直切割)
split():通过参数axis=1或者axis=0(默认axis=0)可以实现水平切割或者垂直切割。split必须要均等分.
array_split():通过参数axis=1或者axis=0可以实现水平切割或者垂直切割。array_split()强制切割,指定切割后的数目实现近似均匀切割。
注意:np.array_split 和np.split(),这两个函数的唯一区别是 split() 必须是等分,否则会抛出异常:ValueError: array split does not result in an equal division。
- K折交叉验证
它指的是将原始数据随机分成K份,每次选择K-1份作为训练集,剩余的1份作为测试集。交叉验证重复K次,取K次准确率的平均值作为最终模型的评价指标。一般取K=10,即10折交叉验证,如下图所示:
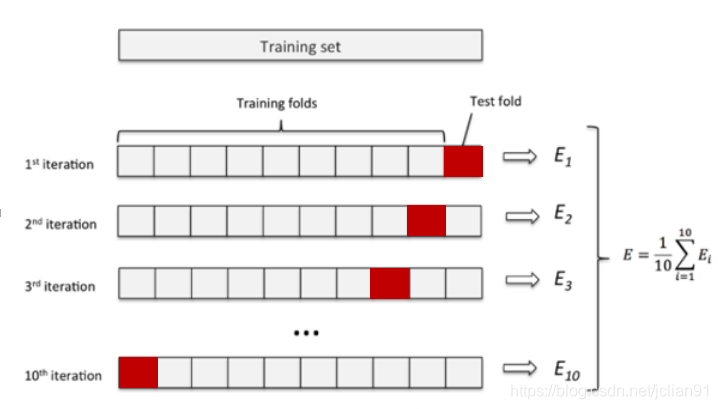
用交叉验证的目的是为了得到可靠稳定的模型。K折交叉验证能够有效提高模型的学习能力,类似于增加了训练样本数量,使得学习的模型更加稳健,鲁棒性更强。选择合适的K值能够有效避免过拟合。
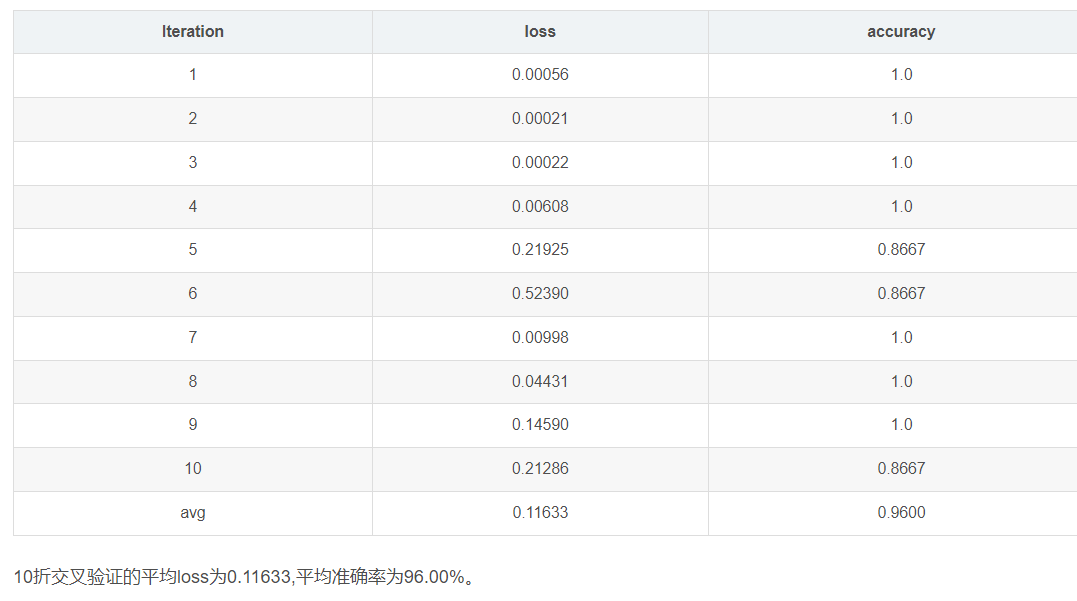
把10次平均值作为模型泛化能力的评判标准
完结撒花!!!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号