flink计算引擎
1.1 初识Flink
1) Flink项目的理念是:“Apache Flink是为分布式、高性能、随时可用以及准确的流处理应用程序打造的开源流处理框架”。
2) Apache Flink是一个框架和分布式处理引擎,用于对无界(nc lk 9999)和有界数据(一个文档)流进行有状态计算。Flink被设计在所有常见的集群环境中运行,以内存执行速度和任意规模来执行计算。
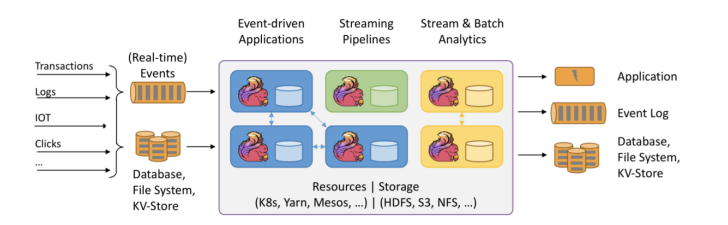

1.2 Flink的重要特点
1.2.1 事件驱动型(Event-driven)
1) 事件驱动型应用是一类具有状态的应用,它从一个或多个事件流提取数据,并根据到来的事件触发计算、状态更新或其他外部动作。比较典型的就是以kafka为代表的消息队列几乎都是事件驱动型应用。(Flink的计算也是事件驱动型)
2) sparkstreaming是时间驱动:批次的时间
1.2.2 流(flink)与批(spark)的世界观
1) 批处理的特点是有界、大量,非常适合需要访问全套记录才能完成的计算工作,一般用于离线统计。 流处理的特点是无界、实时, 无需针对整个数据集执行操作,而是对通过系统传输的每个数据项执行操作,一般用于实时统计。
2) 在spark的世界观中,一切都是由批次组成的,离线数据是一个大批次,而实时数据是由一个一个无限的小批次组成的。
3) 而在flink的世界观中,==一切都是由流组成的,离线数据是有界限的流==,实时数据是一个没有界限的流,这就是所谓的有界流和无界流。
4) 无界数据流:
无界数据流有一个开始但是没有结束,它们不会在生成时终止并提供数据,必须连续处理无界流,也就是说必须在获取后立即处理event。对于无界数据流我们无法等待所有数据都到达,因为输入是无界的,并且在任何时间点都不会完成。处理无界数据通常要求以特定顺序(例如事件发生的顺序)获取event,以便能够推断结果完整性
5) 有界数据流:
有界数据流有明确定义的开始和结束,可以在执行任何计算之前通过获取所有数据来处理有界流,处理有界流不需要有序获取,因为可以始终对有界数据集进行排序,有界流的处理也称为批处理。
1.2.3 分层API
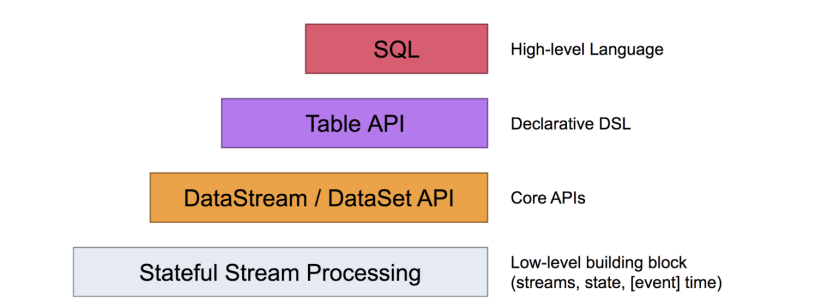
Croe APIs--> spark core Table API --> sql --> spark sql
1) 最底层级的抽象仅仅提供了有状态流,它将通过过程函数(Process Function)被嵌入到DataStream API中。底层过程函数(Process Function) 与 DataStream API 相集成,使其可以对某些特定的操作进行底层的抽象,它允许用户可以自由地处理来自一个或多个数据流的事件,并使用一致的容错的状态。除此之外,用户可以注册事件时间并处理时间回调,从而使程序可以处理复杂的计算。
2) 实际上,大多数应用并不需要上述的底层抽象,而是针对核心API(Core APIs) 进行编程,比如DataStream API(有界或无界流数据)以及DataSet API(有界数据集)。这些API为数据处理提供了通用的构建模块,比如由用户定义的多种形式的转换(transformations),连接(joins),聚合(aggregations),窗口操作(windows)等等。DataSet API 为有界数据集提供了额外的支持,例如循环与迭代。这些API处理的数据类型以类(classes)的形式由各自的编程语言所表示。
3) Table API 是以表为中心的声明式编程,其中表可能会动态变化(在表达流数据时)。Table API遵循(扩展的)关系模型:表有二维数据结构(schema)(类似于关系数据库中的表),同时API提供可比较的操作,例如select、project、join、group-by、aggregate等。Table API程序声明式地定义了什么逻辑操作应该执行,而不是准确地确定这些操作代码的看上去如何。
4) 尽管Table API可以通过多种类型的用户自定义函数(UDF)进行扩展,其仍不如核心API更具表达能力,但是使用起来却更加简洁(代码量更少)。除此之外,Table API程序在执行之前会经过内置优化器进行优化。
你可以在表与 DataStream/DataSet 之间无缝切换,以允许程序将 Table API 与 DataStream 以及 DataSet 混合使用。
5) Flink提供的最高层级的抽象是 SQL 。这一层抽象在语法与表达能力上与 Table API 类似,但是是以SQL查询表达式的形式表现程序。SQL抽象与Table API交互密切,同时SQL查询可以直接在Table API定义的表上执行。
6) 目前Flink作为批处理还不是主流,不如Spark成熟,所以DataSet使用的并不是很多。Flink Table API和Flink SQL也并不完善,大多都由各大厂商自己定制。==所以我们主要学习DataStream API的使用==。实际上Flink作为最接近Google DataFlow模型的实现,是流批统一的观点,所以基本上使用DataStream就可以了。
