团队博客
人工智能实战团队作业Beta展示 + Postmoterm报告
Beta展示——算术字符识别工具
1.背景介绍
如何在计算机上辅助计算公式?目前的方案主要包括mathOCR、爱作业、作业帮等代表,如下:

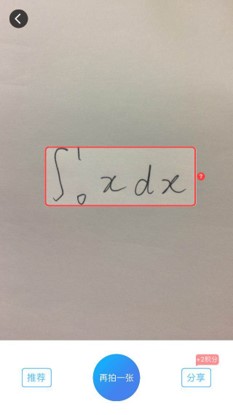

它们的缺点主要包括:
不支持手写字符输入、
不支持复杂题型、
不支持题库外的式子等等,
对于复杂的公式难以识别,对于简单的公式则应用场景不多。因此我们希望解决上述痛点,增强产品功能。
此类产品主要针对有辅助计算需求的学者和论文写作者,但还有一个基本的要求是近年来不断升级的验证码识别,以算术形式出现的验证码往往由被修改过的字符以异常的形式排列,因此不要求识别工具对于复杂式子的识别,但有对识别准确率的要求。算式识别工具可以作为API借口提供服务,便于爬虫等需要自动访问网页的工具调用,提高对算术验证码的识别、通过能力。
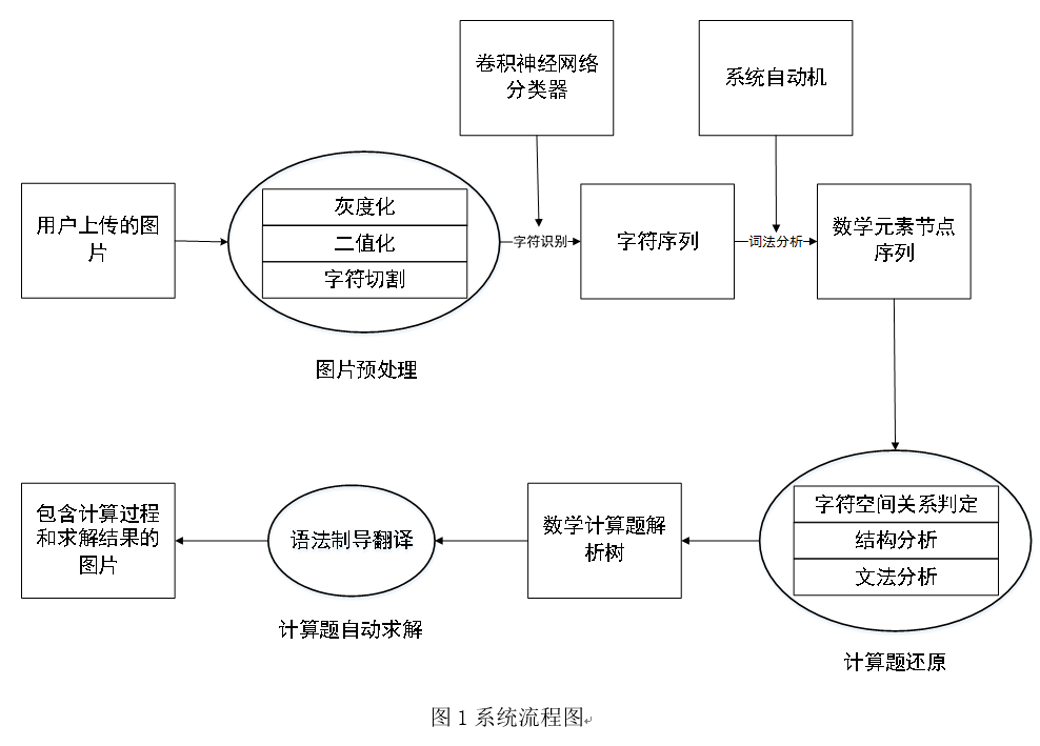
2. 架构设计
识别目标:对于四则运算+-*/ 和分式具有识别和计算能力
架构设计:
接收用户输入 -> 图片预处理 -> CNN识别 -> 获得算术字符流 -> 序列分析 -> 数学计算题解析树 -> 求解并返回结果
架构设计图示:
3. 系统实现
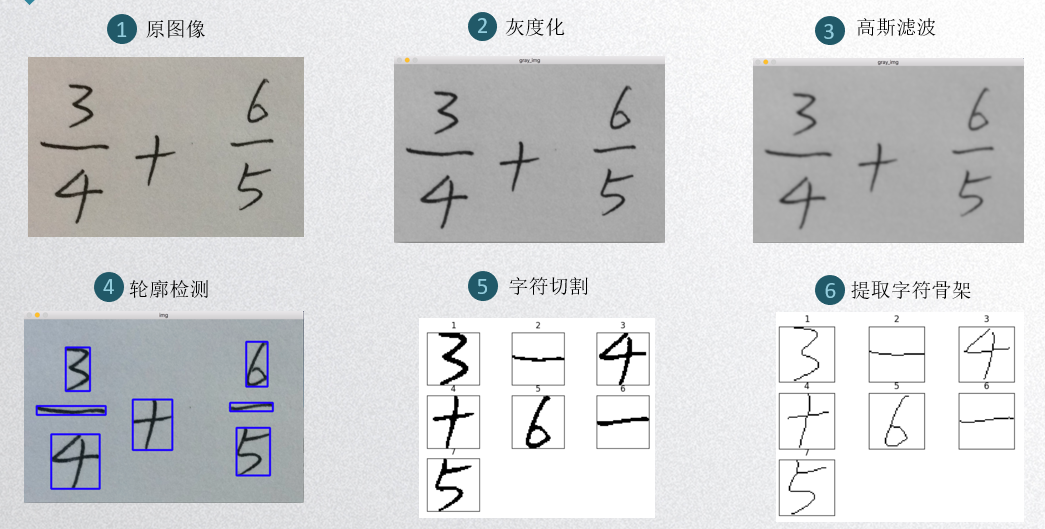
图片预处理
图片预处理以OpenCV作为主要工具。预处理的主要目的是把图片中的字符切割出来,同时避免无关变量对字符识别的影响。
主要步骤包括:灰度化、二值化、高斯滤波、字符切割与细化
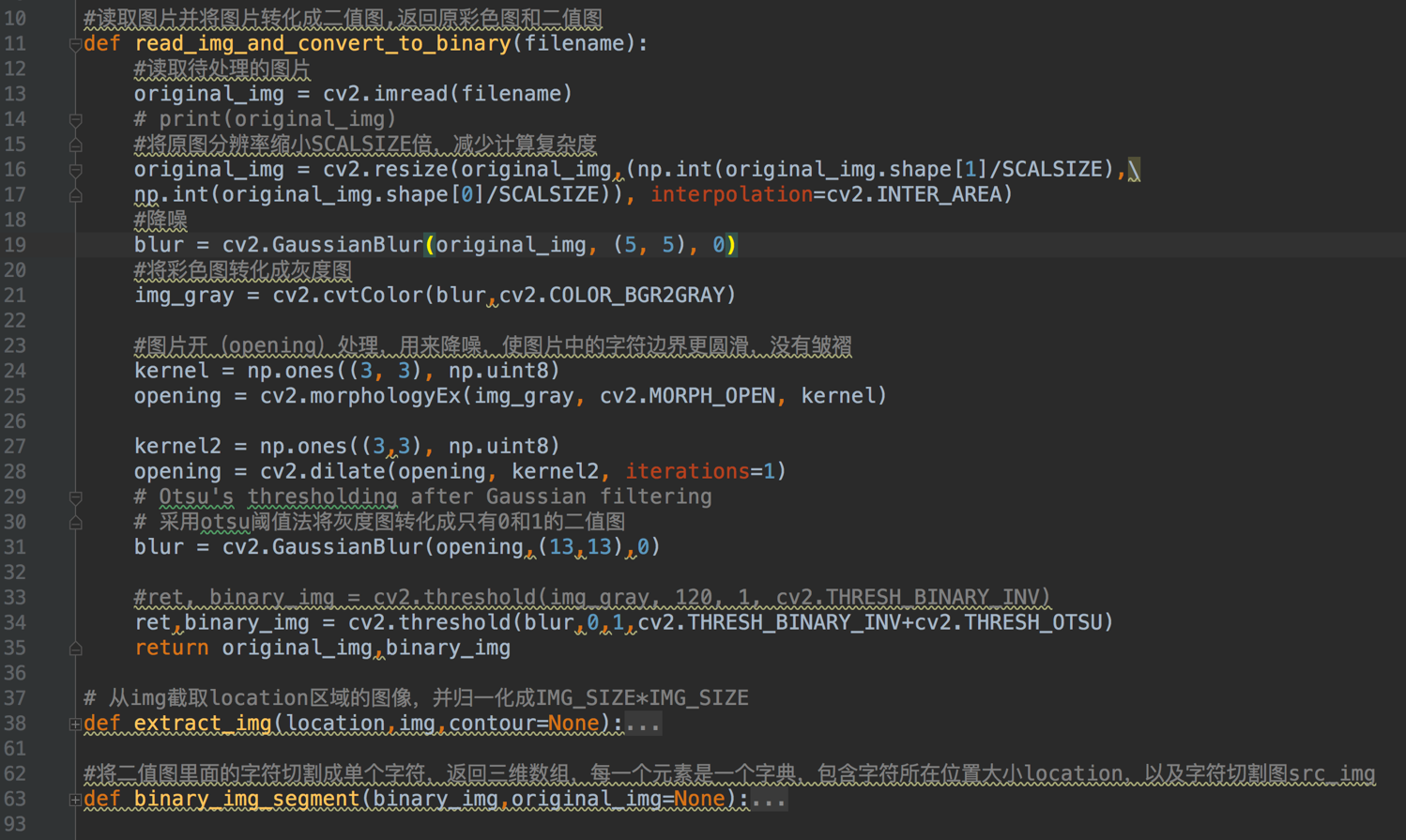
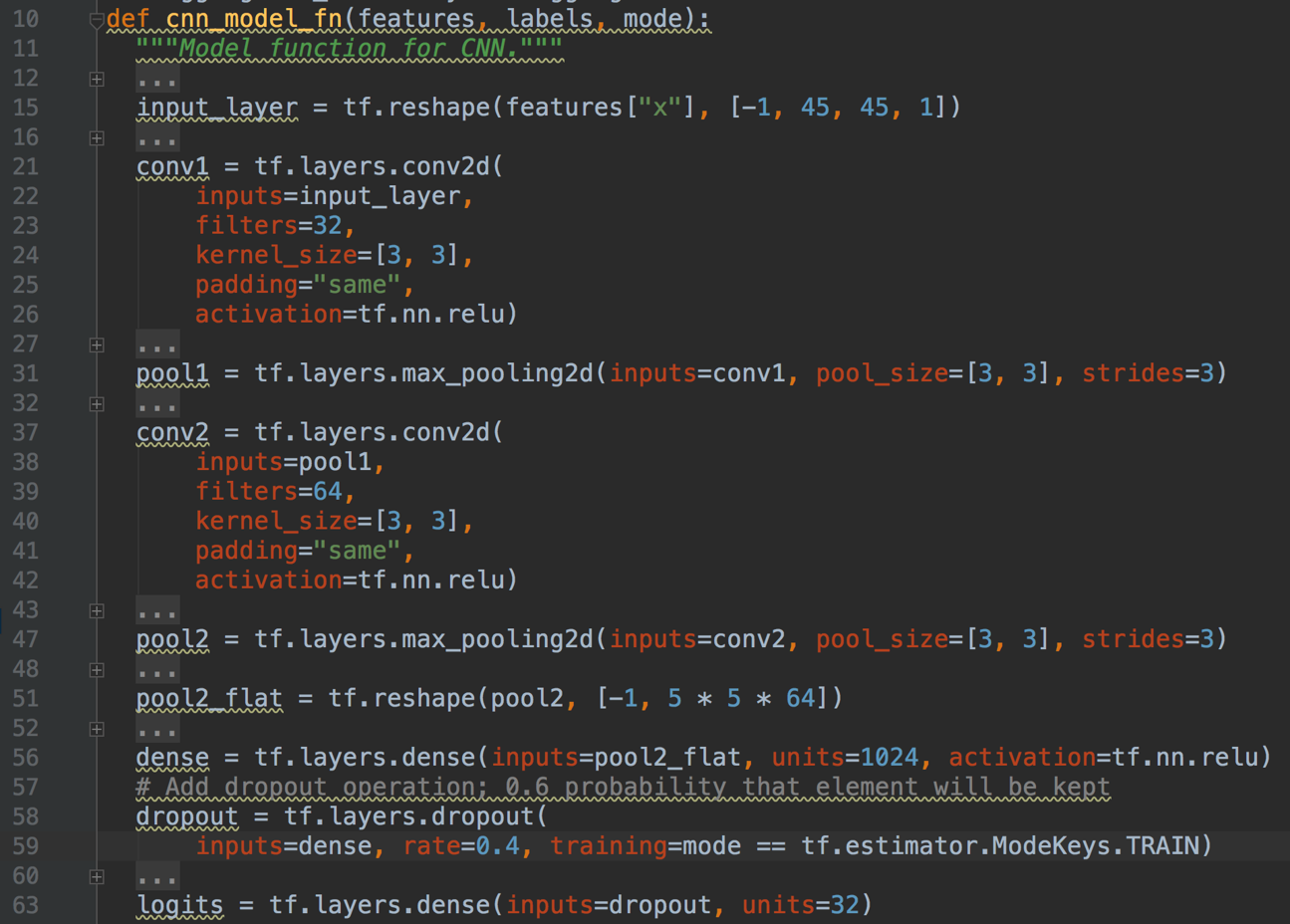
工具介绍:
- 卷积神经网络模型(CNN)
不需要提取字符特征值
图像识别精确度高- 国际数学公式识别比赛数据集(CROHME)