7) 2020年12月8日发布的1.12.0版本, 已经完成实现了真正的流批一体, 写好的一套代码, 即可以处理流式数据, 也可以处理离线数据. 这个与前面版本的处理有界流的方式是不一样的, Flink专门对批处理数据做了优化处理.
1.3 Spark or Flink
Spark 基于微批处理的方式需要同步会有额外开销,因此无法在延迟上做到极致。在大数据处理的低延迟场景,Flink 已经有非常大的优势。
1.4 Flink的应用
1.4.1 应用Flink的场景
1) 事件驱动型应用
事件驱动型应用是一类具有状态的应用,它从一个或多个事件流提取数据,并根据到来的事件触发计算、状态更新或其他外部动作。
事件驱动型应用是在计算存储分离的传统应用基础上进化而来。在传统架构中,应用需要读写远程事务型数据库。
相反,事件驱动型应用是基于状态化流处理来完成。在该设计中,数据和计算不会分离,应用只需访问本地(内存或磁盘)即可获取数据。系统容错性的实现依赖于定期向远程持久化存储写入 checkpoint。下图描述了传统应用和事件驱动型应用架构的区别。
2) 数据分析应用
Apache Flink 同时支持流式及批量分析应用。
Flink 为持续流式分析和批量分析都提供了良好的支持。具体而言,它内置了一个符合 ANSI 标准的 SQL 接口,将批、流查询的语义统一起来。无论是在记录事件的静态数据集上还是实时事件流上,相同 SQL 查询都会得到一致的结果。同时 Flink 还支持丰富的用户自定义函数,允许在 SQL 中执行定制化代码。如果还需进一步定制逻辑,可以利用 Flink DataStream API 和 DataSet API 进行更低层次的控制。此外,Flink 的 Gelly 库为基于批量数据集的大规模高性能图分析提供了算法和构建模块支持。
3) 数据管道应用
提取-转换-加载(ETL)是一种在存储系统之间进行数据转换和迁移的常用方法。ETL 作业通常会周期性地触发,将数据从事务型数据库拷贝到分析型数据库或数据仓库。
数据管道和 ETL 作业的用途相似,都可以转换、丰富数据,并将其从某个存储系统移动到另一个。但数据管道是以持续流模式运行,而非周期性触发。因此它支持从一个不断生成数据的源头读取记录,并将它们以低延迟移动到终点。例如:数据管道可以用来监控文件系统目录中的新文件,并将其数据写入事件日志;另一个应用可能会将事件流物化到数据库或增量构建和优化查询索引。
1.4.2 应用Flink的行业

电商和市场营销
数据报表、广告投放
物联网(IOT)
传感器实时数据采集和显示、实时报警,交通运输业
物流配送和服务业
订单状态实时更新、通知信息推送、电信业基站流量调配
银行和金融业
实时结算和通知推送,实时检测异常行为
第2章 Flink快速上手
2.1创建maven项目
1) idea.POM文件中添加需要的依赖: 课件上面有
2) src/main/resources添加文件:log4j.properties
log4j.rootLogger=error, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%-4r [%t] %-5p %c %x - %m%n
3) idea的配置 创建目录和基本设置
<!-- 1. 编码 file encoding
2. 换行符 code style
3. maven
更新快照 选中
不要托管给maven 不选
4. 创建项目的时候, 万万不要把项目存入到中文路径
5. maven仓库也不要存到中文路径-->
2.2批处理WordCount 也是有界流
public class WcBounded {
public static void main(String[] args) {
// 1. 创建流StreamExecutionEnvironment的执行环境 自动根据当前运行的环境获取合适的执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//设置通过此环境执行的操作的并行度。设置平行度
env.setParallelism(1);
// 2. 通过环境从数据源(source)获取一个流
DataStreamSource<String> source = env.readTextFile("input/words.txt");
// 3. 对流做各种转换 ,单词都是String的类型
SingleOutputStreamOperator<String> wordStream= source.flatMap(new FlatMapFunction<String, String>() {
2.3流处理WordCount 也是无界流
就是读取的方式不一样,这个是获取无限的数据过来
public class WcUnBounded {
public static void main(String[] args) {
// 1. 创建流StreamExecutionEnvironment的执行环境 自动根据当前运行的环境获取合适的执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//设置通过此环境执行的操作的并行度。设置平行度
env.setParallelism(1);
// 2. 通过环境从数据源(source)获取一个流
DataStreamSource<String> source = env.socketTextStream("hadoop162", 9999);
// 3. 对流做各种转换 ,单词都是String的类型
SingleOutputStreamOperator<String> wordStream= source.flatMap(new FlatMapFunction<String, String>() {
==2.4 拉姆达表达式和泛型擦除==
1) 例子 1 :new的接口A 实现类是匿名内部类
public class Lambda {
public static void main(String[] args) {
//实现类是匿名内部类
A a = n -> System.out.println("匿名内部类的方法" + n);
A a2 = new A() {
2) 例子 2 传的参数是接口
public class Lambda2 {
/*
java中的函数: lambda表达式(拉姆达表达式)
接口:
interface
常量
抽象方法
默认方法(default)
函数式接口:
如果一个接口中只有一个抽象方法, 这样的接口就是函数式接口,
而且要继承的父类也只有一个相同的抽象方法
如果一个类型是函数式接口类型, 则创建对象的时候可以使用lambda表示
*/
public static void main(String[] args) {
test2(new Bb() {
3) keyby可以写拉姆达表达式,其他类型写不方便
public class WcUnBoundLambda {
public static void main(String[] args) {
// 1. 创建流StreamExecutionEnvironment的执行环境 自动根据当前运行的环境获取合适的执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//设置通过此环境执行的操作的并行度。设置平行度
env.setParallelism(1);
// 2. 通过环境从数据源(source)获取一个流
DataStreamSource<String> source = env.socketTextStream("hadoop162", 9999);
// 3. 对流做各种转换 ,单词都是String的类型
SingleOutputStreamOperator<String> wordStream= source.flatMap(new FlatMapFunction<String, String>() {
第3章 Flink部署
master 在flink中叫 JobManager
worker 在flink中叫 TaskManager
3.1 开发模式
咱们前面在idea中运行Flink程序的方式就是开发模式.
3.2 local-cluster模式
Flink中的Local-cluster(本地集群)模式,主要用于测试, 学习.
3.2.1 local-cluster模式配置
local-cluster模式基本属于零配置.
1) 上传Flink的安装包flink-1.13.1-bin-scala_2.12.tgz到hadoop162
2) 解压
3) 进入目录/opt/module, 复制flink-local
cp -r flink-1.13.1 flink-local
3.2.2 在local-cluster模式下运行无界的WordCount
1) 打包idea中的应用
2) 把不带依赖的jar包上传到目录/opt/module/flink-local下
3) 启动本地集群
bin/start-cluster.sh
4) 在hadoop162中启动netcat,相当于一个服务端,无界流的数据过来
nc -lk 9999
注意: 如果没有安装netcat需要先安装:
sudo yum install -y nc
5) 命令行提交Flink应用
bin/flink run -m hadoop162:8081 -c com.atguigu.flink.java.chapter_2.Flink03_WC_UnBoundedStream
./flink-prepare-1.0-SNAPSHOT.jar
6) 在浏览器中查看应用执行情况
http://hadoop162:8081
7) 也可以在WEB UI提交应用
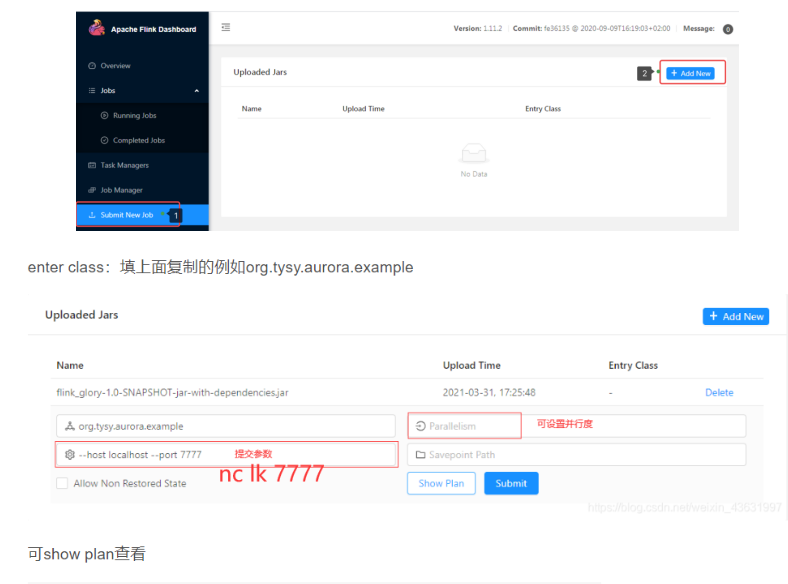
3.3 Standalone模式
Standalone模式又叫独立集群模式.