海量字符集图片
与实际输入相似
具体步骤:
结构分析:
- 数据结构:数据结构是研究数据在计算机怎么表示的问题。而数学计算题也可以抽象成一种数据类型。
- 编译原理:编译原理是一门讲解一种语言如何翻译成另外一门语言的过程。
- 树结构:树可以很方便地表达数学计算式这种具有嵌套关系的数据。
- 文法:文法可以用来解析数学计算式,将其转换成一颗语义树。
- 分治算法:可以将一个大的数学计算式分成比较小的表达式,分而治之。
- 特征值法:对于字符间的空间关系,可以提取两个字符之间的一些特征,再根据这些特征判断它们的空间关系。
项目重要文件介绍:
- 项目配置文件:
待补充
操作说明:
- 运行程序:
待补充
- 在界面左边输入手写字符
- 右侧显示识别结果,界面上端显示计算结果
- 点击Solve按钮:展示结果
- 点击Clear按钮:清楚输入状态
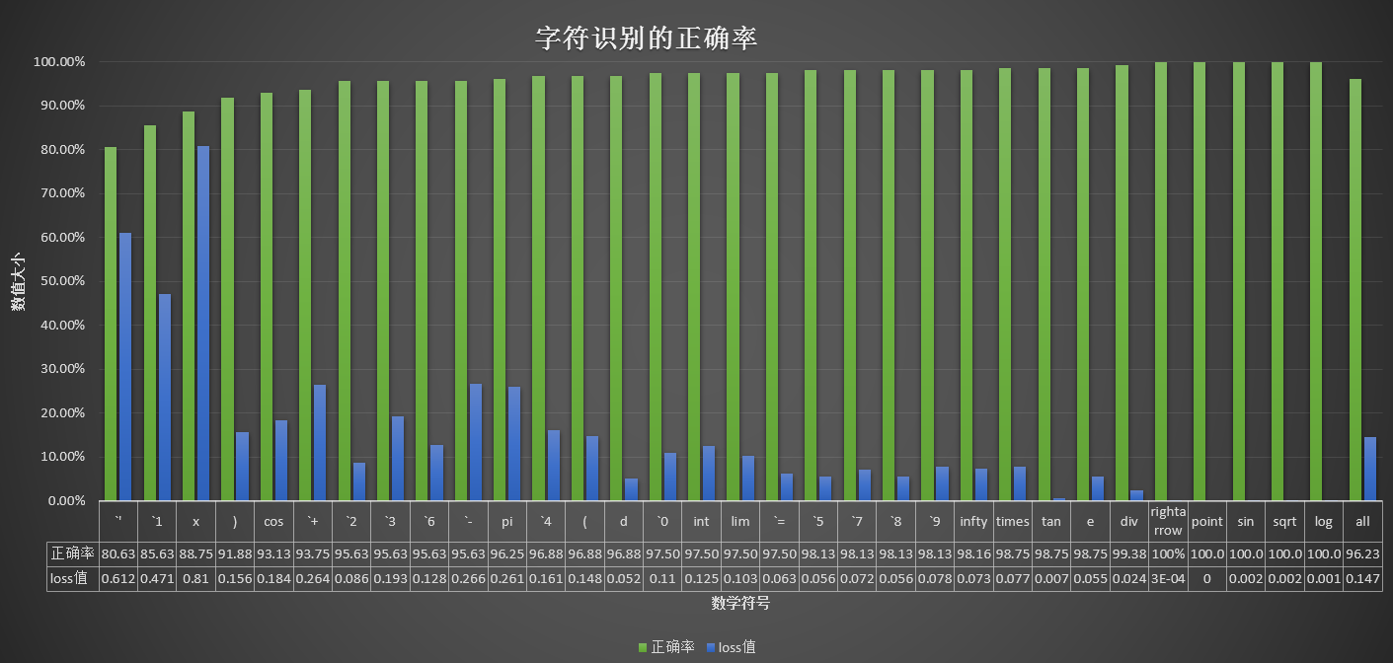
4. 实验结果
识别正确率
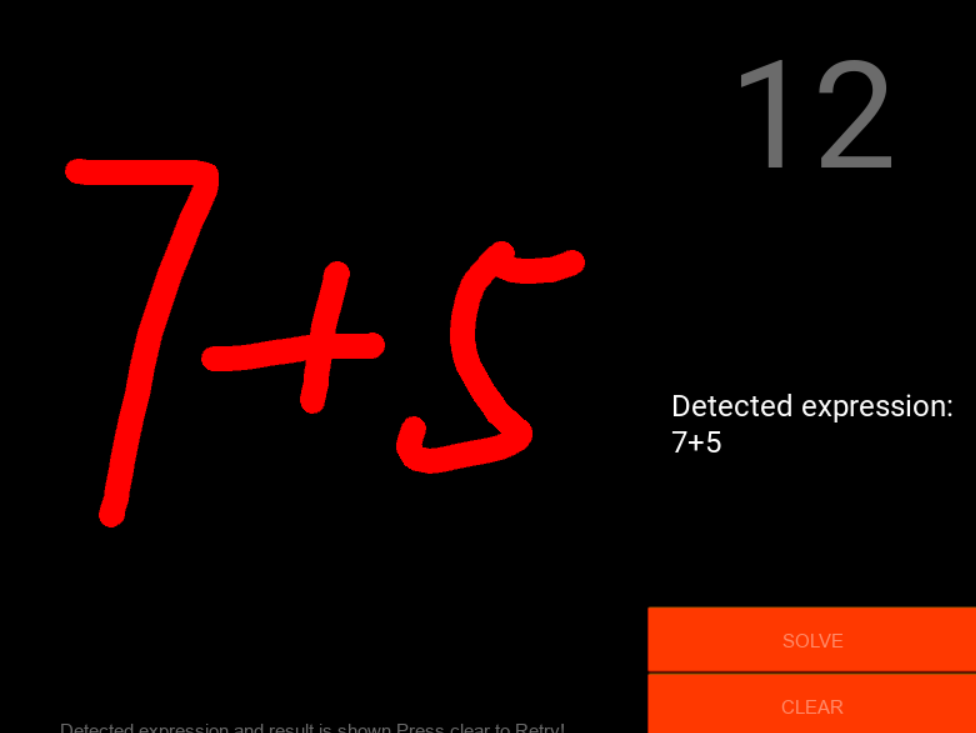
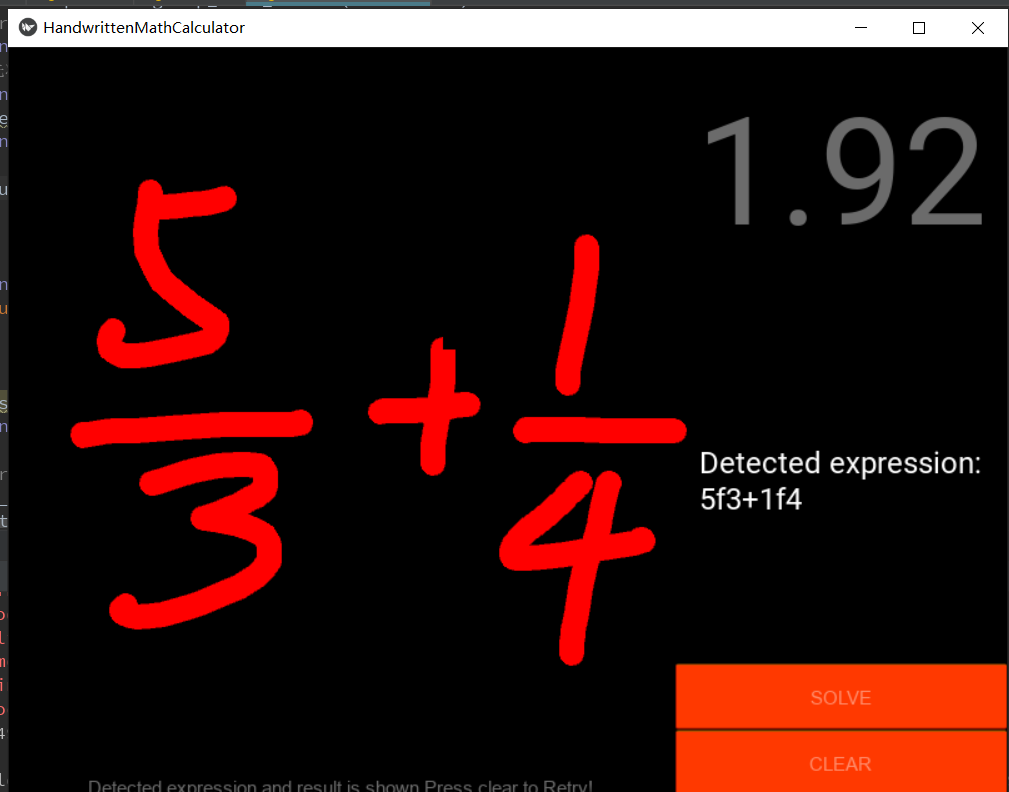
测试样例:
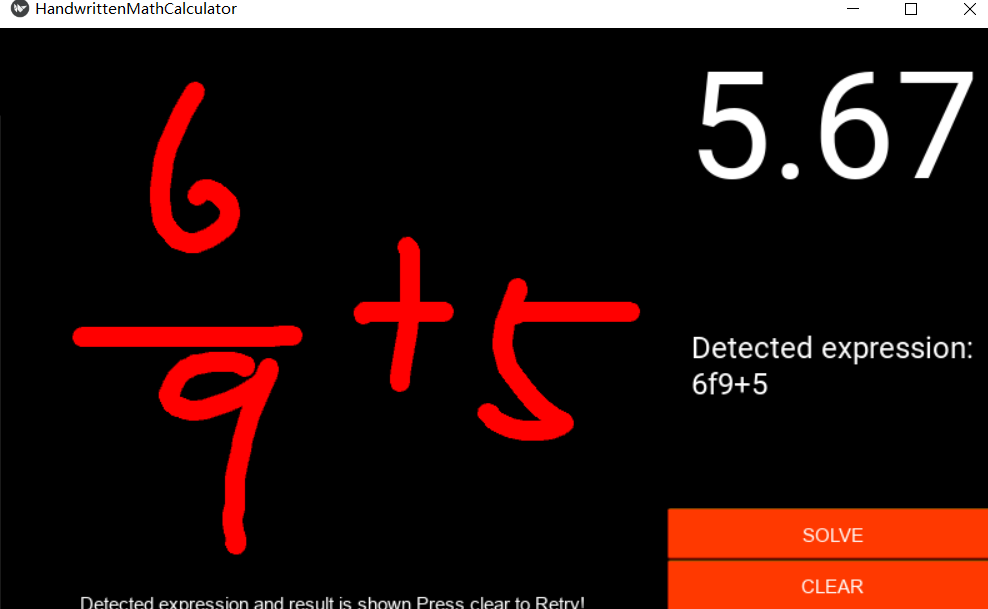