# 3.3.1 Standalone模式配置
1.复制flink-standalone
cp -r flink-1.13.1 flink-standalone
2.修改配置文件:flink-conf.yaml
jobmanager.rpc.address: hadoop162
3.修改配置文件:workers
hadoop163
hadoop164
4.分发flink-standalone到其他节点
# 3.3.2 Standalone模式运行无界流WorkCount
1.启动standalone集群 先起集群, 多个job共享这个集群
bin/start-cluster.sh
2.命令行提交Flink应用 bin/flink run -d -m hadoop162:8081 -c 主类 ...jar
bin/flink run -m hadoop162:8081 -c com.atguigu.flink.java.chapter_2.Flink03_WC_UnBoundedStream
./flink-prepare-1.0-SNAPSHOT.jar
3.查看执行情况与本地集群一致.
4.也支持Web UI界面提交Flink应用
# 3.3.3Standalone高可用(HA)
任何时候都有一个 主 JobManager 和多个备用 JobManagers,以便在主节点失败时有备用 JobManagers 来接管集群。这保证了没有单点故障,一旦备 JobManager 接管集群,作业就可以正常运行。主备 JobManager 实例之间没有明显的区别。每个 JobManager 都可以充当主备节点。
1:修改配置文件: flink-conf.yaml
high-availability: zookeeper
high-availability.storageDir: hdfs://hadoop162:8020/flink/standalone/ha
high-availability.zookeeper.quorum: hadoop162:2181,hadoop163:2181,hadoop164:2181
high-availability.zookeeper.path.root: /flink-standalone
high-availability.cluster-id: /cluster_atguigu
2:修改配置文件: masters
hadoop162:8081
hadoop163:8081
3:分发修改的后配置文件到其他节点
4:在/etc/profile.d/my.sh中配置环境变量
Flink没有依赖这个环境,所以需要配置一个路径才可以找到hadoop命令,但是spark有
export HADOOP_CLASSPATH=`hadoop classpath`
分发到其他节点
5:首先启动dfs集群和zookeeper集群
6:启动standalone HA集群
bin/start-cluster.sh
7:可以分别访问
http://hadoop162:8081
http://hadoop163:8081
8:可以在zookeeper上面看
rest_server_lock这上面就可以看到
9:杀死hadoop162上的Jobmanager, 再看leader

3.4 Yarn模式
1) 独立部署(Standalone)模式由Flink自身提供计算资源,无需其他框架提供资源,这种方式降低了和其他第三方资源框架的耦合性,独立性非常强。但是你也要记住,Flink主要是计算框架,而不是资源调度框架,所以本身提供的资源调度并不是它的强项,所以还是和其他专业的资源调度框架集成更靠谱,所以接下来我们来学习在强大的Yarn环境中Flink是如何使用的。(其实是因为在国内工作中,Yarn使用的非常多)
2) 把Flink应用提交给Yarn的ResourceManager, Yarn的ResourceManager会申请容器从Yarn的NodeManager上面. Flink会创建JobManager和TaskManager在这些容器上.Flink会根据运行在JobManger上的job的需要的slot的数量动态的分配TaskManager资源
3.4.1 Yarn模式配置
1 复制flink-yarn
cp -r flink-1.13.6 flink-yarn
2 配置环境变量HADOOP_CLASSPATH, 如果前面已经配置可以忽略.
在/etc/profile.d/my.sh中配置
export HADOOP_CLASSPATH=`hadoop classpath`
Flink没有依赖这个环境,所以需要配置一个路径才可以找到hadoop命令,但是spark有
3.4.2 Flink on Yarn的3种部署模式
1: Session-Cluster模式执行无界流WordCount
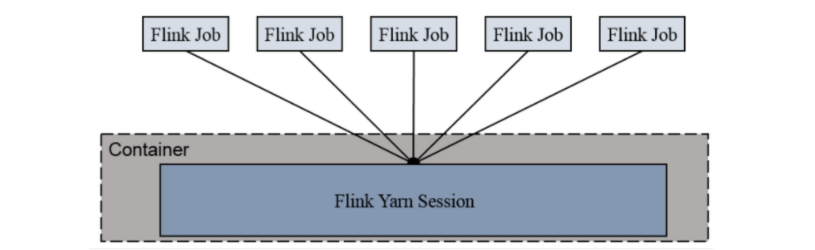
1: Session-Cluster模式需要先启动Flink集群,向Yarn申请资源。以后提交任务都向这里提交。这个Flink集群会常驻在yarn集群中,除非手工停止。
2: 在向Flink集群提交Job的时候, 如果资源被用完了,则新的Job不能正常提交.
3: 缺点: 如果提交的作业中有长时间执行的大作业, 占用了该Flink集群的所有资源, 则后续无法提交新的job.
所以, Session-Cluster适合那些需要频繁提交的多个小Job, 并且执行时间都不长的Job.
4: 所有的job都提交到这个集群上 main函数在客户端执行
1) 启动一个Flink-Session 这是这种模式的玩法
bin/yarn-session.sh -d
2) 在Session上运行Job,会自动去找你启动的程序 -d 看不到日志,进程在后台
bin/flink run -d -c 主类 jar包
bin/flink run -c com.atguigu.flink.java.chapter_2.Flink03_WC_UnBoundedStream ./flink-prepare-1.0-SNAPSHOT.jar
会自动找到你的yarn-session启动的Flink集群.也可以手动指定你的yarn-session集群:
我不想手动指定
2: Per-Job-Cluster模式执行无界流WordCount
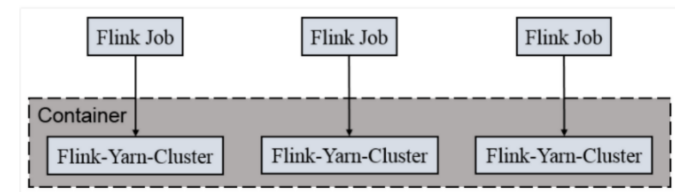
1: 一个Job会对应一个Flink集群,每提交一个作业会根据自身的情况,都会单独向yarn申请资源,直到作业执行完成,一个作业的失败与否并不会影响下一个作业的正常提交和运行。独享Dispatcher和ResourceManager,按需接受资源申请;适合规模大长时间运行的作业。
2: 每次提交都会创建一个新的flink集群,任务之间互相独立,互不影响,方便管理。任务执行完成之后创建的集群也会消失。在客户端执行
3: 每启动一个job启动一个集群, main函数在客户端执行,会话随着job的创建和消失
4:启动下面的命令会直接创建一个yarn会话 bin/flink run -d -t yarn-per-job -c 主类 jar包
bin/flink run -d -t yarn-per-job -c com.atguigu.flink.java.chapter_2.Flink03_WC_UnBoundedStream
./flink-prepare-1.0-SNAPSHOT.jar
3: Application Mode模式执行无界流WordCount
1: Application Mode会在Yarn上启动集群, 应用jar包的main函数(用户类的main函数)将会在JobManager上执行. 只要应用程序执行结束, Flink集群会马上被关闭. 也可以手动停止集群.
2: 与Per-Job-Cluster的区别: 就是Application Mode下, 用户的main函数是在集群中(job manager)执行的
3: 官方建议:
出于生产的需求, 我们建议使用Per-job or Application Mode,因为他们给应用提供了更好的隔离!
4: 每启动一个job启动一个集群 main函数在JobManager执行
5: bin/flink run-application -d -t yarn-application -c 主类 jar包
6: 开始操作
bin/flink run-application -t yarn-application -c com.atguigu.flink.java.chapter_2.Flink03_WC_UnBoundedStream
./flink-prepare-1.0-SNAPSHOT.jar
3.4.3 Yarn模式高可用
1) Yarn模式的高可用和Standalone模式的高可用原理不一样.
2) Standalone模式中, 同时启动多个Jobmanager, 一个为leader其他为standby, 当leader挂了, 其他的才会有一个成为leader.
3) yarn的高可用是同时只启动一个Jobmanager, 当这个Jobmanager挂了之后, yarn会再次启动一个, 其实是利用的yarn的重试次数来实现的高可用.