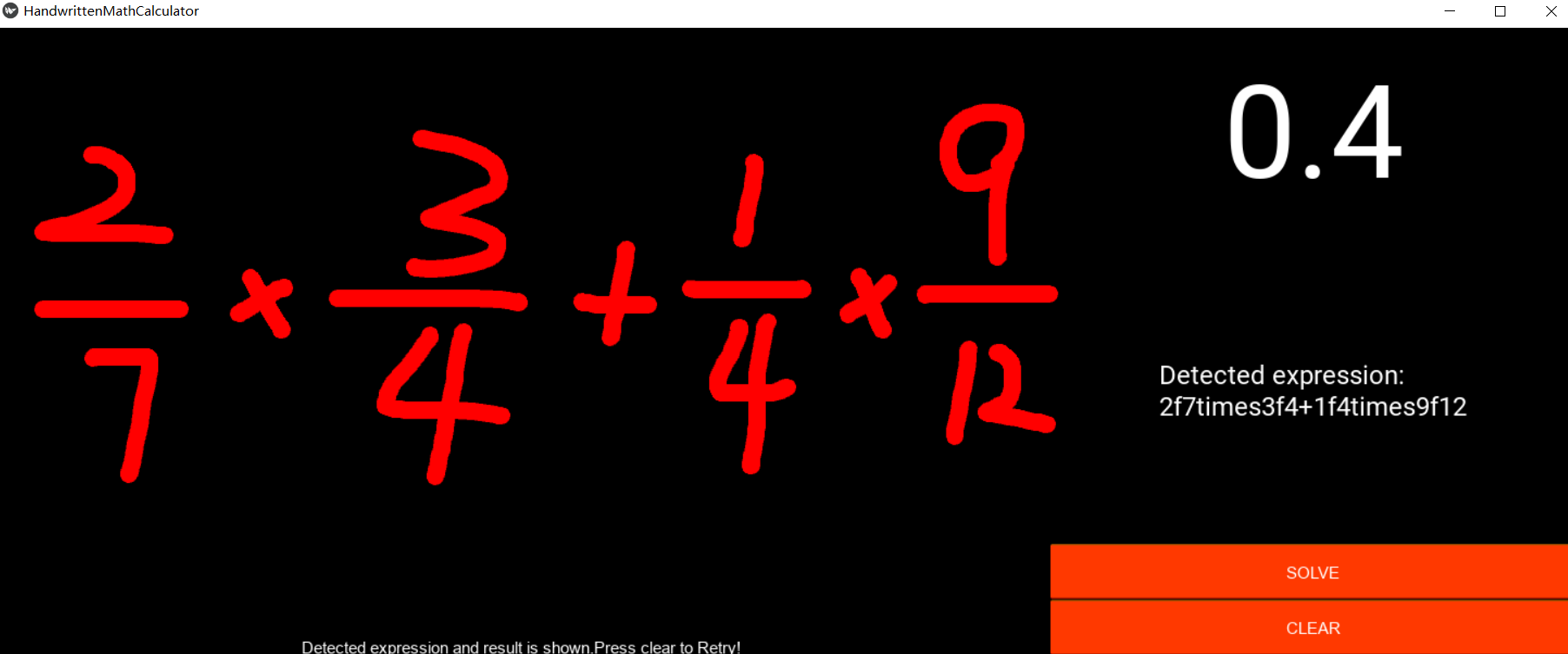

5. 总结
> 优点
- 提出了可行的一般化的手写做题系统算法框架。
- 使用卷积神经网络模型识别字符,精度高,适应性强。
- 拓展了属性文法,使其适用于数学计算题的自动求值。
> 缺点
- 缺乏更为广泛的测试。
- 在设计逻辑上,前面环节的错误会导致后面环节的错误。
Postmoterm报告
总述
<成员>每个成员在beta阶段更加积极配合完成任务,由于课业影响,整个项目执行期较短,但成员基本都能加急完成分配的任务,并致力于找bug和debug。
<吸收教训>在alpha和beta阶段的时间安排都不算很合理,不过beta阶段的预备时间比alpha阶段多了50%以上,算是做了一定的准备工作。其次由于目标更为清晰,beta阶段的构建过程更加顺利。
<开发评价>我们主要是大教堂的开发模式,因为前期感觉没有太多可以展示的项目代码。后续功能完善,或者在其他更为大型的项目中将考虑转向市集模式。整个开发周期较长,但实际项目推进的时间较短,一方面说明项目安排是存在问题的,执行力度不足;一方面说明开发资源没有充分利用,团队成员能力应该高于开发此项目所需最低需求,项目可以更快更好地完成。
设想和目标
我们的软件要解决什么问题?是否定义得很清楚?是否对典型用户和典型场景有清晰的描述?