4) 在yarn-site.xml中配置 注意: 配置完不要忘记分发, 和重启yarn
<property>
<name>yarn.resourcemanager.am.max-attempts</name>
<value>4</value>
<description>
The maximum number of application master execution attempts.
</description>
</property>
5) 在flink-conf.yaml中配置
yarn.application-attempts: 3
high-availability: zookeeper
high-availability.storageDir: hdfs://hadoop162:8020/flink/yarn/ha
high-availability.zookeeper.quorum: hadoop162:2181,hadoop163:2181,hadoop164:2181
high-availability.zookeeper.path.root: /flink-yarn
6) 启动yarn-session
7) 杀死Jobmanager, 查看他的复活情况
注意: yarn-site.xml中是它活的次数的上限, flink-conf.xml中的次数应该小于这个值.
注意: 在10秒之内重启三次要是没有完成,还是杀不死yarn-session,这是flink默认设置这个,怕一个程序执行时间需要3天,中断了,但是因为你设置的这个程序不能重启了,所以设置了10秒内完成你设置的这个
3.5 K8S & Mesos模式
容器化部署时目前业界很流行的一项技术,基于Docker镜像运行能够让用户更加方便地对应用进行管理和运维。容器管理工具中最为流行的就是Kubernetes(k8s),而Flink也在最近的版本中支持了k8s部署模式。这里我们也不做过多的讲解.
Mesos是Apache下的开源分布式资源管理框架,就和yarn一样的,它被称为是分布式系统的内核,在Twitter得到广泛使用,管理着Twitter超过30,0000台服务器上的应用部署,但是在国内,依然使用着传统的Hadoop大数据框架,所以国内使用mesos框架的并不多,这里我们就不做过多讲解了。
第4章Flink运行架构
4.1运行架构
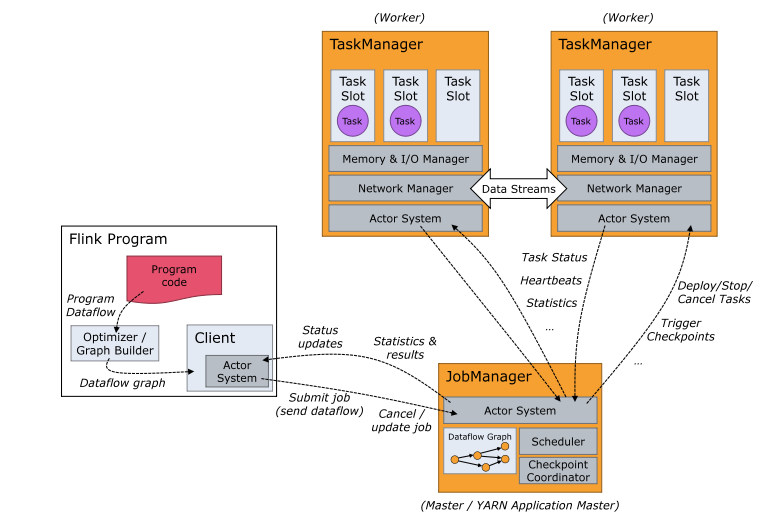
1) Flink运行时包含2种进程:1个JobManager和至少1个 TaskManager
2) TaskManager 是一个进程 --> 有多个 slots (线程,封装cpu和内存) --> 1个slots有多个task
4.1.1客户端
严格上说, 客户端不是运行和程序执行的一部分, 而是用于准备和发送dataflow到JobManager. 然后客户端可以断开与JobManager的连接(detached mode), 也可以继续保持与JobManager的连接(attached mode)
客户端作为触发执行的java或者scala代码的一部分运行, 也可以在命令行运行:bin/flink run ...
4.1.2 JobManager
1) 控制一个应用程序执行的主进程,也就是说,每个应用程序都会被一个的JobManager所控制执行。 JobManager会先接收到要执行的应用程序,这个应用程序会包括:作业图(JobGraph)、逻辑数据流图(logical dataflow graph)和打包了所有的类、库和其它资源的JAR包。 2) JobManager会把JobGraph转换成一个物理层面的数据流图,这个图被叫做“执行图”(ExecutionGraph),包含了所有可以并发执行的任务。JobManager会向资源管理器(ResourceManager)请求执行任务必要的资源,也就是任务管理器(TaskManager)上的插槽(slot)。一旦它获取到了足够的资源,就会将执行图分发到真正运行它们的TaskManager上。 3) 而在运行过程中,JobManager会负责所有需要中央协调的操作,比如说检查点(checkpoints)的协调。 这个进程包含3个不同的组件
4.1.2.1 ResourceManager
1) 负责资源的管理,在整个 Flink 集群中只有一个 ResourceManager. 注意这个ResourceManager不是Yarn中的ResourceManager, 是Flink中内置的, 只是赶巧重名了而已.
2) 主要负责管理任务管理器(TaskManager)的插槽(slot),TaskManger插槽是Flink中定义的处理资源单元。
3) 当JobManager申请插槽资源时,ResourceManager会将有空闲插槽的TaskManager分配给JobManager。如果ResourceManager没有足够的插槽来满足JobManager的请求,它还可以向资源提供平台发起会话,以提供启动TaskManager进程的容器。另外,ResourceManager还负责终止空闲的TaskManager,释放计算资源。
4.1.2.2 Dispatcher
负责接收用户提供的作业,并且负责为这个新提交的作业启动一个新的JobMaster 组件. Dispatcher也会启动一个Web UI,用来方便地展示和监控作业执行的信息。Dispatcher在架构中可能并不是必需的,这取决于应用提交运行的方式。
4.1.2.3 JobMaster
JobMaster负责管理单个JobGraph的执行.多个Job可以同时运行在一个Flink集群中, 每个Job都有一个自己的JobMaster.
4.1.3 TaskManager
1) Flink中的工作进程。通常在Flink中会有多个TaskManager运行,每一个TaskManager都包含了一定数量的插槽(slots)。插槽的数量限制了TaskManager能够执行的任务数量。
2) 启动之后,TaskManager会向资源管理器注册它的插槽;收到资源管理器的指令后,TaskManager就会将一个或者多个插槽提供给JobManager调用。JobManager就可以向插槽分配任务(tasks)来执行了。
3) 在执行过程中,一个TaskManager可以跟其它运行同一应用程序的TaskManager交换数据。
4.2 核心概念
4.2.1 TaskManager与Slots
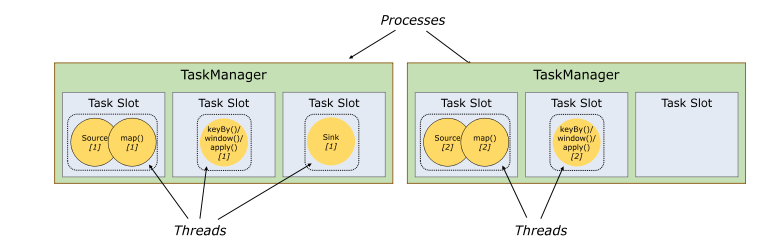
1) Flink中每一个worker(TaskManager)都是一个JVM进程,它可能会在独立的线程上执行一个Task。为了控制一个worker能接收多少个task,worker通过Task Slot来进行控制(一个worker至少有一个Task Slot)。
2) 这里的Slot如何来理解呢?很多的文章中经常会和Spark框架进行类比,将Slot类比为Core,其实简单这么类比是可以的,可实际上,可以考虑下,当Spark申请资源后,这个Core执行任务时有可能是空闲的,但是这个时候Spark并不能将这个空闲下来的Core共享给其他Job使用,所以这里的Core是Job内部共享使用的。接下来我们再回想一下,之前在Yarn Session-Cluster模式时,其实是可以并行执行多个Job的,那如果申请两个Slot,而执行Job时,只用到了一个,剩下的一个怎么办?那我们自认而然就会想到可以将这个Slot给并行的其他Job,对吗?所以Flink中的Slot和Spark中的Core还是有很大区别的。
3) 每个task slot表示TaskManager拥有资源的一个固定大小的子集。假如一个TaskManager有三个slot,那么它会将其管理的内存分成三份给各个slot。资源slot化意味着一个task将不需要跟来自其他job的task竞争被管理的内存,取而代之的是它将拥有一定数量的内存储备。需要注意的是,这里不会涉及到CPU的隔离,slot目前仅仅用来隔离task的受管理的内存。
4.2.2 Parallelism(并行度)
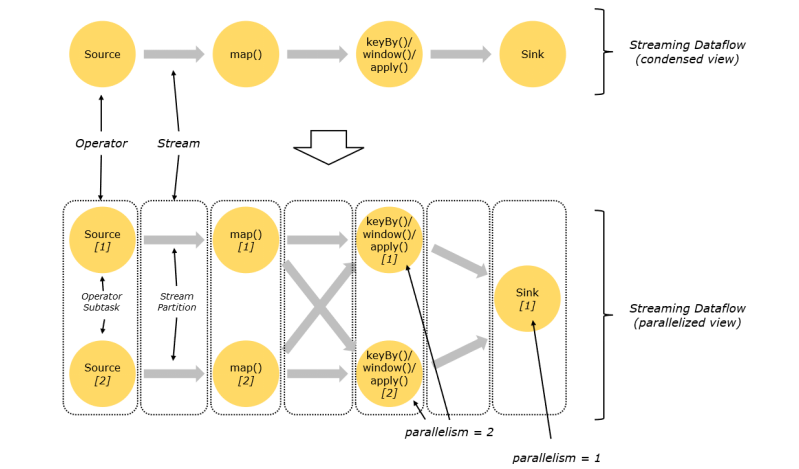
一个特定算子的子任务(subtask)的个数被称之为这个算子的并行度(parallelism),一般情况下,一个流程序的并行度,可以认为就是其所有算子中最大的并行度。一个程序中,不同的算子可能具有不同的并行度。