- 我们希望设计一个支持算术字符识别的工具,它是一个客户端,能够接收用户输入的算术字符,然后返回计算过程和结果。工具主要针对验证码识别,以及简单的手写识别。在验证码识别中,只需将验证码图片导入即可。
我们达到目标了么(原计划的功能做到了几个? 按照原计划交付时间交付了么? 原计划达到的用户数量达到了么?)
- Alpha版本实现了对单个数字的识别,Beta版本实现了手写算式识别。基本按照预定时间交付。暂未推向市场,未获得用户。
和上一个阶段相比,团队软件工程的质量提高了么? 在什么地方有提高,具体提高了多少,如何衡量的?
- 我们在代码质量上有所提高,具体是计算核心算法被更新,UI被重写。
有什么经验教训? 如果历史重来一遍, 我们会做什么改进?
- 我们实行计划的时间有点赶,没有明确团队成员的任务就开始执行项目,主要还是靠大佬hold住。
计划
是否有充足的时间来做计划?
- 是的。
团队在计划阶段是如何解决同事们对于计划的不同意见的?
- 微信在线讨论。
你原计划的工作是否最后都做完了? 如果有没做完的,为什么?
- 我们原计划的工作基本完成,但未实现在验证码工具上的完整应用程序,暂未将识别范围拓展至更多类型的算式。
是否项目的整个过程都按照计划进行,项目出了什么意外?有什么风险是当时没有估计到的,为什么没有估计到?
- 出现了分式识别的bug,分式的识别准确率较低。因为没有对分式的识别进行单独测试。
我们学到了什么? 如果历史重来一遍, 我们会做什么改进?
- 我们将调整项目进度安排,并对更多类型的计算进行实现和测试。
资源
我们有足够的资源来完成各项任务么?
- 是的。该项目的硬件需求较低,人员充足。
测试的时间,人力和软件/硬件资源是否足够? 对于那些不需要编程的资源 (美工设计/文案)是否低估难度?
低估了UI设计的难度,导致UI改进程度不大。
变更管理
每个相关的成员都及时知道了变更的消息?
- 是的。
我们采用了什么办法决定“推迟”和“必须实现”的功能?
- 取决于当时所有人员的空闲情况,以及交付的紧急程度。
成员是否能够有效地处理意料之外的工作请求?
- 目前都已处理。
设计/实现
设计工作在什么时候,由谁来完成的?是合适的时间,合适的人么?
- 是在项目的启动阶段,由团队讨论完成。
设计工作有没有碰到模棱两可的情况,团队是如何解决的?
- 比如对于产品功能的定位,最初的设计意见不一,最终讨论决定先做稳一点的验证码识别工具。
什么功能产生的Bug最多,为什么?在发布之后发现了什么重要的bug? 为什么我们在设计/开发的时候没有想到这些情况?
- 字符识别功能Bug最多,一个是因为神经网络模型训练的不好,一个是因为对于识别逻辑没有考虑充分,导致存在未考虑过的情况出现,比如分式识别错误。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号