Stream在算子之间传输数据的形式可以是one-to-one(forwarding)的模式也可以是redistributing的模式,具体是哪一种形式,取决于算子的种类。
1) One-to-one: 1对1的关系 ,且并行度相同 stream(比如在source和map operator之间)维护着分区以及元素的顺序。那意味着flatmap 算子的子任务看到的元素的个数以及顺序跟source 算子的子任务生产的元素的个数、顺序相同,map、fliter、flatMap等算子都是one-to-one的对应关系。类似于spark中的窄依赖 2) Redistributing:分区数据发生了改变, stream(map()跟keyBy/window之间或者keyBy/window跟sink之间)的分区会发生改变。每一个算子的子任务依据所选择的transformation发送数据到不同的目标任务。例如,keyBy()基于hashCode重分区、broadcast和rebalance会随机重新分区,这些算子都会引起redistribute过程,而redistribute过程就类似于Spark中的shuffle过程。类似于spark中的宽依赖
4.2.3 Task与SubTask
一个算子就是一个Task. 一个算子的并行度是几, 这个Task就有几个SubTask
4.2.4 Operator Chains(优化)
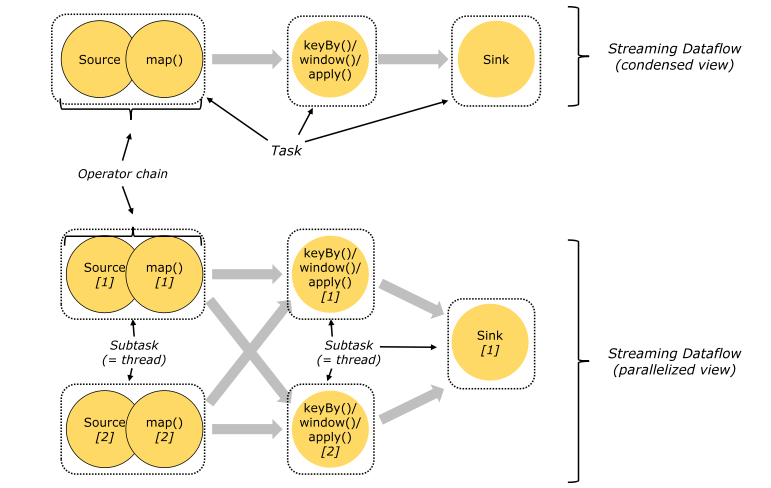
1: 操作链的优化是自动实现:
算子与算子之间: one-to-one
算子的并行度一样
-- 1: .startNewChain()
开启一个新链: 当前算子不会和前面的优化在一起
如果后面的算子满足优化条件, 也会与当前算子优化到一起
-- 2: .disableChaining()
当前算子不参与任何链的优化
--3: env.disableOperatorChaining()
当前应用所有算子都不进行优化
实际生产环境下, 尽量不要禁止优化: 优化只有好处没有坏处
2: 在flink中, 有4种办法设置并行度
-- 1. 在flink-conf.yaml 配置文件中设置算子的默认并行度
parallelism.default: 1
-- 2. 提交job的是时候通过参数设置
bin/flink run -d -p 2 ...
-- 3. 在代码中通过环境设置
env.setParallelism(1);
注意: 在flink中socket这个source他的并行度只能是1.
-- 4. 单独给每个算子设置并行度
.setParallelism(3)
演示代码:
public class Flink02_WC_UnBounded {
public static void main(String[] args) {
System.out.println("Flink02_WC_UnBounded.main");
// 1. 创建流的执行环境 自动根据当前运行的环境获取合适的执行环境
Configuration conf = new Configuration();
conf.setInteger("rest.port", 2000);
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(conf);
env.setParallelism(1);
//env.disableOperatorChaining(); 当前应用所有算子都不进行优化
// 2. 通过环境从数据源(source)获取一个流
DataStreamSource<String> source = env.socketTextStream("hadoop162", 9999);
// 3. 对流做各种转换
SingleOutputStreamOperator<String> wordStream = source
.flatMap(new FlatMapFunction<String, String>() {